Article
Make the most of the powerful JSON_TABLE function
Utilize JSON information with IBM DB2 for iJSON_TABLE is a powerful function that enables the easy decomposition of JavaScript Object Notation (JSON) data into relational format. After providing a brief overview of JSON, the article explains the four types of database columns that can be defined using JSON_TABLE and provides examples of using JSON_TABLE to retrieve JSON objects from the web and process that information in relational form. Following these examples, database users can easily import JSON data into their relational database.
JSON_TABLE
A popular format for information interchange on the internet is JavaScript Object Notation, commonly known as JSON. One reason for the usage of JSON is its tight integration with JavaScript, which is supported by web browsers and used widely to implement web applications. Furthermore, many information sources on the web provide data in the JSON format, allowing JavaScript and other applications to consume that data. Recognizing the importance of JSON as an information interchange format, the latest version of the SQL standards includes SQL language elements which work with JSON. One of the most powerful language elements is JSON_TABLE, which converts a JSON object into a relational table. This allows JSON information to be easily consumed by database applications, without the need to write a program to parse the JSON text.
This article begins by briefly describing the JSON format. It then explains SQL/JSON path expressions, which provide the means to locate information within JSON objects. The article then explains the different types of column information that can be extracted using JSON_TABLE. Finally, several examples of the use of JSON_TABLE in DB2 for i are illustrated.
JSON_TABLE is available on IBM® DB2® for i for releases 7.2 and 7.3. It is provided with the 7.2 Database Group PTF SI99702 level 14 and the 7.3. Database Group PTF SI99703 level 3, which were released in November 2016.
JSON
The JSON data interchange format has been standardized by Ecma International and the standard is available at https://ecma-international.org/publications-and-standards/standards/ecma-404/. The primary structural unit of JSON is the object and a JSON object is represented as a list of key-value pairs. These key-value pairs are separated by commas and enclosed within curly braces. In a key-value pair, a colon separates the key from the value. Listing 1 shows a simple JSON object representing a person's name. In this object, the key-pairs are "first"and"John","middle"and"K", and "last" and "Doe".
Listing 1. A simple JSON object
{ "first" : "John" , "middle" : "K", "last" : "Doe" }The key of a key-value pair must be a string, which is a sequence of Unicode characters surrounded by double quotes.
The value of a key-value pair can be one of the following:
- String – "John"
- Number – 567.12
- Boolean value – true or false
- No value – null
- Object – { "middle-init" : K , "middle-full" : "Kevin" }
- Array – [ "red", "green", "blue" ]
In JSON, a number is a signed decimal number that may include an exponent using the exponential E notation. A boolean value is either the special value true or the special value false. The special value null indicates an empty value. A JSON array consists of a list of values, separated by commas, within enclosing brackets. Listing 2 shows a simple JSON array which contains the strings "red","green", and "blue".
Listing 2.JSON array
[ "red", "green", "blue" ] A JSON object can use these elements in various combinations to represent information. Listing 3 shows a sample JSON object. In this object, there are five outermost key-value pairs, with the keys "id","name","phones","lazy", and "married". The value for the first key-value pair is the number 901. For the second key-value pair, the value is an object with the keys "first", "middle", and "last". For the third key-value pair, the value is an array. The elements of the array are themselves JSON objects with keys "type" and "number". The fourth key-value pair has a boolean value, which in this case is false. The last key-value pair has the value null.
Listing 3. Sample JSON object
{
"id" : 901,
"name" : { "first":"John", "middle":"K", "last":"Doe" },
"phones" : [ {"type" : "home", "number" : "555‑3762" },
{"type" : "work", "number" : "555‑7242" }],
"lazy" : false,
"married" : null
}
Converting to relational form
The purpose of JSON_TABLE is to extract information from a JSON object and represent it as a relational table. Figure 1 shows an example of extracting the information from a JSON object and representing it as a relational table. In this example, a table is created with the columns ID, FIRSTNAME, LASTNAME, PHONE_TYPE, and PHONE_NUMBER. The value in the ID column comes from the value associated with the "id" key in the JSON object. The values for the FIRSTNAME and LASTNAME columns come from the values associated with the "first" and "last" keys. Because there are two different values in the array associated with the "phones" key, these two values are used to create two rows in the relational table, where the data for the PHONE_TYPE and PHONE_NUMBER column are retrieved from the values associated with the "type" and "number" keys of the objects within the array.
