Tutorial
Experiences writing a reactive Kafka application
Our journey to reactive - transforming a microservices Kafka applicationArchive date: 2025-06-10
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Apache Kafka is an extremely powerful tool for streaming large quantities of data and enabling asynchronous, non-blocking communication within systems. However, when building applications that use Kafka it can be hard to immediately test whether Kafka is working as it should. To help make this process easier, we created a Kafka starter app designed to enable you to test your Kafka deployment, with a fully functioning UI.
The first version of this application was written using the Kafka Java Producer and Consumer clients.
There has been a recent surge in popularity for reactive systems. These systems are more resilient, elastic, and responsive. This is, in part, achieved through applications in a reactive system communicating using asynchronous message passing. Because Kafka is often used as the platform to facilitate this asynchronous message passing, we decided to explore the options for rewriting our Kafka application in a reactive manner.
In this tutorial, you'll learn about our experience of moving to a reactive programming style, adopting the Vert.X Kafka client. You'll learn how that reactive framework allowed us to simplify our code and easily build a reactive Kafka application. Finally, you can try out our application by following the steps at the end of this article.
Why use a Reactive toolkit when specifically using Kafka?
When writing reactive applications that integrate with Apache Kafka, using the basic Java Producer and Consumer clients can be a good starting point. However, these clients are not optimized for Reactive Systems. Instead, you should consider using a reactive framework or toolkit. Using reactive frameworks or toolkits for Kafka applications provides the following advantages:
- Simplified Kafka APIs that are reactive
- Built-in back pressure
- Enabling asynchronous, per-record processing
There are several open-source Reactive frameworks and toolkits that include Kafka clients:
- Vert.x Kafka Client
- MicroProfile Reactive Messaging Kafka Connector
- Project Reactor Kafka
- Alpakka Kafka Connector
In our application, we chose to use the Vert.x Kafka Client for three main reasons: its internal event loop for coordination, its back-pressure support for consumers, and its use in projects we already use and work on.
Vert.x is an open source project that includes an internal event bus, allowing different parts of your application to communicate via asynchronous message passing. Additionally, Vert.x provides a Java client for consuming records from Kafka, that can be easily paused and resumed. Vert.x is a very popular open source toolkit that is used in projects such as Strimzi, which is an open source project that provides container images and operators for running Apache Kafka on Kubernetes.
The main motivation for creating this application in the first place was to give developers a quick and easy way to test out new Kafka installations. We also wanted to use it as a way to start exposing developers to the terminology used in Kafka (such as topics, offsets, and partitions) and to explore how these things are used in practice. Finally, we needed a mechanism to allow developers to send custom records into Kafka and observe those records being consumed back again.
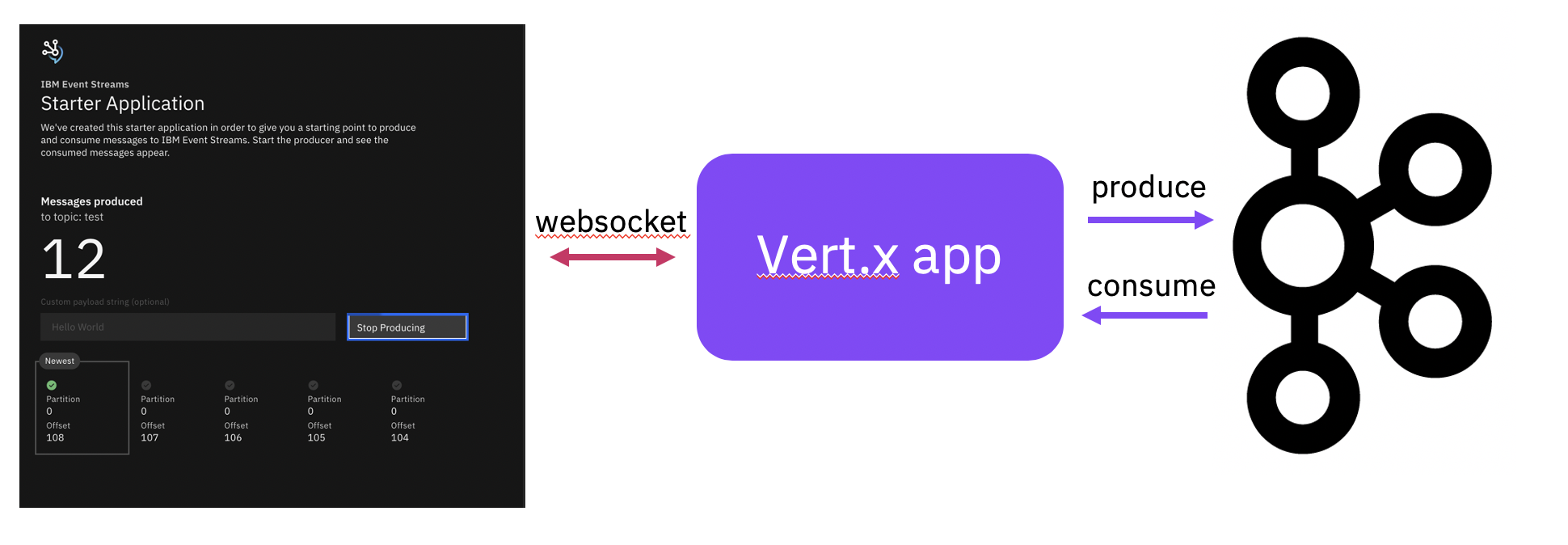
To achieve these aims, we decided to write an application comprising a frontend in JavaScript and a backend in Java. The frontend would allow users to specify a payload to send to Kafka, control when the payload is sent, and control when to consume it back from Kafka. The backend app then would take this payload and do the actual work of producing and consuming records to Kafka. We decided to use WebSockets for the frontend to send commands to the backend and for the backend to return details of any records that are produced or consumed back along the WebSockets for the frontend to display.
