Article
SQL indexes and native I/O – no contradiction
Profit from the use of SQL indexes when native I/O is usedArchive date: 2025-02-10
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.With every release and technology refresh, powerful enhancements are included in IBM DB2 for i. Among them, multiple enhancements for defining and modifying SQL- defined database objects, such as tables, views and indexes can be found.
Even though DDS is an outdated technology and DB2 for i enhancements primarily focus on SQL, a lot of companies refrain from defining their database objects with SQL in favor of DDS. The main reason for this hesitation is, data access in most (legacy) RPG and COBOL programs is performed in the traditional way, with the record-level access method. What these companies are not aware of is that SQL-defined database objects can be accessed with native I/O in the same way as DDS-described physical and logical files.
Logical file types
Before using SQL-defined database objects or translating existing DDS-described physical or logical file definitions into their SQL equivalents, we first have to differentiate between the various types of logical files.
DDS basically provides a single type of logical files while SQL principally includes two different object types, views and indexes.
DDS-described logical files
Traditionally DDS-described logical files are used in conjunction with native I/O for getting fast access to the data and reading the data in a predefined sequence. Those logical files include an access path, where a single or multiple independent key fields (compound key) are defined. With the help of these keys, it is possible to locate records or rows in a physical file or table and read the data in a predefined sequence.
Even though it is possible to define logical files without key information, they are rarely defined for use with native I/O.
A DDS-described logical file is not restricted to a single physical file or table, but multiple files can be joined together. A DDS-described logical file can be defined to reference DDS-described physical files or SQL tables. In joined logical files, it is even possible to combine DDS-described physical files and SQL-defined tables.
DDS-described logical files can include key definitions, but all key fields must be located within the same physical file or table. When a DDS-described logical file contains key definitions, it is referred to as a DDS-keyed logical file.
DDS-described logical files can either include all or a subset of fields or columns of the based physical files or tables. This method is often used for avoiding access to sensitive data, for example the salary or birthday. With this technique, it is even possible to access data with native I/O in SQL tables that include columns defined with data types that are not supported by DDS, RPG or COBOL, such as large objects (LOB) or XML documents.
When using logical files that include only a subset of the columns in the base table, only the predefined columns can be accessed with native I/O. If a native I/O write_action is performed against those logical (un-joined) files, the excluded columns are populated with their default values. When performing an _update operation, the values in the excluded columns remain untouched.
Additionally a DDS-described logical file can include SELECT / OMIT clauses, that is, rules for reducing data access at the row or record level.
When accessing data with native I/O, it is the programmer who decides which physical and logical files are needed and includes them directly in the source code. Once defined it is always used without any ifs, ands or buts. If a logical file to be accessed with native I/O is deleted, the program will crash with the next call.
When accessing the data with SQL methods, the query optimizer decides if_and _what access paths (defined keys) have to be used. Those access paths can be located in either DDS-keyed logical files or indexes. Even though a DDS-keyed logical file can be specified within an SQL statement, it is not recommended. Contrary to native I/O where the programmer decides and explicitly defines the logical files to be used, in SQL the decision is made by the query optimizer. Specifying a DDS-keyed logical file will not force the query optimizer to use exactly this access path. Instead, the specified DDS-keyed logical file first has to be analyzed. The query has to be rewritten, based on the physical files or tables and other information such as keywords or SELECT / OMIT clauses included in the DDS description of the logical file. The key information included in the DDS description, however, is ignored. After having rewritten the SQL statement, all available access paths located in either DDS-keyed logical files or SQL indexes or key constraints are evaluated with regard on the WHERE conditions, the JOIN information, the GROUP BY clause and the ORDER BY criteria. The access path decision is also influenced by the detail found in the Global Statistics Cache (GSC), which is managed by the SQL Query Engine (SQE) Statistics Manager.
SQL views
Using SQL views is a great concept for moving business logic into the database, masking the complexity of the SQL statements and reducing the final source code. An SQL view is based on an SQL SELECT statement and can include everything that is allowed within a SELECT statement with one exception (ORDER BY is not allowed). Within a view definition multiple physical files or tables and other views can be joined together by using any allowed join method. Scalar and / or user defined functions (UDFs) can be used for converting and modifying existing column values or for building new columns. Data can be condensed and summarized by including aggregate functions and GROUP BY clauses. With the use of UNION, INTERSECT, or EXCEPT expressions, multiple sub-SELECT statements can be merged together. Additionally common table expressions, hierarchical query clauses and nested sub-SELECT statements can be included.
Because SQL views cannot include an ORDER BY clause, they never include key information. Because of the lack of any key information, views do not have to be updated when adding, modifying, or deleting rows in the underlying tables. In this way, theoretically hundreds of views can be built over the same table without causing any performance decrease or increase in storage consumption.
SQL views can be used in composition with SQL like any physical file or table. Even though an ORDER BY clause is not allowed within the view definition, an ORDER BY clause can be added in the final SELECT statement when accessing a view. If the data has to be returned in a predefined sequence, the use of the ORDER BY clause is mandatory. Otherwise, there is no guarantee for the data to be always returned in the required sequence, because the SQL optimizer could decide to use a different access path.
SQL views are very powerful for moving business logic into the database, encapsulating complexity and even reducing source code, at least if the data access is performed using SQL.
Because of the lack of any key information, the use of SQL views with native I/O is rather restricted. .
SQL indexes
By default DDS-created physical files, SQL tables or SQL views do not include any key information. Key information can only be added to DDS physical files.
When accessing data located within SQL tables or physical files, the data is found and returned. Without additional access paths (SQL indexes, DDS-keyed logical files, or key constraints), the complete table or physical file is searched. A table scan is not a problem for small tables or physical files with a few hundred rows, but can be a time consuming process for large tables with several millions or even billions of rows.
In the SQL world, access paths for speeding up data access are stored in separate database objects, known as SQL indexes.
When using native I/O it is the programmer who specifies the logical files that have to be used without ifs and buts.
When running SQL statements, it is the query optimizer that makes the decision if and what access paths should be used. In this way, there is no reason to reference a DDS-keyed logical file or SQL index within an SQL statement. The optimizer analyzes the SQL statement, and validates the existing access paths (in DDS-keyed logical files and SQL indexes) by considering the information provided by the statistics manager about data composition. The optimizer might even decide combining multiple access paths for the same table or physical file in the same query. If the right access paths exist, the optimizer's decisions are more flexible and precise than most decisions a programmer can make.
SQL indexes can be built based on SQL-defined tables as well as DDS-described physical files.
SQL provides two different kinds of indexes.
- Binary radix tree indexes
Binary radix tree indexes are traditional access paths containing all key information. Traditional binary radix tree indexes can be compared with DDS-keyed logical files without any JOIN instruction, field or column selection, and SELECT / OMIT clauses. To provide fast data access, the key values are arranged in the form of a tree. To find the required key values, the index branches are traversed until the required leaf node(s) are found.
Figure 1 shows a small database table with a single key field containing names. It also shows the structure of a binary radix tree index which can be used for retrieving the record or row for a specific name or for returning the data ordered by the name.
