Article
Introduction to convolutional neural networks
Explore the different steps that go into creating a convolutional neural networkComputer vision is a branch within computer science that enables computers to recognize the visual world. Several machine learning- and deep learning-based algorithms are available that help with building models to make predictions on images or videos. This article explores convolutional neural networks (CNN), a type of supervised deep learning algorithm.
A convolutional neural network is an extension of artificial neural networks (ANN) and is predominantly used for image recognition-based tasks. A previous article covered different types of architectures that are built on artificial neural networks . This article explains the different steps that go into creating a convolutional neural network. These steps are:
- Image channels
- Convolution
- Pooling
- Flattening
- Full connection
Image channels
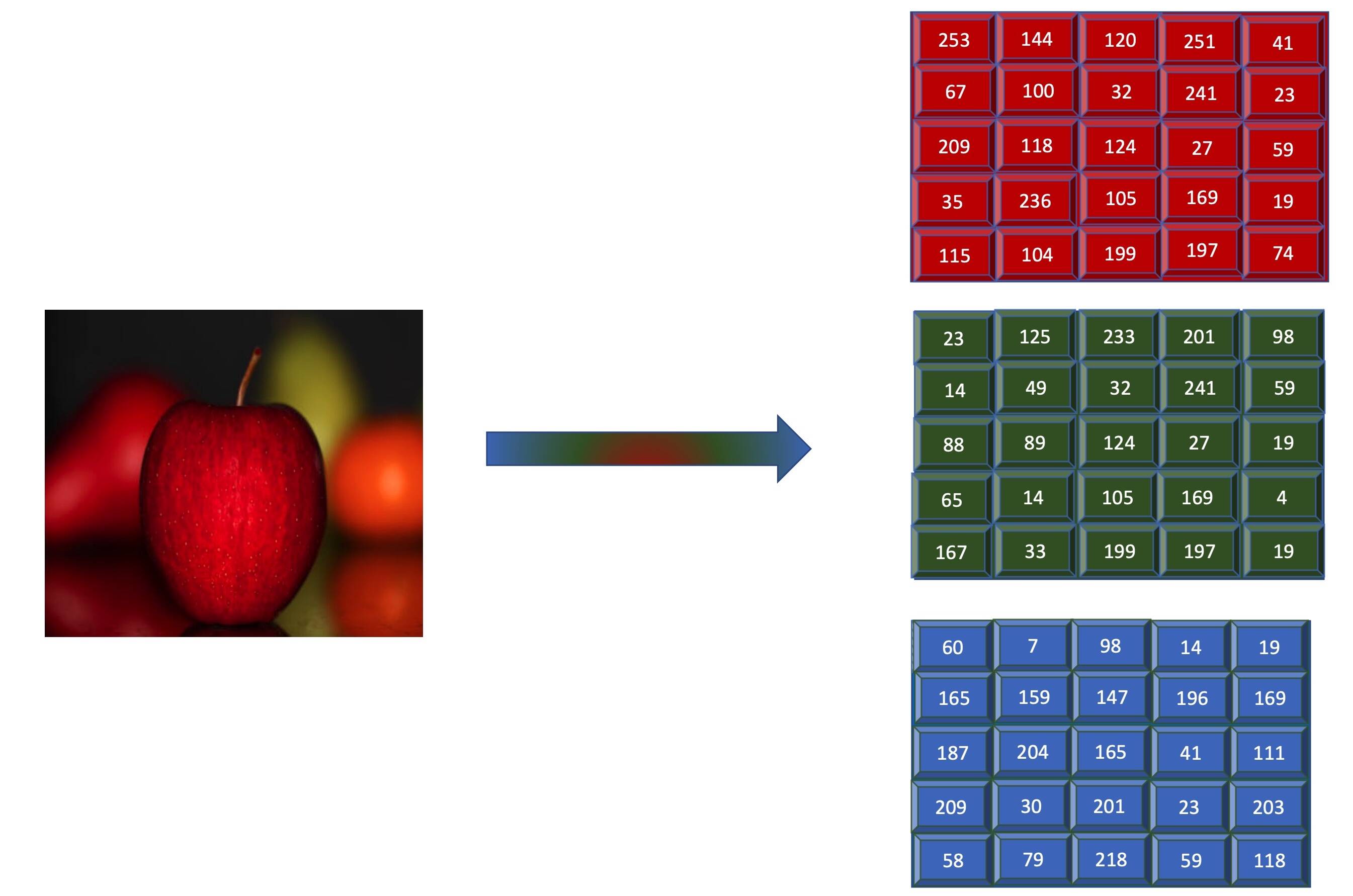
The first step in the process of making an image compatible with the CNN algorithm is to find a way to represent the image in a numerical format. The image is represented using its pixel. Each pixel within the image is mapped to a number between 0 and 255. Each number represents a color ranging between 0 for white and 255 for black.
For a black and white image, an image with length m and width n is represented as a 2-dimensional array of size mXn. Each cell within this array contains its corresponding pixel value. In the case of a colored image of the same size, a 3-dimensional array is used. Each pixel from the image is represented by its corresponding pixel values in three different channels, each pertaining to a red, blue, and green channel.
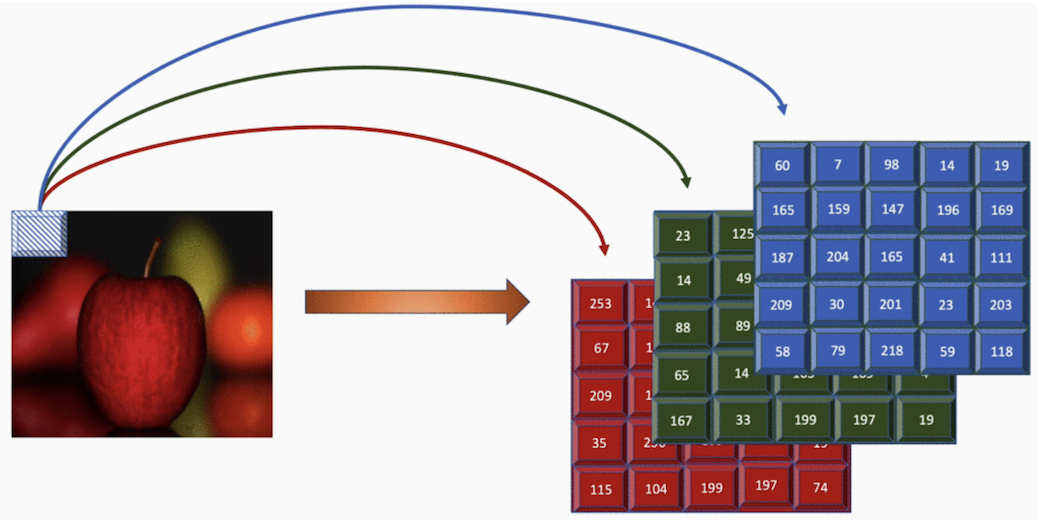
The image is represented as a 3-dimensional array, with each channel representing red, green, and blue values, respectively, as shown in the following image.
