Article
Exploring Watson NLU's Syntax API
Extract more semantic information within your content by using tokenization lemmatization, parts of speech, and sentence splittingThis article follows on to the article, An introduction to Watson natural language processing.
What is natural language processing?
Natural language processing is the parsing and semantic interpretation of text, allowing computers to learn, analyze, and understand human language. These capabilities can be applied to use cases such as text mining, recognizing individual people from their writing, and performing sentiment analysis. Watson™ Natural Language Understanding offers advanced text analytics.
Watson Natural Language Understanding can analyze text and return a five-level taxonomy of the content as well as concepts, emotion, sentiment, entities, and relations. The new release of its syntax API feature allows users to extract much more semantic information within their content by leveraging tokenization, parts of speech, lemmatization, and sentence splitting. Let's take a look at each of those sub-features.
Tokenization
Tokenization is the process in which sentences are segmented into words, phrases, or symbols called tokens. This is a crucial and necessary step that occurs prior to any data processing. Tokenization is essentially pre-processing one's data, identifying the basic units needed to be processed. Without these basic units, it is difficult to carry out an analysis of the content.
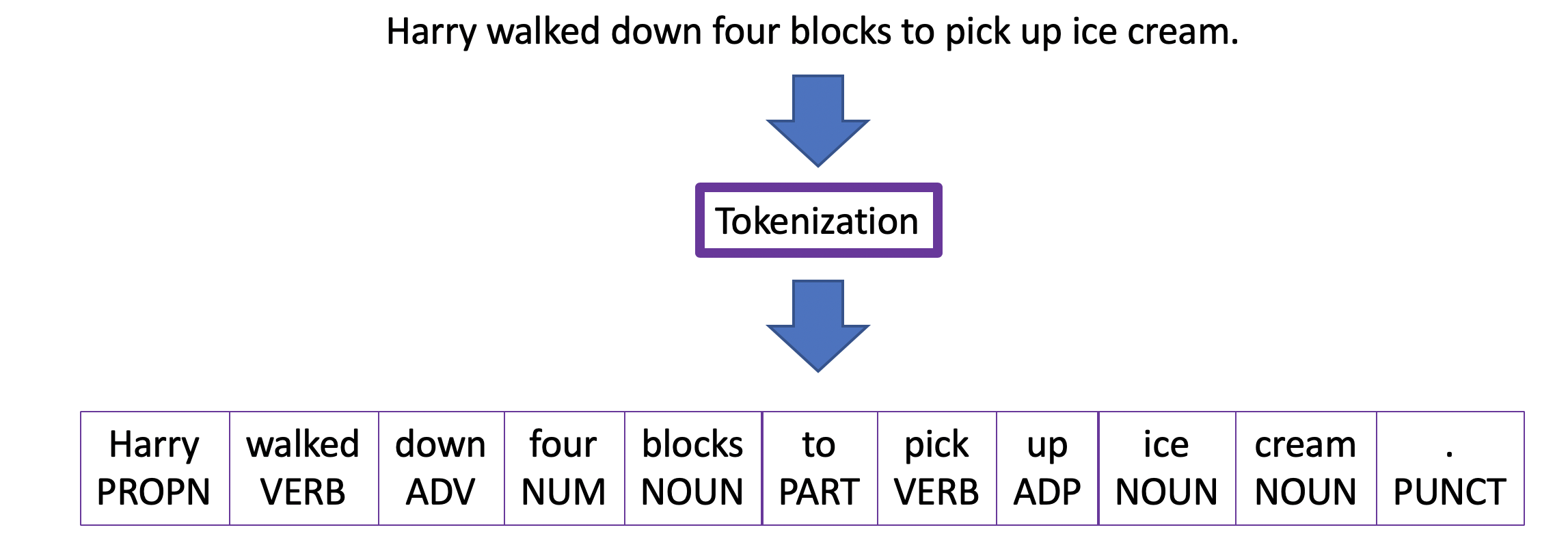
In most languages, words are often split up by white spaces. Tokenization splits up the words and punctuation symbols and delivers the building blocks of the text.
Lemmatization
Documents are going to have multiple versions of a word within the content -- run and running, for example. These words and their different forms have similar meanings only in their simplest form. The goal of lemmatization is to reduce the complexity of these words and break down the word into its simplest form.

Through lemmatization, we see that the more complex version of words were broken down into simpler meanings while still conveying the same thought. Lemmatization allows users to reduce the complexity of their algorithms by reducing words down to their simplest form.
Parts of speech
After a phrase has been tokenized, each token is categorized by a certain part of speech. Watson Natural Language Understanding uses the universal parts of speech across all languages, including noun, verb, adjective, pronoun, punctuation, and proper noun. Parts of speech are extremely important when it comes to natural language processing. It can be used in word-sense disambiguation and understanding the intent behind each word within a sentence.