Figure 1. Extracting JSON data into a relational table
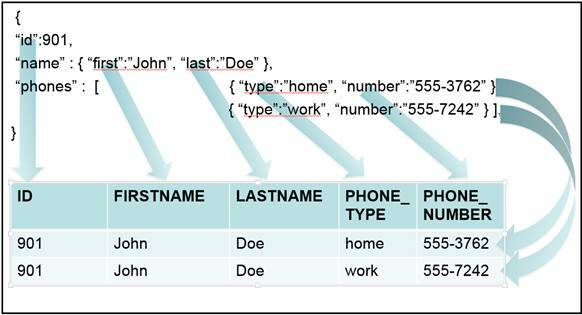
When extracting JSON data into a relational table, we must specify what to place in the two dimensions of the relational table. For the first dimension, we must specify which columns are in the relational table. In Figure 1, we see that the column names are ID, FIRSTNAME, LASTNAME, PHONE_TYPE, and PHONE_NUMBER. For the second dimension, we must specify which rows should be produced. In Figure 1, rows are produced for each value in the array associated with the "phones" key.
SQL/JSON path expressions
When extracting relational information from a JSON object, there must be a way to specify where the information can be found in the JSON object. In JSON_TABLE, this information is specified using an SQL/JSON path expression. An SQL/JSON path expression is a list of directions to find one or many values within a JSON object. Informally, this list contains directions to start with the current object, to look inside an object, to look inside an array, or to look for a value associated with a key.
As an example, consider the JSON object shown in Listing 4. To find the phone number associated with the first element in the phone array, we must use the following directions: First, we need to start with the current object. Second, look inside the object. Then, look for the value associated with the "phones" key. Then, look at the first element of the array. Then look within the object. Finally look at the value associated with the "number" value to find "555-3762".
Listing 4. Sample JSON object
{
"phones" : [ {"type" : "home", "number" : "555‑3762" },
{"type" : "work","number" : "555‑7242" },
}
In SQL/JSON path expressions, the following directions have an associated syntax:
- $ – Start with the current object
- . – Look inside an object
- [ ] – Look inside an array
– Reference the value associated with a key
Consequently, the SQL/JSON path to extract the first phone number is '$.phones[0].number'.
Associated with an SQL/JSON path expression is a mode, which is either lax or strict. Lax mode means that when the SQL/JSON path expression is evaluated, certain error conditions are tolerated, whereas strict mode produces a failure when those error conditions are encountered.
An SQL/JSON path expression could result in the evaluation of an array. When using the lax mode, if an array is encountered and the SQL/JSON path expression does not have a step to dereference the array, the array is automatically dereferenced. Furthermore, if the SQL/JSON path expression has a step to dereference an array, for example [0], and an array is not encountered, the step to dereference the array is ignored. Finally, if any other error is encountered, the result is an empty value instead of an error. Table 1 summarizes the difference between these modes.
Table 1. SQL/JSON path mode
| Lax | Strict | |
|---|---|---|
| Automatic unnesting of arrays | Certain path steps, such as the member access $.key, automatically iterate over the elements of an array. | Arrays are not automatically unnested. |
| Automatic wrapping within an array | Subscript path steps, such as [0] or [*], may be applied to a non-array. | There is no automatic wrapping prior to subscript path steps. |
| Error handling | Errors not handled by the automatic unnesting and automatic wrapping features are converted to empty SQL/JSON sequences. | Errors are strictly defined in all cases. |
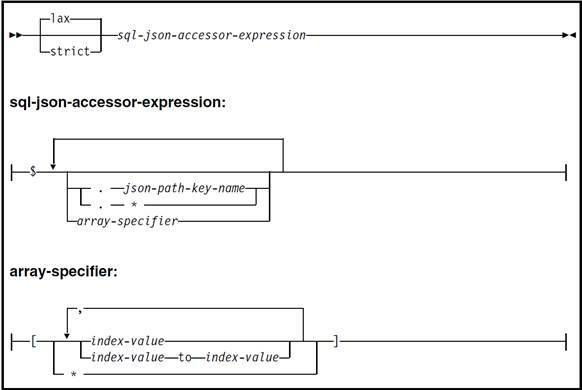
More formally, the syntax diagram for an SQL/JSON path expression is shown in Figure 2. An SQL/JSON path expression can optionally begin with a mode. If a mode is not specified, then lax is used. The path begins with the dollar symbol ($) to indicate the current JSON context. Then, accessors to find a key-value with an object or an array specifier are used. The member accessor ".*" means to access all values in the object and the array specifier "*" means to access all values in an array. When referencing the values in an array, the elements to be accessed can be explicitly stated. For example, elements at indexes 0,1,3 can be accessed. Alternatively, a range of elements can be specified using the keyword to. For example, 0 to 3 can be used to access elements 0, 1, 2, and 3. In SQL/JSON path expressions, the first element of the array is found at index value 0.
