Article
Optimize your Java cloud-native applications with OpenJ9 JITServer
Learn how the Eclipse OpenJ9 JITServer remote compiler reduces latency, cuts container costs, and maximizes throughput for micro‑service workloads.With the current trend of migrating applications to the cloud, a new set of challenges have emerged -- namely related to performance and cost. This article proposes that the Eclipse OpenJ9 JITServer technology from IBM Semeru Runtimes is a great solution to address both of these issues. With the use of the JITServer, we describe how it is possible to ensure the high quality of service (QoS) that clients demand, while also lowering costs through better use of managed container resources.
In this article, we will cover JIT compiler basics, how the JITServer can make a big difference in a micro-container environment, and include a working demo that utilizes the JITServer technology.
First came the JIT compiler
Programs written in Java are converted by the javac compiler into machine independent bytecodes which, at runtime, are interpreted by the Java Virtual Machine (JVM). This technique ensures portability of Java programs across different architectures, but it affects performance because interpretation is inherently slow. The answer to this performance issue was the inclusion of a Just-in-Time (JIT) compiler, which, at runtime, transforms sequences of bytecodes into machine code that is cached by the JVM.
Shown below is the workflow from Java code to execution on the host machine:
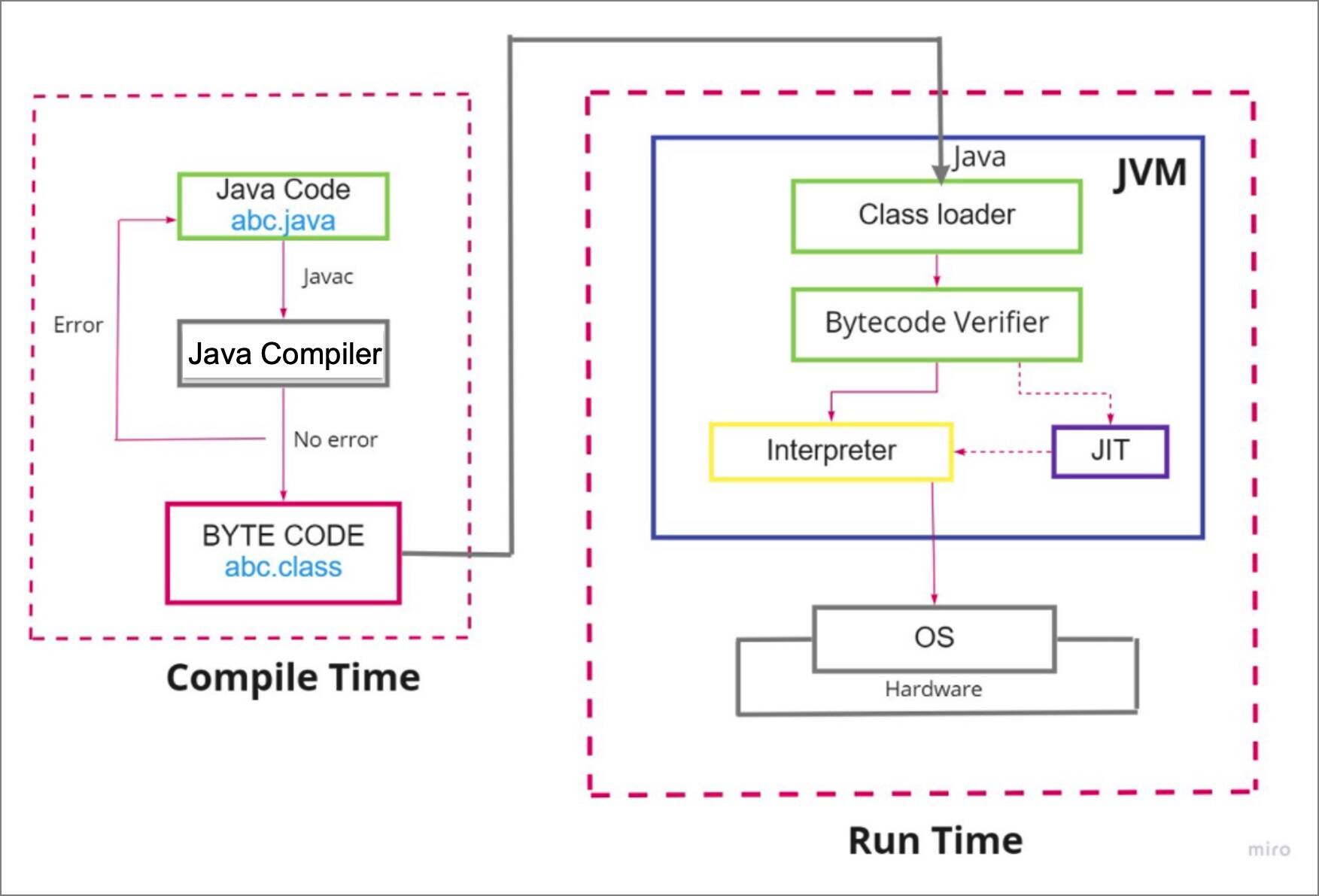
Compile time -- Converting Java code to bytecode:
javac abc.javainvokes the Java compiler that converts the Java code into bytecode (note that this is the standard Java compiler, not the JIT compiler that is run in the JVM).- The bytecode is stored in a class file:
abc.class.
