Article
Exploring the DWARF debug format information
Introduction to Debugging with attributed record formatsIntroduction
DWARF (debugging with attributed record formats) is a debugging file format used by many compilers and debuggers to support source-level debugging. It is the format of debugging information within an object file. The DWARF description of a program is a tree structure where each node can have children or siblings. The nodes might represent types, variables, or functions.
DWARF uses a series of debugging information entries (DIEs) to define a low-level representation of a source program. Each debugging information entry consists of an identifying tag and a series of attributes. An entry or group of entries together, provides a description of a corresponding entity in the source program. The tag specifies the class to which an entry belongs and the attributes define the specific characteristics of the entry.
DWARF sections
The different DWARF sections that make up the DWARF data are:
| .debug_abbrev | Abbreviations used in the .debug_info section |
|---|---|
.debug_aranges | Lookup table for mapping addresses to compilation units |
.debug_frame | Call frame information |
.debug_info | Core DWARF information section |
.debug_line | Line number information |
.debug_loc | Location lists used in the DW_AT_location attributes |
.debug_macinfo | Macro information |
.debug_pubnames | Lookup table for global objects and functions |
.debug_pubtypes | Lookup table for global types |
.debug_ranges | Address ranges used in the DW_AT_ranges attributes |
.debug_str | String table used in .debug_info |
.debug_types | Type descriptions |
The .debug_abbrev section contains the abbreviation tables for all the compilation units that are DWARF compiled. The abbreviations table for a single compilation unit consists of a series of abbreviation declarations. Each declaration specifies the tag and attributes for a particular debugging information entry. The appropriate entry in the abbreviations table guides the interpretation of the information contained directly in the .debug_info section. The .debug_info section contains the raw information regarding the symbols. Each compilation unit is associated with a particular abbreviation table, but multiple compilation units can share the same table.
DWARF representation
There are licensed tools, such as readelf, dwarfdump,_and_libdwarf available to read DWARF information. A script or program can read the output of these tools to find and interpret the required information. It is important to know tags and attribute definitions to write such scripts.
Common tags and attributes
The following list shows the tags that are mostly of interest when debugging a C++ application.
| DW_TAG_class_type | Represents the class name and type information |
|---|---|
DW_TAG_structure_type | Represents the structure name and type information |
DW_TAG_union_type | Represents the union name and type information |
DW_TAG_enumeration_type | Represents the enum name and type information |
DW_TAG_typedef | Represents the typedef name and type information |
DW_TAG_array_type | Represents the array name and type information |
DW_TAG_subrange_type | Represents the array size information |
DW_TAG_inheritance | Represents the inherited class name and type information |
DW_TAG_member | Represents the members of class |
DW_TAG_subprogram | Represents the function name information |
DW_TAG_formal_parameter | Represents the function arguments' information |
DW_AT_name | Represents the name string |
DW_AT_type | Represents the type information |
DW_AT_artificial | Is set when it is created by compiler |
DW_AT_sibling | Represents the sibling location information |
DW_AT_data_member_location | Represents the location information |
DW_AT_virtuality | Is set when it is virtual |
DWARF information
The following command is used to compile a program in the DWARF format using the XLC compiler.
/usr/vacpp/bin/xlC ‑g ‑qdbgfmt=dwarf ‑o test test.CFigure 1. Sample test program

The dwarfdump output of the above example can be interpreted in the following way.
Compilation unit
The .debug_abbrev section for DW_TAG_compile_unit looks as shown in Figure 2.
Figure 2. .debug_abbrev section

DW_TAG_* is generally followed by DW_CHILDREN_* and a series of attributes (DW_AT_*) along with the (DW_FORM_*)format.DW_CHILDREN_* is a 1-byte value that determines whether a debugging information entry using this abbreviation has child entries. If the value is DW_CHILDREN_yes, the next physically succeeding entry of any debugging information entry using this abbreviation is the first child of that entry. If the 1-byte value following the abbreviation's tag encoding is DW_CHILDREN_no, the next physically succeeding entry of any debugging information entry using this abbreviation is a sibling of that entry. Each chain of sibling entries is terminated by a null entry.
Figure 3. DW_TAG_compile_unit in the .debug_info section

The DW_FORM_* attribute specifies the way to read DW_AT* in the.debug_infosection. In this case, DW_AT_name is of the form string. So the first attribute of DW_TAG_compile_unit has to be handled as a string in the .debug_info section, which is test.C.
- The file type is
C_plus_plusand it is present at/home/raji. - The file is compiled using
IBM XL C/C++v12.
Extract class information
DW_TAG_class_type– Represents the class name and type informationDW_TAG_member– Represents the members of classFigure 4. Class name and member information

Figure 4 explains that:
- There is a data type, named
intand its size is4bytes. - There is a class, named
baseand its size is4bytes and its sibling entry is at location<126>. - There is a class member, named
basemember. The type of this member is at location<82>, which isint. The scope ispublicand it is present at the 0th location from the starting of the class.
Extract array size
The immediate child of DW_TAG_array_type is DW_TAG_subrange_type, which has the array size. Array size is calculated as (DW_AT_upper_bound- DW_AT_lower_bound) +1. If it is a two-dimensional array, there will be an immediate sibling of type DW_TAG_subrange_type again. In this case, the array size is 8 (7+1).
Figure 5. Array size

Extract function names and arguments
DW_TAG_subprogram -Represents function name informationDW_TAG_formal_parameter``-Represents function arguments' informationFigure 6. Function name

Figure 7. Function arguments

Figure 7 describes that:
- There is a function, named
display, and its scope ispublicand its sibling is located at<332>. - The mangled name is
display__7myclassFi. - The first argument to the function is
this. It is created by the compiler asDW_AT_artificialand is set toyesand the type is at location<421>, which ismyclass. - The second argument name is x and the type is at location
<82>, which isint.
Extract typedef
DW_TAG_typedef represents the typedef name and type information.
Figure 8. typedef

From Figure 8, we can understand that there is a typedef entry named int_type and its type is at location <82>, which is int.
Extract enum information
DW_TAG_enumeration_typehas the enum name andDW_TAG_enumerator represents its elements' information.DW_AT_const_valuespecifies the values assigned to the elements.Figure 9. enum values
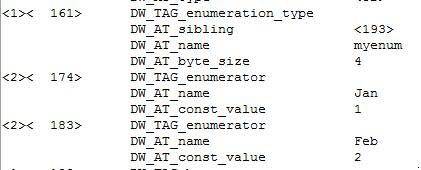
Figure 9 explains that:
myenumis the name of the enum and its size is4bytes.Janis the first element and its value is1.Febis the second element and its value is2.
Extract inheritance information
DW_TAG_inheritancerepresents the inherited class name and type information.
Figure 10. inheritance

Figure 10 explains that:
- There is a derived class named,
myclass, and its size is24bytes. - The base class is at location
<94>, and is namedbase. The DW_VIRTUALITY_noneattribute specifies it as a non-virtual class.