Article
Recurrent neural networks deep dive
Build your own RNNA recurrent neural network (RNN) is a class of neural networks that includes weighted connections within a layer (compared with traditional feed-forward networks, where connects feed only to subsequent layers). Because RNNs include loops, they can store information while processing new input. This memory makes them ideal for processing tasks where prior inputs must be considered (such as time-series data). For this reason, current deep learning networks are based on RNNs. This tutorial explores the ideas behind RNNs and implements one from scratch for series data prediction.
Neural networks are computational structures that map an input to an output based on a network of highly connected processing elements (neurons). For a quick primer on neural networks, you can read another of my tutorials, "A neural networks deep dive," which looked at perceptrons (the building blocks of neural networks) and multilayer perceptrons with back-propagation learning.
In the prior tutorial, I explored the feed-forward network topology. In this topology, shown in the following figure, you feed an input vector into the network through the hidden layers, and it eventually results in an output. In this network, the input maps to the output (every time the input is applied) in a deterministic way.
But, say that you're dealing with time-series data. A single data point in isolation isn't entirely useful because it lacks important attributes (for example, is the data series changing? growing? shrinking?). Consider a natural language processing application in which letters or words represent the network input. When you consider understanding words, letters are important in context. These inputs aren't useful in isolation but only in the context of what occurred before them.
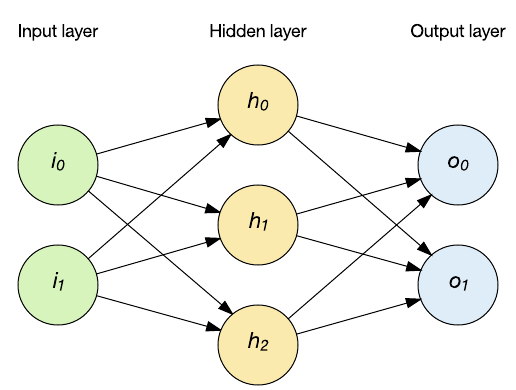
Applications of time-series data require a new type of topology that can consider the history of the input. This is where you can apply RNNs. An RNN includes the ability to maintain internal memory with feedback and therefore support temporal behavior. In the following example, the hidden layer output is applied back into the hidden layer. The network remains feed-forward (inputs are applied to the hidden layer, and then the output layer), but the RNN maintains internal state through context nodes (which influence the hidden layer on subsequent inputs).
RNNs aren't a single class of network but rather a collection of topologies that apply to different problems. One interesting aspect of recurrent networks is that with enough layers and nodes, they are Turing complete, which means that they can implement any computable function.
Architectures of RNNs
RNNs were introduced in the 1980s, and their ability to maintain memory of past inputs opened new problem domains to neural networks. Let's explore a few of the architectures that you can use.
Hopfield
The Hopfield network is an associative memory. Given an input pattern, it retrieves the most similar pattern for the input. This association (connection between the input and output) mimics the operation of the human brain. Humans are able to fully recall a memory given partial aspects of it, and the Hopfield network operates in a similar way.
Hopfield networks are binary in nature, with individual neurons on (firing) or off (not firing). Each neuron connects to every other neuron through a weighted connection (see the following image). Each neuron serves as both the input and the output. At initialization, the network is loaded with a partial pattern, and then each neuron is updated until the network converges (which it is guaranteed to do). The output is provided on convergence (the state of the neurons).

Hopfield networks are able to learn (through Hebbian learning) multiple patterns and converge to recall the closest pattern given the presence of noise in the inputs. Hopfield networks aren't suitable for time-domain problems but rather are recurrent in nature.
Simple recurrent networks
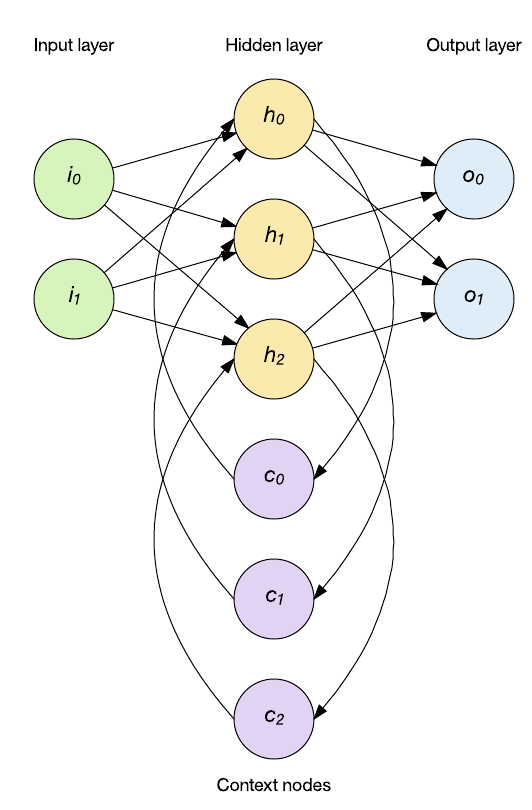
Simple recurrent networks are a popular class of recurrent networks that includes a state layer for introducing state into the network. The state layer influences the next stage of input and therefore can be applied to time-varying patterns of data.