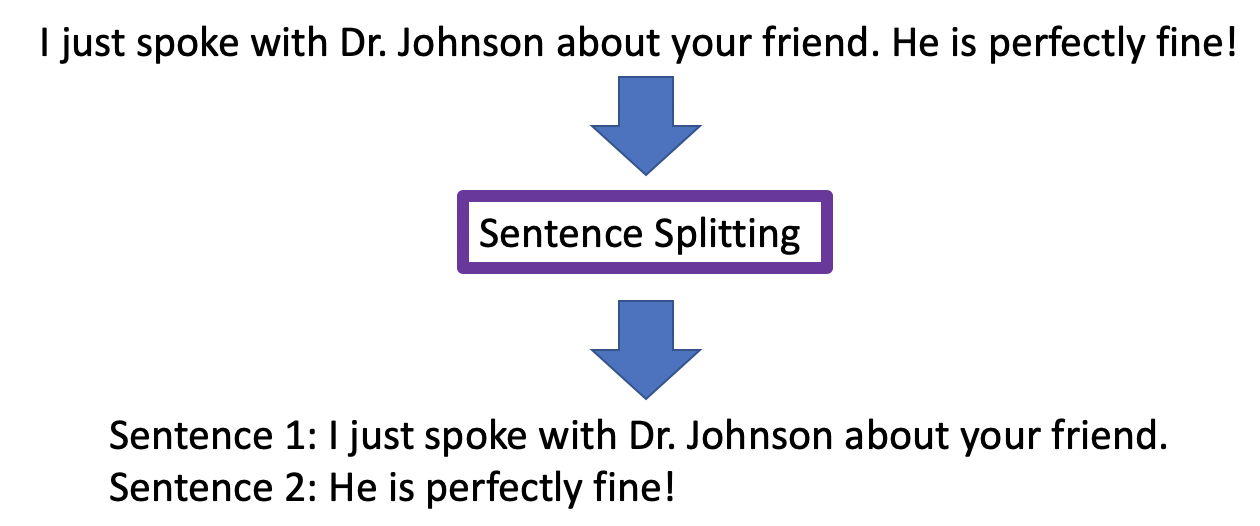
Sentence splitting
There will be multiple instances where users will have to know when a sentence stops and when the next one begins without being confused with a proper noun such as "Mr." or "Mrs." in the sentence. Watson Natural Language Understanding determines when a complete thought has been expressed in a sentence and can tell when that sentence ends and when the next one begins.
Example request to Syntax API
To call the syntax API by using curl commands, copy and paste the following code using your API authorization token. If you have forgotten how to create an API authorization token, you can follow these instructions.
curl --request POST \
--url 'https://api.us-south.natural-language-understanding.watson.cloud.ibm.com/api/v1/analyze?version=2019-01-27' \
--header "Authorization: Bearer {your token here}" \
--header 'content-type: application/json' \
--data '{
"text": "Mr. Earl wasn't looking for his wallet. He's searching for his new scarf to fit his look.",
"features": {
"syntax": {
"sentences": true,
"tokens": {
"lemma": true,
"part_of_speech": true
}
}
},
"language": "en"
}'
The API returns the following output:
{
"usage": {
"text_units": 1,
"text_characters": 89,
"features": 0
},
"syntax": {
"tokens": [
{
"text": "Mr.",
"part_of_speech": "PROPN",
"location": [
0,
3
],
"lemma": "Mr."
},
{
"text": "Earl",
"part_of_speech": "PROPN",
"location": [
4,
8
],
"lemma": "earl"
},
{
"text": "was",
"part_of_speech": "AUX",
"location": [
9,
12
],
"lemma": "be"
},
{
"text": "n't",
"part_of_speech": "PART",
"location": [
12,
15
],
"lemma": "not"
},
{
"text": "looking",
"part_of_speech": "VERB",
"location": [
16,
23
],
"lemma": "look"
},
{
"text": "for",
"part_of_speech": "ADP",
"location": [
24,
27
],
"lemma": "for"
},
{
"text": "his",
"part_of_speech": "PRON",
"location": [
28,
31
],
"lemma": "his"
},
{
"text": "wallet",
"part_of_speech": "NOUN",
"location": [
32,
38
],
"lemma": "wallet"
},
{
"text": ".",
"part_of_speech": "PUNCT",
"location": [
38,
39
]
},
{
"text": "He",
"part_of_speech": "PRON",
"location": [
40,
42
],
"lemma": "he"
},
{
"text": "'s",
"part_of_speech": "AUX",
"location": [
42,
44
],
"lemma": "be"
},
{
"text": "searching",
"part_of_speech": "VERB",
"location": [
45,
54
],
"lemma": "search"
},
{
"text": "for",
"part_of_speech": "ADP",
"location": [
55,
58
],
"lemma": "for"
},
{
"text": "his",
"part_of_speech": "PRON",
"location": [
59,
62
],
"lemma": "his"
},
{
"text": "new",
"part_of_speech": "ADJ",
"location": [
63,
66
],
"lemma": "new"
},
{
"text": "scarf",
"part_of_speech": "NOUN",
"location": [
67,
72
],
"lemma": "scarf"
},
{
"text": "to",
"part_of_speech": "PART",
"location": [
73,
75
],
"lemma": "to"
},
{
"text": "fit",
"part_of_speech": "VERB",
"location": [
76,
79
],
"lemma": "fit"
},
{
"text": "his",
"part_of_speech": "PRON",
"location": [
80,
83
],
"lemma": "his"
},
{
"text": "look",
"part_of_speech": "NOUN",
"location": [
84,
88
],
"lemma": "look"
},
{
"text": ".",
"part_of_speech": "PUNCT",
"location": [
88,
89
]
}
],
"sentences": [
{
"text": "Mr. Earl wasn't looking for his wallet.",
"location": [
0,
39
]
},
{
"text": "He's searching for his new scarf to fit his look.",
"location": [
40,
89
]
}
]
},
"language": "en"
}
Conclusion
The syntax API is compatible with other features within Watson Natural Language Understanding, such as entities, categories, and so on. You can focus more on the business need of implementing natural language processing, as opposed to focusing on the complexity of language models. Syntax API is currently under an experimental release. Currently, this feature is free to use.
Read more about the syntax API in the API Docs, then try out the new syntax feature for Watson Natural Language Understanding.