Article
Understanding atomic and composite patterns for big data solutions
Explore the logical layers of a big data solutionArchive date: 2022-11-01
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Introduction
Part 3 of this series describes the logical layers of a big data solution. These layers define and categorize the various components that must address the functional and non-functional requirements for a given business case. This article builds on the concept of layers and components to explain the typical atomic and composite patterns in which they are used in the solution. By mapping a proposed solution to the patterns given here, you can visualize how the components need to be designed and where they should be placed functionally. The patterns also help define the architecture of the big data solution. Using atomic and composite patterns can help further refine the roles and responsibilities of each component of the big data solution.
This article covers atomic and composite patterns. The final article in this series will describe solution patterns.
Figure 1. Categories of patterns
Atomic patterns
Atomic patterns help identify the how the data is consumed, processed, stored, and accessed for recurring problems in a big data context. They can also help identify the required components. Accessing, storing, and processing a variety of data from different data sources requires different approaches. Each pattern addresses specific requirements — visualization, historical data analysis, social media data, and unstructured data storage, for example. Atomic patterns can work together to form a composite pattern. There is no layering or sequence to these atomic patterns. For example, visualization patterns can interact with data access patterns for social media directly, and visualization patterns can interact with the advanced analysis processing pattern.
Figure 2. Examples of atomic patterns for consumption, processing, data access, and storage
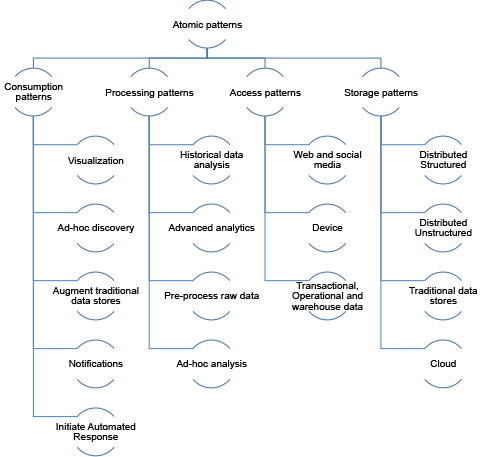
Data consumption patterns
This type of pattern addresses the various ways in which the outcome of data analysis is consumed. This section includes data consumption patterns to meet several requirements.
Visualization pattern
The traditional way of visualizing data is based on graphs, dashboards, and summary reports. These traditional approaches are not always the optimal way to visualize the data.
Typical requirements for big data visualization, including emerging requirements are listed below:
- To do live analysis and display of stream data
- To mine data interactively, based on context
- To perform advanced searches and get recommendations
- To visualize information in parallel
- To have access to advanced hardware for futuristic visualization needs
Research is under way to determine how big data insights can be consumed by humans and machines. The challenges include the volume of data involved and the need to associate context with it. Insight must be presented in the appropriate context.
The goal is to make it easier to consume the data intuitively, so the reports and dashboards might offer full-HD viewing and 3-D interactive videos, and might provide users the ability to control business activities and outcomes from one application.
Ad-hoc discovery pattern
Creating standard reports that suit all business needs is often not feasible because businesses have varied requirements for queries of business data. Users might need the ability to issue ad-hoc queries when looking for specific information, depending on the context of the problem.
Ad-hoc analysis can help data scientists and key business users understand the behavior of business data. Complexity involved in ad-hoc processing springs from several factors:
- Multiple data sources available for the same domains.
- A single query can have multiple results.
- The output can be static with a variety of formats (video, audio, graphs, text).
- The output can be dynamic and interactive.
Augment traditional data stores
During initial exploration of big data, many enterprises would prefer to use the existing analytics platform to keep costs down and to rely on existing skills. Augmenting existing data stores helps broaden the scope of data available for existing analytics to include data that resides inside and outside organizational boundaries, such as social media data, which can enrich the master data. By broadening the scope to include new facts tables, dimensions, and master data in the existing storages, and acquiring customer data from social media, an organization can gain deeper customer insight.
Keep in mind, however, that new data sets are typically larger in size, and existing extract, transform, and load tools might not be sufficient to process it. Advanced tools with massively parallel processing capabilities might be required to address the volume, variety, veracity, and velocity characteristics of data.