Runtime -- Execute the bytecode on the host machine:
java abcloads the class file bytecode into the class loader of the JVM.- The bytecode verifier ensures the security of the bytecode.
- One bytecode at a time, the interpreter converts the bytecode into machine code and executes it.
- The JIT compiler can improve execution performance 10x over the interpreter. Based on profiling metrics, the JIT compiler will supply machine code of recurring bytecodes to the JVM for execution.
JIT compilation -- The good and the bad
The JIT compiler provides some benefits when it comes to performance:
- Pre-compiled native machine code executes 10x faster than a bytecode-by-bytecode interpreter.
- The use of a code cache optimizes efficiency.
Unfortunately, the performance gains do not come without a cost, especially in a small container environment where a premium is placed on minimizing CPU and memory costs. Some of the negatives associated with JIT compilers include:
- Consumes more CPU cycles and memory
- Slows application startup
- Can create memory spikes and out-of-memory (OOM) crashes
- Can create CPU consumption spikes degrading the QoS
- Adds complexity of container provisioning due to factoring in worst-case scenarios
- If JIT crashes, it takes down the whole JVM
The image below shows an example of how JIT compilation induces spikes for CPU consumption and memory usage of the JVM.
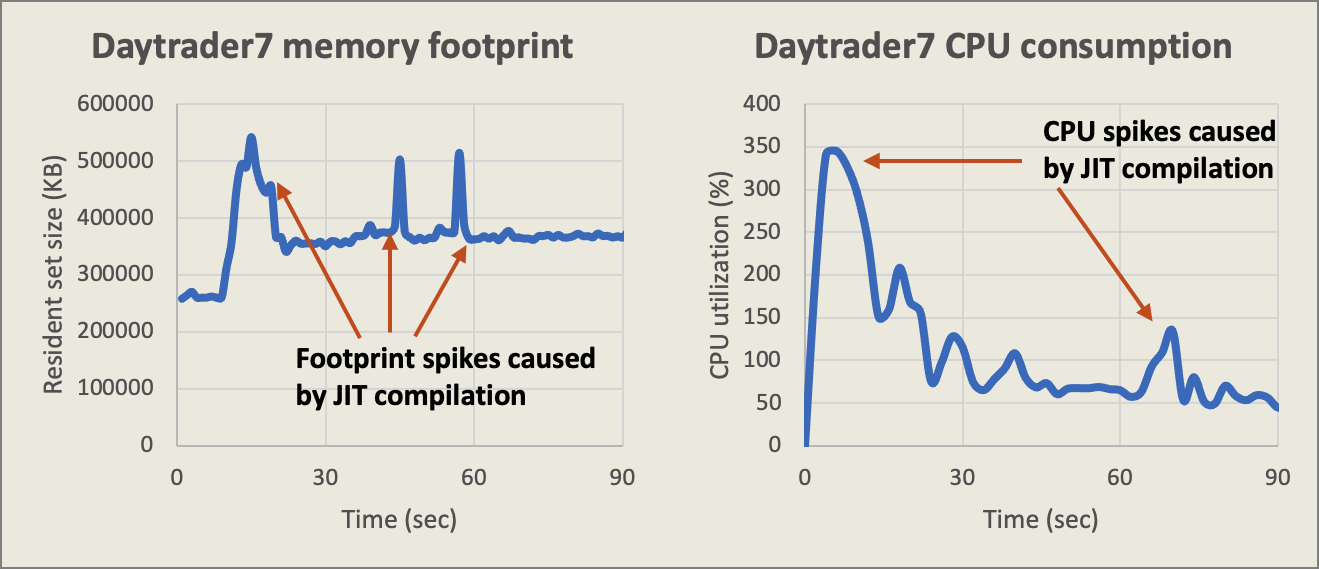
While this application may only use ~360MB of memory at steady state, the JIT compiler can create large footprint spikes. To avoid OOM-induced crashes, the container will need to be sized to accommodate these occasional spikes. Additional experimental tests may need to be performed to determine how high the spikes can be. Remember that in a container environment, native OOM events will result in the container being killed.