Figure 1: Binary radix tree index – tree structure
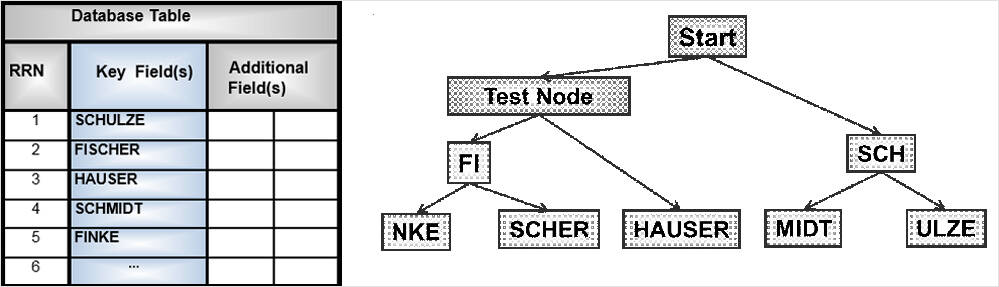
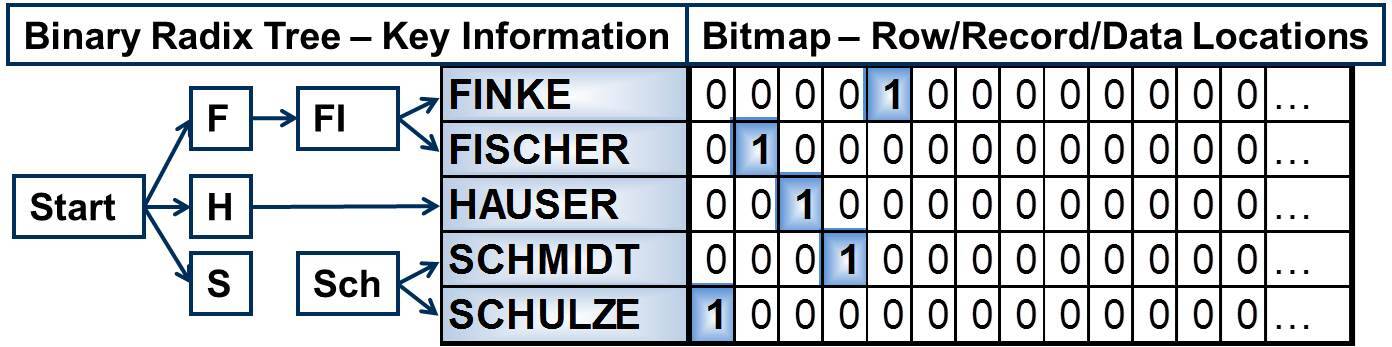
On the lowest level, behind the leaf is a bitmap containing the information about which row or record matches the key values. Based on this bitmap, the requested data itself can be located and retrieved from the database. When accessing data with SQL, binary radix tree indexes are considered (costed) if less than 15 % to 20 % of the rows in a table will be returned. Otherwise, a table scan is likely to be used. Figure 2 shows the binary radix tree and the bitmaps for the index.Figure 2: Binary radix tree index – bitmaps
- Encoded vector indexes (EVIs) Encoded vector indexes are special kind of indexes that can be used to get fast data access if between 20% to 70% of the rows or data in a table are being returned. But EVIs provide only restricted use for joining tables and / or ordering data.
With IBM i 6.1, both index types were enhanced. So newly generated key columns (derived indexes) and / or WHERE conditions (sparse indexes) can be included.
SQL indexes are not allowed to be specified within an SQL statement. The query optimizer can use all access paths in either DDS-keyed logical files or binary radix tree indexes, or encoded vector indexes.
When accessing data with native I/O, the programmer can even decide to use an SQL index. Binary radix tree indexes can be defined and used with native I/O similar to any DDS-keyed logical file. Encoded vector indexes are special SQL objects and cannot be accessed with native I/O.
Generating SQL indexes
SQL Indexes can be generated similar to any (SQL) database object by constructing and running the appropriate SQL commands.
New indexes (binary radix tree and EVIs) are generated with the CREATE INDEX statement.
Existing SQL indexes can be deleted with the DROP INDEX statement. Before re-creating an index, it first has to be deleted. There is no OR REPLACE option available in the CREATE INDEX statement.
Labels and longer comments can be added or modified by running a LABEL ON INDEX statement and / or a COMMENT ON INDEX statement.
Scripting tools
There are several interfaces available that allow those SQL commands to be typed in and executed immediately, for example the IBM i Navigator includes a Run SQL Script interface.
A similar Run SQL Script interface was added to the IBM i Access Client Solutions package in December, 2015 but it does not yet include all the options that are available in the based IBM i Navigator's Run SQL Script interface.
IBM i Access Client Solutions consolidates the most commonly used tasks for managing your IBM i into one simplified location. Refer IBM i Access Client Solutions for more information.
Figure 3 shows the IBM i Access Client Solutions Run SQL Script interface.
Figure 3: IBM i Access Client Solutions – Run SQL scripts

SQL indexes can be generated with the interactive SQL (STRSQL) green screen command interface. But STRSQL is an outdated technology and should no longer be used.
The SQL scripts entered and run with one of the Run SQL Script interfaces can be stored as a *.sql file on your workstation or as a stream file located within the integrated file system (IFS). Those stored SQL scripts can be reopened and rerun with either of these interfaces.
The IBM i Navigator Run SQL Script also allows SQL scripts being stored as traditional source physical file member.
SQL scripts stored in physical file members or as stream files in the IFS can be run either with the IBM i Navigator Run an SQL scripting tool or with the Run SQL Statements (RUNSQLSTM) CL command.
IBM i Navigator – wizards
The downside of the scripting tools is that the correct syntax of the SQL statements needs to be known because there are only restricted assistance and limited prompt methods. But both IBM i Navigator versions, Windows based and browser based, include a wizard for creating SQL indexes.
These wizards support all enhancements that have been added since IBM i 6.1, including the creation of new key columns based on an SQL expression or the addition of the WHERE conditions to an index. Even the special options necessary for native I/O can be set.
Figure 4 shows the IBM i Navigator wizard for creating all kinds of SQL indexes. In the options tab, you can enter native I/O options such as the record format or field or column selection.
Figure 4: IBM i Navigator – new index wizard – options tab

Accessing data with native I/O
The traditional method for accessing data with native I/O was to use DDS-keyed logical and physical files.
DDS is an outdated technology and most future DB2 for i improvements are focused on SQL. Therefore, it would be preferred
for IBM i clients to shift from DDS to the SQL Data Definition Language (DDL) even if the data access approach continues to use native I/O.
Using DDS-keyed logical files – the traditional Way
In legacy applications, data access is mostly performed with native I/O by specifying DDS-keyed logical files.
Listing 1 shows the DDS description of the ORDHL02 DDS logical file.
Listing 1: Keyed logical file – DDS description
A R ORDERHDRF PFILE(ORDERHDRX)
∗
∗ KEY FIELDS
A K COMPANY R
A K DELDATE R
A K ORDERNO R
A K STATUS R
∗
∗ SELECT / OMIT When accessing the ORDHL02 keyed logical file with native I/O all fields or columns defined within the underlying ORDERHDRX physical file or table are loaded.
