Article
How persistence works in an Apache Kafka deployment
Persisting data in a default Kafka or IBM Event Streams on IBM Cloud deploymentIn this article, we'll explore how Apache Kafka persists data that is sent to a Kafka deployment. We discuss topic partitions and log segments, acknowledgements, and data retention.
This article assumes that you have an understanding of the basic concepts of Kafka:
- A Kafka deployment consists of 1 or more Kafka broker processes in a Kafka cluster
- Messages are written to and read from topic partitions by producer and consumer clients
- Topic partitions can be replicated across 1 or more brokers
To find out more about Apache Kafka, see their Introduction to Apache Kafka and the Apache Kafka Documentation.
We'll also describe how Kafka in IBM Event Streams on IBM Cloud is configured when it comes to data persistence.
Topic partitions and log segments
The data in a topic partition is split into log segments. For each log segment, there is a file on disk. One of the segments is the active segment into which messages are currently written. Once the size or time limit of the active segment is reached, the corresponding file is closed and a new one is opened. By splitting the data of a topic partition into segments, Kafka can purge and compact messages from the non-active segments.
In the following diagram, the topic partition has 3 replicas, broker 2 is the leader replica, and brokers 1 and 3 are the follower replicas. Each of the replicas has a segment for the topic partition, which is backed up by its own file.
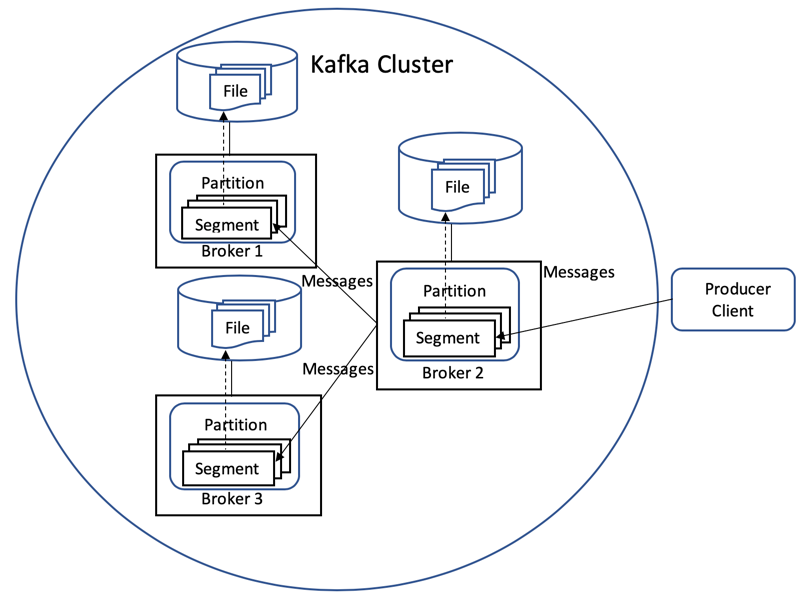
When the data is written to a log segment, by default it is not flushed to disk immediately. Kafka relies on the underlying operating system to lazily flush the data to disk, which improves performance. Although this might appear to increase the risk of data loss, in most cases, each topic partition will be configured to have more than 1 replica. So, the data will exist on more than one broker.
Kafka has server and per-topic configuration parameters that allow the frequency of flushing of segment data to disk to be controlled by the number of messages that have been received or by how long a message has been in the segment. In general, you should not override the default of allowing the operating system to decide when to flush the segment data to disk, but instead you should rely on replication for the durability of your data.
Acknowledgements
A producer client can choose how many replicas to wait to receive the data in memory (although not necessarily written to disk) before the write is considered complete. You use the ACKs setting in the producer client configuration.
A producer sending messages has the following options for waiting for messages to be received by the Kafka:
- It doesn’t wait for a reply (
ACKs=0) - It waits for a reply to say that the leader broker has received the message (
ACKs=1) - It waits for a reply to say that all the in-sync replica brokers have received the message
ACKs=all)
In the case where there are 3 replicas (like in the diagram above), if the producer has specified ACKS=all it will wait for all 3 replicas to receive the data. Thus, once the producer has written the data, if a broker fails, there are 2 remaining brokers that also have copies of the data. When the failed broker comes back on-line, there is a period of "catch up" until it is in sync with the other brokers. However, with ACKs=0 or ACKs=1, there is a greater risk of losing data if a broker failure occurs before the data has reached all of the replicas.
Data retention
Data retention can be controlled by the Kafka server and by per-topic configuration parameters. The retention of the data can be controlled by the following criteria:
The size limit of the data being held for each topic partition:
log.retention.bytesproperty that you set in the Kafka broker properties fileretention.bytesproperty that you set in the topic configuration
The amount of time that data is to be retained:
log.retention.ms,log.retention.minutes, orlog.retention.hoursproperties that you set in the Kafka broker properties fileretention.ms,retention.minutes, orretention.hoursproperties that you set in the topic configuration
When either of these limits is reached, Kafka purges the data from the system.
When you use the REST Admin API or the Administration Kafka Java Client API you can specify only the retention.bytes and retention.ms properties.
How persistence is configured in IBM Event Streams on IBM Cloud
IBM Event Streams on IBM Cloud has many different plans to choose from, but the Enterprise plan offers the best options where persistence is concerned. The Enterprise plan offers significantly more partitions and storage space for maximum retention periods. For more information on IBM Event Streams on IBM Cloud plans, see "Choosing your plan" in the documentation.
The Enterprise plan of IBM Event Streams on IBM Cloud in a multi-zone region configures Kafka in this manner:
- There is one Kafka cluster per instance of the Event Streams on IBM Cloud service in a multi-zone region.
- The cluster is split across 3 availability zones within the region in which the instance is provisioned.
- There are 3 brokers in the Kafka cluster, with a broker in each availability zone.
- The number of replicas for each topic partition is 3. Thus, if a whole availability zone becomes unavailable, there will still be 2 copies of the topic partition data available.
IBM Event Streams on IBM Cloud uses the default settings for flushing log segment data and does not allow it to be changed on a per-topic basis.
With IBM Event Streams on IBM Cloud, you can use the Administration REST API or the Administration Kafka Java Client API to control the retention of data when creating topics.
Summary
To provide high performance, Kafka does not write data to disk immediately by default. The risk of data loss can be mitigated by replicating the data over more than one broker. The duration over which data is retained can be controlled by time or by maximum size of data.