You can apply statefulness in various ways, but two popular approaches are the Elman and Jordan networks (see the following image). In the case of the Elman network, the hidden layer feeds a state layer of context nodes that retain memory of past inputs. As shown in the following figure, a single set of context nodes exists that maintains memory of the prior hidden layer result. Another popular topology is the Jordan network. Jordan networks differ in that instead of maintaining history of the hidden layer they store the output layer into the state layer.
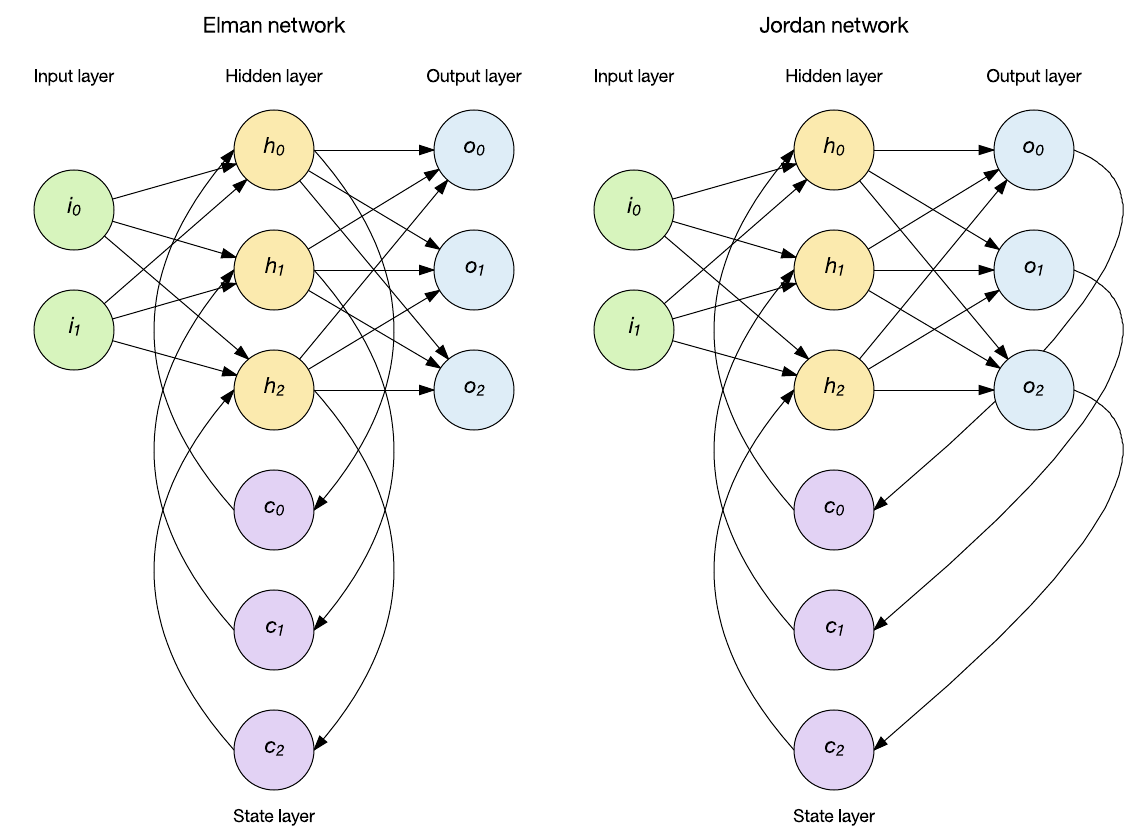
Elman and Jordan networks can be trained through standard back-propagation, and each has been applied to sequence recognition and natural language processing. Note here that a single state layer has been introduced, but it's easy to see that you could add state layers where the state layer output acts as the input for a subsequent state layer. I explore this idea in the context of the Elman network later in this tutorial.
