Article
Message compression in Apache Kafka
Why you need compression in your messaging appsNowadays, Apache Kafka carries the lifeblood of an enterprise -- its data or events. As more and more functionality gets supported by Kafka, the amount of data that flows through Kafka increases.
Apache Kafka is unlike the typical traditional messaging systems. Traditional messaging systems "pop out" messages after they are read by consumers. However, Kafka can store data on disk for long periods of time. This is known as "retention period" in Kafka. The longer you retain the data, the more data gets added on the disk, thereby increasing disk space requirements.
Also, Kafka implements replication by default. A common setting for the replication factor in Kafka is 3, which means that for each incoming message 2 copies will be made. The replication factor is once again increasing the disk space requirements.
The disk space requirements for storing Kafka messages take into account these factors:
- Average message size
- Messages per day
- Retention period (days)
- Replication factor
You can compute your disk space requirement as:
`(avg-msg-size) x (msgs-per-day) x (retention-period-days) x (replication-factor)``
For example, let's use these numbers as an example:
- Average message size is 10kb
- Messages per day is 1,000,000
- Retention period is 5 days
- Replication factor is 3
Using our disk space utilization formula:
10 x 1000000 x 5 x 3 = 150,000,000 kb = 146484 MB = 143 GB
Needless to say, when you use Kafka in your messaging solutions, you need to implement some compression on the data, so that you minimize the disk space utilization.
When to use compression
Let's start out by summarizing when you should use Kafka's compression facilities. For example, use Kafka compression when:
- You can tolerate slight delay in message dispatch, as enabling compression increases message dispatch latency.
- Your data which is fairly repetitive like server logs, XML data, JSON messages. These are good candidates since XML and JSON data have repeating field names, server logs have a typical structure, and many of the values in the data are repeated.
- You can spend more CPU cycles to save disk and network bandwidth.
However, Kafka compression is not always warranted. Kakfa compression might not help when:
- The volume of data is not high. Infrequent data might not fill up message batches and that can affect compression ratio. (More on this later.)
- The data is textual, unique-like encoded strings, or base64 payloads. This data might contain unique sequences of characters and it will not compress very well.
- The application is very time critical and you cannot tolerate any delay in message dispatch.
Message Compression in Kafka
Kafka lets you compress your messages as they travel over the wire. This compression process lets you achieve two things:
- Reducing network bandwidth usage.
- Saving disk space on Kafka brokers.
The only tradeoff with these two benefits of compression is slightly higher CPU utilization.
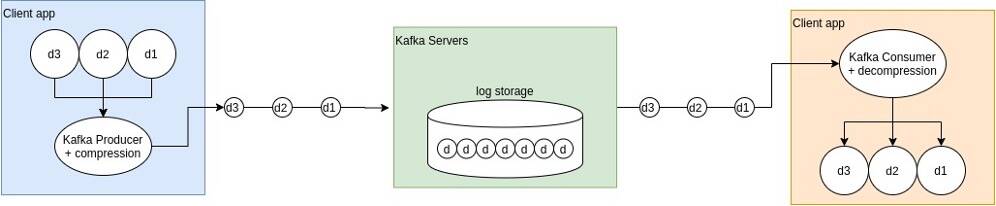
The following diagram is a visual representation of how Kafka compresses messages and how more messages are being stored in the Kafka server due to the compression.
Supported Compression Types in Kafka
Kafka supports four primary types of compression:
- Gzip
- Snappy
- Lz4
- Zstd
Let's take a look into characteristics of these compression types:
| Compression type | Compression ratio | CPU usage | Compression speed | Network bandwidth usage |
|---|---|---|---|---|
| Gzip | Highest | Highest | Slowest | Lowest |
| Snappy | Medium | Moderate | Moderate | Medium |
| Lz4 | Low | Lowest | Fastest | Highest |
| Zstd | Medium | Moderate | Moderate | Medium |
Looking at this table, we can see that Snappy fits in the middle, giving a good balance of CPU usage, compression ratio, speed and network utilization. Zstd is also a very good compression algorithm, providing higher compression ratio at slightly more CPU than Snappy. Zstd is a compression algorithm that was developed at Facebook and has characteristics similar to that of Snappy. However, Zstd is only recently supported in Kafka. You will need to upgrade Kafka if its older than version 2.1.0 to use Zstd compression.
How to enable compression
Kafka supports compression via property compression.type. The default value is none, which means messages are sent un-compressed. Otherwise, you specify the supported types: gzip, snappy, lz4, or zstd.
Broker and Topic level compression settings
We can set compression.type property on either topics or brokers, which means that all messages going to that topic or broker will get compressed by default. You don't need to change your applications.