Notification pattern
Big data insight enables humans, businesses, and machines to act instantly by using notifications to indicate events. The notification platform must be capable of handling the anticipated volume of notifications to be sent out in a timely manner. These notifications are different from mass mailing or mass sending of SMS messages because the content is generally specific to the consumer. For example, recommendation engines can provide insight on the huge customer base across the world, and notifications can be sent to such customers.
Initiate an automated response pattern
Business insight derived from big data can be used to trigger or initiate other business processes or transactions.
Processing patterns
Big data can be processed when data is at rest or data is in motion. Depending on the complexity of the analysis, the data might not be processed at real time. This pattern addresses how the big data is processed in real time, near real time, or batch.
The following high-level categories for processing big data apply to most analytics. These categories also often apply to traditional RDBMS-based systems. The only difference is the massive scale of data, variety, and velocity. In processing big data, techniques such as machine learning, complex event processing, event stream processing, decision management, and statistical model management are used.
Historical data analysis pattern
Traditional historical data analysis is limited to a predefined period of data, which usually depends on data retention policies. Beyond that period, data is usually archived or purged because of processing and storage limitations. These limitations are overcome by Hadoop-based systems and other equivalent systems with huge storage and distributed, massively parallel processing capabilities. The operational, business, and data warehouse data are moved to big data storage and are processed using the big data platform capabilities.
Historical analysis involves analyzing the historical trends for given period, set of seasons, and products and comparing that to the current data available. To be able to store and process such huge data, tools like HDFS, NoSQL, SPSS®, and InfoSphere® BigInsights™ are useful.
Advanced analytics pattern
Big data provides enormous opportunities to realize creative insights. Different data sets can be co-related in many contexts. Discovering these relationships requires innovative complex algorithms and techniques.
Advanced analysis includes predictions, decisions, inferential processes, simulations, contextual information identifications, and entity resolutions. The application of advanced analytics includes biometric data analysis, for example, DNA analysis, spatial analysis, location-based analytics, scientific analysis, research, and many others. Advanced analytics require heaving computing to manage the huge amount of data.
Data scientists can guide in identifying the suitable techniques, algorithms, data sets, and data sources required to solve problems in a given context. Tools such as SPSS, InfoSphere Streams, and InfoSphere BigInsights provide such capabilities. These tools access unstructured data and the structured data (for example, JSON data) stored in big data storage systems such as BigTable, HBase, and others.
Pre-process raw data pattern
Big data solutions are mostly dominated by Hadoop systems and technologies based on MapReduce, which are out-of-the-box solutions for distributed storage and processing. However, extracting data from unstructured data such as images, audio, video, binary feeds, or even text is a complex task and needs techniques such as machine learning and natural language processing, etc. The other major challenge is how to verify the accuracy and correctness of output from such techniques and algorithms.
To perform analysis on any data, the data must be in some kind of structured format. The unstructured data accessed from various data sources can be stored as is and then transformed into structured data, for example JSON) and stored back in the big data storage systems. Unstructured text can be converted into semi- or structured data. Similarly, image, audio, and video data need to be converted into the formats that can be used for analysis. Moreover, the accuracy and correctness of the advanced analytics that use predictive and statistical algorithms depends on the amount of data and algorithms used to train its models.
The following list shows the algorithms and activities required to convert unstructured data into structured data:
- Document and text classification
- Feature extraction
- Image and text segmentation
- Co-relating the features, variables, and timings and then extracting the values with timing
- Accuracy checking for output using techniques such as the confusion matrix and other manual activities
Data scientists can help in choosing the appropriate techniques and algorithms.
Ad-hoc analysis pattern
Processing ad-hoc queries on big data bring challenges different from those incurred when doing ad-hoc queries on structured data because the data sources and data formats are not fixed and require different mechanisms to retrieve and process the data.
Although simple ad-hoc queries can be resolved by big data providers, in most cases, the queries are complex because data, algorithms, formats, and entity resolutions must be discovered dynamically at runtime. The expertise of data scientists and business users is required to defining the analysis required for the following tasks:
- Identify and discover the computations and algorithms
- Identify and discover the data sources
- Define the required formats that can be consumed by the computations
- Perform the computations on the data in parallel
Access patterns
Although there are many data sources and ways data can be accessed in a big data solution, this section covers the most common.