Other networks
Work on recurrent-style networks has not stopped, and today, recurrent architectures are setting the standard for operating on time-series data. The long short-term memory (LSTM) approach in deep learning has been used with convolutional networks to describe in generated language the content of images and videos. The LSTM includes a forget-gate that lets you "train" individual neurons about what's important and how long it will remain important. LSTM can operate on data where important events can be separated by long periods of time.
Another recent architecture is called the gated recurrent unit (GRU). The GRU is an optimization of the LSTM that requires fewer parameters and resources.
RNN training algorithms
RNNs have unique training algorithms because of their nature of incorporating historical information in time or sequence. Gradient descent algorithms have been successfully applied to RNN weight optimization (to minimize the error by adjusting the weight in proportion to the derivative of the error of that weight). One popular technique is back-propagation through time (BPTT), which applies weight updates by summing the weight updates of accumulated errors for each element in a sequence, and then updating the weights at the end. For large input sequences, this behavior can cause weights to either vanish or explode (called the vanishing or exploding gradient problem). To combat this problem, hybrid approaches are commonly used in which BPTT is combined with other algorithms such as real-time recurrent learning.
Other training methods can also be successfully applied to evolving RNNs. Evolutionary algorithms can be applied (such as genetic algorithms or simulated annealing) to evolve populations of candidate RNNs, and then recombine them as a function of their fitness (that is, their ability to solve the given problem). Although not guaranteed to converge on a solution, they can be successfully applied to a range of problems, including RNN evolution.
One useful application of RNNs is the prediction of sequences. In the following example, I build an RNN that I can use to predict the last letter of a word given a small vocabulary. I'll feed the word into the RNN, one letter at a time, and the output of the network will represent the predicted next letter.
Genetic algorithm flow
Before jumping into the RNN example, let's look at the process behind genetic algorithms. The genetic algorithm is an optimization technique that is inspired by the process of natural selection. As shown in the following figure, the algorithm creates a random population of candidate solutions (called chromosomes) that encode the parameters of the solution being sought. After they are created, each member of the population is tested against the problem and a fitness value assigned. Parents are then identified from the population (with higher fitness being preferred) and a child chromosome created for the next generation. During the child's generation, genetic operators are applied (such as taking elements from each parent [called crossover] and introducing random changes into the child [called mutation]). The process then begins again with the new population until a suitable candidate solution is found.

Representing neural networks in a population of chromosomes
A chromosome is defined as the individual member of the population and contains an encoding for the particular problem to be solved. In the context of evolving an RNN, the chromosome is made up of the weights of the RNN, as shown in the following figure.
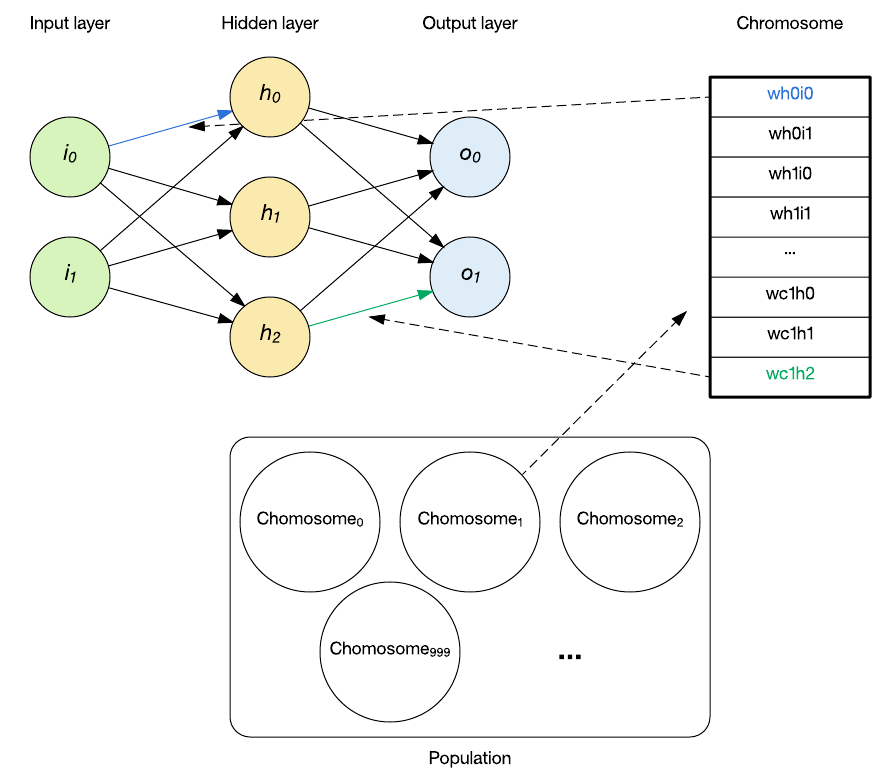
Each chromosome contains a 16-bit value per weight. The value, in the range 0 - 65535, is converted to a weight by subtracting half the range, and then multiplying it by 0.001. This means that the encoding can represent values in the range -32.767 to 32.768 in increments of 0.001.