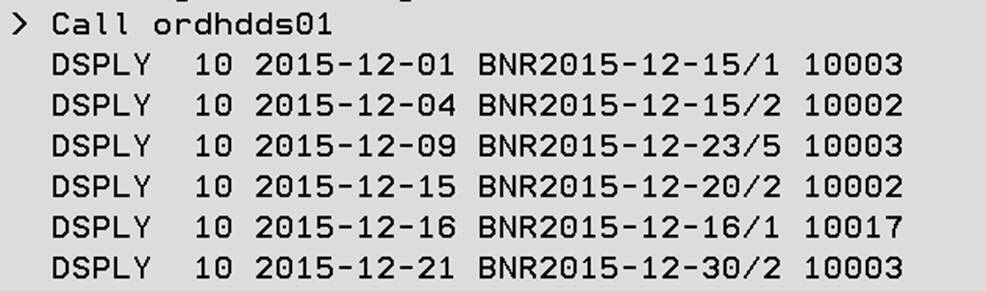
The ORDHDDS01 RPG program whose source code is shown in Listing 2 uses native I/O to read all orders for a specific company number (COMPANY=10) that were delivered in a specific date range (December 2015). Because the ORDHL02 DDS-keyed logical file is used, it first has to be defined within the F-Specs.
Within the C-Specs the ORDHL02 keyed logical file is positioned on the first row with the required company (COMPANY = 10) and the from delivery date (FROMDELDATE = '2015-12-01'). All rows with the same company and a delivery date starting with the from delivery date up to the to delivery date (TODELDATE = '2015-12-31') are read in a loop.
To keep it easy, only company no, delivery date, order no and customer no of the read records are displayed using the DSPLY RPG Operations code.
The Listing 2 example is coded by using RPG free format F- and D-Specs, but also works with fixed format F- and D-Specs.
Listing 2: Leveraging DDS-keyed logical files with native I/O
DCL‑F ORDHL02 Keyed Rename(OrderHdrF: ORDHL02F);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCompany Int(5) Inz(10);
DCL‑S FromDelDate Date(∗ISO) inz(D'2015‑12‑01');
DCL‑S ToDelDate Date(∗ISO) inz(D'2015‑12‑31');
DCL‑S Text VarChar(50);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑ ‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
SetLL (KeyCompany: FromDelDate: '') ORDHL02;
DoU %EOF(ORDHL02) = ∗On;
ReadE (KeyCompany) ORDHL02;
If %EOF(ORDHL02)
or DelDate > ToDelDate;
Leave;
EndIf;
Text = %Char(Company) + ' ' + %Char(DelDate: ∗ISO) + ' ' +
%Trim(OrderNo) + ' ' + %Trim(CustNo);
Dsply Text;
EndDo;
Return; If we run this program, the result rows as shown in Figure 5 will be returned. All orders for company 10 delivered in December 2015 are listed in the sequence of the delivery date and order number.
Figure 5: Result – leveraging keyed logical files with native I/O
Using traditional SQL indexes in composition with native I/O
The ORDHDRL02 logical file consists of the key information, that is, lists all key fields in the sequence to be ordered. Additionally, it includes all other columns or fields defined within the base SQL table or DDS-described physical files.
Similar to a DDS-keyed logical file, a traditional SQL index includes basically all key information and (for native I/O) all columns of the base table. When performing WRITE, UPDATE or DELETE native operations a different format name that does not match the file name is required. If the file does not include a different format name, the format name which is identical to the file name can be renamed within the source code.
Even though the SQL standard does not include file formats, different format names can be defined in DB2 for i tables, views, and indexes by adding the RCDFMT keyword. If an SQL index is created without explicitly including the RCDFMT keyword, the format of the base physical file/SQL table is adopted.
Listing 3 shows the SQL script with the CREATE INDEX statement of the ORDERHDRX_I02 SQL index which is the equivalent for the ORDHL02 DDS-keyed logical file. The SQL index includes the access path by defining the four key columns, COMPANY, DELDATE, ORDERNO and STATUS. When accessing the ORDERHDRX_I02 index with native I/O, all columns of the base table are available.
Because the ORDERHDRX_I02 SQL index name exceeds 10 characters, a 10 character system name is needed. To prevent DB2 for i from generating a unique system name, the FOR SYSTEM NAME clause is used and the ORDHI02 system name is defined.
The index definition does not include an explicit RCDFMT (record format) clause. So the record format name from the ORDERHDRX base table is inherited. When defining the index in RPG within the F-Specs, the index name or the record format name can be directly used. But, it also possible to rename the format with the RENAME RPG keyword and use the renamed record format within the program.
Listing 3. Listing 3: SQL script – creating ORDERHDRX_I02 binary radix index
Create Index ORDERHDRX_I02 For System Name ORDHI02
On ORDERHDRX
(COMPANY Asc, DELDATE Asc, ORDERNO Asc, STATUS Asc);
Label On Index ORDERHDRX_I02
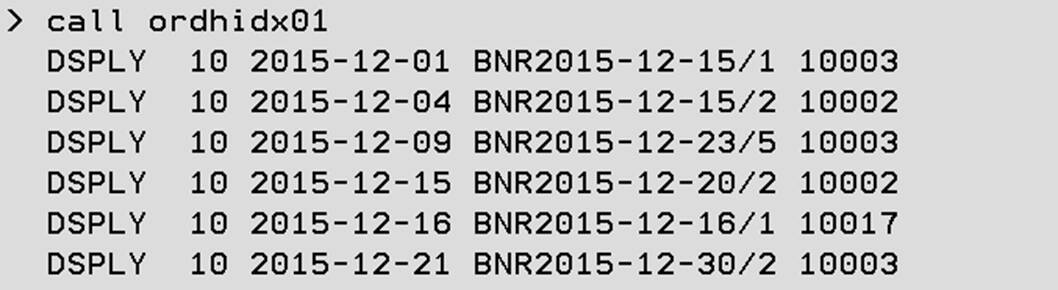
is 'Order header ‑ Company/Del.Date/Order/Status'; Listing 4 shows the source code for the ORDHIDX01 RPG program. This example produces equivalent results as the native I/O ORDHDDS01 program in the Listing 2 example. ORDHIDX01 differs from, ORDHDDS01 by using an SQL index instead of a DDS-keyed logical file.
Listing 4: Leveraging binary radix tree indexes with native I/O
DCL‑F OrdHI02 Keyed Rename(OrderHdrF: OrdHI02F);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCompany Int(5) Inz(10);
DCL‑S FromDelDate Date(∗ISO) inz(D'2015‑12‑01');
DCL‑S ToDelDate Date(∗ISO) inz(D'2015‑12‑31');
DCL‑S Text VarChar(50);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
SetLL (KeyCompany: FromDelDate: '') OrdHI02;
DoU %EOF(OrdHI02) = ∗On;
ReadE (KeyCompany) OrdHI02;
If %EOF(OrdHI02)
or DelDate > ToDelDate;
Leave;
EndIf;
Text = %Char(Company) + ' ' + %Char(DelDate: ∗ISO) + ' ' +
%Trim(OrderNo) + ' ' + %Trim(CustNo);
Dsply Text;
EndDo;
Return; If we run this example, we see the same information in Figure 6. The data seen has the same sequence as in the previous example (see Figure 5).
Figure 6: Result – leveraging binary radix indexes with native I/O
SQL DDL, including SQL indexes has support for long SQL names and short system names. In the fixed format F-Specs there was no way to use the long SQL names for tables or indexes. The fixed form file definition (F-specs position 7 to 16) was restricted to 10 characters. The longer SQL column names however could already be used before full-free F- or D-specs were introduced. For using the long column names, the ALIAS keyword must have been added to the file definition in the F-specs.
Beginning with the free format F-specs, long SQL names can be used, but the EXTDESC keyword has to be specified to indicate the compiler which file based on the system name should be used at the compilation time to obtain the external file description. For using the SQL name at runtime, the EXTFILE(*EXTDESC) keyword has to be added.