JITServer to the rescue
JITServer technology decouples the JIT compiler from the VM and lets the JIT compiler run remotely in its own process. This mechanism prevents your Java application suffering possible negative effects due to CPU and memory consumption caused by JIT compilation. With the JITServer, the application is not affected by the stability of the compilation; if the JITServer goes down, the application continues to run. Note that the JVM retains the ability to compile locally using its embedded JIT compiler. This prevents a possible performance loss in case the JITServer is not available due to to a crash or network issues.
The following image is an example architecture diagram of how the JITServer fits in a container environment.
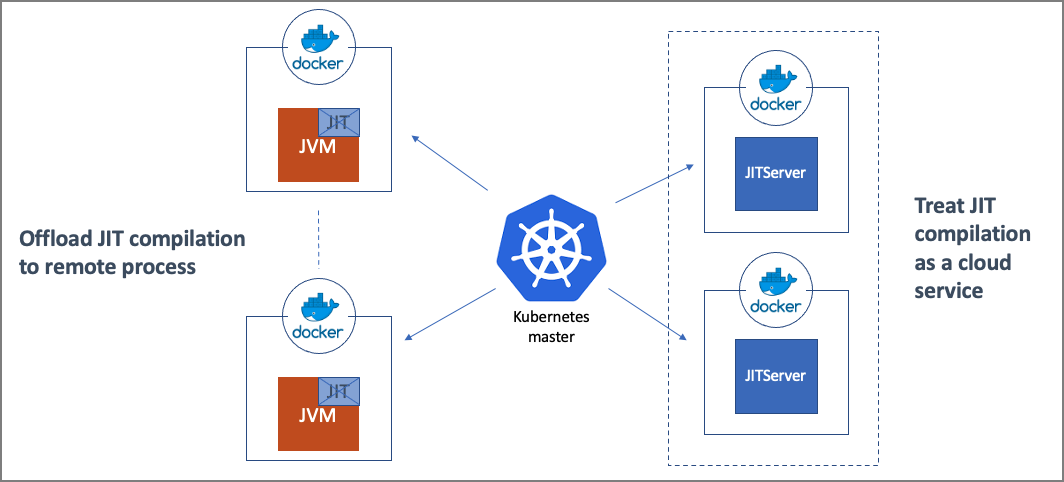
Think of it as a micro-services solution applied at the JVM level. Here we split the JVM into multiple parts and communicate through the network. Kubernetes takes care of the scaling -- more JITServer instances can be added or removed as needed.
The following diagram shows a high-level view of the process flow between the JVM and the JITServer.
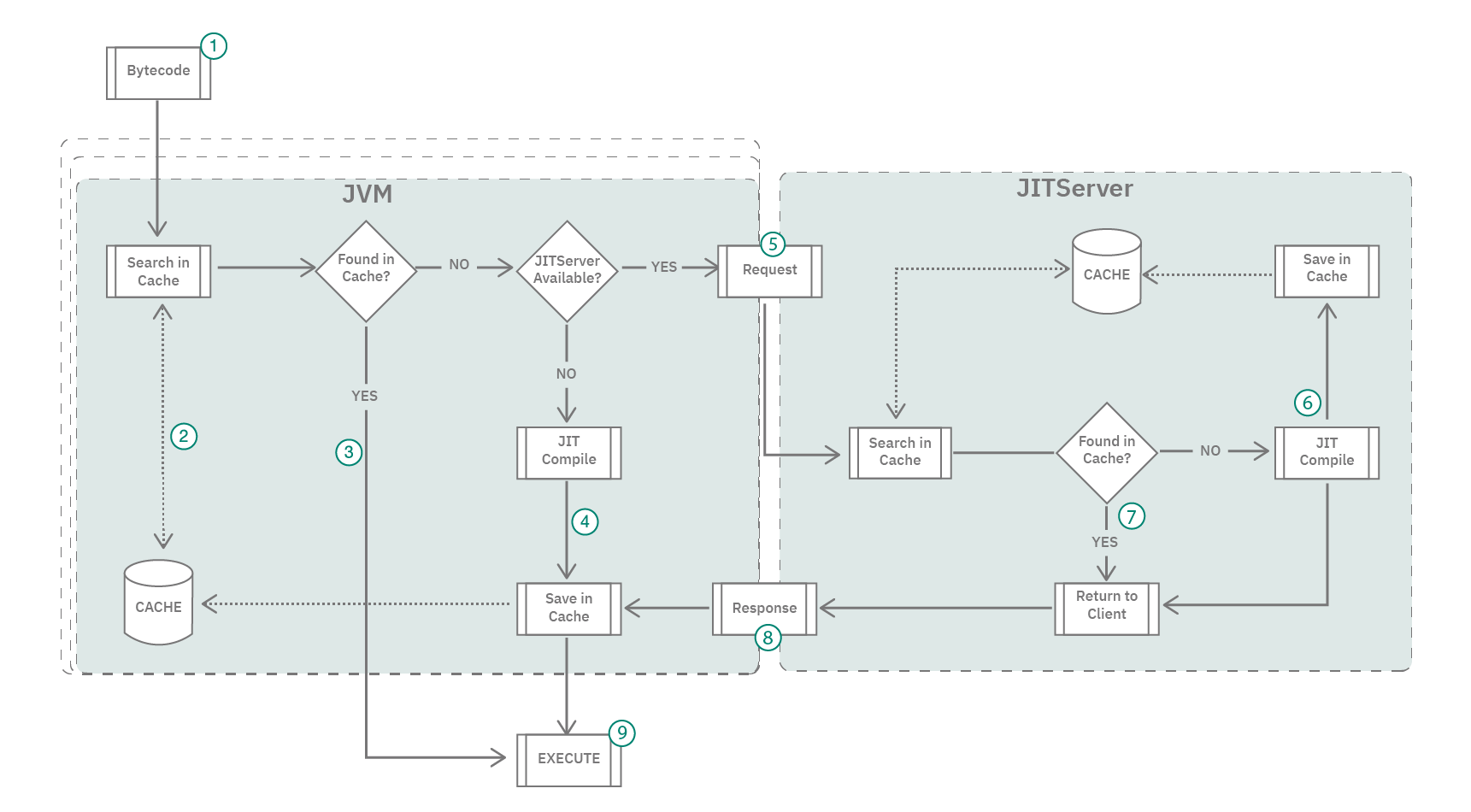
Note that in OpenJ9 the compilation occurs at the method level.
- The bytecode is passed into the JVM.
- The JVM checks if the method code is already stored in its local code cache.
- If the JVM already has the compiled method code, the code is executed.
- If the method needs to be compiled and no JITServer is running, the JVM JIT compiler is invoked. The compiled method code is then stored locally and then executed.
- If a JITServer is running, the method is passed to the JITServer. If server side caching is enabled, JITServer will first check its server side cache for a compatible compiled body.
- If the JITServer does not have it stored in the server side cache, it will compile the method, store it in its server side cache if possible, then return the code back to the JVM.
