Article
Apply the Strangler Fig Application pattern to microservices applications
How to get microservices to work with your real-world appsIf you’re like me, you’re constantly reading articles and blogs about new development tools, new development and operations practices, or new architectural principles. The problem is that too often, the practices or architectural principles might look great on paper, or perhaps would work out fine if you were to implement them in a brand new (greenfield) application, but it’s not quite as clear how you would implement them in an existing application.
However, we live in a world where brownfield applications—existing apps that were not built according to all the latest approaches, or using the latest tools—are more common. This is particularly true of the microservices architecture. Most of the development teams I talk to think microservices sound like a great idea, but they’re not sure how they can start using them since they are currently working with huge monolithic applications.
Thus, it’s great when you come across a solution that’s really helpful in situations like this, and that’s true of Martin Fowler’s Strangler Fig Application pattern. And even though he wrote it prior to the development of the microservices architecture, this pattern offers excellent guidance to teams that want to move to a microservices approach.
What is the Strangler Fig Application pattern?
In a 2004 article on his website, Martin Fowler defined the Strangler Fig Application pattern as a way of handling the release of refactored code in a large web application.
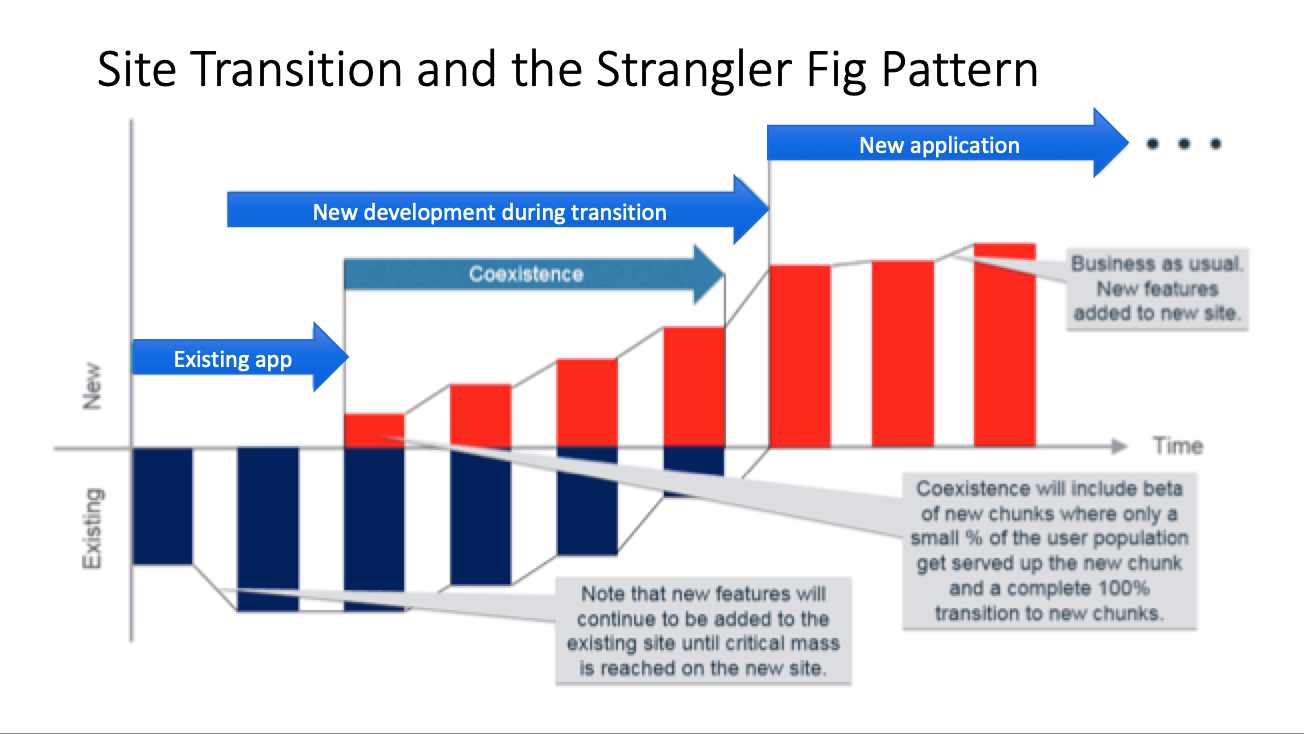
The Strangler Fig Application is based on an analogy to a vine that strangles a tree that it’s wrapped around. The idea is that you use the structure of a web application—the fact that web apps are built out of individual URIs that map functionally to different aspects of a business domain—to divide an application into different functional domains, and replace those domains with a new microservices-based implementation one domain at a time. This creates two separate applications that live side-by-side in the same URI space. Over time, the newly refactored application “strangles” or replaces the original application until finally you can shut off the monolithic application altogether. Thus, the Strangler Fig Application pattern steps are transform, coexist, and eliminate:
Transform—Create a parallel new site (for example, in IBM Cloud or even in your existing environment) but based on more modern approaches.
