Article
From data to knowledge
Learn how information science has made significant leaps forwardOver the past few years, information science has made significant leaps forward. As local servers gave ground to cloud services, SQL databases and data tables began to migrate toward NoSQL and key-value data stores. Then came the advent of big data and the associated scaling technologies to handle the large volumes, varieties, and velocities of data.
Major advances in hardware and software made all this possible. Data storage is not expensive; therefore, it's possible to store vast amounts of data cheaply.
Data analytics makes sense of all this data and produces information from it. Based on this information, you can make decisions and take actions. The result is a corresponding evolution in the field of data analytics. Cognitive processing such as machine learning and deep learning now augment analytics.
Analysts need to clean and check the validity of input data before using it for analysis. Structured data allows for easy retrieval, and so raw data must be prepared and formatted before data analysis can begin. The data-information-knowledge-wisdom (DIKW) model is useful for understanding how raw data turns into useful information, and then into knowledge, and finally wisdom.
About this series
There are three articles in the How data becomes knowledge series:
- From data to knowledge: This article traces the path from raw data to stored knowledge. It identifies various data sources and the differences between structured and unstructured data. Then, it identifies what makes data valuable before applying the DIKW model to data science.
- Data lakes and data swamps: This article introduces the terminology surrounding data lakes and data warehouses, explores the evolution and benefits of data lakes, and explains how the advent of machine learning is a compelling reason to move to data lake architectures. Managing data by structuring and cataloging it makes it more useful and valuable. Knowing and being able to trust the data source and data are crucial factors in ensuring high-quality data. Data governance provides help in this regard.
- Extracting dark data: This article of the series discusses the factors that lead to the creation of dark data, the steps you can take to curate and manage data more effectively, and the methods you can use to extract and use dark data after the fact. Of all data, 90% is unstructured, which makes efficient querying a problem. Machine learning helps bring structure and therefore efficiency to this dark data. Relational data is more valuable because it can produce better insights.
Data sources
Raw data comes from diverse sources. A significant source of data continues to be the traditional relational database. Another major source of data is machine-generated and real-time data, such as from Internet of Things (IoT) devices. Data mining tools scrape websites or social media and generate data. Machines also generate data in the form of transactions and log files.
Human interactions over digital media produce data in the form of text and email messages, images, and videos. The human brain is adept at extracting information from these diverse media formats. In contrast, this kind of data is a challenge for computers to understand. Machines tend to produce structured data, while humans tend to produce unstructured data.
Structured and unstructured data
Structured data has a high degree of organization, which makes storing it in a relational database easy. Simple queries and search algorithms can efficiently retrieve this data, which makes processing structured data with computers easy and efficient.
In contrast, unstructured data lacks a machine-readable structure. Humans are currently better and more efficient than machines at reading and extracting such data, but the effort is both time-consuming and energy expensive. Human-centric processes are also prone to errors. So, what makes data valuable, and how can you apply the DIKW model?
What makes data valuable?
Data is typically a jumble of raw facts, and users need to sift through it to properly interpret and organize the data. Only then does the data become useful. Data also comes in multiple formats. For example, images and videos can hold a lot of data that requires interpretation to extract information from them. The process of reviewing and filtering data for relevant facts is costly in terms of time and resources. This process is also subjective, inconsistent, and error-prone.
Information, in contrast, is a collection of consistently organized and structured facts. Users invest less time and energy finding relevant facts. They can easily find a category of relevance or interest within the information. This makes information more valuable than raw data.
Knowledge is the application of information to answer a question or solve a problem. In other words, information with context or meaning is knowledge. An earlier successful outcome serves as the basis for assigning this context to information. Thus, knowledge depends on the memory of and learning successful outcomes, and so the process of converting information to knowledge is deterministic. Again, this process is costly in terms of time and resources; therefore, knowledge is more valuable than simple information.
When data undergoes data analysis, it becomes more relevant, useful, and valuable. Real-world problems don't have simple solutions: To solve such problems, you must apply information from multiple contexts. Combining data sources helps provide diverse contexts that are useful in real-world problem solving and decision making. In short, data becomes valuable when it meets the following criteria:
- It is available promptly.
- It is concise, well organized, and relevant.
- It has meaning and context based on experience.
- It is an aggregate of multiple data sources.
Data is a valuable commodity when it can reduce the time, effort, and resources required to solve problems and help make sound decisions.
DIKW model variants
Many variants of the DIKW model exist. One variant, proposed by Milan Zeleny in 1987, is DIKWE, which adds an apex layer for enlightenment. Another variant, proposed by Russell Ackoff in 1989, is DIKUW, which adds an intermediate layer for understanding. Some experts model this as DIKIW, where the second I stands for insight or intelligence.
The DIKW model helps us describe methods for problem-solving or decision making. Although developed before the advent of machine learning, it still models many concepts used in data science and machine learning.