Figure 2. SQL/JSON path expression syntax
JSON_TABLE syntax
To create a relational table from a JSON object, the database needs to know several pieces of information. First, it must know where to locate the JSON object. Second, it must know the uppermost level for producing rows. Third, it must know the definition for each column, where each column definition contains the column name, the data type, and the SQL/JSON path to the JSON value. Figure 3 shows the syntax for JSON_TABLE when used with the simplest form of a column definition, a regular column definition.
Figure 3. Basic JSON_TABLE syntax using a regular column definition
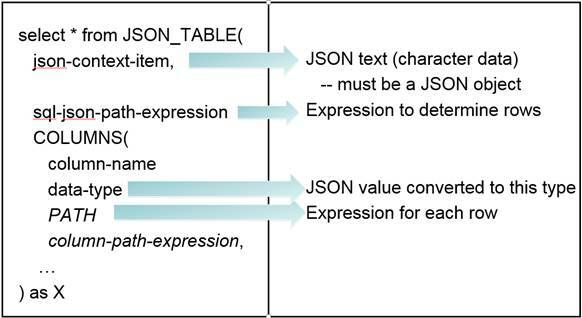
In this syntax, the table function name, JSON_TABLE, indicates that JSON_TABLE is to be called. The first parameter is the json-context-item, which usually is a character string containing a JSON object. DB2 for i also supports passing a binary large object (BLOB) field which contains a JSON object in the Binary JSON (BSON) format. This format was used by the previous DB2 JSON store. If the DB2 JSON store was used to store BSON objects into the database, these objects can now be consumed by JSON_TABLE.
The second parameter of JSON_TABLE is the sql-json-path-expression. This is the top-level expression that indicates which elements of the JSON object should be used to produce output rows in the resulting table. Within this expression, the beginning '$' symbol represents the json-context-item.
The third part of JSON_TABLE indicates which columns should be produced. Each column has a column-name and a corresponding data-type. The path to find the requested JSON element is specified using the keyword PATH followed by an SQL/JSON path. Many columns can be specified with each column definition separated by a comma. In JSON_TABLE, specifying a column path is optional. If a column path is not specified, then a path of the form '$.column-name' is used. When using this feature, it must be remembered that SQL/JSON paths are case sensitive.
To illustrate the use of JSON_TABLE, we use a global variable that contains a JSON object. Listing 5 shows SQL statements that can be used to create a global variable named JSON_VAR and populate the global variable with a JSON object.
Listing 5. JSON into variable
CREATE VARIABLE JSON_VAR VARCHAR(2000);
SET JSON_VAR='{
"id" : 901,
"name" : { "first":"John", "last":"Doe" },
"phones" : [{"type":"home", "number":"555-3762"},
{"type":"work", "number":"555-7252"}]}';
Now that we have a JSON object, we can use JSON_TABLE to extract values from that JSON object into relational data. Listing 6 shows a simple use of JSON_TABLE. In this example, a SELECT statement is used to invoke JSON_TABLE and return all the columns that it produces. The global variable JSON_VAR is used as the JSON input to JSON_TABLE. In this example,'$' is used as the outermost SQL/JSON path expression, which means that the column definitions will use the existing JSON object as their context item. Because '$' only references one item in the object, this use of JSON_TABLE will only produce one row. After the outermost SQL/JSON path expression, the columns are defined. The first column is named ID and has a type of VARCHAR(10). The SQL/JSON path to locate that value is 'lax $.id'. Similarly, this example has columns FIRST and LAST, which return the first name and last name within the inner JSON object referenced by the "name" key.
Listing 6. Simple JSON_TABLE query
SELECT * FROM JSON_TABLE(JSON_VAR,
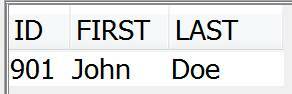
'Running this query results in the table shown in Figure 4. From the JSON object, the id has been retrieved, as well as the first name and last name.
