Article
Supervised learning models
Explore some supervised learning approaches such as support vector machines and probabilistic classifiersSupervised learning is a method by which you can use labeled training data to train a function that you can then generalize for new examples. The training involves a critic that can indicate when the function is correct or not, and then alter the function to produce the correct result. Classical examples include neural networks that are trained by the back-propagation algorithm, but many other algorithms exist. This tutorial explores some of the other approaches such as support vector machines (SVMs) and probabilistic classifiers (naïve Bayes) in learning applications.
In supervised learning, you create a function (or model) by using labeled training data that consists of input data and a wanted output. The supervision comes in the form of the wanted output, which in turn lets you adjust the function based on the actual output it produces. When trained, you can apply this function to new observations to produce an output (prediction or classification) that ideally responds correctly.
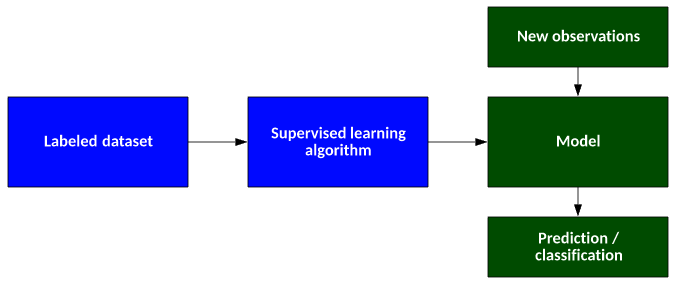
As shown in Figure 1, the supervised learning algorithm uses a labeled data set to produce a model. You can then use this model with new data to validate the model's accuracy or in production with live data.
Figure 1. A typical supervised learning algorithm
Support vector machines
SVMs are a popular supervised learning model that you can use for classification or regression. This approach works well with high-dimensional spaces (many features in the feature vector) and can be used with small data sets effectively. When the algorithm is trained on a data set, it can easily classify new observations efficiently. It does this by constructing one or more hyperplanes to separate the data set between two classes.
Note: Recall that a hyperplane is a subspace whose dimension is 1 less than the feature space. So, given a space that is defined by a feature vector of size 3, the hyperplane is a two-dimensional (2D) plane that intersects that space.
Dimensionality
What makes the SVM model unique is its approach to separating the data set. Analyzing data that is highly dimensional can be problematic, so much so that Richard Bellman coined the phrase the "curse of dimensionality." This curse refers to several phenomena that appear with highly dimensional data. In the context of machine learning, Gordon Hughes found that smaller data sets described by a highly dimensional feature space suffered because the predictive power decreased as the dimensionality increased, the result of a lack of data that covers all features and all possible feature values.
Rather than rely on dimensionality reduction, SVM actually increases the dimensionality of the feature space to properly separate it. Let's look at a simple example.
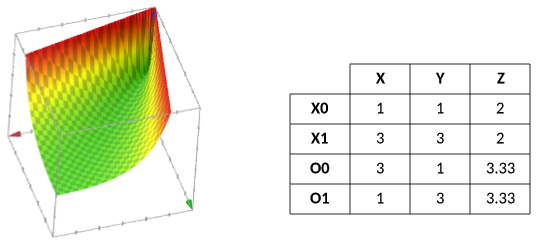
Consider a simple data set that consists of four samples of two classes (X and O). Each sample represents a 2D feature vector, and it's clear from the graph in Figure 2 that a hyperplane (a line for a 2D space) cannot separate the samples. This data set is not linearly separable.
Figure 2. A simple data set with two classes

SVM solves the linearity problem by adding a feature to the feature vector (called a classifier) computed as a function of the other existing feature vectors. So, from a data set that you can visualize in two dimensions, you get a new data set that exists in three dimensions. (I chose a contrived function to demonstrate how SVM chooses its classifiers.)
Figure 3 shows this classifier function and the computed classifier (z). As shown in the three-dimensional (3D) plot, the X samples exist in the trough of the function (its distinct lows), while the O samples exist on the upper sides of the function. Looking at the z values, it's clear now that you can separate the two classes through a hyperplane in the z dimension (specifically, at z = 2.665).
Figure 3. A classifier function and the computed classifier
So, by adding a feature within the feature vector (or a third dimension, as demonstrated here for visualization), you change the feature space and permit a simple segregation of the data.
Kernel functions
This was a contrived example, but SVM can do what it does in a few different ways. The goal of the classifier is to find what's called the maximum-margin hyperplane that divides the observations to maximize the distance between the hyperplane and the nearest point from each class. This latter constraint is called the maximum-margin. The observations that make up the nearest points in each class are called the support vectors (because they support the boundary of the hyperplane). Finding the maximum margin is important because the resulting hyperplane is less likely to result in overfitting (where the model corresponds too closely to a particular set of data).