The zip code information necessary for checking the zip code range in the ORDHIDX02 program in Listing 6 must be taken from the ADDRESSX address master table.
Listing 5 shows the unique key index definition of the ADDRESX_U01 index built over the ADDRESSX address master table.
Listing 5: SQL script – creating the ADDRESSX_U01 unique key index
Create Unique Index ADDRESSX_U01 For System Name ADDRU01
On ADDRESSX
(CUSTNO Asc)
RcdFmt ADDRESSF Add All Columns;
Label On Index ADDRESSX_U01
is 'Address Master ‑ CustNo'; Because the short system names are sometimes rather cryptic especially when the system names are automatically generated, using the longer SQL names would be preferred.
Listing 6 shows the RPG code for the ORDHIDX RPG program where the long SQL names for the ORDERHDRX_I02 and ADDRESSX_U01 indexes are used. To associate the long SQL names, the short system names are specified on the EXTDESC keyword.
Listing 6: Leveraging indexes with native I/O using long SQL names
DCL‑F OrderHdrX_I02 ExtDesc('ORDHI02') ExtFile(∗ExtDesc) Keyed;
DCL‑F AddressX_U01 ExtDesc('ADDRU01') ExtFile(∗ExtDesc) Keyed;
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCompany Int(5) Inz(10);
DCL‑S FromDelDate Date(∗ISO) inz(D'2015‑12‑01');
DCL‑S ToDelDate Date(∗ISO) inz(D'2015‑12‑31');
DCL‑S Text VarChar(50);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
SetLL (KeyCompany: FromDelDate: '') OrderHdrX_I02;
DoU %EOF(OrderHdrX_I02) = ∗On;
ReadE (KeyCompany) OrderHdrX_I02;
If %EOF(OrderHdrX_I02)
or DelDate > ToDelDate;
Leave;
EndIf;
Chain (CustNo) AddressX_U01;
If Not %Found(AddressX_U01);
Iter;
ElseIf ZipCode < '73000' or ZipCode > '75999';
Iter;
EndIf;
Text = %Char(Company) + ' ' + %Char(DelDate: ∗ISO) + ' ' +
%Trim(OrderNo) + ' ' + %Trim(CustNo) + ' ' +
%Trim(ZipCode);
Dsply Text;
EndDo;
Return; If we run the ORDHIDX02 program the rows as shown in Figure 7 are returned.
Figure 7: Result – leveraging indexes with native I/O using SQL names

Manipulating data with native I/O using SQL indexes
It is even possible to perform WRITE, UPDATE, and DELETE operations with native I/O using SQL indexes. In the ORDHIDX03 RPG Program, shown in Listing 9, all order header and appropriate order detail rows for all orders delivered in August 2015 are copied into history tables and deleted from the order header and order detail tables.
The ORDERHDRX_HIST and ORDERDETX_HIST history tables are SQL-defined tables and include all columns of the original order tables and a few additional columns. Some of the additional columns use SQL-specific features.
Listing 7 contains the CREATE TABLE statement for the ORDERHDRX_HIST order header history table and the ORDERDETX_HIST order detail history table. Both history tables include a column defined with the IDENITTY keyword. This column is automatically updated when inserting a new row, regardless of whether SQL or native I/O is used to insert the row. To prevent duplicate identity values a PRIMARY KEY CONSTRAINT built over the identity column is included.
Both tables also include a timestamp column defined with a ROW CHANGE TIMESTAMP expression that causes the column value to be updated with the current timestamp. Again DB2 for I will provide the same behavior regardless of whether SQL or native I/O is used.
To enable native I/O usage different record format names are specified using the RCDFMT keyword.
Listing 7: SQL script – creating order header history and order detail history tables
‑‑ Order header History – Table
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
Create Or Replace Table ORDERHDRX_HIST
For System Name ORDERHDRXH
( OHIDHIST Integer Generated Always
as Identity(Start With 1 Increment By 1
No MinValue No MaxValue
No Cycle No Order
Cache 20),
COMPANY SmallInt Not NULL Default 0,
ORDERNO Char(15) Not NULL Default '',
CUSTNO Char(15) Not NULL Default '',
ORDERTYPE Char(3) Not NULL Default '',
DELDATE Date Not NULL Default '0001‑01‑01',
DELTERMS Char(3) Not NULL Default '',
STATUS Char(3) Not NULL Default '',
WRTDATTIM Timestamp Not NULL
For Each Row On Update
as Row Change Timestamp,
WRTUSER VarChar(20) Not NULL Default User,
Constraint ORDERHDRXH_PrimKey Primary Key (OHIDHIST) )
RcdFmt ORDERHDRHF;
‑‑ Order detail History – Table
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
Create Or Replace Table ORDERDETX_HIST
For System Name ORDERDETXH
( ODIDHIST Integer Generated Always
as Identity(Start With 1 Increment By 1
No MinValue No MaxValue
No Cycle No Order
Cache 20),
COMPANY SmallInt Not NULL Default 0,
ORDERNO Char(15) Not NULL Default '',
ORDERPOS SmallInt Not NULL Default 0,
ITEMNO Char(22) Not NULL Default '',
ORDERQTY Integer Not NULL Default 0,
DELQTY Integer Not NULL Default 0,
STATUS Char(3) Not NULL Default '',
WRTDATTIM Timestamp Not NULL
For Each Row On Update
as Row Change Timestamp,
WRTUSER VarChar(20) Not NULL Default User,
Constraint ORDERDETXH_PrimKey Primary Key (ODIDHIST) )
RcdFmt ORDERDETHF;
For performing the native I/O database manipulations, the following indexes are added to the ORDERHDRX order header, the ORDERDETHDRX order detail, and the ORDERHDRX_HIST and ORDERDETX_HIST order history tables.
Listing 8 shows the SQL used to create the indexes which include all columns of the base table and the specified record formats match the record format names of the base tables.
Listing 8: SQL script – creating indexes for the history tables
‑‑ Order header ‑ Index
Create Index ORDERHDRX_I03 For System Name ORDHDRI03
On ORDERHDRX
(DELDATE Asc, COMPANY Asc, ORDERNO Asc)
RcdFmt ORDERHDRF Add All Columns;
‑‑ Order header History – Index: Company, OrderNo, WrtDatTim
Create Index ORDERHDRX_HIST_I02 For System Name ORDHHI02
On ORDERHDRX_HIST
(COMPANY Asc, ORDERNO Asc, WRTDATTIM Dessc)
RcdFmt ORDERHDRHF Add All Columns;
‑‑ Order detail Index
Create Unique Index ORDERDETX_U01 For System Name ORDDU01
On ORDERDETX
(COMPANY Asc, ORDERNO Asc, ORDERPOS Asc)
RcdFmt ORDERDETF Add All Columns;
‑‑ Order detail History – Index:
Create Index ORDERDETX_HIST_I02 For System Name ORDDHI02
On ORDERDETX_HIST
(COMPANY Asc, ORDERNO Asc, ORDERPOS Asc, WRTDATTIM Desc)
RcdFmt ORDERDETHF Add All Columns;
These indexes are used for copying and deleting old order data.
For native I/O the indexes must be registered within the F-Specs and enabled for the different operations, as shown in the ORDHIDX03 RPG program in Listing 9.
Data from the order header and order detail tables is only read through the ORDERHDRX_I02 and the ORDERDETX_I02 indexes and deleted after the data is written to the history tables. Therefore both indexes are defined with the USAGE (*DELETE) keyword in the F-Specs.
