Article
Why enterprise messaging and event streaming are different
Complementary technologies supporting multiple use casesEnterprise messaging technologies, such as IBM MQ, RabbitMQ and ActiveMQ, have provided asynchronous communication within and across applications for many years. Recently, event streaming technologies (such as Apache Kafka) have grown in popularity, and they also provide asynchronous communication.
Developers and architects might incorrectly assume that it’s trivial or sensible to change between these two types of technologies. As is the case in many situations, once you scrape the surface and truly understand why these technologies were created, and what use cases each technology is suitable for, it quickly becomes clear that enterprise messaging technologies and event streaming technologies are actually complementary technologies instead of competing technologies.
In this article, we'll review two asynchronous use cases — "request for processing" and "access enterprise data" — to help you learn more about enterprise messaging and event streaming technologies. Then, we will discuss the key capabilities to consider when selecting the right technology for your asynchronous communication solution.
Asynchronous use cases
To understand when to use which technology, let’s start with the use cases around asynchronous communication:
Request for processing: This use case has an application making a request to another system or service to complete an action. This may result in a response message being returned to the requester. This pattern has existed since the beginning of IT, and is likely to continue for ever more. For synchronous, low quality of service communication, HTTP is the natural choice due to the availability of the technology, while asynchronous messaging is the natural choice for mission-critical communication. For further discussion on when to use synchronous and asynchronous communication, review the article "An introduction to APIs and messaging".
Access enterprise data: In this use case, components within the enterprise can emit data that describe their current state. This data does not normally contain a direct instruction for another system to complete an action. Instead, components allow other systems to gain insight into their data and status. This can be a powerful mechanism to distribute and consume enterprise data.
Request for processing use case
Enterprise messaging technologies excel in the request for processing use case and include many capabilities that make it a natural fit:
- Conversational messaging. Built into the messaging technology is the ability to complete a request/response interaction. This allows applications to interact in either a request only (fire and forget) or request/response pattern, whichever is most appropriate for the scenario.
- Targeted reliable delivery. When a message is sent, it is deliberately targeted to the entity that will process the message. Different levels of message reliability can be used, depending on the application and the significance of the message. In the case of mission-critical communication, it should be once-and-once-only, assured delivery. At-most-once or at-least-once delivery can be considered for systems that can accept loss or duplication.
- Transient data persistence. Data is only stored until a consumer has processed the message or when it expires. The data does not need to be persisted longer than required, and it is beneficial from a system resource point of view that it does not.
Access enterprise data use case
Central to the access enterprise data use case is a publish/subscribe (pub/sub) engine, where publishing applications emit data to a topic and subscribing applications register to one or more topics to receive the data from the publishing application. The pub/sub engine is responsible for the distribution ensuring that everyone receives the expected data. It also acts as an abstraction layer enabling the availability of the publishing and subscribing applications to be different.
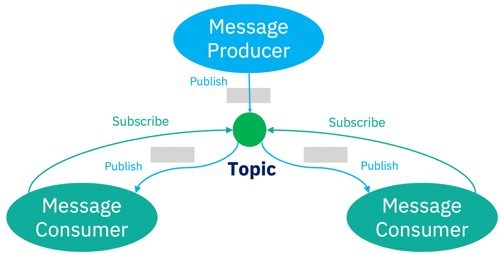
Pub/sub engines have been around for many years. For instance the JMS 1.0 specification released in 1998 included this capability, many years before the initial release of Apache Kafka in 2011. Both enterprise messaging and event streaming technologies provide a pub/sub engine and this causes confusion about which is most suitable for a given project.
Many event streaming technologies provide this pub/sub engine but also have additional capabilities that are ideal for specific use cases, helping to distinguish from when an enterprise messaging solution might be useful. For example, Apache Kafka excels at:
- Stream history. Apache Kafka stores events published to a topic and only removes these when they have been configured to expire or when system resource limitations have been reached. This allows subscribers to replay events, not only the most recently published. This is the mirror image of the messaging technology Transient Data Persistence characteristic.
- Scalable subscriptions. The stream history allows Apache Kafka to scale the number of subscribers in a lightweight method. Each subscriber has a pointer into the topic stream history that represents its position, this minimizes the overhead of a new subscriber. This frees Apache Kafka to support thousands, potentially tens of thousands of subscribers to the same subscription with minimal impact.
Choosing between enterprise messaging and event streaming technologies
As described above, enterprise messaging and event streaming technologies have different capabilities that they excel at but also have capabilities in common. Selecting the right technology for your solution is key to ensuring that it is not a forced fit.
To facilitate this evaluation, consider these key selection criteria to consider when selecting the right technology for your solution:
- Event history
- Fine-grained subscriptions
- Scalable consumption
- Transactional behavior
Event history
Does the solution need to be able to retrieve historical events either during normal and/or failure situations? Within a messaging pub/sub model, the event is published to a topic. Once it is received by the subscriber it is their responsibility to store this information for the future. There are certain situations where the pub/sub model can retain the last publication, but it is certainly unusual to get the messaging technology to store historical events. For Apache Kafka, storing event history is fundamental to the architecture, the only questions are how much and for how long. In many use cases it is critical to store this history, while in others it may be undesirable from a security and system resources standpoint.