- If the JITServer does have the method stored in the server side cache, it simply returns it to the JVM.
- The JVM receives the method code from the JITServer. The method code is then stored locally and executed.
NOTE:
- The communication between the JVM and the JITServer typically involves multiple requests and responses because the JITServer may need additional info about the classes, profiling data, etc.
- Heuristics in the JVM are used to determine if the method should be compiled locally or sent to the JITServer. Some methods are quite small (cheap compared to the local resources available) and are not worth sending over the network.
- Multiple JVM clients can use the same JITServer. This increases the utilization of JITServer and provides additional advantages when server side caching is enabled: when a JVM requests a compilation for a method that is already cached at the server, the JITServer will just return it. This takes fewer CPU resources and network latency is improved (no back and forth communication like normal -- just one round-trip).
- From a developer's perspective, the complexity of the JITServer is hidden.
Benefits in a container environment
Using a JITServer in a container environment provides multiple benefits:
- JIT compilation resources can be scaled independently from the Java application resources.
- Application containers can use smaller memory limits to minimize costs.
- Overall cluster memory utilization (JITServer included) is reduced because memory consumption peaks from different applications don’t align.
- Provisioning is simpler -- user only needs to care about application requirements.
- Ramp-up is faster, especially in constrained environments.
- Performance of short-lived applications is better.
- Performance is more predictable because CPU spikes caused by JIT compilation are eliminated.