Data read from the order tables is written to the order history tables using the ORDERHDRX_HIST_I02 and ORDERDETX_HIST_I02 indexes. Because no other operation is performed on the history tables, these indexes only need the USAGE (*OUTPUT) keyword.
For performing the native I/O WRITE, UPDATE and / or DELETE operations, the record format name has to be used. If the file, table or index name and the format name is identical, the format has to be renamed within the F-Specs by using the RENAME keyword. Because the format names of the indexes used in the example differ from the integrated format names renaming is not necessary. In this example they are renamed just for easier assignment.
The ORDERHDRX_I02 order header index is positioned to the start delivery date, and all order header rows up to the end date are read in a loop.
Because the column names (except the additional ones) in the order header and order header history table are identical, there is no need to explicitly move those column contents into the order header history table.
The only information that is explicitly added to the history row is the CURRENT_USER from the program status data structure.
The next identity column value, as well as the current timestamp information are automatically determined and set, when writing a new row with native I/O into the history file. The renamed format name is specified with the WRITE operation.
Listing 9 shows the RPG source code for the ORDHIDX03 program.
Listing 9: Modifying data with native I/O in conjunction with indexes
DCL‑F OrderHdrx_I03 ExtDesc('ORDHDRI03') ExtFile(∗ExtDesc)
Commit
Usage(∗Delete) Keyed
Rename(OrderHdrF: OrdHdrXF03);
DCL‑F OrderHdrX_Hist_I02 ExtDesc('ORDHHI02') ExtFile(∗ExtDesc) Commit
Usage(∗Output)
Rename(OrderHdrHF: OrdHHstF02);
DCL‑F OrderDetX_U01 ExtDesc('ORDDU01') ExtFile(∗ExtDesc) Commit
Usage(∗Delete) Keyed
Rename(OrderDetF: OrdDetXF01);
DCL‑F OrderDetX_Hist_I02 ExtDesc('ORDDHI02') ExtFile(∗ExtDesc) Commit
Usage(∗Output);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑DS PGMSDS PSDS Qualified;
MsgTxt Char(70) Pos(91);
CurrUser Char(10) Pos(358);
End‑DS;
DCL‑S FromDelDate Date(∗ISO) inz(D'2015‑08‑01');
DCL‑S ToDelDate Date(∗ISO) inz(D'2015‑08‑31');
DCL‑S Text VarChar(50);
DCL‑S NextRow Ind;
DCL‑S SaveDelDate Date(∗ISO);
DCL‑S SaveOrderNo Like(OrderNo);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
//Delete Order header / Order details
Commit;
SetLL (FromDelDate: ∗LoVal) OrderHdrx_I03;
DoU %EOF(OrderHdrx_I03);
Monitor;
//1. Read all Order headers within a specific date range
// 1.1. Write the Order header Rows into History File
Read OrdHdrxF03;
If %EOF(OrderHdrx_I03)
or DelDate > ToDelDate;
Leave;
EndIf;
WrtUser = PGMSDS.CurrUser;
Write OrdHHstF02;
// 1.2. Read all Order details for the current Order
// 1.2.1 Write the Order detail rows into History file
// 1.2.2 Delete the appropriate Order detail row
SetLL (Company: OrderNo: ∗LoVal) OrderDetX_U01;
DoU %EOF(OrderDetX_U01);
ReadE (Company: OrderNo) OrdDetXF01;
If %EOF(OrderDetX_U01);
Leave;
EndIf;
WrtUser = PGMSDS.CurrUser;
Write OrderDetHF;
Delete OrdDetXF01;
EndDo;
// 1.3. Delete the Order header Row
Delete OrdHdrXF03;
Commit;
On‑Error;
SaveDelDate = DelDate;
SaveOrderNo = OrderNo;
Rolbk;
SetGT(SaveDelDate: SaveOrderNo) OrderHdrX_I03;
Iter;
EndMon;
EndDo;
Commit;
Return; Enhanced indexing technologies
Before IBM i 6.1, SQL indexes could only be built over existing columns in the base tables.
Sometimes however, column values include different information and need to be split into different (key) columns, so that the data can be accessed and sorted in the appropriate sequence.
For example, what if the customer number column value was overloaded to include a country label and a customer category. While this is not ideal data model design, it might be encountered.
For a specific report, customers with the same customer category located in a specific country have to be grouped together. When generating this report with SQL, an SQL scalar function (SUBSTR) has to be used on the left side of the comparison operator in the WHERE condition. The usage of a function on a search predicate, however, prevented the optimizer from using an index to speed up the selection processing.
Before IBM i 6.1 there was no way of generating key columns in an index over a column in the base table that was modified by a scalar function, for example SUBSTR (CUSTNO, 3, 2), UPPER (NAME) or YEAR (SALESDATE).
With native I/O that data could only be accessed and returned in the desired sequence by using a DDS-keyed logical file with additional columns for the customer number to be split into different pieces using the SST (substring) keyword.
In DDS-described logical files it is not only possible to split columns but also to concatenate several columns together with the CONCAT keyword. For example a date might be stored in three columns, a year, a month and a day column, instead of a single column. Even though DDS has some capabilities for including functions for defining key columns it is rather restricted.
Beginning with IBM i 6.1, derived and sparse indexes were introduced in DB2 for i. Derived indexes are also known as function-based indexes while with sparse indexes WHERE conditions can be added to an index. Both binary radix tree and encoded vector indexes can include key derivations and selection criteria in the index definition.
The derived key index support is a significant addition for speeding up the selection processing.
A traditional index contains a key value for every row in the table while a sparse index contains only a key value for a subset of the rows in the table. The condition on the WHERE clause effectively limits the key values to only those rows in the table that meet the specified search condition or conditions.
How derived and sparse indexes can help and can be used with native I/O is demonstrated in the following examples.
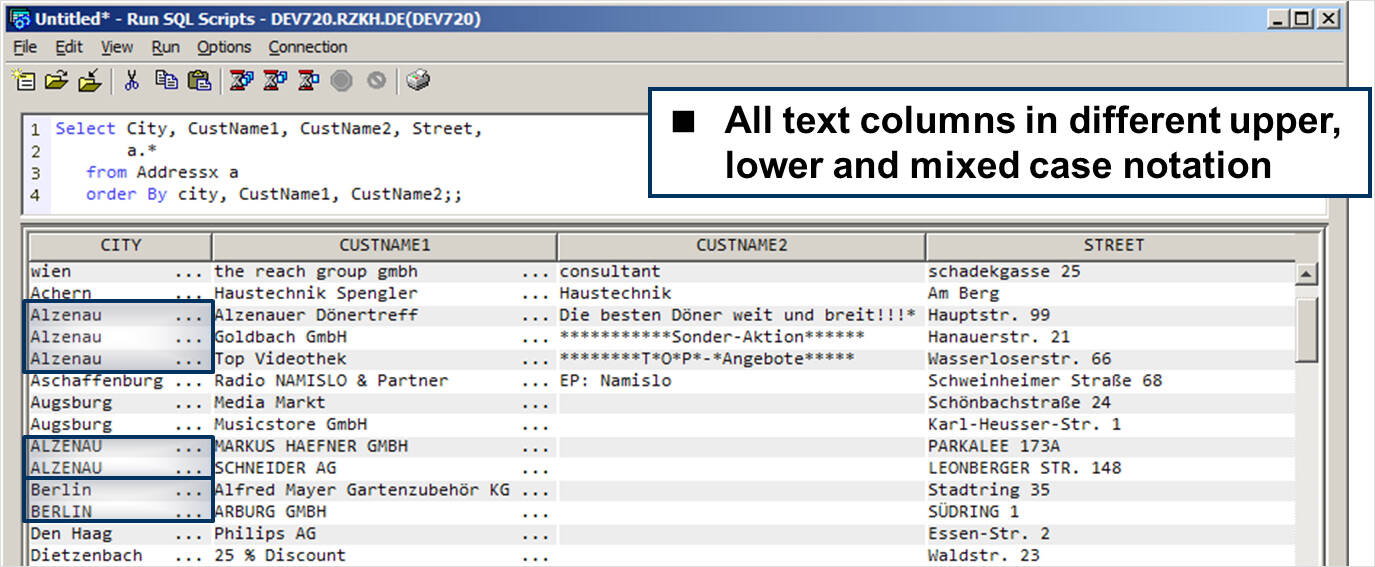
Figure 8 shows the ADDRESSX address master table content where the city, customer names and street are entered in either upper, lower or mixed case notation. For a specific report, all customers located in a specific country must be returned.