Convolution
Now that the image has been represented as a combination of numbers. the next step in the process is to identify the key features within the image. This is extracted using a method known as convolution.
Convolution is an operation where one function modifies (or convolves) the shape of another. Convolutions in images are generally applied for various reasons such as to sharpen, smooth, and intensify. In CNN, convolutions are applied to extract the prominent features within the images.
How are features detected
To extract key features within an image, a filter or a kernel is used. A filter is an array that represents the feature to be extracted. This filter is strided over the input array, and the resulting convolution is a 2-dimensional array that contains the correlation of the image with respect to the filter that was applied. The output array is referred to as the feature map.
For simplicity, the following animation shows how an edge detector filter is applied to just the blue channel output from the previous step. Later, you'll learn how filters are applied to all three channels.
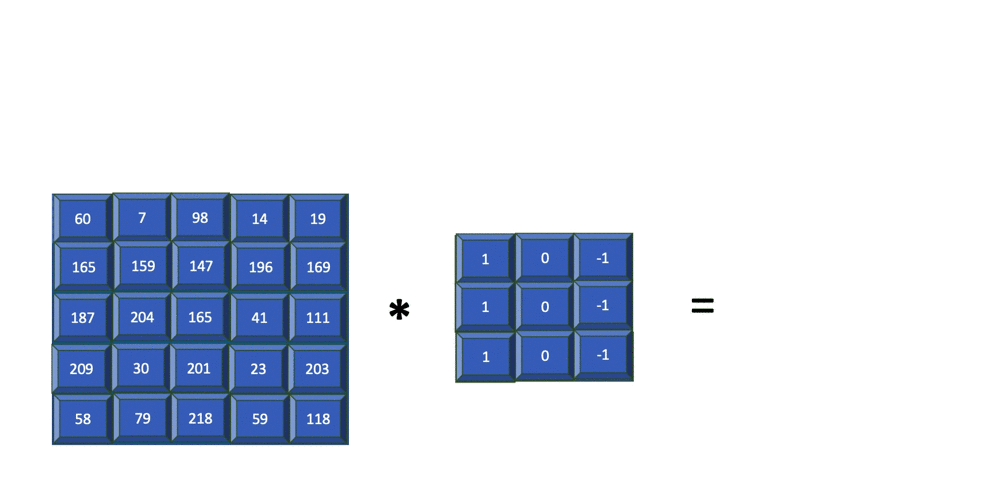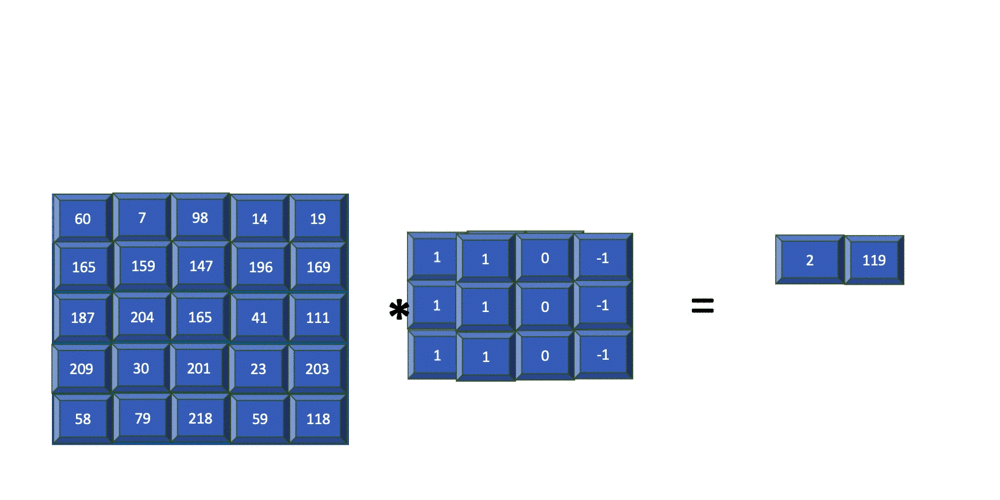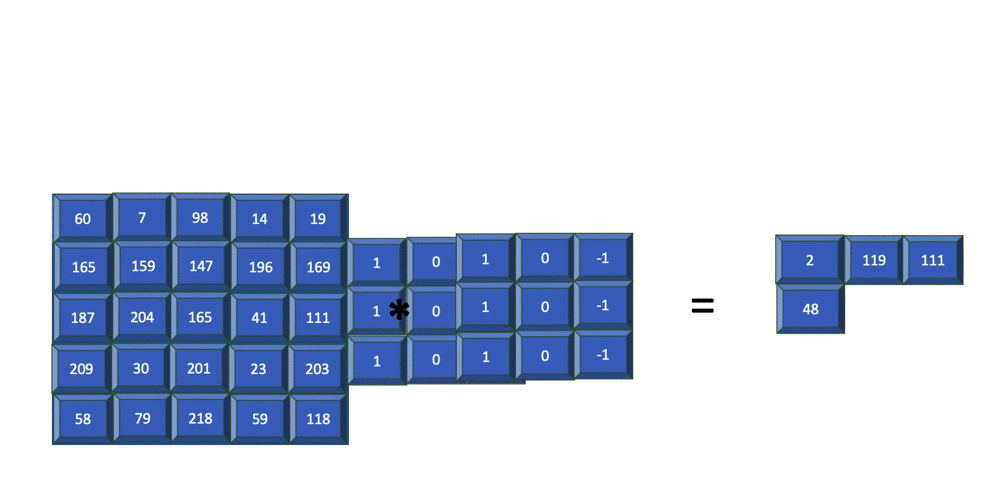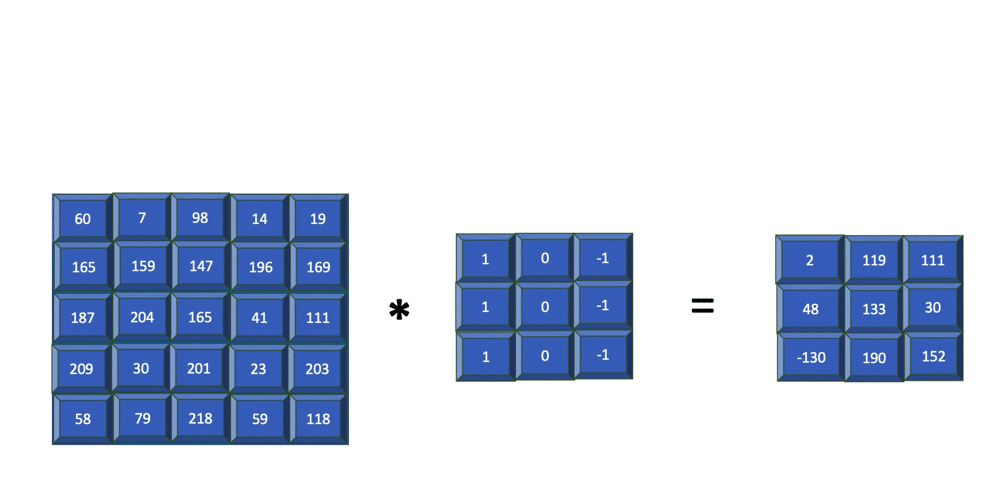
The resulting image contains just the edges present in the original input. The filter used in the previous example is of size 3x3 and is applied to the input image of size 5x5. The resulting feature map is of size 3x3. In summary, for an input image of size nXn and a filter of size mXm, the resulting output is of size (n-m+1)X(n-m+1).
Strided convolutions
During the process of convolution, you can see how the input array is transformed into a smaller array while still maintaining the spatial correlation between the pixels by applying filters. Here, I discuss an option on how to help compress the size of the input array much more.
What is striding
In the previous section, you saw how the filter is applied to each 3x3 section of the input image. You can see that this window is slid by one column to the right each time, and the