Fine-grained subscriptions
When a topic is created in Apache Kafka this creates one or more partitions within the solution. This is a fundamental architectural concept within Apache Kafka, and provides the capability to scale the solution to handle a massive amount of events. Each partition uses up resources and it is normally advisable to limit the number of topics to hundreds or maybe thousands within a single cluster.
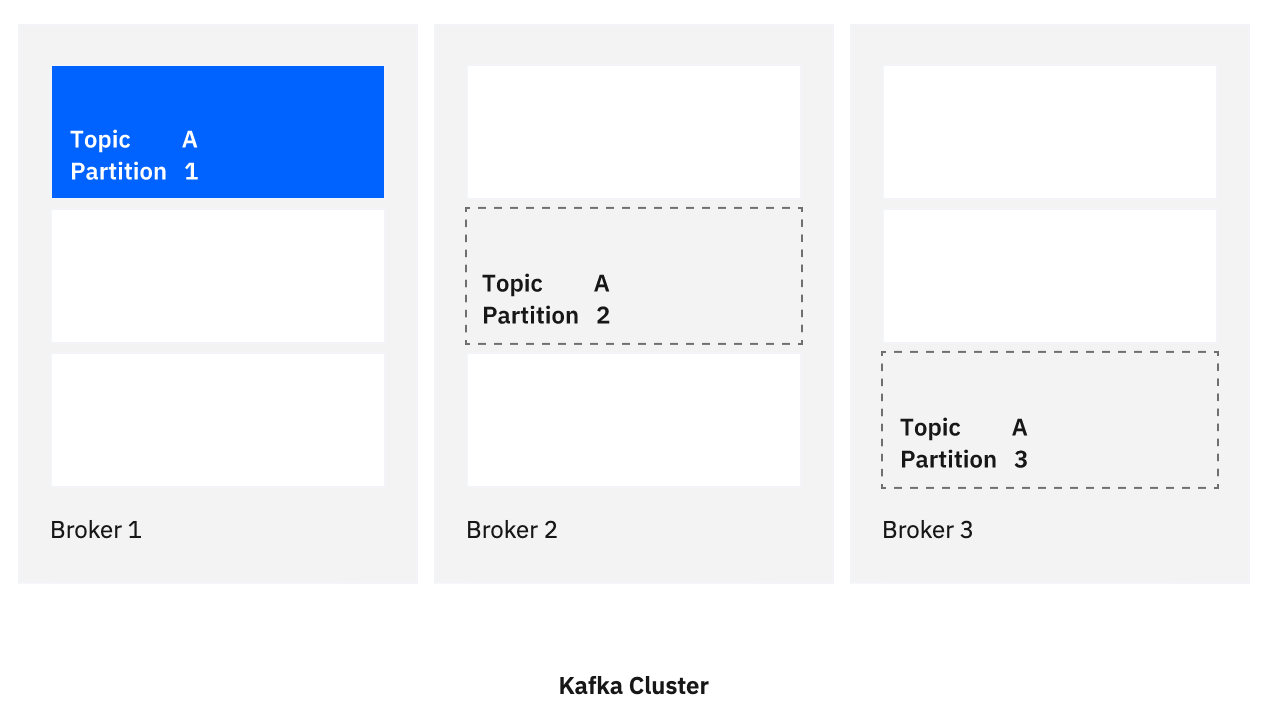
Messaging pub/sub technologies have a more flexible mechanism, where the topic can be a hierarchical structure such as /travel/flights/airline/flight-number/seat, allowing more subscription points. This allows subscribing applications to select the events at a finer granularity. In addition, messaging pub/sub selectors can be used to further refine the events of interest.
Applications subscribing to messaging pub/sub systems are far less likely to receive events that are irrelevant to them, while applications subscribing to Apache Kafka that want only a small proportion of events will likely need a discarding filter to be applied early in the processing.
Scalable Consumption
If 100 consumers subscribe to all events on a topic, a messaging technology may create 100 messages for each published event. Each of these may be stored and, if required, persisted to disk using system resources. In the case of Apache Kafka, the event is written once and each consumer has an index corresponding to where they are in the event history. Messaging providers such as IBM MQ are highly scalable, so depending on the number of events emitted by the publisher, and the number of subscribers, this may or may not be a factor in deciding the most appropriate technology.
Transactional behavior
Both enterprise messaging technologies, such as IBM MQ, and event streaming technologies, such as Apache Kafka, provide transactional APIs to process events. However, the two implementations do work differently and therefore aren't automatically interchangeable. IBM MQ provides the ACID properties of Atomicity, Consistency, Isolation, and Durability but these are not guaranteed in the same way in Apache Kafka. Often in a pub/sub solution, the specific transactional behavior of IBM MQ is not as critical as in a request for processing use case so being aware of the difference is important.
Summary and next steps
In summary, although enterprise messaging technologies and event streaming technologies may initially appear to be overlapping, the use cases and scenarios where each are appropriate are different. Messaging technologies excel in the request for processing scenario, while event streaming technologies specialize in providing a pub/sub engine with stream history. These two technologies truly are complementary in nature, and so clients commonly have a need for both.
Explore more about these messaging technologies:
- Get started with IBM MQ with the IBM MQ Developers Essentials learning path, or explore the articles, tutorials, and other IBM MQ content on IBM Developer.
- Get started with Apache Kafka with the Develop production-ready, Apache Kafka apps learning path, or explore the articles, tutorials, and other Apache Kafka content on IBM Developer.