Figure 4. JSON_TABLE result
JSON_TABLE with nested columns
In the previous example, only a single row was created from the JSON object. To retrieve multiple rows using the array elements embedded in the JSON object, a nested column definition is used. A nested column definition can take the place of a regular column definition. Its syntax is shown in Figure 5.
Figure 5. Nested column definition

A nested column definition begins with the keyword NESTED and is followed by an SQL/JSON path expression which indicates which JSON values are to be processed by the columns within the nested definition. This path expression indicates which elements of an array should be used to produce rows. Typically, the path expression contains '[*]' which indicates that all the elements of an array are handled. After the path, the columns are defined using the COLUMNS keyword, just like the columns that are defined in a regular column definition.
Listing 7 shows an example of using a nested column definition. As in the previous example, the context item references the JSON_VAR variable and '$' is used as the outer most SQL/JSON path expression. This query also returns the first and last name, as before. It then uses a NESTED column definition which has '$.phone[*]' as the SQL/JSON path expression. This expression directs JSON_TABLE to produce a row for each element of the phones array. For each object encountered in the array, column definitions are used to extract the "type" and "number" values for each phone number. In this example, these lower-level column definitions do not include a path. So, the default paths of the form '$.type' and '$.number' are used.
Listing 7. Nested JSON_TABLE query
SELECT * FROM JSON_TABLE( JSON_VAR,
'
Figure 6 shows the result of running this query. Because there are two phone objects in the phone array, two rows are returned.
Figure 6. JSON_TABLE nested result

JSON_TABLE ordinality
Another type of column definition is the ordinality column. An ordinality column is used to number the rows within a nesting level. The syntax for an ordinality column is shown in Figure 7. It consists of the column name followed by the keywords FOR ORDINALITY. The SQL data type of an ordinality column is BIGINT.
Figure 7. Ordinality column syntax

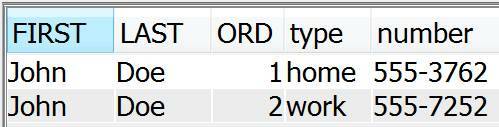
Listing 8 shows an example of using JSON_TABLE with an ordinality column. In this example, the column name is ORD.
Listing 8. Ordinality JSON_TABLE query
SELECT * FROM JSON_TABLE( JSON_VAR,
'
Figure 8 shows the results of running this query. The result now has an ORD column with the values 1 and 2 for the two rows generated.
Figure 8. JSON_TABLE ordinality result
JSON_TABLE and FORMAT JSON
The final type of column definition is a FORMAT JSON column definition. A simplified syntax for this column definition is shown in Figure 9. This column definition is similar to the standard column definition, with the exception that the keywords, FORMAT JSON, are used after data-type. When using this column definition, the JSON value found by the column-path-expression-constant is returned in JSON format. In practice, this format is useful to the programmer when developing a JSON_TABLE expression, as this allows a programmer to see the JSON value produced by a particular JSON path.
Figure 9. FORMAT JSON column definition

Listing 9 shows an example of using FORMAT JSON. In this example, we want to see the results of using various steps in an SQL/JSON path.
Listing 9. FORMAT JSON query
SELECT * FROM JSON_TABLE( JSON_VAR,
'
Figure 10 shows the result of running this query. The ALL column contains the JSON object, which is referenced by using '$'. The PHONES column reflects the JSON array corresponding to '$.phones'. The PHONE0 column returns the JSON object found in the first element of the phones array. Finally, the TYPE column contains the type of phone found within the first element of the phones array. Because FORMAT JSON is used and the result is a string value, the double quotes present in the original JSON object are also returned.
Figure 10. FORMAT JSON JSON_TABLE result

JSON_TABLE options
JSON_TABLE has a number of options that can be used to configure its behavior. There are options available for the uppermost level of JSON_TABLE as well as options for regular column definitions and FORMAT JSON column definitions.
At the uppermost level of JSON_TABLE, the error handling behavior can be specified. This behavior is either EMPTY ON ERROR or ERROR ON ERROR. The default is EMPTY ON ERROR which means that an empty table (that is, a table with no rows) is returned when a table level error is encountered. The ERROR ON ERROR setting indicates that an error should be returned.
Listing 10 shows an example of using the ERROR ON ERROR setting. Note that the context path uses the strict mode to force the error. Figure 11 shows the resultant error.