The following image represents the architecture for our sample application.
Efficiency improvements to our code
As mentioned previously, the backend of this application was originally written using the Producer and Consumer clients that the Apache Kafka project provides. When writing the application, we ran into a number of difficulties that we hoped would be made easier by switching to using a reactive framework. These issues ranged from the processing of records as they came back from Kafka, to handling the exchange of information with the frontend, to how to configure the application.
Producing records
In both the original version and Vert.x version of our application, the flow for producing records is fairly straight forward:
- Start command is sent to the backend on the WebSocket.
- Backend starts the producer which sends a new record every 2 seconds.
- Stop command is sent to the backend on the WebSocket.
- Backend stops producer, and no new records are produced.
In the original application using the standard Producer client, the call to produce a record is a blocking call. Switching over to the Vert.x producer meant that we would now get a Future back from the send function. This allows the application to asynchronously produce new records while waiting for the acknowledgement from Kafka of in-flight records. This was a small code change but changing to not blocking when talking to external services, like Kafka, is an important feature of reactive systems. This makes it easier to build the application to be resilient when these external services are unavailable.
Consuming and processing records
In the original version of the application, we were having to use a for loop inside a while loop that resulted in the following flow when consuming records:
- Poll for records.
- Poll function returns with a batch of records.
- Iterate through each record in the batch.
- For each record, send the record along the WebSocket to the frontend.
- After iteration is complete, return to Step 1.
So, while we were processing the current batch of records, no new records could be fetched.

In the new application using the Vert.x client instead, you simply write a handler function that will be called every time a new record arrives. This allows asynchronous consuming and processing of records which fits in much better with the reactive paradigm.

This change makes the flow a lot simpler. Vert.x now handles the step of polling for new records. The application code does the following:
- Receive a new record.
- Send the record along the WebSocket to the frontend.
This not only allows the application to process on a per-record basis but also leaves the developer free to focus on the processing of records, rather than the work of consuming them from Kafka.
Flow control
We wanted the ability to pause and resume both producing and consuming records from the frontend. In the original application, where the default Java Kafka client was used, the while loop that calls the poll for the consumer needed to be exited and resumed based on commands from the frontend. Because this client is single threaded, the loop had to be executed in a separate thread to the main flow of the application. As we wanted to produce records on a timer, a similar while loop in a separate thread was required for the producer. Therefore, we had to deal with the headache of writing logic to control the thread lifecycle and synchronize data across threads just to get control over the flow of records.
In the Vert.x application, we were able to use a combination of Vert.x features and Vert.x Kafka client features to make this flow control much easier. For the producer, we used a feature in Vert.x that allows a handler to be called on a timer basis. The handler could be called once, or multiple times, and it was easy for us to pause and resume the timer when start and stop requests arrived from the WebSocket.
For the consumer in the Vert.x application, we could use the built-in back-pressure support that allows consumers to be paused and resumed. When a stop command comes from the WebSocket, the consumer is paused and the Vert.x client will stop polling for new records from Kafka. At a later time, the consumer can be resumed and the Vert.x client will resume polling and the existing handler will start receiving new records.
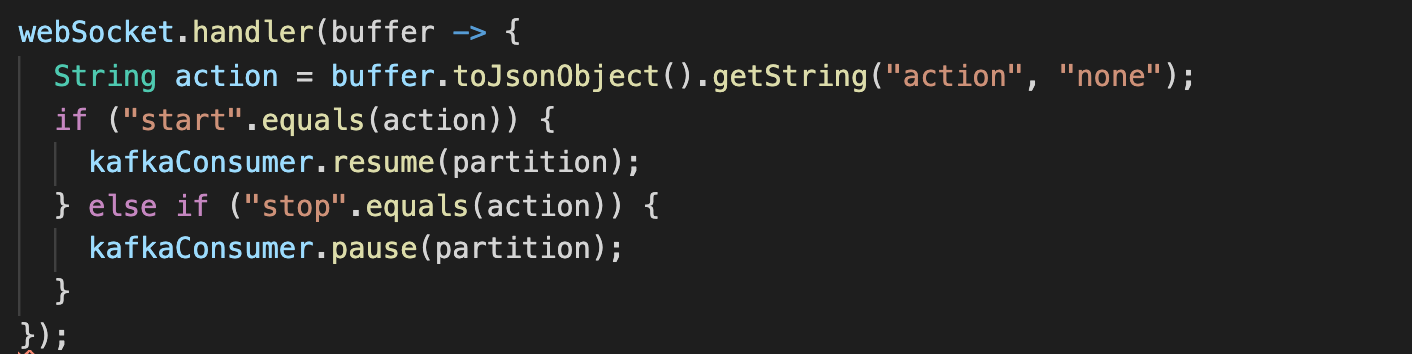
To get the commands to the clients to start or stop producing or consuming records, we used the Vert.x internal event bus. Messages from the WebSocket could easily be passed to the "Verticles" that were running the producer and consumer along the event bus. As a result, for the Vert.x version of the application, we did not have to write any thread handling logic.