end of each row is slid down by one row. In this case, sliding of the filter over the input was done one step at a time. This is referred to as striding. The following example shows the same convolution, but strided with 2 steps.
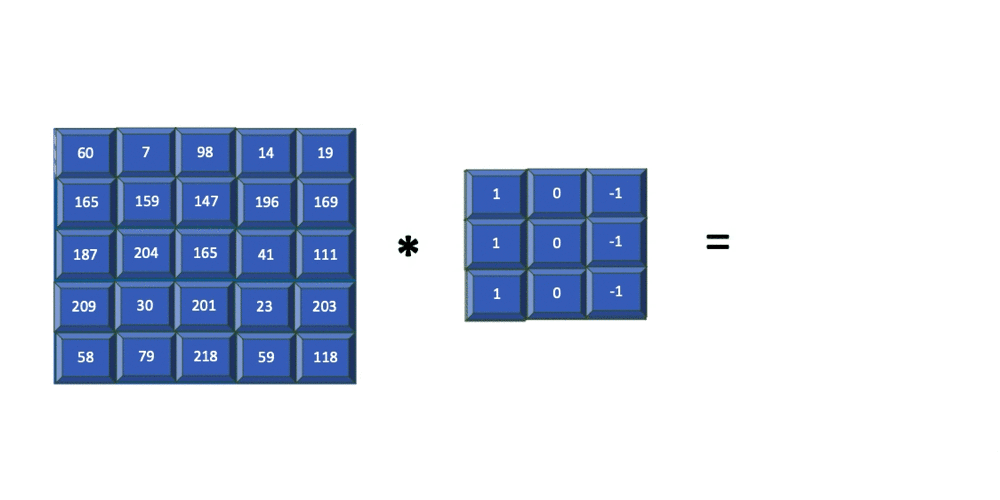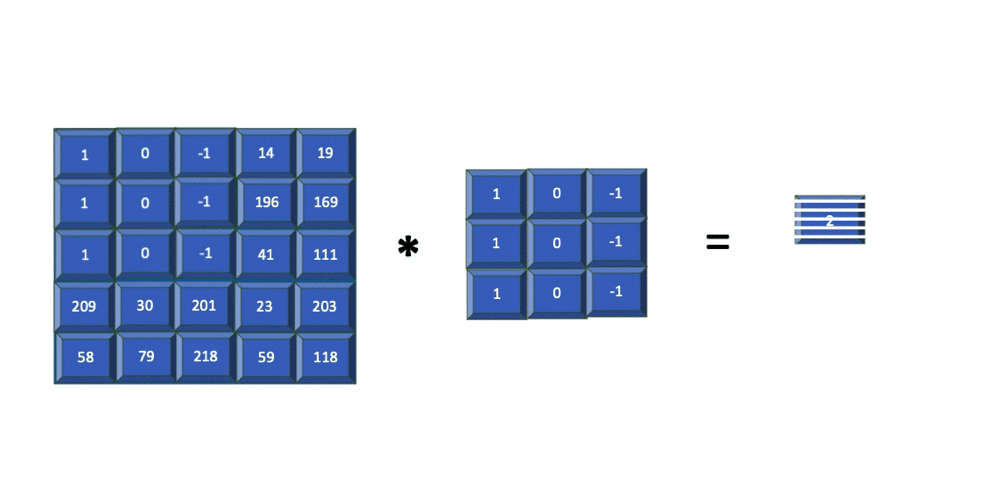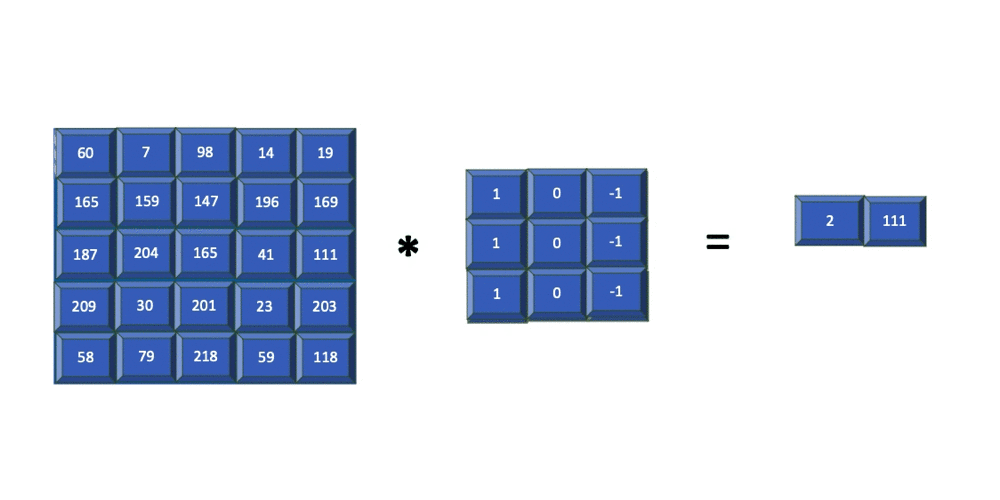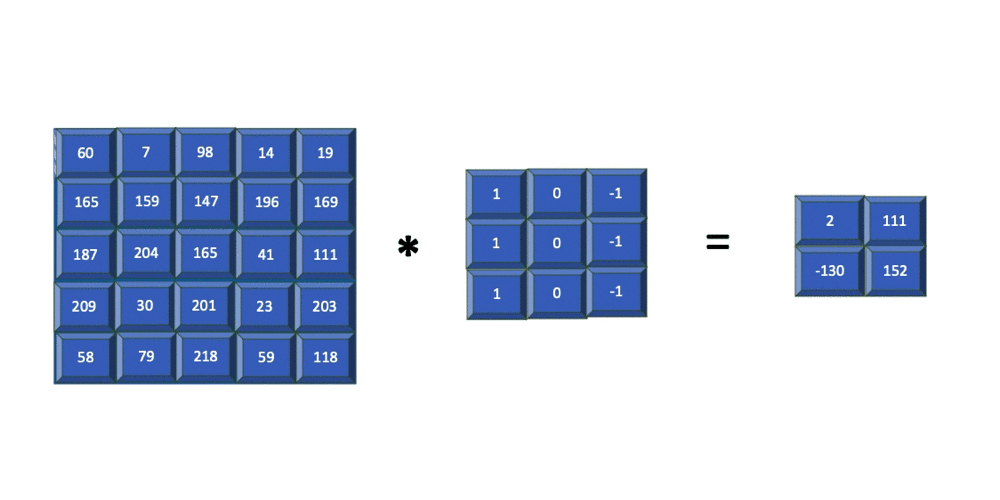
The filter used in the previous example is of size 3x3 and is applied to the input image of size 5x5 with a stride=2. The resulting feature map is of size 2x2. In summary, for an input image of size nXn and a filter of size mXm with stride=k, the resulting output will be of size ((n-m)/k+1)X((n-m)/k+1).
Padding
During convolution, notice that the size of the feature map is reduced drastically when compared to the input. Also, notice that the filter stride touches the cells in the corners just once, but the cells to the center are filtered quite a few times.