The result rows must be ordered by the CITY column value, but independent of the case notation.
Figure 8: Address master table content
Traditional indexes and sort sequences
If we want to create the report with native I/O, we are faced with the problem that the city, the customer names and address use in different case notations.
When creating DDS-keyed logical files or SQL index, the hexadecimal sort sequence is used. When reading the data, values entered in small letters are returned first, followed by the values entered in mixed case, and finally with data values in capital letters. The sort sequence is: abcde … xyzABCDE … XYZ.
To get the records returned to be independent of the upper or lower case notation, the sort sequence must be set *LANGIDSHR (shared-weight sort sequence table). The sort sequence of an index is inherited from the session or connection in which the index is created.
- When creating the index with the IBM i Navigator Run SQL Script facility, sort sequence and language ID can be set over Connection → JDBC Settings → Language.
- When running the CREATE INDEX statement stored in either a source member or an IFS file with the RUNSQLSTM (Run SQL Statement) CL command, sort sequence and language ID can be set through the SRTSEQ and LANGID options in the command.
- If the RUNSQL (Run SQL) CL command is used to perform the CREATE INDEX statement, sort sequence and language ID can also be set through the SRTSEQ and LANGID options.
- When creating the index with the IBM i Navigator wizard, sort sequence and language can directly be selected.
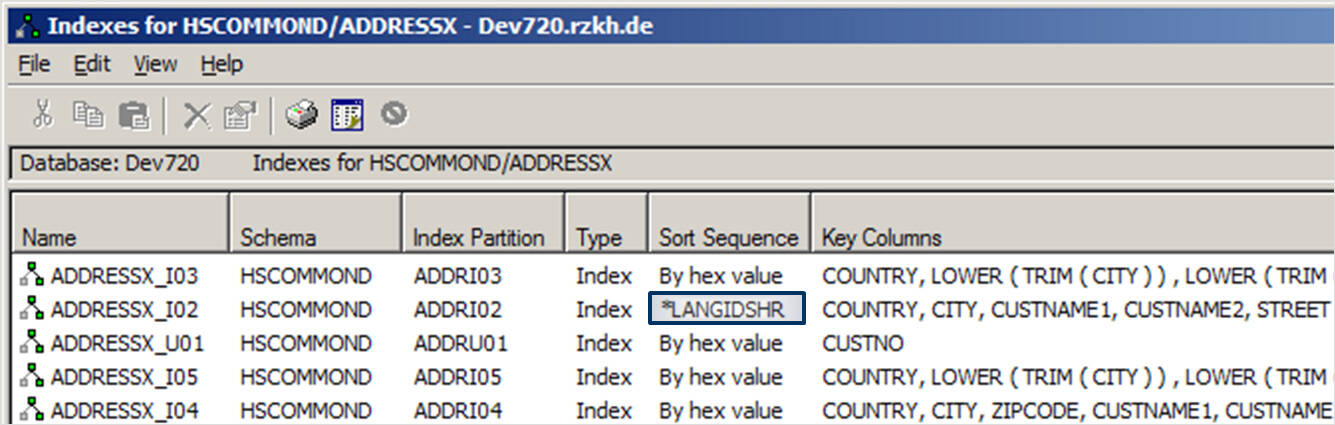
Figure 9 shows the definition of the ADDRESSX_I02 traditional index that is accessed in the next RPG example. The CREATE INDEX statement is run through the RUNSQL CL command. Sort sequence and language ID are both set with the RUNSQL statement.
Figure 9: Creating the ADDRESSX_I02 index with the LANGIDSHR sort sequence

Figure 10 is the output from the IBM i Navigator show indexes confirming that the ADDRESSX_I02 index is being generated with the *LANGIDSHR sort sequence.
Figure 10: List indexes – display sort sequence
Listing 10 shows the source code of the ADDRIDX01 RPG program, where the ADDRESSXI02 index is read in a loop. The index is first positioned with the country Value (COUNTRY = D = Germany) and the city value (CITY = _frankfurt in lower case letters). Only rows with a city value of Frankfurt (in any case) are processed. The loop ends when the end of file is reached or as soon as the city value no longer matches Frankfurt.
For comparison issues, the city values are converted into lower case characters by using the %XLATE built-in function.
Because the *LANGIDSHR sort sequence is used on the index, all rows containing a city value name equal to any case variant of FRANKFURT are returned, so there is no need to iterate any rows.
Listing 10: Leveraging SQL indexes with sort sequence and native I/O
DCL‑F ADDRESSX_I02 ExtDesc('ADDRI02') ExtFile(∗ExtDesc) Keyed;
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCountry Like(Country) inz('D');
DCL‑S KeyCity Like(City) inz('frankfurt');
DCL‑S Text VarChar(50);
DCL‑S CompareCity Like(City);
DCL‑S UpperLetter VarChar(26) inz('ABCDEFGHIJKLMNOPQRSTUVWXYZ');
DCL‑S LowerLetter VarChar(26) inz('abcdefghijklmnopqrstuvwxyz');
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
CompareCity = KeyCity;
SetLL (KeyCountry: KeyCity: ∗Loval) AddressX_I02;
DoU %EOF(AddressX_I02) = ∗On;
ReadE (KeyCountry) AddressX_I02;
If %EOF(AddressX_I02)
or %Xlate(UpperLetter: LowerLetter: City) <> CompareCity;
Leave;
EndIf;
Text = %Subst(City: 1: 15) +' '+ %Subst(ZipCode: 1: 5) +' '+
%Subst(CustNo: 1: 7) +' '+ %Subst(CustName1: 1: 20);
Dsply Text;
EndDo;
Return; When running the ADDRIDX01 RPG program, the results returned are as shown in Figure 11.
Figure 11: Result – leveraging indexes with sort sequence

Derived indexes
When creating and using indexes with a specified sort sequence, this sort sequence is adopted for all columns. There is no way to define one key column with a hexadecimal sort sequence while a different key column uses a shared-weight sequence.
With derived indexes scalar functions, arithmetic operators and character operators can be used to define new key columns based on SQL expressions. In this way, it is possible to generate a key column in conjunction with the LOWER scalar function for a case insensitive search, while other character key values are not modified.
Listing 11 shows the SQL script containing the CREATE INDEX statement for the ADDRESSX_I03 index. The COUNTRY column is a character column, but includes only uppercase country labels. So the index key can simply reference the column name.