The process of taking a chromosome from the population and generating an RNN is simply defined as initializing the weights of the network with the translated weights from the chromosome. In this example, this represents 233 individual weights.
Letter prediction with RNNs
Now, let's explore the application of letters to a neural network. Neural networks operate on numerical values, so some representation is required to feed a letter into a network. For this example, I use one-hot encoding. One-hot encoding converts a letter into a vector in which a single element of the vector is set. This encoding creates a distinct feature that can be used mathematically—for example, each letter represented gets its own weight applied within the network. While in this implementation, I represent letters through one-hot; natural language processing applications represent words in the same fashion. The following figure illustrates the one-hot vectors used in this example and the vocabulary used for testing.

So, now I have an encoding that will allow my RNN to work with letters. Now, let's look at how this works in the context of the RNN. The following figure illustrates the Elman-style RNN in the context of letter prediction (feeding the one-hot vector representing the letter b). For each letter in the test word, I encode the letter as a one-hot, and then feed it as the input to the network. The network is then executed in a feed-forward fashion, and the output is parsed in a winner-takes-all fashion to determine the winning element that defines the one-hot vector (in this example, the letter a). In this implementation, only the last letter of the word is checked; other letters are ignored from being validated, nor are they part of the fitness calculation.

Simple Elman-style RNN implementation
Let's look at the sample implementation of an Elman-style RNN trained through a genetic algorithm. You can find the Linux source code for this implementation at GitHub. The implementation is made up of three files:
- main.c, which provides the main loop and a function to test and derive the fitness of a population
- ga.c, which implements the genetic algorithm functions
- rnn.c, which implements the actual RNN
I focus on two core functions: the genetic algorithm process and the RNN evaluation function
The meat of the RNN is found in the RNN_feed_forward function, which implements the execution of the RNN network (see the following code). This function is split into three stages and mirrors the network shown in the previous image. In the first stage, I calculate the outputs of the hidden layer, which incorporates the input layer and the context layer (each with its own set of weights). The context nodes are initialized to zero before testing a given word. In the second stage, I calculate the outputs of the output layer. This step incorporates each hidden layer neuron with its own distinct weights. Finally, in the third stage, I propagate the first context-layer neuron to the second context-layer neuron and the hidden-layer output to the first context node. This step implements the two layers of memory within the network.
Note that in the hidden layer, I use the tan function as my activation function and the sigmoid function as the activation function in the output layer. The tan function is useful in the hidden layer because it has the range -1 to 1 (allowing both positive and negative outputs from the hidden layer). In the output layer, where I'm interested in the largest value to activate the one-hot vector, I use the sigmoid because its range is 0 to 1.
void RNN_feed_forward( void )
{
int i, j, k;
// Stage 1: Calculate hidden layer outputs
for ( i = 0 ; i < HIDDEN_NEURONS ; i++ )
{
hidden[ i ] = 0.0;
// Incorporate the input.
for ( j = 0 ; j < INPUT_NEURONS+1 ; j++ )
{
hidden[ i ] += w_h_i[ i ][ j ] ∗ inputs[ j ];
}
// Incorporate the recurrent hidden.
hidden[ i ] += w_h_c1[ i ] ∗ context1[ i ];
hidden[ i ] += w_h_c2[ i ] ∗ context2[ i ];
// apply tanh activation function.
hidden[ i ] = tanh( hidden[ i ] );
}
// Stage 2: Calculate output layer outputs
for ( i = 0 ; i < OUTPUT_NEURONS ; i++ )
{
outputs[ i ] = 0.0;
for ( j = 0 ; j < HIDDEN_NEURONS+1 ; j++ )
{
outputs[ i ] += ( w_o_h[ i ][ j ] ∗ hidden[ j ] );
}
// apply sigmoid activation function.