Web and social media access pattern
The Internet is the source of data that provides many of the insights derived today. Web and social media is useful in almost all analysis, but different access mechanisms are required to acquire this data.
Web and social media is the most complex among all the data sources because of its huge variety, velocity, and volume. There are around 40-50 categories of websites and each requires different treatment to access this data. This section lists these categories and explains the accessing mechanism. The high-level categories from the big data perspective are commerce sites, social media sites, and sites having specific and generic components. See Figure 3 for the access mechanisms. The accessed data is stored in data storage after pre-processing, if required.
Figure 3. Web and social media data access
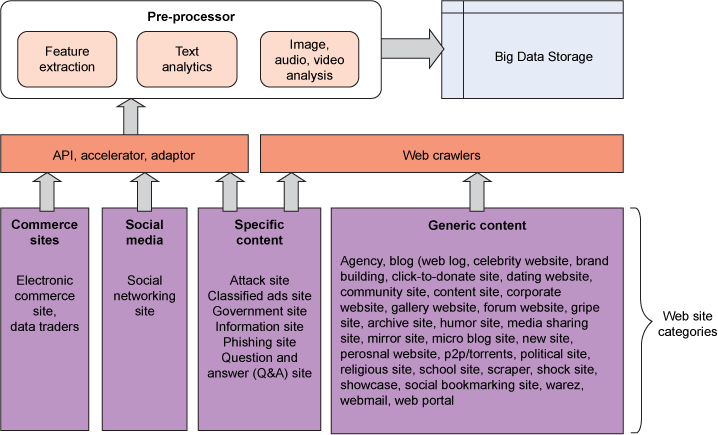
The following steps are required to access web media information.
Figure 4. Big data accessing steps
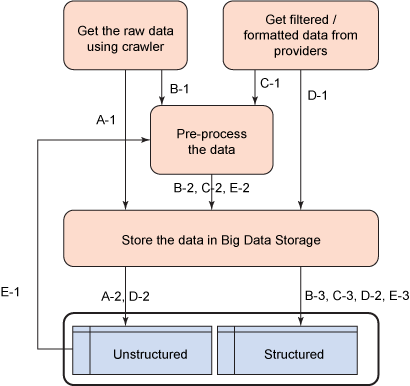
Web media access for data in unstructured storage
- Step A-1. A crawler reads the raw data.
- Step A-2. The data is stored in unstructured storage.
Web media access pre-process data for structured storage
- Step B-1. The crawler reads the raw data.
- Step B-2. This data gets pre-processed.
- Step B-3. The data is stored in structured storage.
Web media access to pre-process unstructured data
- Step C-1. Data from the providers can be unstructured, in rare cases.
- Step C-2. Data is pre-processed.
- Step C-3. Data is stored in structured storage.
Web media access for unstructured or structured data
- Step D-1. Data providers provide structured or unstructured data.
- Step D-2. Data is stored in structured or unstructured storage.
Web media access for pre-process unstructured data
- Step E-1. Unstructured data, stored without pre-processing, cannot be useful unless it is in a structured format.
- Step E-2. Data is pre-processed.
- Step E-3. Pre-processed, structured data is stored in structured storage.
As shown in the diagram, the data can be directly stored in storage, or it can be pre-processed and converted into an intermediate or standard format, then stored.
Before the data can be analyzed, it has to be in a format that can be used for entity resolution or for querying required data. Such pre-processed data can be stored in a storage system.
Although pre-processing is often thought of as trivial, it can be very complex and time-consuming.
Device-generated data pattern
Device-generated content includes data from sensors. Data is sensed from data origins such as weather information, electrical measurements, and pollution data, and is captured by the sensors. The data can be photos, videos, text, and other binary formats.
The following diagram explains the typical process for processing machine generated data.