Knowledge is the most valuable distillation of data, and although knowledge gives you the means to solve a problem, it doesn't necessarily show you the best way to do so. The ability to pick the best way to reach the desired outcome comes from experience gained in earlier attempts to reach a successful solution.
Wisdom is the ability to pick the best choice leading to a successful outcome. People gain wisdom through experience and knowledge, some of which comes from:
- Developing an understanding of problem-solving methods
- Developing insights by analyzing data and information for a given context
- Gathering intelligence from other people solving the same problems
The many variations of the DIKW model now begin to make sense.
Application to data science and machine learning
You've already seen that when people perform repetitive tasks, those tasks are error-prone, inconsistent, and subjective. You have also noticed that machines do not perform well when dealing with unstructured data. Humans are adept at interpreting unstructured data, evaluating options and risks, and deciding a course of action in split seconds.
A machine running traditional algorithms struggles to do the same in real time primarily because programming becomes increasingly complex. It is time-consuming to evaluate many options and navigate decision trees in a serial manner. Parallel algorithms are an alternative, but they require a lot of processing power. However, even with this added power, these algorithms cannot easily adapt and deal with the uncertainty of real-world problems, especially when data is unstructured.
Neural networks modeled on human brain cells have been around for decades but have suffered from a lack of suitable computer processor architecture to exploit their strengths. The evolution of the graphics processing unit (GPU) architecture for general-purpose computing has allowed neural networks to come into their own. This evolution has led to a surge in the use of machine learning to deal with unstructured data, with considerable success.
Figure 1 shows how you can adapt the DIKW model to data science. The darker layers show the traditional DIKW model; the lighter layers show the processes that lead to the distillation of data to the next-higher layer.
The DIKW model applied to data science
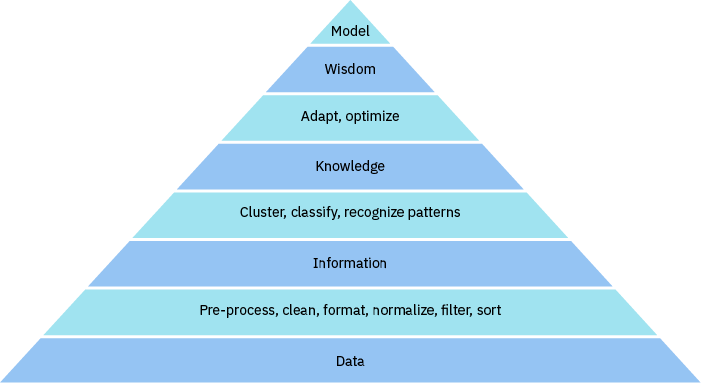
Traditional data science methods can handle the first process layer: converting raw data into information. Machine learning can now help extract knowledge from information. Machine learning algorithms find context in information by recognizing patterns, grouping, or classifying information. Data scientists create machine learning models by using manual optimization and tweaking to achieve the best outcomes, selecting the model best suited to the specific task. However, the advent of deep learning means that machines can perform these tasks autonomously as well.
Deep learning
Deep learning is a specialized subset of machine learning inspired by neuroscience and the working of the human brain. Deep learning algorithms differ from other machine learning algorithms in that they use many layers of several types of neural networks. These layers form a structured hierarchy and, just like a human brain, pass the output of an earlier layer to the next layer.
This cascade of layers gives deep learning networks the ability to learn abstract concepts and perform more complex tasks than simple, single-task pattern recognition and classification. Deep learning algorithms can use both supervised and unsupervised learning and often use a hybrid of these learning methods, an approach that makes them adaptive when used in real-world applications.
When used for real-time speech, image, and video processing applications, deep learning algorithms can deal with the uncertain or incomplete inputs often caused by noisy environmental factors. As a result, they have much better efficiency than simple machine learning algorithms.
Going forward
Data is a valuable commodity — when it can reduce the time, effort, and resources required to solve problems and help us make sound decisions. Machines can efficiently deal with structured data, but 90 percent of all data is unstructured, including texts, emails, images, and video.
Humans are better suited than machines in dealing with unstructured data, but humans are error-prone, inconsistent, and subjective when they perform repetitive tasks, such as extracting information from unstructured data and storing it as structured data (data-entry). The process is also expensive in terms of time, resources, and energy consumption.
The DIKW model helps us understand the process behind the conversion of data into information and knowledge. Machine learning techniques help make the extraction of knowledge easier to perform or even autonomous through adaptation and optimization of successful outcomes. Therefore, deep learning makes it possible to augment data analysis and significantly reduce the time, effort, and resources required to solve problems and help us make sound decisions. Part 2 of this series shows how data lakes help speed up and reduce the costs of data ingestion by allowing storage of large volumes of multiformat data.