outputs[ i ] = sigmoid( outputs[ i ] );
}
// Stage 3: Save the context hidden value
for ( k = 0 ; k < HIDDEN_NEURONS+1 ; k++ )
{
context2[ k ] = context1[ k ];
context1[ k ] = hidden[ k ];
}
return;
}
I implement my genetic algorithm in the following code example. You can view this code in three parts. The first part calculates the total fitness of the population (used in the selection process) and also the most fit chromosome in the population. The most fit chromosome is used in the second part, which simply copies this chromosome to the next population. This is a form of elitist selection, where I maintain the most fit chromosome through to the next population. The population consists of 2,000 chromosomes.
In the final part of the genetic algorithm, I randomly select two parents from the population and create a child from them for the new population. The selection algorithm is based on what's called roulette wheel selection, where chromosomes are selected at random but more fit parents are selected at a higher rate. After two parents have been selected, they are recombined into a child chromosome for the next population. This process includes the potential for crossover (where one of the parents' genes are selected for propagation) and also mutation (where a weight can be randomly redefined). This process occurs with low probability (one mutation per recombination and slightly less for crossover).
void GA_process_population( unsigned int pop )
{
double sum = 0.0;
double max = 0.0;
int best;
int i, child;
best = 0;
sum = max = population[ pop ][ best ].fitness;
// Calculate the total population fitness
for ( i = 1 ; i < POP_SIZE ; i++ )
{
sum += population[ pop ][ i ].fitness;
if ( population[ pop ][ i ].fitness > max )
{
best = i;
max = population[ pop ][ i ].fitness;
}
}
// Elitist ‑‑ keep the best performing chromosome.
recombine( pop, best, best, 0, 0.0, 0.0 );
// Generate the next generation.
for ( child = 1 ; child < POP_SIZE ; child++ )
{
unsigned int parent1 = select_parent( pop, sum );
unsigned int parent2 = select_parent( pop, sum );
recombine( pop, parent1, parent2, child, MUTATE_PROB, CROSS_PROB );
}
return;
}
Sample execution
You can build the sample source code at GitHub in Linux simply by typing make, and then executing with ./rnn. Upon execution, the population is randomly created, and then natural selection occurs over some number of generations until a solution is found that accurately predicts the last character of the entire test vocabulary or the simulation fails to converge on a solution properly. Success or failure is determined by average fitness; if it reaches 80% of the maximum fitness, then the population lacks sufficient diversity to find a solution and will exit.
If a solution is found, the code will emit the entire test vocabulary and show the prediction of each word. Note that chromosome fitness is based only on the final letter of a word, so internal letters are not predicted. The following code provides a sample of the successful output.
$ ./rnn
Solution found.
Testing based
Fed b, got s
Fed a, got b
Fed s, got e
Fed e, got d
Testing baned
Fed b, got s
Fed a, got b
Fed n, got d
Fed e, got d
Testing sedan
Fed s, got s
Fed e, got d
Fed d, got s
Fed a, got n
...
Testing den
Fed d, got d
Fed e, got n
Testing abs
Fed a, got d
Fed b, got s
Testing sad
Fed s, got s
Fed a, got d
The graph of the average and maximum fitness is shown in the following figure. Note that each graph begins at a fitness level of ~13. Twelve of the words end in d, so a network simply emitting d for any letter sequence has that level of success. However, moving forward the weights must evolve to consider prior letters to accurately predict for the given vocabulary. As shown, more than half of the generations are required to predict the last test case in the successful run.

An interesting note is that each graph demonstrates a theory in evolutionary biology called punctuated equilibria, a phenomenon characterized by long periods of stasis (general stability) punctuated by a burst of evolutionary change. In one case, it resulted in getting stuck in a local minimum; in the other, evolution was successful (global maximum).
Going further
Traditional neural networks provide the ability to map an input vector to an output vector in a deterministic way. For a large set of problems, this is ideal, but when sequences or time-series data must be considered, introducing internal memory to a network can allow it to consider prior data when making a decision about its output. RNNs introduce feedback into traditional feed-forward networks so that they include one or more levels of memory. RNNs represent a foundational architecture for the future and can be found in the most advanced technologies in deep learning, such as LSTM and GRU.