Figure 5. Device-generated data access
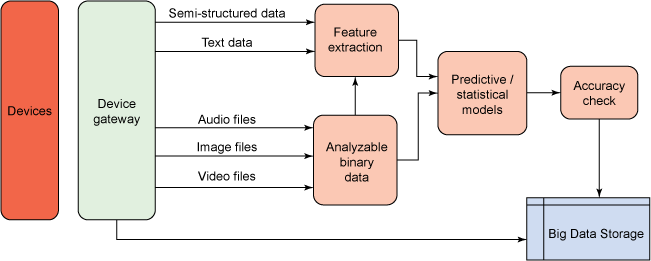
Figure 5 explains the process for accessing data from sensors. The data captured by the sensors can be sent to device gateways that do some initial pre-processing and that buffer the high-velocity data. The machine-generated data is mostly in binary format (audio, video, and sensor reading) or in text format. Such data can be initially stored in a storage system or it can be pre-processed and then stored. The pre-processing is required for analysis.
Transactional, operational and warehouse data pattern
It is possible to store the existing transactional, operational, and warehouse data to avoid purging or archiving data (because of storage and processing limitations), or to reduce the load on the traditional storage storage when the data is accessed by other consumers.
For most enterprises, the transactional, operational, master data, and warehouse information is at the heart of any analytics. This data, if augmented with the unstructured data and the external data available across the Internet or through sensors and smart devices, can help organizations get accurate insight and perform advanced analytics.
Transactional and warehouse data can be pushed into storage using standard connectors made available by various database vendors. Pre-processing transactional data is much easier because the data is mostly structured. Simple extract, transform, and load processes can be used to move the transactional data into storage. Transactional data can be easily converted into the formats like JSON and CSV. Using tools such as Sqoop makes it easier to push transactional data into storage systems such as HBase and HDFS.
Storage patterns
The storage patterns helps to determine the appropriate storage for various data types and formats. Data can be stored as is, stored against key-value pairs, or stored in predefined formats.
Distributed file systems such as GFS and HDFS are quite capable of storing any sort of data. But the ability to retrieve or query the data efficiently affects performance. The selection of technology makes a difference.
Storage pattern for distributed and unstructured data
Most big data is unstructured and can have information that can be extracted in different ways for different contexts. Most of the time, unstructured data must be stored as is, in its original format.
Such data can be stored in distributed file systems such as HDFS and NoSQL document storage such as MongoDB. These systems provide an efficient way to retrieve unstructured data.
Storage pattern for distributed and structured data
Structured data includes data that arrives from the data source and is already in a structured format and unstructured data that has been pre-processed into a formats such as JSON. This converted data must be stored to avoid frequent data conversion from raw data to structured data.
Technologies such as BigTable from Google are used to store structured data. BigTable is a large-scale, fault-tolerant, self-managing system that includes terabytes of memory and petabytes of storage.
HBase in Hadoop is comparable to BigTable. It uses HDFS for underlying storage.
Storage pattern for traditional data stores
Traditional data storage is not the best choice for storing big data, but in cases in which enterprises are doing initial data exploration, they may choose to use the existing data warehouse, RDBMS system and other content stores. These existing storage systems can be used to store the data that is digested and filtered using the big data platform. Do not consider traditional data storage systems as appropriate for big data.
Storage pattern for cloud storage
Many cloud infrastructure providers have distributed structured, unstructured storage capability. Big data technologies are bit different from traditional configurations, maintenance, system management, and programming and modeling perspectives. Moreover, the skills required to implement big data solutions are rare and costly. Enterprises exploring the big data technologies can use cloud solutions that provide big data storage, maintenance, and system management.
The data to be stored is often sensitive; it includes medical records and biometric data. Consider the data security, data sharing, data governance, and other policies around data, especially when considering cloud as a storage repository for big data. The ability to transfer huge amount of data is also another key consideration for cloud storage.
Composite patterns
Atomic patterns focus on providing capabilities required to perform individual functions. Composite patterns, however, are classified based on the end-to-end solution. Each composite pattern has one or more dimensions to consider. There are many variations in the cases that apply to each pattern. Composite patterns map to one or more atomic patterns to solve a given business problem. The list of composite patterns described in this article is based on typically recurring business problems, but this is not a comprehensive list of composite patterns.
Store and explore pattern
This pattern is useful when the business problem demands storing a huge amount of new and existing data that has been previously unused because of lack of adequate storage and analysis capability. The pattern is designed to ease the load on existing data storage. The stored data can be used for initial exploration and ad-hoc discovery. Users can derive reports to analyze the quality of data and its value in further processing. Raw data can be pre-processed and cleaned using ETL tools, before any type of analysis can happen.