Coexist—Leave the existing site where it is for a time. Redirect from the existing site to the new one so the functionality is implemented incrementally.
Eliminate—Remove the old functionality from the existing site (or simply stop maintaining it) as traffic is redirected away from that portion of the old site.
The great thing about applying this pattern is that it creates incremental value in a much faster timeframe than if you tried a “big bang” migration in which you update all the code of your application before you release any of the new functionality. It also gives you an incremental approach for adopting microservices—one where, if you find that the approach doesn’t work in your environment, you have a simple way to change direction if needed.
When does the pattern work and when does it not work?
Of course, you can't assume that a pattern will apply to every situation. There are a few prerequisites that must be in place in order for this approach to be successful:
Web- or API-based monolith: This is the first requirement. The whole purpose of the Strangler Fig Application pattern is that you have to have a way of easily moving back and forth between new and old functionality. If you’re working with a web application, then the URL structure of that app gives you a framework for choosing what parts of the system are implemented in which way. On the other hand, thick client applications or similar native mobile applications are not as well suited to this approach since they don’t necessarily have a structure that allows you to pull the application apart in the same way.
Standardized URL structure (true use of URLs): Even though web applications all work according to some standards imposed by the structure of the web (such as the use of HTTP and HTML), there are many different application architectures that can be used to implement those web applications. However, there is still a lot of leeway within this approach. For instance, when there is an intermediate layer underneath the server requests (as with a portal approach), you may have a problem if you are using URLs to divide the application up; the decision for switching and routing isn’t made at the browser level, but deeper in the application, which is more complicated.
Meta UIs: When the UI is a “meta” UI (such as when it is business-process based or it is constructed on the fly), the approach will still work, but the chunk is larger and must be implemented all at once. That’s because you have to rework either the entire generation framework or, at the very least, all of those places that interact with your current, non-microservices-based business model.
How not to apply the pattern
Just as there are cases where the pattern applies, there are likewise cases where it does not apply—or at least does not apply easily. These cases include:
Don’t apply it one page at a time: The smallest sliver is a single microservice. You want to avoid having two different data access methods for your data at the same time to avoid consistency problems.
Don’t apply it all at once: If you do your entire application at one time you’re not really applying the Strangler Fig Application pattern, are you?
A release process for Strangler microservices
In the IBM Garage Method, we use concepts from agile methods to help us organize our work. For example, a hill (or an MVP definition) is broken down through the inception process into user stories that represent individual implementable elements of the MVP. Related user stories are grouped into epics that describe higher levels of system functionality.
That brings us back to the challenge of gradual system replacement through the Strangler Fig Application pattern. Epics are grouped together into chunks that that are tied together either by implementation restrictions or user-experience relationships that become initial large-scale rollout units. In most cases, a chunk is bounded by a UI flow that defines a user task, and all the parts within that flow are implemented in a consistent way.
Squads implement epics: A single squad might implement one or more epics within a chunk, but the smallest element of implementation responsibility for a squad is an epic. The squad adds the user stories that define that epic to an ongoing ranked backlog of prioritized uUser stories for implementation.