This technique is called the kernel trick—that is, applying a function to turn a lower dimensional space into a higher dimensional space. SVM uses various kernels (similarity functions) depending on the data, such as the dot product (linear kernel) and the radial basis function. Given a data set with many features, it's not immediately clear which kernel function is best for transforming the nonlinear space into a linear space. Therefore, SVMs commonly implement multiple kernel functions so that it can try multiple kernels to identify the best option.
Naïve Bayes classifiers
Naïve Bayes is a method that permits the construction of classifiers in a simple and straightforward way. One interesting feature of naïve Bayes is that it works well with very small data sets. Naïve Bayes classifiers exploit certain assumptions about the data—namely, that all attributes are independent—but even with this simplification, you can successfully apply the algorithm to complex problems. Let's first look at Bayes theorem, and then we'll work through a simple classification problem.
Bayes theorem
Bayes theorem, illustrated in Figure 4, provides a way to determine the probability of an event based on prior knowledge of conditions that might be related to the event. It says that the probability of a target (c) given a predictor (x, called the posterior probability) can be calculated from the probability of the predictor given the class (called likelihood) multiplied by the prior probability of the class that is divided by the prior probability of the predictor (sometimes called the evidence).
Figure 4. Bayes theorem
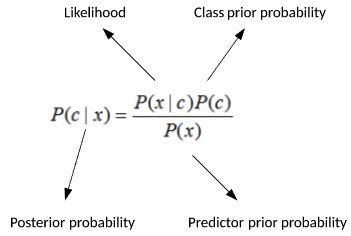
Put more simply, Bayes theorem permits the calculation of conditional probabilities of some event given prior evidence (target c occurs given that a prior event x occurred). For example, given a collected data set, you could use Bayes to identify the probability that it will rain given other attributes (such as whether it's overcast or sunny).
Bayes through example
Let's dig into this theorem through an example. Here in Colorado, one of our biggest winter pastimes is snow sports. However, not every day is a great day to ski. In Figure 5, I've listed 15 observations of weather and temperature and whether it was a ski day. For weather, it might be sunny, windy, or snowing; for temperature, it's either cold or freezing. My dependent variable is the ski class, which is represented as yes or no. Given a set of conditions, I want to identify whether I should ski. At the right side of this figure is the class probability, represented by the counts of each class (how many instances of yes or no occur in the data set).
Figure 5. Simple table of weather conditions for skiing

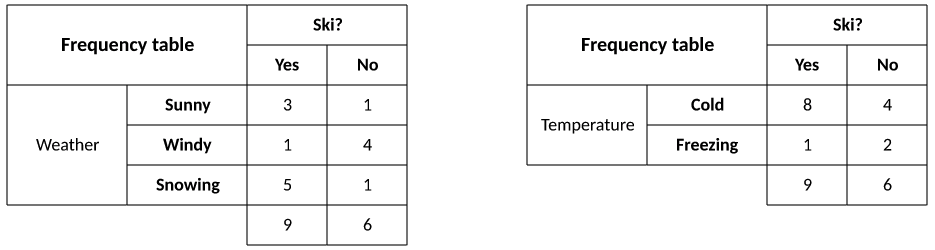
Next, I build frequency tables from the data set (that is, the individual probabilities for weather and temperature). For each feature attribute, I count and sum the occurrences of each feature for the given class (P(c) or Yes/No). This table is shown in Figure 6.
Figure 6. Frequency tables for the data set
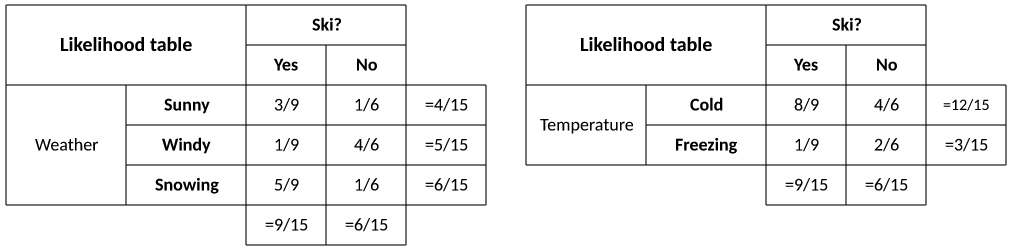
From this table, I can see the frequencies for each event given the target.