Figure 6. Store and explore composite pattern
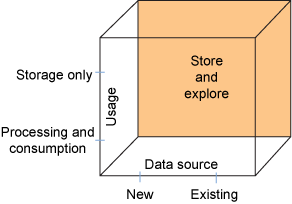
Figure 6 depicts the various dimensions for this pattern. Usage of data could be for the purpose of only storing it or also to process and consume it.
An example of a storage-only case is the situation in which data is just acquired and stored for the future to meet a compliance or legal requirement. The processing and consumption case is for the situation in which the outcome of the analysis can be processed and consumed. Data can be accessed from newly identified sources or from existing data stores.
Purposeful and predictable analysis composite pattern
This pattern is used to perform analysis using various processing techniques and, as a result, may enrich existing data with new insight or create output that can be consumed by various users. The analysis can happen in real time as the events are happening or in batch mode to draw insight based on data that has been gathered. As an example of data at rest that can be analyzed, a telecommunications company might build churn models that include analyzing the call data records, social data, and transaction data. As an example of analyzing data in motion, the need to predict that a given transaction is experiencing fraud must happen in real time or near real time.
Figure 7. Purposeful and predictive analysis composite pattern
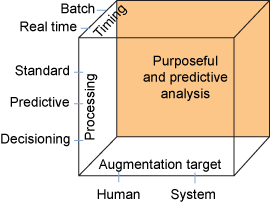
Figure 7 depicts the various dimensions for this pattern. Processing performed could be standard or predictive, and it can include decision-making.
In addition, notifications can be sent to a system or users regarding certain tasks or messages. The notifications can use visualization. The processing can happen in real time or in batch mode.
Actionable analysis pattern
The most advanced form of big data solution is the case in which analysis is performed on the set of data and actions are implied based on the repeatable past actions or on an action matrix. The actions can be manual, partially automated, or fully automated. The base analysis needs to be highly accurate. The actions are predefined and the result of analysis is mapped against the actions. The typical steps involved in actionable analysis are:
- Analyze the data to get the insight.
- Make a decision.
Activate the appropriate channel to take the action to the right consumer.
Figure 8. Actionable analysis composite pattern
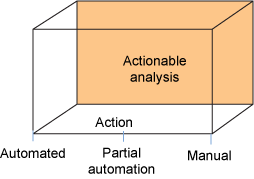
Figure 8 illustrates that the analysis can be manual, partially automated, or fully automatic. It uses the atomic patterns as explained in the diagram.
Manual action means the system recommends the actions based on the outcome of the analysis and the human being decides and carries out the actions. Partial automation means that the actions are recommended by the analysis, but human intervention is not required to set the action in motion or to choose from a set of recommended actions. Fully automated means the actions are executed immediately by the system after the decision is made. For example, a work order may be created by the system automatically after equipment is predicted to fail.
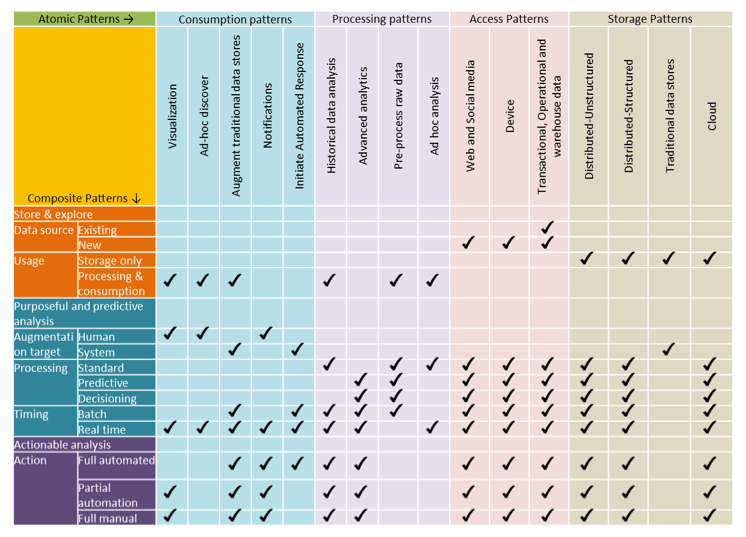
The following matrix shows how the atomic patterns map to the composite patterns, which are combinations of atomic patterns. Each composite pattern is designed to be used in certain situations for data that has a particular set of characteristics. The matrix shows the typical combinations of patterns. The patterns must be tailored to meet specific situations and requirements. In the matrix, the composite patterns are listed in order from simplest to most complex. The "store and explore" pattern is the least complex.