Listing 10. ERROR ON ERROR
SELECT * FROM JSON_TABLE( JSON_VAR,'strict $.forceError' COLUMNS( "id" VARCHAR(10) PATH 'lax $.id')
ERROR ON ERROR )as t;
Figure 11. Result of ERROR ON ERROR

For regular column definitions, the following six options are available to control the behavior when empty values are found or errors are encountered:
- Return NULL when empty
Use NULL ON EMPTY to return NULL when the key is not found.
- Return ERROR when empty
Use ERROR ON EMPTY to cause an error to be issued when the key is not found.
- Return a default value when empty
Use DEFAULT <value> ON EMPTY to return a literal value when the key is not found.
- Return NULL on an error
Use NULL ON ERROR to return NULL when the path expression encounters an error.
- Return ERROR on an error
Use ERROR ON ERROR to cause an error to be issued when the path expression encounters an error.
- Return a default value on an error
Use DEFAULT <value> ON ERROR to return a literal value when the path expression encounters an error.
Listing 11 shows an example of using these settings and the corresponding output is shown in Figure 12. In this example, NULL is returned for the EMPTYCOL1 and ERRORCOL1 columns because the specified elements cannot be found. The use of strict mode in the path for ERRORCOL1 column causes the error to occur. For the EMPTYCOL2 and ERRORCOL2 columns, the specified 'EMPTY2' and 'ERROR2' strings are returned.
Listing 11. ON EMPTY and ON ERROR settings
SELECT * FROM JSON_TABLE( JSON_VAR, '
Figure 12. ON EMPTY and ONE ERROR output

JSON_TABLE examples
The real power of JSON_TABLE can be seen when processing a JSON object that is retrieved from the web. The following examples demonstrate how to consume JSON values retrieved from various websites. These examples illustrate how JSON_TABLE can easily convert JSON data into relational information.
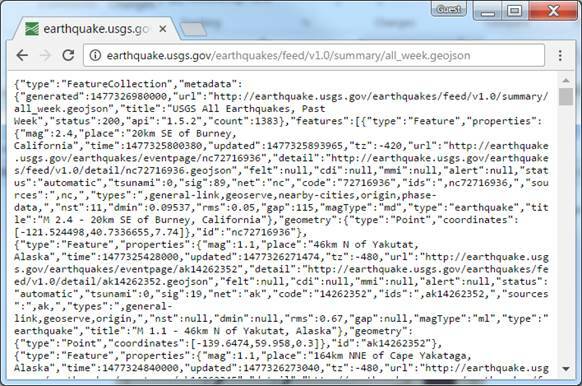
The United States Geological Survey provides a JSON feed of recent earthquake information. You can find the information about earthquakes within the last week at https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_week.geojson. You can view the information using a web browser as shown in Figure 13.
Figure 13. Earthquakes feed
From this information, we want to get a list of the recent earthquakes with their report times, magnitudes, and location. This can be accomplished using the SQL statement in Listing 12. In this statement, the SYSTOOLS.HTTPGETCLOB function is used to retrieve the JSON object from the website. This object is then used as the input to JSON_TABLE. After the input value is specified, the path 'lax $.features[*]' is used to retrieve all the earthquake information stored in the array specified by the "features" key. We then define three columns to contain the information for the time (in milliseconds), magnitude, and place of the earthquake. The SQL/JSON path expressions used to locate this information are defined for each column.
Listing 12. Earthquakes JSON_TABLE
select * from JSON_TABLE(
SYSTOOLS.HTTPGETCLOB('https://earthquake.usgs.gov' ||
'/earthquakes/feed/v1.0/summary/all_week.geojson',null),
'$.features[*]'
COLUMNS( MILLISEC BIGINT PATH '$.properties.time',
MAG DOUBLE PATH '$.properties.mag',
PLACE VARCHAR(100) PATH '$.properties.place'
)) AS X;
The beginning of the result of running this query is shown in Figure 14.
Figure 14. Earthquakes result
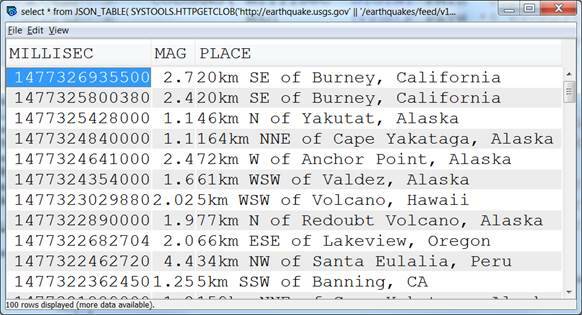
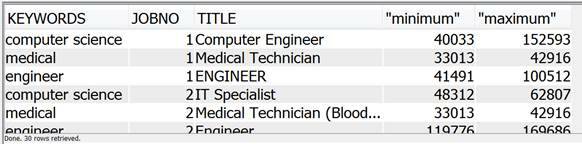
Figure 15. Results
Summary
JSON_TABLE is a powerful tool now available to process JSON data on DB2 for i. By using SQL/JSON path expressions to locate information in JSON objects, JSON_TABLE can place that information into the rows and columns of database tables. In conjunction with HTTP functions, JSON feeds can be consumed using SQL and combined with traditional forms of relational data.