To ensure that the size of the feature map retains its original input size and enables equal assessment of all pixels, you apply one or more layers of padding to the original input array. Padding refers to the process of adding extra layers of zeros to the outer rows and columns of the input array.
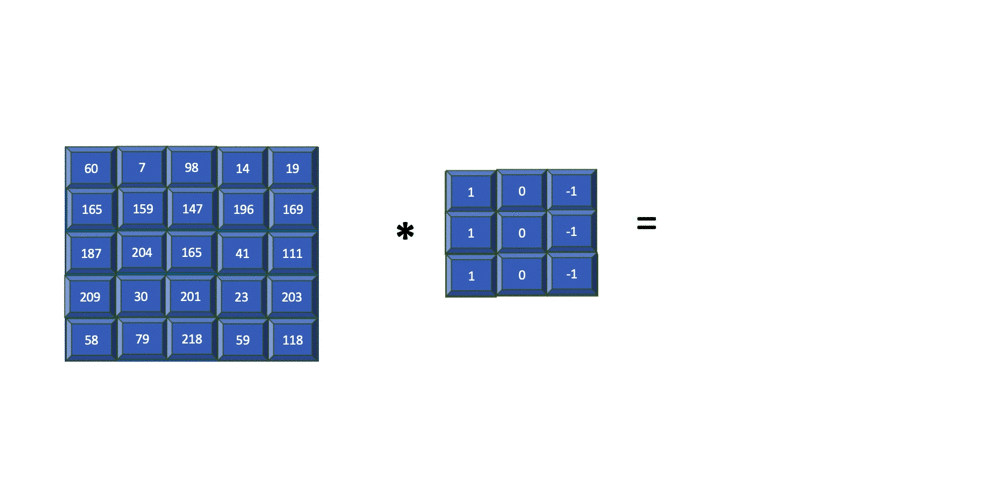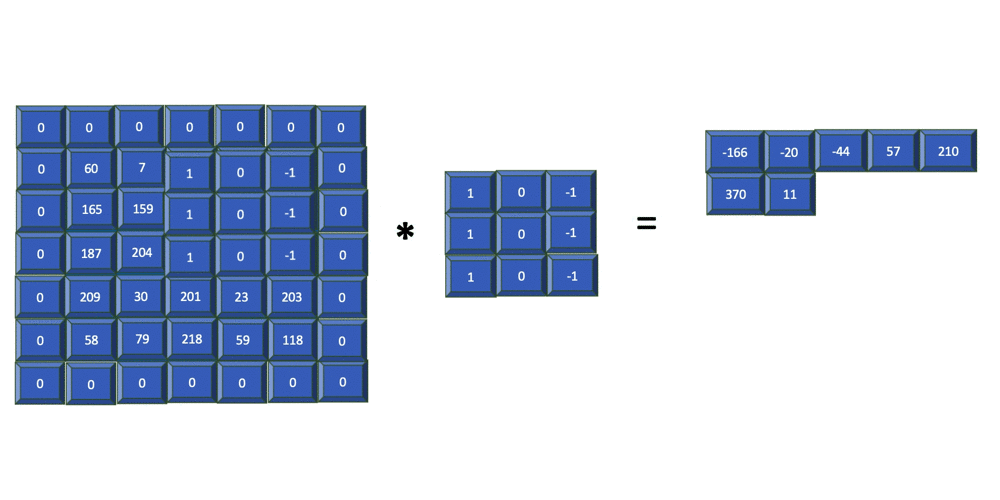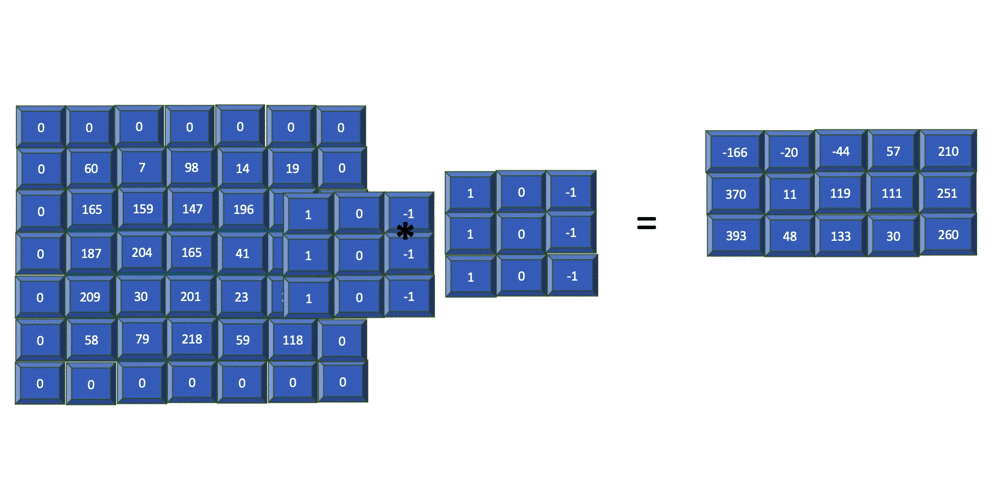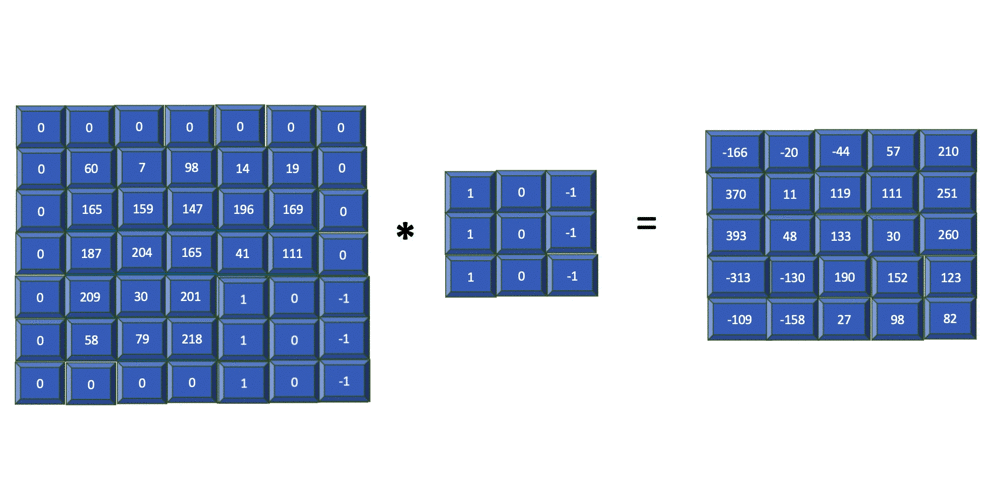
The previous image shows how 1 layer of padding is added to the input array before a filter is applied. You can see that for an input array of size 5x5, padding is set to one, filter is size 3x3, and the output is a 5x5 array. In general, for an input image of size nXn and a filter of size mXm with padding = p, the resulting output is of size (n + 2p - m +1)X(n + 2p - m +1).
How are convolutions applied over the RGB channels
So far, you've seen how the convolution operation looks if images were represented with just one channel. I used the blue channel from the first step to walk you through an example. Now, let's look at how convolution looks when a color image over 3 channels is used.