Figure 9. Composite to atomic patterns mapping
Summary
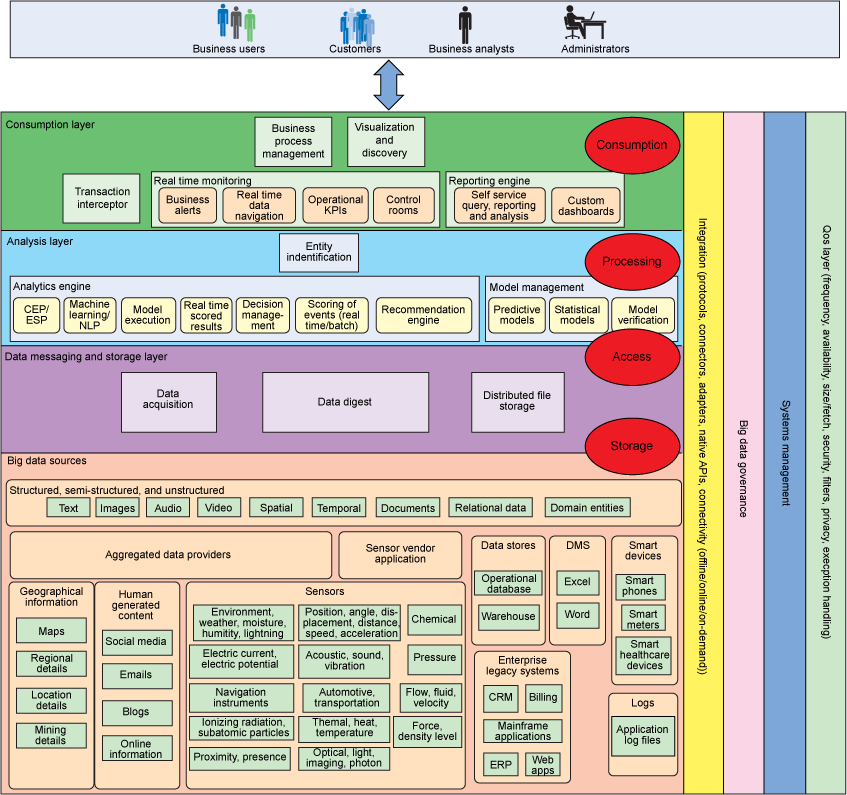
Taking a patterns-based approach can help the business team and the technical team to agree on the primary objective of the solution. Using the patterns, the technical team can define the architectural principles and make some of the key architecture decisions. The technical team can apply these patterns to the architectural layers and derive the set of components needed to implement the solution. Often, the solution starts with a limited scope and evolves as the business becomes more and more confident that the solution will bring value. As this evolution happens, the composite and atomic patterns that align to the solution get refined. The patterns can be used in the initial stages to define a pattern-based architecture and to map out how the components in the architecture will be designed, step by step.
Figure 10. Atomic patterns mapping to architecture layers
In Part 2 of this series, we describe the complexities associated with big data and how to determine if it's time to implement or update your big data solution. In this article, we covered atomic and composite patterns and explained that a solution can be composed of multiple patterns. Given a particular context, you may find that some patterns are more appropriate than the others. We recommend you take an end-to-end view of the solution and examine the patterns involved, then define the architecture of the big data solution.
For architects and designers, mapping to patterns enables further refinement of the responsibilities of each component in the architecture. For business users, it's often helpful to gain a better understanding of the business scope of the big data problem, so that valuable insights can be derived and so the solution meets matches the desired outcome.
Solution patterns further help to define the optimal set of components based on whether the business problem needs data discovery and exploration, purposeful and predictable analysis, or actionable analysis. Remember that there is no recommended sequence or order in which the atomic, composite, or solution patterns must be applied for arriving at a solution. The next article in this series introduces solution patterns for this purpose.