COLUMNS(
id VARCHAR(10) PATH 'lax $.id',
first VARCHAR(10) PATH 'lax $.name.first',
last VARCHAR(10) PATH 'lax $.name.last' )
) as t;
Running this query results in the table shown in Figure 4. From the JSON object, the id has been retrieved, as well as the first name and last name.
Figure 4. JSON_TABLE result
JSON_TABLE with nested columns
In the previous example, only a single row was created from the JSON object. To retrieve multiple rows using the array elements embedded in the JSON object, a nested column definition is used. A nested column definition can take the place of a regular column definition. Its syntax is shown in Figure 5.
Figure 5. Nested column definition
A nested column definition begins with the keyword NESTED and is followed by an SQL/JSON path expression which indicates which JSON values are to be processed by the columns within the nested definition. This path expression indicates which elements of an array should be used to produce rows. Typically, the path expression contains '[*]' which indicates that all the elements of an array are handled. After the path, the columns are defined using the COLUMNS keyword, just like the columns that are defined in a regular column definition.
Listing 7 shows an example of using a nested column definition. As in the previous example, the context item references the JSON_VAR variable and '$' is used as the outer most SQL/JSON path expression. This query also returns the first and last name, as before. It then uses a NESTED column definition which has '$.phone[*]' as the SQL/JSON path expression. This expression directs JSON_TABLE to produce a row for each element of the phones array. For each object encountered in the array, column definitions are used to extract the "type" and "number" values for each phone number. In this example, these lower-level column definitions do not include a path. So, the default paths of the form '$.type' and '$.number' are used.
Listing 7. Nested JSON_TABLE query
__CODE_BLOCK_6__Figure 6 shows the result of running this query. Because there are two phone objects in the phone array, two rows are returned.
Figure 6. JSON_TABLE nested result
JSON_TABLE ordinality
Another type of column definition is the ordinality column. An ordinality column is used to number the rows within a nesting level. The syntax for an ordinality column is shown in Figure 7. It consists of the column name followed by the keywords FOR ORDINALITY. The SQL data type of an ordinality column is BIGINT.
Figure 7. Ordinality column syntax
Listing 8 shows an example of using JSON_TABLE with an ordinality column. In this example, the column name is ORD.
Listing 8. Ordinality JSON_TABLE query
__CODE_BLOCK_7__Figure 8 shows the results of running this query. The result now has an ORD column with the values 1 and 2 for the two rows generated.
Figure 8. JSON_TABLE ordinality result
JSON_TABLE and FORMAT JSON
The final type of column definition is a FORMAT JSON column definition. A simplified syntax for this column definition is shown in Figure 9. This column definition is similar to the standard column definition, with the exception that the keywords, FORMAT JSON, are used after data-type. When using this column definition, the JSON value found by the column-path-expression-constant is returned in JSON format. In practice, this format is useful to the programmer when developing a JSON_TABLE expression, as this allows a programmer to see the JSON value produced by a particular JSON path.
Figure 9. FORMAT JSON column definition
Listing 9 shows an example of using FORMAT JSON. In this example, we want to see the results of using various steps in an SQL/JSON path.
Listing 9. FORMAT JSON query
Figure 10 shows the result of running this query. The ALL column contains the JSON object, which is referenced by using '$'. The PHONES column reflects the JSON array corresponding to '$.phones'. The PHONE0 column returns the JSON object found in the first element of the phones array. Finally, the TYPE column contains the type of phone found within the first element of the phones array. Because FORMAT JSON is used and the result is a string value, the double quotes present in the original JSON object are also returned.
Figure 10. FORMAT JSON JSON_TABLE result
JSON_TABLE options
JSON_TABLE has a number of options that can be used to configure its behavior. There are options available for the uppermost level of JSON_TABLE as well as options for regular column definitions and FORMAT JSON column definitions.