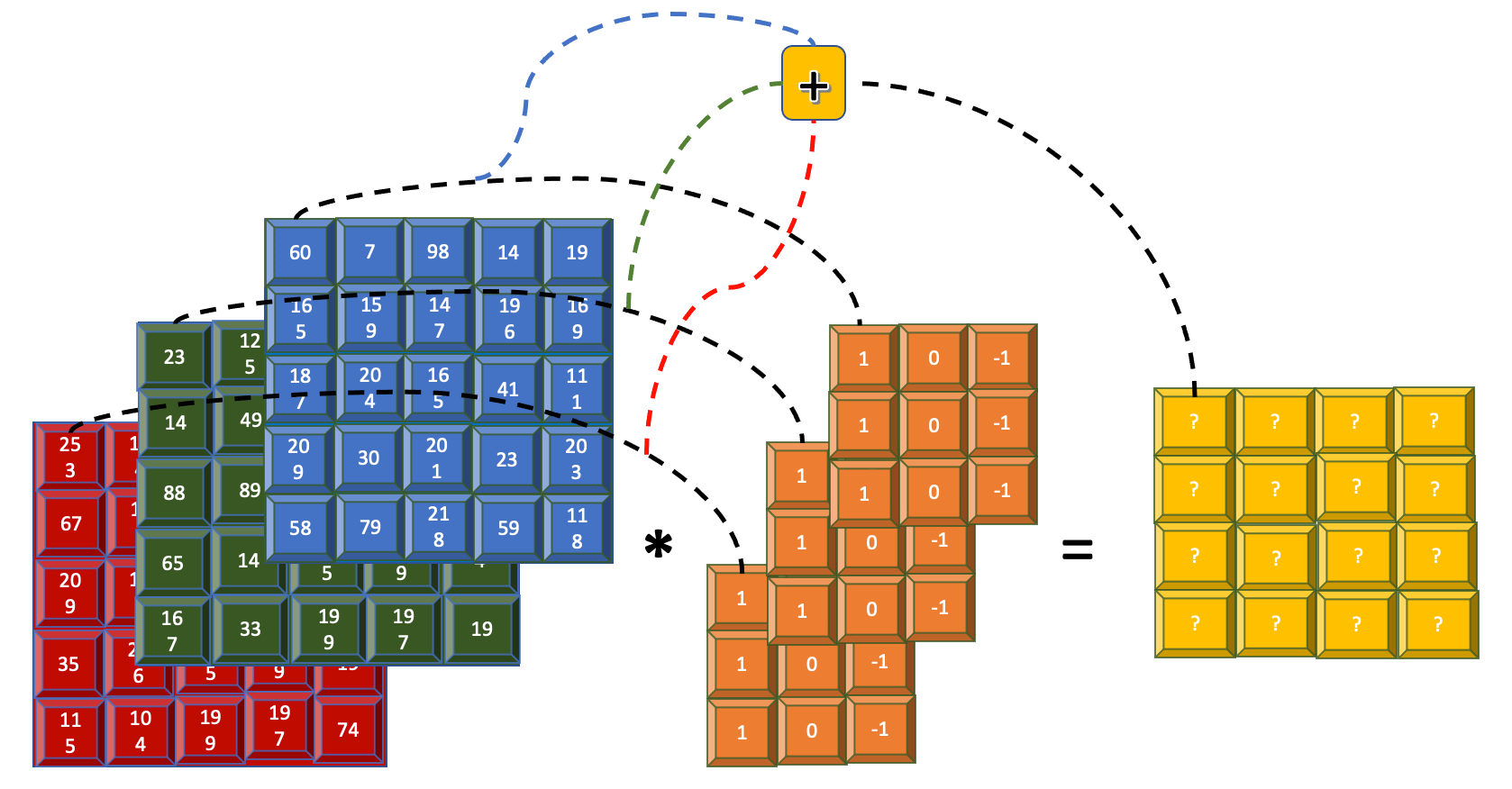
For a 5x5 image represented over 3 channels, the 3x3 filter is now replicated three times, once for each channel. The input image is a 5x5x3 array, and the filter is a 3x3x3 array. However, the output map is still a 2D 4x4 array. The convolutions on the same pixel through the different channel are added and are collectively represented within each cell.
In general, for an input image of size nXn and filter of size mXm over N channel, the image and filters are converted into arrays of sizes nXnXN and mXmXN, respectively, and the feature map produced is of size (n-m+1)X(n-m+1) assuming stride=1.
How are convolutions applied to more than one filter
In the previous section, you saw what the output of applying convolution over multiple channels looks like. In doing that, I took an edge filter and calculated the convolutions using it. However, this was using just one filter. In reality, the CNN model needs to use multiple filters at the same time to observe and extract key features. I now discuss what the output to using multiple filters looks like.
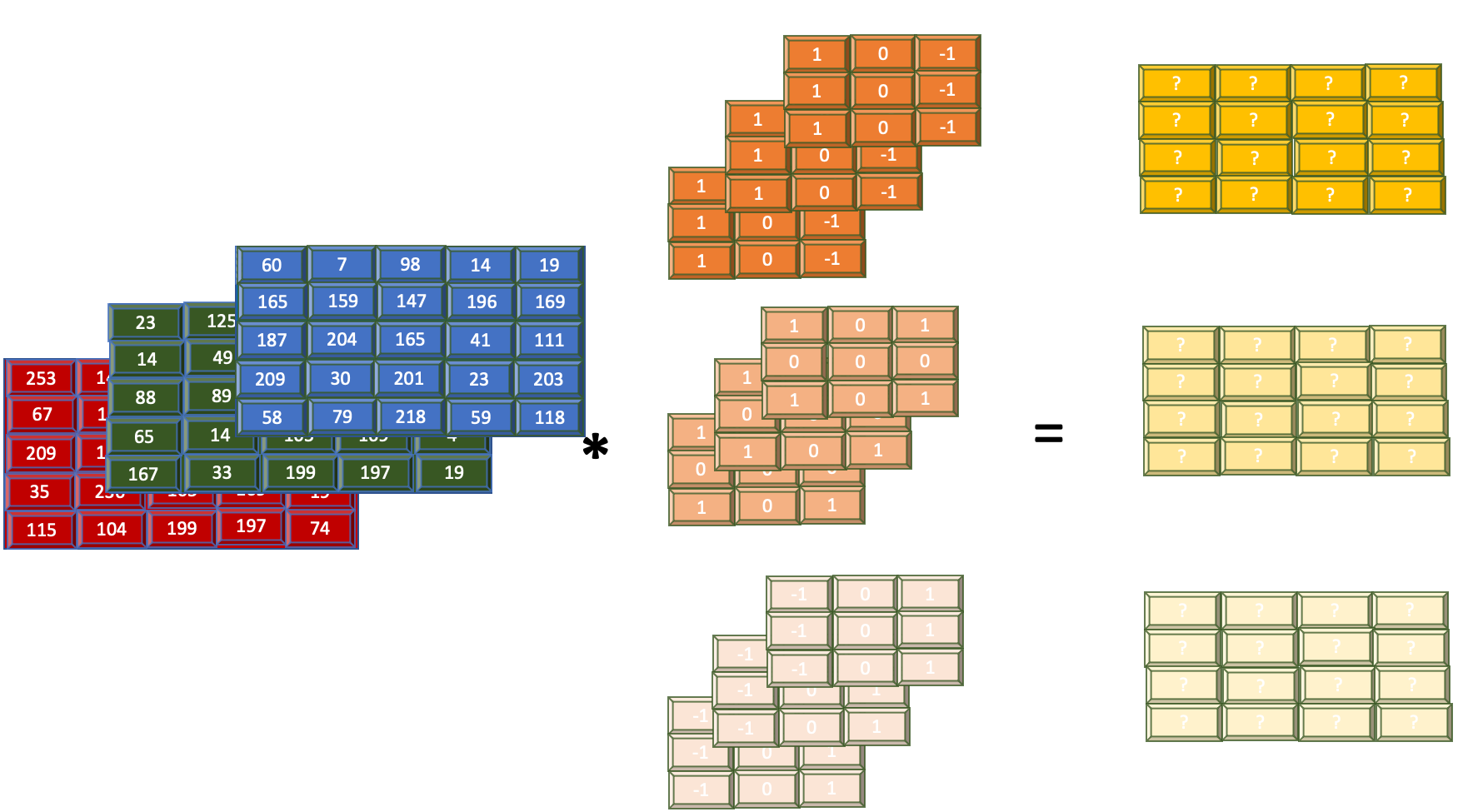
In the previous image, you see that applying convolution using three filters over the RGB channels produces three 4x4 arrays. Thus, for an input image of size nXn and filter of size mXm over N channel and F filters, the feature map produced is of size (n-m+1)X(n-m+1)XF assuming that stride=1.