Additional useful Vert.x features
Vert.x is a modular toolkit that provides a wide range of libraries, allowing you to build an application that only includes what it needs. For our application, one such library we found useful is the Vert.x Config library, which enables configuration to be loaded from multiple locations and using various syntaxes.
When you write a modern cloud-native application, it is important to externalize your configuration. We did this to a certain extent in our original application, but left options like the key/value serializers and deserializers and the security protocol hard-coded. By doing this, we could move the application between different Kafka installations, but only if they were configured the same.
For the Vert.x application, we decided to go further and provide all of the Kafka connection configuration externally. The application could then be used against any Kafka, and it was far easier to switch between secure and non-secure Kafka endpoints.
The Vert.x Config library allowed us to provide a kafka.properties file with all of our configuration that is loaded at runtime. The only nuance we found was that the retrieved config is usually converted into Java primitives. The first time we tried this we found that Vert.x converted the Kafka producer setting called "acks"(https://kafka.apache.org/documentation/#acks) to a Double rather than it being left as a String. We found that turning the conversion off stopped Kafka from complaining about the format of our configuration values.
This is just one of the features that we chose to include to enable a more cloud-native approach for our application, but there are plenty of other great Vert.x libraries that you can explore in the Vert.x docs.
Summary and next steps
In the end, updating our application to use Vert.x has allowed us to write an application that is more reactive and asynchronous in nature. It has also greatly simplified our codebase now that we no longer have to make the producer and consumer client calls in separate threads to achieve flow control. Overall, we found that using Vert.x in general and the Vert.x Kafka client specifically made integration with Kafka much easier for our use case.
Steps to run our application
Our application is available on GitHub so you can try it out for yourselves. At the time of this writing, the UI is not yet available, but it is hopefully coming soon and you can still try out the application without it.
You will need to have Kafka up and running. To run Kafka on your local machine, you can go through the first two steps of the Kafka Quickstart guide to start Zookeeper and Kafka. Alternatively, if you want to run Kafka on Kubernetes, we recommend the Strimzi operator.
Once ZooKeeper and Kafka are running, follow these steps to run the application:
Clone the repo for our sample app:
git clone https://github.com/ibm-messaging/kafka-java-vertx-starter.gitChange directories to where the sample app was cloned:
cd kafka-java-vertx-starterBuild the sample app:
mvn packageIf Kafka is not accessible on
localhost:9092, or if you have turned security on, you will need to edit thekafka.propertiesfile. If you started Kafka using the Quickstart guide, no changes tokafka.propertiesare required.Run the sample app:
java -jar target/demo-0.0.2-SNAPSHOT-all.jarTo view the UI, connect to:
http://localhost:8080/Use the buttons in the UI to produce and consume records
You can also watch us run the app and show how to use the app (using websocat and the terminal):

Video will open in new tab or window.
You can explore the source code of the application in our GitHub repository.
Explore more about reactive systems
If you’re interested in learning more about what reactive systems are then you can download our free e-book “Reactive Systems Explained”, or you can check out our “Getting started with Reactive Systems” article.
For those who are already familiar with the concepts of reactive systems but want to explore how to transform your own applications to be more reactive, then you can try out our guide “Creating reactive Java microservices” on openliberty.io (our lightweight open source web application server). This guide introduces you to the MicroProfile Reactive Messaging specification. Alternatively, you can check out the “Reactive in Practice” tutorial series which documents the transformation of the Stock Trader application into a reactive system step by step.
If you're keen to start building a reactive system but are keen to use supported runtimes for your enterprise applications, we offer several options including reactive APIs from OpenLiberty and MicroProfile but also Vert.x and Quarkus through our Red Hat runtime offering.
Explore more about Kafka
If you've read this article and are now interested in exploring Kafka more, check out our dedicated area for Apache Kafka on IBM Developer for useful articles, tutorials, and code patterns. Alternatively, you can simply head straight to our “What is Apache Kafka” article to get started.
If you are looking for a fully supported Apache Kafka offering, check out IBM Event Streams, the Kafka offering from IBM. Event Streams in IBM Cloud Pak for Integration adds on valuable capabilities to Apache Kafka including powerful ops tooling, a schema registry, award-winning user experience, and an extensive connector catalog to enable a connection to a wide range of core enterprise systems."