At the uppermost level of JSON_TABLE, the error handling behavior can be specified. This behavior is either EMPTY ON ERROR or ERROR ON ERROR. The default is EMPTY ON ERROR which means that an empty table (that is, a table with no rows) is returned when a table level error is encountered. The ERROR ON ERROR setting indicates that an error should be returned.
Listing 10 shows an example of using the ERROR ON ERROR setting. Note that the context path uses the strict mode to force the error. Figure 11 shows the resultant error.
Listing 10. ERROR ON ERROR
Figure 11. Result of ERROR ON ERROR
For regular column definitions, the following six options are available to control the behavior when empty values are found or errors are encountered:
- Return NULL when empty
UseNULL ON EMPTYto returnNULLwhen the key is not found. - Return ERROR when empty
UseERROR ON EMPTYto cause an error to be issued when the key is not found. - Return a default value when empty
UseDEFAULT <value> ON EMPTYto return a literal value when the key is not found. - Return NULL on an error
UseNULL ON ERRORto returnNULLwhen the path expression encounters an error. - Return ERROR on an error
UseERROR ON ERRORto cause an error to be issued when the path expression encounters an error. - Return a default value on an error
UseDEFAULT <value> ON ERRORto return a literal value when the path expression encounters an error.
Listing 11 shows an example of using these settings and the corresponding output is shown in Figure 12. In this example, NULL is returned for the EMPTYCOL1 and ERRORCOL1 columns because the specified elements cannot be found. The use of strict mode in the path for ERRORCOL1 column causes the error to occur. For the EMPTYCOL2 and ERRORCOL2 columns, the specified 'EMPTY2' and 'ERROR2' strings are returned.
Listing 11. ON EMPTY and ON ERROR settings
Figure 12. ON EMPTY and ONE ERROR output
JSON_TABLE examples
The real power of JSON_TABLE can be seen when processing a JSON object that is retrieved from the web. The following examples demonstrate how to consume JSON values retrieved from various websites. These examples illustrate how JSON_TABLE can easily convert JSON data into relational information.
The United States Geological Survey provides a JSON feed of recent earthquake information. You can find the information about earthquakes within the last week at https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_week.geojson. You can view the information using a web browser as shown in Figure 13.
Figure 13. Earthquakes feed
From this information, we want to get a list of the recent earthquakes with their report times, magnitudes, and location. This can be accomplished using the SQL statement in Listing 12. In this statement, the SYSTOOLS.HTTPGETCLOB function is used to retrieve the JSON object from the website. This object is then used as the input to JSON_TABLE. After the input value is specified, the path 'lax $.features[*]' is used to retrieve all the earthquake information stored in the array specified by the "features" key. We then define three columns to contain the information for the time (in milliseconds), magnitude, and place of the earthquake. The SQL/JSON path expressions used to locate this information are defined for each column.
Listing 12. Earthquakes JSON_TABLE
__CODE_BLOCK_11__The beginning of the result of running this query is shown in Figure 14.
Figure 14. Earthquakes result
Figure 15. Results
Summary
JSON_TABLE is a powerful tool now available to process JSON data on DB2 for i. By using SQL/JSON path expressions to locate information in JSON objects, JSON_TABLE can place that information into the rows and columns of database tables. In conjunction with HTTP functions, JSON feeds can be consumed using SQL and combined with traditional forms of relational data.
Figure 6 shows the result of running this query. Because there are two phone objects in the phone array, two rows are returned.
Figure 6. JSON_TABLE nested result
JSON_TABLE ordinality
Another type of column definition is the ordinality column. An ordinality column is used to number the rows within a nesting level. The syntax for an ordinality column is shown in Figure 7. It consists of the column name followed by the keywords FOR ORDINALITY. The SQL data type of an ordinality column is BIGINT.
Figure 7. Ordinality column syntax
Listing 8 shows an example of using JSON_TABLE with an ordinality column. In this example, the column name is ORD.
Listing 8. Ordinality JSON_TABLE query
__CODE_BLOCK_7__Figure 8 shows the results of running this query. The result now has an ORD column with the values 1 and 2 for the two rows generated.
Figure 8. JSON_TABLE ordinality result
JSON_TABLE and FORMAT JSON
The final type of column definition is a FORMAT JSON column definition. A simplified syntax for this column definition is shown in Figure 9. This column definition is similar to the standard column definition, with the exception that the keywords, FORMAT JSON, are used after data-type. When using this column definition, the JSON value found by the column-path-expression-constant is returned in JSON format. In practice, this format is useful to the programmer when developing a JSON_TABLE expression, as this allows a programmer to see the JSON value produced by a particular JSON path.