Pooling layers
To further reduce the size of the feature map generated from convolution, I apply pooling before further processing. This helps to further compress the dimensions of the feature map. For this reason, pooling is also referred to as subsampling.
Pooling is the process of summarizing the features within a group of cells in the feature map. This summary of cells can be acquired by taking the maximum, minimum, or average within a group of cells. Each of these methods is referred to as min, max, and average pooling, respectively.
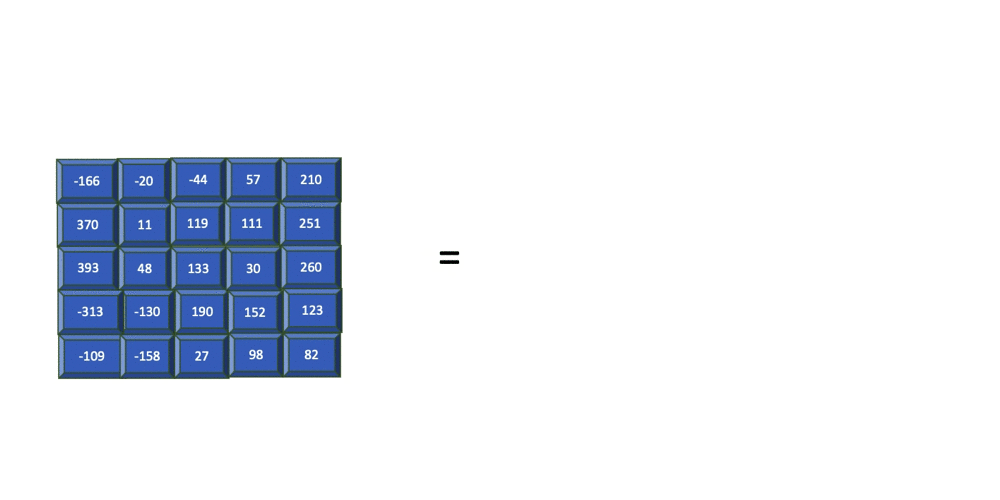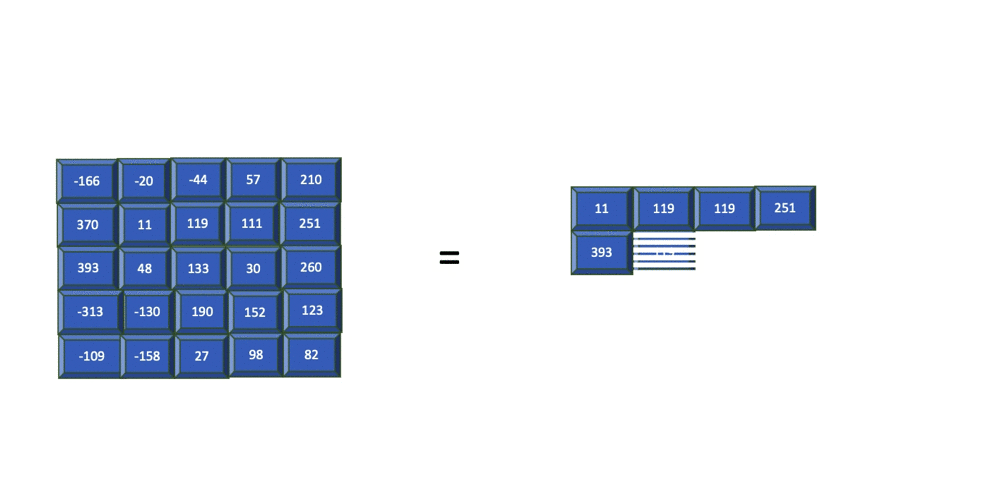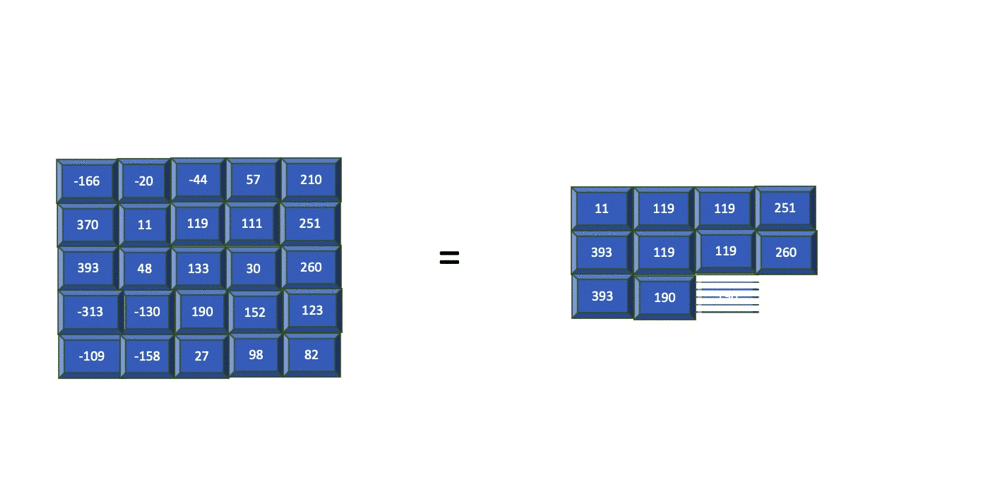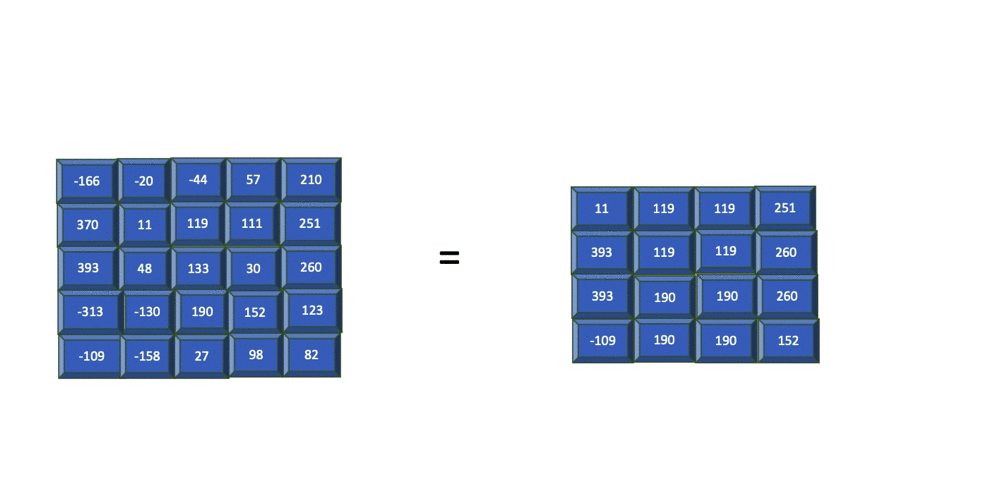
The previous image shows how max pooling is applied to a filter of size 2 (2x2) and stride=1. This means that for every 2x2 cell group within the feature map, the maximum value within this region is extracted into the output cell.
I should note that the previous example shows a pooling-applied outcome of just one feature map. However, in CNN, pooling is applied to feature maps that result from each filter.
Flattening
You can think of CNN as a sequence of steps that are performed to effectively capture the important aspects of an image before applying ANN on it. In the previous steps, you saw the different transitions that are applied to the original image.

The final step in this process is to make the outcomes of CNN be compatible with an artificial neural network. The inputs to ANN should be in the form of a vector. To support that, I apply flattening, which is the step to convert the multidimensional array into an nX1 vector, as shown previously.