All other key columns are defined based on an SQL expression. These SQL expressions first remove all leading and trailing blanks from the column values by using the TRIM scalar function. The remaining characters are converted into lowercase letters with the LOWER scalar function. For the additional key columns long SQL names as well as short system names are defined.
A different format name to be used with native I/O is added by specifying the RCDFMT keyword.
The index includes all table columns as well as the key columns based on SQL expressions.
Listing 11: SQL script – creating ADDRESSX_I03 derived index
Create Index ADDRESSX_I03 For System Name ADDRI03
on ADDRESSX
(COUNTRY,
Lower(Trim(City)) as CITY_LOWERCASE
For Column LOWCITY,
Lower(Trim(CustName1)) as CUSTNAME1_LOWERCASE
For Column LOWNAME1,
Lower(Trim(CustName2)) as CUSTNAME2_LOWERCASE
For Column LOWNAME2,
Lower(Trim(Street)) as STREET_LOWERCASE
For Column LOWSTREET)
RcdFmt ADDRESSXF
Add All Columns;
Listing 12 shows the source code of the ADDRIDX02 RPG program, where all rows with the country label of Germany (D) and the city of Frankfurt are processed. Because the key column includes all city values in lower case characters, there is no need to convert and compare the city values. Instead the rows can be directly read with a partial key, consisting of the COUNTRY and CITY_LOWERCASE key columns.
Listing 12: Leveraging derived indexes with native I/O
DCL‑F ADDRESSX_I03 ExtDesc('ADDRI03') ExtFile(∗ExtDesc) Keyed;
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCountry Like(Country) inz('D');
DCL‑S KeyCity Like(City) inz('frankfurt');
DCL‑S Text VarChar(50);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
SetLL (KeyCountry: KeyCity: ∗Loval) AddressX_I03;
DoU %EOF(AddressX_I03) = ∗On;
ReadE (KeyCountry: KeyCity) AddressX_I03;
If %EOF(AddressX_I03);
Leave;
EndIf;
Text = %Subst(City: 1: 15)+' '+ %Subst(ZipCode: 1: 5) +' '+
%Subst(CustNo: 1: 7)+' '+ %Subst(CustName1: 1: 20);
Dsply Text;
EndDo;
Return; Figure 12 shows the result of running the ADDRIDX02 RPG program. The result matches the result of the previous RPG example exactly, where a traditional index with a sort sequence was used (see Figure 11).
The RPG code in ADDRIDX02 is as simpler as the RPG code in ADDRIDX01, because an improved index strategy is used in place of the (RPG) source code.
Figure 12: Result – Leveraging derived indexes

Derived indexes are even more powerful.
Key column expressions can include arithmetic operators such as +, - , * and /. It is even possible to use nested parenthesis.
Additionally, a wide range of scalar functions can be used for key column expressions. But there are several exceptions:
- Several date and time functions, such as DAYNAME, MONTHNAME, WEEK_ISO, TIMESTAMP_FORMAT, or VARCHAR_FORMAT are not supported.
- A few string functions such as REPLACE, REPEAT, LPAD, or RPAD and all regular expression scalar functions are not supported.
- Encryption and decryption scalar functions are not supported.
- Unfortunately UDFs are not supported for key column expressions. A homegrown UDF for converting numeric dates into real dates cannot be used, but an SQL expression consisting of multiple nested scalar functions can be specified directly.
The SALES7N sales table includes the SALESDATE7 column in which the sales date is stored as a 7-digit numeric date value in the CYYMMDD format.
Listing 13 contains an index definition that includes two key columns (CUSTNO and ITEMNO) from the base table SALES7N.
The SALES_DATE and SALES_WEEKDAYISO key columns are defined based on the SQL expressions. In both expressions, the 7-digit numeric date value is converted into a real date. To get an 8-digit numeric date value in the YYYYMMDD format. 19000000 is added first to the 7-digit numeric value. The resulting 8-digit numeric date value is converted to a character representation using the DIGITS scalar function. The date character representation is concatenated with '000000' to get a valid timestamp representation in the YYYYMMDDHHMMSS format. This timestamp representation is finally converted into a real date by using the DATE scalar function.
The SALES_WEEKDAYISO column contains the day of week according to ISO guidelines (Monday=1, Sunday=7), which is determined from the converted sales date by using the DAYOFWEEK_ISO scalar function.
Listing 13: SQL script – creating SALES7N_I01 derived index with date conversion and scalar functions in the key expressions
Create Index SALES7N_I01 For System Name SALES7NI01
On SALES7N
(Date(Digits(Dec(SalesDate7 + 19000000, 8, 0)) concat '000000')
as Sales_Date For Column SalesDate,
CustNo,
ItemNo,
DayOfWeek_ISO(Date(Digits(Dec(SalesDate7 + 19000000, 8, 0))
concat '000000'))
as Sales_WeekDayISO For Column WeekDay)
RcdFmt SALES7NF
Add All Columns;
When using this index with native I/O, real date values and even the day of week are available. There is no need to perform those conversions and calculations within the (RPG) source code. This could be a big advantage if the company, in future, might replace the numeric date values with real date values. At that time, only the index needs to be re-created by replacing the SQL expression with the new date column. The native I/O program, however, can stay untouched.
SQL expressions in derived indexes can also include CASE expressions.
Listing 14 shows the ORDERDETX_I02 index definition which contains several key columns based on SQL expressions with the CASE clauses.
The STATUS column in the order detail table contains a character representation (CL=Cancelled, EN=Order entered, PD=Partly Delivered, CP=Completely Delivered) that does not match the output sequence necessary for a specific report.
The SORTSTATUS key column processes the STATUS values with the aid of a CASE clause producing numeric values. When using this index in conjunction with native I/O all positive SORTSTATUS values, can be read in any order to meet the business requirements. In this case, we begin by reading all rows with the entered status (EN) followed by the rows with the partly delivered status (PD) ending with the completely delivered status (CP) rows.
The NOTYETDELIVERED key column contains the difference between the order and delivery quantity for all statuses except the cancelled one. These column values are returned in a descending order.
Listing 14: SQL script – creating ORDERDETX_I02 derived index with the CASE clauses in the key expressions
Create Index OrderDetx_I02 For System Name OrdDI02
on OrderDetx
(Cast(Case Status when 'EN' Then 10
When 'CL' Then ‑10
When 'PD' Then 50
When 'CP' Then 100
Else ‑99
End as Integer)
as SortStatus For Column SortSts,
Cast(Case When Status in ('EN', 'PD', 'CP')
Then OrderQty ‑ DelQty
else 0
End as Dec(11, 2))
as NotYetDelivered For Column NotYetDel Desc,
Company, OrderNo, OrderPos)
RcdFmt OrderDetF
Add All Columns;
Sparse indexes
With the SELECT / OMIT clause in DDS-keyed logical files, the number of records to be returned and accessed can be reduced, but the definition is rather cryptic and restricted.
Beginning with IBM i 6.1, sparse indexes were introduced permitting a WHERE clause to be used on the CREATE INDEX statement.
The syntax of the WHERE conditions in the index definition matches the syntax in a SELECT statement. Multiple conditions can be specified, logical operators such as AND, OR and NOT can be used, parenthesis can be set, a wide range of scalar functions can be used, and even several predicates such as LIKE or IN are allowed.