To set up compression on topic level:
sh bin/kafka-topics.sh --create --topic snappy-compressed-topic --zookeeper localhost:2181 --config compression.type=snappy --replication-factor 1 --partitions 1
Enable compression in Kafka producer applications
For typical java based producer application we need to set producer properties as follows:
kafkaProducerProps.put(“compression.type”, “<compression-type>”);
kafkaProducerProps.put(“linger.ms”, 5); //to make compression more effective
Making Kafka compression more effective
To make Kafka compression more effective, use batching. Kafka producers internally use a batching mechanism to send multiple messages in one batch over the network. When more messages are in a batch, Kafka can achieve better compression because with more messages in a batch there is likely to be more repeatable data chunks to compress. Batching is especially better with entropy-less encoding like LZ4 and Snappy because these algorithms work the best with repeatable patterns in data.
Two main producer properties are responsible for batching:
Linger.ms(default is 0)Batch.size(default is 16384 bytes)
After the Kafka producer collects a batch.size worth of messages it will send that batch. But, Kafka waits for linger.ms amount of milliseconds. Since linger.ms is 0 by default, Kafka won't batch messages and send each message immediately.
The linger.ms property makes sense when you have a large amount of messages to send.
It's like choosing private vehicles over public-transport. Using private vehicles is all good only until the number of people traveling via their own cars is less. As the number of people using their own cars goes on increasing, roads start getting congested. So, in such a case, it is better to use buses to transport more people from point A to B, thereby consuming less space on the road.
Although Avro is a popular serialization format for Kafka messaging, JSON messages are still widely used. They’re easy to use and easy to modify. Overall, JSON messages provide for faster development. One thing about JSON messages is that they have field names repeating all over again throughout your messages. So, if your application uses JSON messages, you should use entropy-less encoders like Snappy and Lz4.
Testing and realizing benefits of Kafka compression
We ran some tests on Kafka compression. We used Kafka 2.0.0 and Kafka 2.7.0. We had 1000 messages in JSON format with an average size of 10 KB, giving us a total payload of 10 MB. We used the Kafka serializer, org.apache.kafka.common.serialization.StringSerializer. We tested all of the compression types.
To check if our messages were actually compressed, we did the following:
- We used Kafka's dump-log-segments tool
- We checked physical disk storage in the Kafka log storage directory
Kafka’s dump-log-segments tool
Kafka provides a tool which can help you inspect log segments in Kafka storage. We can run the tool as follows:
kafka-run-class.bat kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /data/compressed-string-test\00000000000000000000.log | head
The result of this command will be something like this:
offset: 7 position: 15562 CreateTime: 1621152301657 isvalid: true keysize: -1 valuesize: 10460 magic: 2 compresscodec: SNAPPY producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: {"custId":"asdasdasdasdasdasd","dob":"asdasdasdasdasdasd","fname":"asdasdasdasdasdasd","lname":"asdasasdasasdasasdas","nationality"...................
The compresscodec property says that the Snappy codec was used.
Check physical disk storage
Let's check the physical disk storage by going to Kafka's log or message storage directory. You can find this storage directory in the server.properties file on your Kafka server on the logs.dir property.
For example, if our storage directory is /data and our topic name is compressed-string-test, we can check our physical disk usage like so:
du -hsc /data/compressed-string-test-0/*
The results will show something like this:
12K compressed-string-test-0/00000000000000000000.index
6.1M compressed-string-test-0/00000000000000000000.log
4.0K compressed-string-test-0/00000000000000000000.timeindex
4.0K compressed-string-test-0/leader-epoch-checkpoint
6.1M total
For our test we can compare these results with the disk size of an uncompressed topic and find out the compression ratio.
Our test results
The following table shows the average compression ratio of 5 hits for each kind of compression.
| Metrics | Uncompressed | Gzip | Snappy | lz4 | Zstd |
|---|---|---|---|---|---|
| Avg latency (ms) | 65 | 10.41 | 10.1 | 9.26 | 10.78 |
| Disk space (mb) | 10 | 0.92 | 2.18 | 2.83 | 1.47 |
| Effective compression ratio | 1 | 0.09 | 0.21 | 0.28 | 0.15 |
| Process CPU usage % | 2.35 | 11.46 | 7.25 | 5.89 | 8.93 |
From our test results, we can see that Snappy can give us good compression ratio at low CPU usage. However, Zstd also catches up with Snappy. At roughly 20% more CPU and 7% more latency, Zstd gives us about 30% more compression. Gzip gives the highest compression, but it is most expensive of them all both in terms of CPU and latency. Lz4 is the weakest candidate in terms of compression ratio.
Summary and next steps
Based on our own test results, enabling compression when sending messages using Kafka can provide great benefits in terms of disk space utilization and network usage, with only slightly higher CPU utilization and increased dispatch latency. Even with the weakest compression method (Lz4 in our tests), the benefit we achieve is about 70% disk space saving! Other better compression methods can give us even higher disk space savings and consequently higher network bandwidth savings. So, when it comes to saving disk space and avoiding network bandwidth from getting choked when you are witnessing huge data volumes, these trade-offs of slightly higher CPU utilization and increased dispatch latency can be tolerable.