However, a chunk is a pretty big rollout unit when you’re trying to receive intermediate feedback from a set of sponsor users. Therefore, we define a smaller release element that can be used internally to gain that feedback. A sliver is the smallest releasable unit that incorporates a microservice and the changes that surround the microservice to make it usable to the end user. So even though a chunk may be an entire flow for booking a ticket on a bus or an airplane and all of the microservices needed to implement that flow, a sliver may be a single page within that flow that represents a step such as showing the confirmation of the ticket booking, plus the microservice needed to retrieve that confirmation. So your chunk would be made up of slivers that are continuously released and made available in a limited way for feedback, but only released to the end user when the entire task represented by the chunk is workable.
How to apply the pattern
You have to interleave two different aspects of your application refactoring: refactoring your back end to the microservices design (the inside part), and refactoring your front end to accommodate the microservices and to make any new functional changes that are driving the refactoring (the outside part).
Inside part
Identify the bounded contexts in your application design. A bounded context is a shared conceptual framework that constrains the meaning of a number of entities within a larger set of business models. In an airline application, flight booking would be one bounded context, while the airline loyalty program would be a different bounded context. Although they may share terms (such as “flight”), the way in which those terms are used and defined can be quite different.
Choose the bounded context that is the smallest and least costly to refactor. Rank your other bounded contexts in order of complexity from least complex to most complex. You’ll want to start with the least complex bounded contexts in order to prove out the value of your refactoring (and shake out any problems in adopting the process) before you take on the more complex (and potentially costly) refactoring tasks.
Conceptually plan out the microservices within the context. You plan out a rough URL structure and overall responsibility of your microservices by applying the entity, aggregate, and service patterns from Evans. Note that at this point, we’re not actually trying to do a detailed design of all of these microservices! We’re just trying to get an understanding of which microservices likely exist so that we can use that “guess” in the next set of steps. Another helpful technique to apply is to perform an Event Storming Workshop. Through the process of event storming, you can usually derive a first-pass set of microservices for any particular sub-domain relatively quickly.
Outside part
Analyze the relationships between the screens in your existing UI. What you don’t want to do is to separate screens in a common flow into different UI paradigms. Keep related things together—cohesion generally applies to UI design in the same way it applies to services and object design.
Apply the principle of least astonishment to the related aspects of the model manipulation. The "principle of least astonishment" is an idea from Kent Beck that simply says “Do whatever astonishes your users the least.” Ask yourself: What are the aspects of your UI that correspond to the microservices identified in the Inside part? Those are the ones to focus on initially—they are probably the most important concepts to the user as well as to the software architect.
Size your chunk (group of related epics) based on the assumption that the UI changes must be self-consistent. This is where the rubber meets the road—it may mean that your first release is significantly larger than a single microservice—if that is what is needed for the UI journey to be consistent to the user—for it to meet the principle of least astonishment—then that is what you need to do.
Choose whether to release an entire chunk at a time, or each chunk as a series of slivers. UI-related changes may require you to release an entire chunk at once, but if your changes are entirely contained to the back-end, then you may be able to release it as a series of individual slivers instead. So, for instance, if you already have a front-end that is based on a single page architecture, and what you are doing is simply pulling microservices out of a monolithic architecture, you may need to cut it into slivers based on how you can refactor the database that all the services in the initial monolith shared. So for instance, you may want to pull out slivers related to querying before you pull out slivers related to updating.
Over time what happens is that as you release new chunks, you shut off the traffic to the old chunks, resulting in a phased reimplementation of the site’s functionality.
Conclusion
In this article, I’ve shown you a few of the ramifications of applying the Strangler Fig Application pattern—when it applies, when it doesn’t, and what it means for release management. I’ve also introduced a couple of new terms that we use in our consulting practice in the IBM Cloud Garage and that I hope you will find helpful. In particular, I’ve shown a process for planning your microservices development when applying the Strangler Fig Application pattern, and for managing the releases of functionality in your application.