Listing 15 shows an example where the ADDRESSX_I04 sparse index is generated. When using this index, only rows including a country value of D (Germany), A (Austria), and CH (Swiss) are considered. Besides having the index to include selection by country label, the rows returned by the index are reduced further by checking whether the company is incorporated in Germany. This is accomplished by examining the CUSTNAME1 and CUSTIMERNAME2 columns for any instance of the string 'gmbh' (GmbH = Incorporated/Inc. in German).
Listing 15: SQL script – creating the ADDRESSX_I04 sparse index
Create Index ADDRESSX_I04 For System Name
ADDRI04 On ADDRESSX (COUNTRY, CITY, ZIPCODE, CUSTNAME1, CUSTNAME2) WHERE COUNTRY in ('D',
'A', 'CH') and Lower(Trim(CUSTNAME1) concat ' ' concat Trim(CUSTNAME2)) like '%gmbh%' RcdFmt
ADDRESSXF Add All Columns; Listing 16 shows the source code for the ADDRIDX04 RPG program where all rows with customers from Frankfurt in Germany who include GMBH somewhere in the CUSTNAME1 column or CUSTNAME2 column in any case are read and displayed.
Because the original columns are used as key columns and the city name is entered in different upper case and lower case notations, the city value is converted into lowercase to be compared with the original key value. If the city value does not match, the row is ignored and the next record is accessed. There might be multiple rows containing other cities between Frankfurt, Frankfurt and FRANKFURT.
Listing 16: Leveraging sparse indexes with native I/O
DCL‑F ADDRESSX_I04 ExtDesc('ADDRI04') ExtFile(∗ExtDesc) Keyed;
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCountry Like(Country) inz('D');
DCL‑S KeyCity Like(City) inz('frankfurt');
DCL‑S Text VarChar(50);
DCL‑S CompareCity Like(City);
DCL‑S UpperLetter VarChar(26) inz('ABCDEFGHIJKLMNOPQRSTUVWXYZ');
DCL‑S LowerLetter VarChar(26) inz('abcdefghijklmnopqrstuvwxyz');
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
CompareCity = KeyCity;
SetLL (KeyCountry: ∗Loval) AddressX_I04;
DoU %EOF(AddressX_I04) = ∗On;
Read AddressX_I04;
If %EOF(AddressX_I04);
Leave;
ElseIf %Xlate(UpperLetter: LowerLetter: City) <> CompareCity;
iter;
EndIf;
Text = %Subst(Country: 1: 2) +' '+ %Subst(ZipCode: 1: 5) +' '+
%Subst(City: 1: 9) +' '+ %Subst(CustNo: 1: 5) +' '+
%Subst(CustName1: 1: 25);
Dsply Text;
EndDo;
Return;
Figure 13 shows the results of calling the ADDRIDX04 program.
Figure 13: Result – leveraging sparse indexes

An SQL index can include key definitions based on an SQL expression and some WHERE conditions either.
Listing 17 shows the ADDRESSX_I05 index which includes the same WHERE conditions as the ADDRESSX_I04 index. The key definitions, however, are based on SQL expressions, for returning the rows independent of the uppercase and lowercase notation.
Listing 17: SQL script – creating ADDRESSX_I05 derived and sparse index
Create Index ADDRESSX_I05 For System Name ADDRI05
on ADDRESSX
(COUNTRY,
Lower(Trim(City)) as CITY_LOWERCASE
For Column LOWCITY,
Lower(Trim(CustName1)) as CUSTNAME1_LOWERCASE
For Column LOWNAME1,
Lower(Trim(CustName2)) as CUSTNAME2_LOWERCASE
For Column LOWNAME2,
Lower(Trim(Street)) as STREET_LOWERCASE
For Column LOWSTREET)
WHERE COUNTRY in ('D', 'A', 'CH')
and Lower(Trim(CUSTNAME1) concat
' ' concat
Trim(CUSTNAME2)) like '%gmbh%'
RcdFmt ADDRESSXF
Add All Columns; Listing 18 shows the RPG source code for the ADDRIDX04 program, where all Customers located in Germany with GMBH in any case somewhere in the CUSTNAME1 and CUSTNAME2 columns are read.
Because of the case insensitivity of the key columns, the required rows can be read by using a partial key, i.e. COUNTRY and LOWCITY. There is neither a need for comparing the city values nor for ignoring any rows.
This yields a solution with less RPG code and better performance because the minimum number of rows were processed, using keyed access.
Listing 18: Leveraging combined derived and sparse indexes
DCL‑F ADDRESSX_I05 ExtDesc('ADDRI05') ExtFile(∗ExtDesc) Keyed;
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
DCL‑S KeyCountry Like(Country) inz('D');
DCL‑S KeyCity Like(LowCity) inz('frankfurt');
DCL‑S Text VarChar(50);
//‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
∗INLR = ∗On;
SetLL (KeyCountry: KeyCity: ∗Loval) AddressX_I05;
DoU %EOF(AddressX_I05) = ∗On;
ReadE (KeyCountry: KeyCity) AddressX_I05;
If %EOF(AddressX_I05);
Leave;
EndIf;
Text = %Subst(Country: 1: 2) +' '+ %Subst(ZipCode: 1: 5) +' '+
%Subst(City: 1: 9) +' '+ %Subst(CustNo: 1: 5) +' '+
%Subst(CustName1: 1: 25);
Dsply Text;
EndDo;
Return;
If we run the RPG example shown in Listing 18, the rows are returned in the sequence as shoin in Figure 14.
Figure 14: Result – leveraging combined derived and sparse indexes

DDS still needed?
SQL indexes can only be built over a single table or physical file.
In an SQL view multiple physical files, tables or views can be joined or merged together, but views do not include any key information. In this way keyed access on views with native I/O is not possible.
DDS, on the other side, provides specifics for joining or merging multiple tables or physical files together and accessing them in a keyed order.
- Keyed and joined logical files When creating joined logical files, multiple physical files or tables can be joined together. Because native I/O requires the rows to be read in a specific sequence, it is possible to add multiple key fields from one of the joined physical files or tables.
- Multi-format logical files A multiple-format logical file is defined over two or more physical files and includes more than one record format, where each record format is associated with one of the merged physical files. When reading from a multi-format logical file, the data is accessed through the associated record format of the physical file. The records are sequenced according to the key specifications that are defined for each of the record formats.
If joined or multi-format logical files are still used in your programs, DDS is still necessary.
New joined or multi-format logical files, however, should no longer be created. Instead alternatives such as creating (un-keyed) SQL views and accessing them with embedded SQL should be preferred.
Conclusion
SQL provides a lot of very powerful specifics for creating indexes, such as using scalar functions for new key columns or adding WHERE conditions for pre-filtering the rows to be accessed. These enhancements are not available in DDS, which is an outdated technology, while all future development is in SQL.
SQL indexes can be used in conjunction with native I/O similar to any keyed logical file. Using the enhanced indexing technologies, especially with derived and sparse indexes, business logic can be moved into the database and the source code can be reduced while the data access is still performed with native I/O.
However, for future development, alternatives to native I/O such as creating SQL views based on (complex) SELECT statements and accessing them with embedded SQL should be considered. That does not mean native I/O has to be completely replaced with embedded SQL. Both methods (embedded SQL and native I/O) have their strength and merits.
And now have fun in creating SQL indexes, native I/O, and embedded SQL.
Connect with the the IBM i community
Connect, learn, share, and engage with other IBM i users as you follow what’s trending and join the discussion. Join now