Next, I translate my frequency tables into likelihood tables (P(x|c)). From the table in Figure 7, I can see that, independent of all other variables, if it's sunny, I'll ski with a probability P(3/9) and not ski with a probability of P(1/6). I could also write this as P(Weather=Sunny | Ski=Yes) = 3/9 and P(Weather=Sunny | Ski=No) = 1/6.
Figure 7. Likelihood tables
Now, I have everything that I need to apply Bayes and predict the probability of a class (whether I'll go skiing) given a set of weather conditions. So, say that I want to know if I'll ski if it's snowing and freezing. I write this equation as P(Yes | Weather=Snowing & Temperature=Freezing).
I start by collecting the data for the likelihood (P(x | c) and the class probability (P(c)). These values came directly out of the likelihood table. So, for the P(Yes) side, I multiply P(Snowing|Yes) with P(Freezing|Yes) and P(Ski=Yes), which gives me the numerator of my equation.
The final step is to calculate the denominator (P(x), or the evidence). This calculation is the same for both classes, so I calculate it once. This step normalizes the result. So, P(Snowing) is 5+1/15 (6/15) and P(Freezing) is 1+2/15 (3/15). Figure 8 shows this calculation.
Figure 8. Calculating the denominator

The final step is to calculate the probabilities by using the numerator and denominators I just computed. Given my sample data set, I take the largest of the probabilities for conditions x, which leads to my answer (I most likely would ski).
Naïve Bayes makes it easy to predict a class for a set of conditions from a data set and can perform better than some models. The approach does assume that predictors are independent, which doesn't always hold for real-world problems.
AdaBoost
Adaptive boosting (AdaBoost) is a meta-algorithm that you can apply to machine learning algorithms to improve their performance. AdaBoost is adaptive in that classifiers are tweaked in favor of miscalculations from previous classifiers. AdaBoost works by combining multiple "weak classifiers" into a single "strong classifier," where weak classifiers are better than random classification and the strong classifier incorporates the output of all weak classifiers. Each weak learner is assigned a weight based on its accuracy. The more accurate a weak learner, the higher the weight assigned to it.
AdaBoost also alters the distribution of training samples to the classifiers. Samples in the training set are assigned weights, and the higher the weight, the more likely it will appear in training to a classifier. Each classifier is trained with a random subset of the total training data, which can include some overlap. Training samples that are not properly classified are increased in weight so that they appear in larger part in the next training iteration (in an attempt to properly train for them in the future, see Figure 9).
Figure 9. A typical AdaBoost example
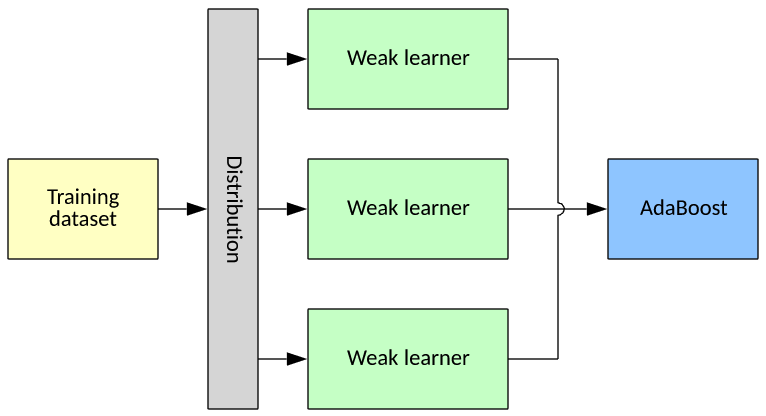
AdaBoost can be defined as an ensemble method because it serves as a meta-algorithm over a collection of other supervised learning algorithms. Because the training set is fractionally distributed to the weak learners, each weak learner can focus on one or more features of the data (as a function of the distribution).
So, by assigning more weight to weak learners given their ability to properly classify a data set (or a subset thereof) and assigning a subset of the overall data set to those weak learners to allow them to focus on a subset of the features, AdaBoost optimizes and improves the accuracy of other supervised learning algorithms.
Going further
This tutorial explored three important methods of supervised learning: SVMs, naïve Bayes classifiers, and AdaBoost. First, it discussed SVMs in the context of their ability to increase the dimensionality of a feature space to convert a nonlinear problem into a linearly separable one. It also ventured into probabilistic classifiers that use the naïve Bayes theorem, which relies on strong independence assumptions between features but nonetheless is a useful and powerful method for implementing classification. Finally, this tutorial explored a boosting technique that is called AdaBoost, which relies on multiple independent classifiers and a weighting scheme that distributes the data set to classifiers, and then weights them according to their accuracy. There's more to supervised learning than the ever-present neural network.