Figure 9. FORMAT JSON column definition
Listing 9 shows an example of using FORMAT JSON. In this example, we want to see the results of using various steps in an SQL/JSON path.
Listing 9. FORMAT JSON query
Figure 10 shows the result of running this query. The ALL column contains the JSON object, which is referenced by using '$'. The PHONES column reflects the JSON array corresponding to '$.phones'. The PHONE0 column returns the JSON object found in the first element of the phones array. Finally, the TYPE column contains the type of phone found within the first element of the phones array. Because FORMAT JSON is used and the result is a string value, the double quotes present in the original JSON object are also returned.
Figure 10. FORMAT JSON JSON_TABLE result
JSON_TABLE options
JSON_TABLE has a number of options that can be used to configure its behavior. There are options available for the uppermost level of JSON_TABLE as well as options for regular column definitions and FORMAT JSON column definitions.
At the uppermost level of JSON_TABLE, the error handling behavior can be specified. This behavior is either EMPTY ON ERROR or ERROR ON ERROR. The default is EMPTY ON ERROR which means that an empty table (that is, a table with no rows) is returned when a table level error is encountered. The ERROR ON ERROR setting indicates that an error should be returned.
Listing 10 shows an example of using the ERROR ON ERROR setting. Note that the context path uses the strict mode to force the error. Figure 11 shows the resultant error.
Listing 10. ERROR ON ERROR
Figure 11. Result of ERROR ON ERROR
For regular column definitions, the following six options are available to control the behavior when empty values are found or errors are encountered:
- Return NULL when empty
UseNULL ON EMPTYto returnNULLwhen the key is not found. - Return ERROR when empty
UseERROR ON EMPTYto cause an error to be issued when the key is not found. - Return a default value when empty
UseDEFAULT <value> ON EMPTYto return a literal value when the key is not found. - Return NULL on an error
UseNULL ON ERRORto returnNULLwhen the path expression encounters an error. - Return ERROR on an error
UseERROR ON ERRORto cause an error to be issued when the path expression encounters an error. - Return a default value on an error
UseDEFAULT <value> ON ERRORto return a literal value when the path expression encounters an error.
Listing 11 shows an example of using these settings and the corresponding output is shown in Figure 12. In this example, NULL is returned for the EMPTYCOL1 and ERRORCOL1 columns because the specified elements cannot be found. The use of strict mode in the path for ERRORCOL1 column causes the error to occur. For the EMPTYCOL2 and ERRORCOL2 columns, the specified 'EMPTY2' and 'ERROR2' strings are returned.
Listing 11. ON EMPTY and ON ERROR settings
Figure 12. ON EMPTY and ONE ERROR output
JSON_TABLE examples
The real power of JSON_TABLE can be seen when processing a JSON object that is retrieved from the web. The following examples demonstrate how to consume JSON values retrieved from various websites. These examples illustrate how JSON_TABLE can easily convert JSON data into relational information.
The United States Geological Survey provides a JSON feed of recent earthquake information. You can find the information about earthquakes within the last week at https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_week.geojson. You can view the information using a web browser as shown in Figure 13.
Figure 13. Earthquakes feed
From this information, we want to get a list of the recent earthquakes with their report times, magnitudes, and location. This can be accomplished using the SQL statement in Listing 12. In this statement, the SYSTOOLS.HTTPGETCLOB function is used to retrieve the JSON object from the website. This object is then used as the input to JSON_TABLE. After the input value is specified, the path 'lax $.features[*]' is used to retrieve all the earthquake information stored in the array specified by the "features" key. We then define three columns to contain the information for the time (in milliseconds), magnitude, and place of the earthquake. The SQL/JSON path expressions used to locate this information are defined for each column.
Listing 12. Earthquakes JSON_TABLE
__CODE_BLOCK_11__The beginning of the result of running this query is shown in Figure 14.
Figure 14. Earthquakes result
Figure 15. Results
Summary
JSON_TABLE is a powerful tool now available to process JSON data on DB2 for i. By using SQL/JSON path expressions to locate information in JSON objects, JSON_TABLE can place that information into the rows and columns of database tables. In conjunction with HTTP functions, JSON feeds can be consumed using SQL and combined with traditional forms of relational data.