Note that the previous example shows flattening applied to just one feature map. However, in CNN, flattening is applied to feature maps that result from each filter.
Full connection: a simple convolutional network
In this final section, I'll combine all of the steps that were previously discussed and look at how the output of the final layer is served as an input to ANN.
The following image shows a sample CNN that is built to recognize an apple image. To begin, the original input image is represented using its pixel values over the RGB channel. Convolutions and pooling are then applied to help identify feature mapping and compress the data further.
Note that convolutions and pooling can be applied to CNN many times. The metrics of the model generated depends on finding the right number of times these steps should be repeated.
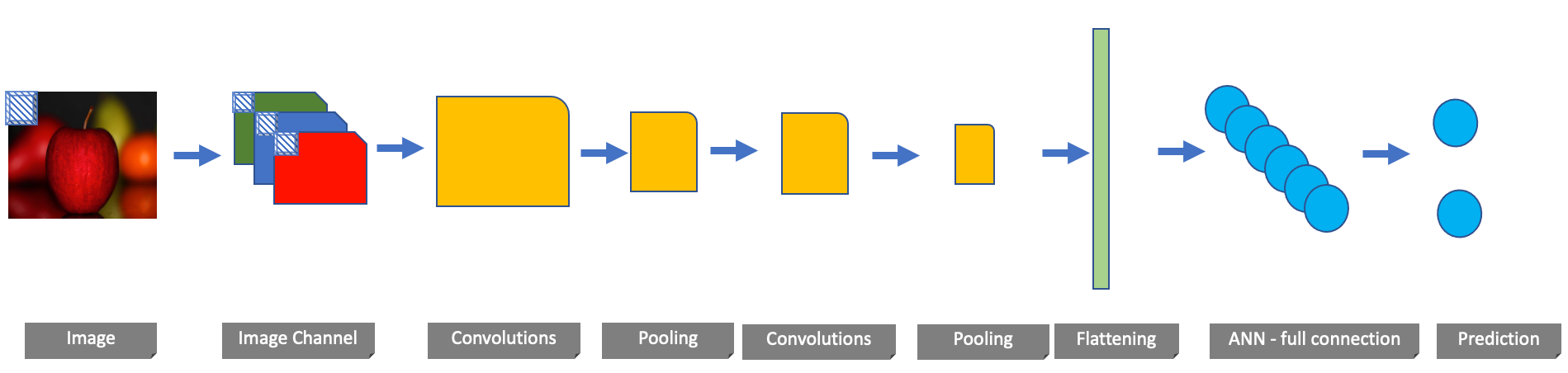
After this, the output is now flattened and converted to a single-dimensional vector to make it compatible with an ANN. As seen in the introduction to deep learning article, this flattened output is passed through one or more fully connected neural networks. The final layer of this network contains the probability under which the original image is predicted.
Summary
In this article, you looked at convolutional neural networks as a type of supervised learning to recognize images. The article explained each of the steps that go into creating a CNN, then concluded by looking at an end-to-end flow of a fully connected CNN.