- Autoscaling behavior is better (a direct consequence of faster ramp-up).
- Better cluster CPU utilization (including JITServer) when server side caching is used.
Where does AOT fit in?
You may be wondering if the JITServer is compatible with another OpenJ9 feature: the dynamic Ahead-Of-Time (AOT) compiler. The idea behind dynamic AOT is that during first-time execution, many Java methods are compiled and stored into a repository called the shared class cache (SCC). Any additional JVMs that connect to the same SCC can take advantage of this AOT code, dramatically improving the start-up time and ramp-up time of Java applications. However, due to technical reasons, the code quality of the AOT code is about 10% less (in terms of throughput) than the code quality of JIT compiled code which is tailor-fitted for a particular JVM. This 10% throughput gap is typically addressed by recompiling hot AOT compiled methods with the regular JIT compiler. Moreover, some methods cannot be subjected to AOT compilations and they need to be compiled with the regular JIT compiler.
Thus, the AOT and JITServer technologies complement each other, rather than competing with one another: The AOT solution can be used to quickly bring the throughput to reasonable levels, while the JITServer can be used to reach peak throughput by performing recompilations and compilations not handled by AOT. It should be noted that the JITServer can perform AOT compilations, and therefore can be used to populate a “cold” (empty) SCC. More than that, optionally, the JITServer can cache the AOT bodies it produces, so that a future request for a cached method can forgo the compilation process entirely.
JITServer vs. vanilla JIT compiler -- How they stack up
These experiments were conducted on Amazon Elastic Compute Cloud (EC2) using micro-VMs. They all compare the performance of using the JITServer vs. non-JITServer standard OpenJ9 setup. As benchmark, we used the AcmeAir Java EE application, which runs on top of an Open Liberty application server.
First, we see how ramp-up time is improved using the JITServer (most compilations occur during ramp-up). We also see that there are no spikes in memory usage (memory consumption is flat and more predictable).
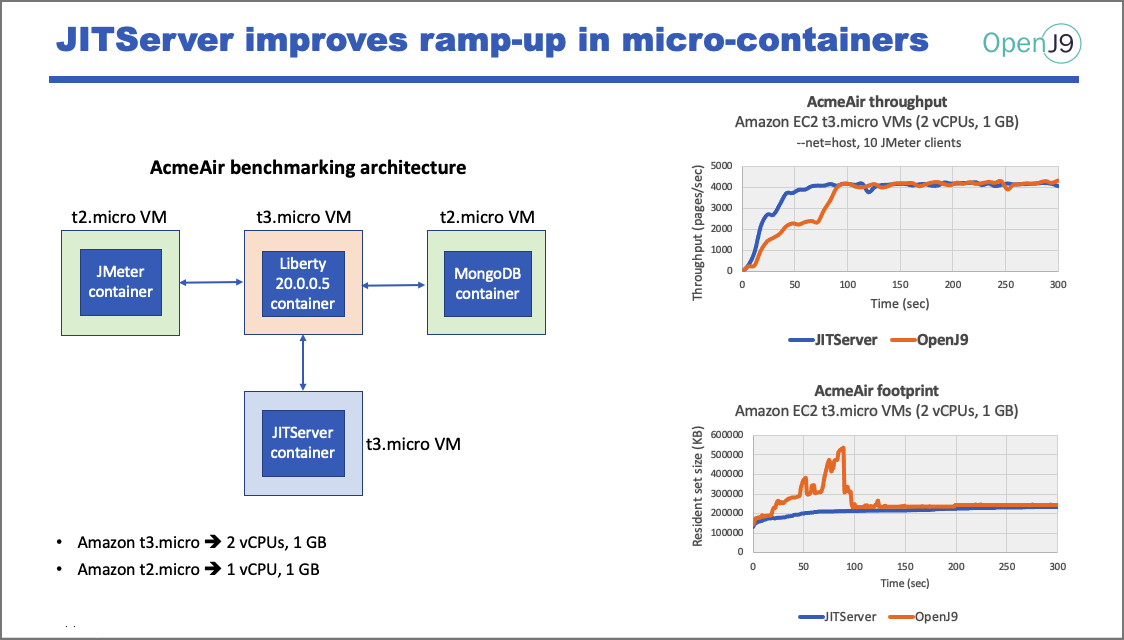
NOTE: Ramp-up speed is more of an issue for short-lived applications, but it's also important for a smooth experience during horizontal pod autoscaling.
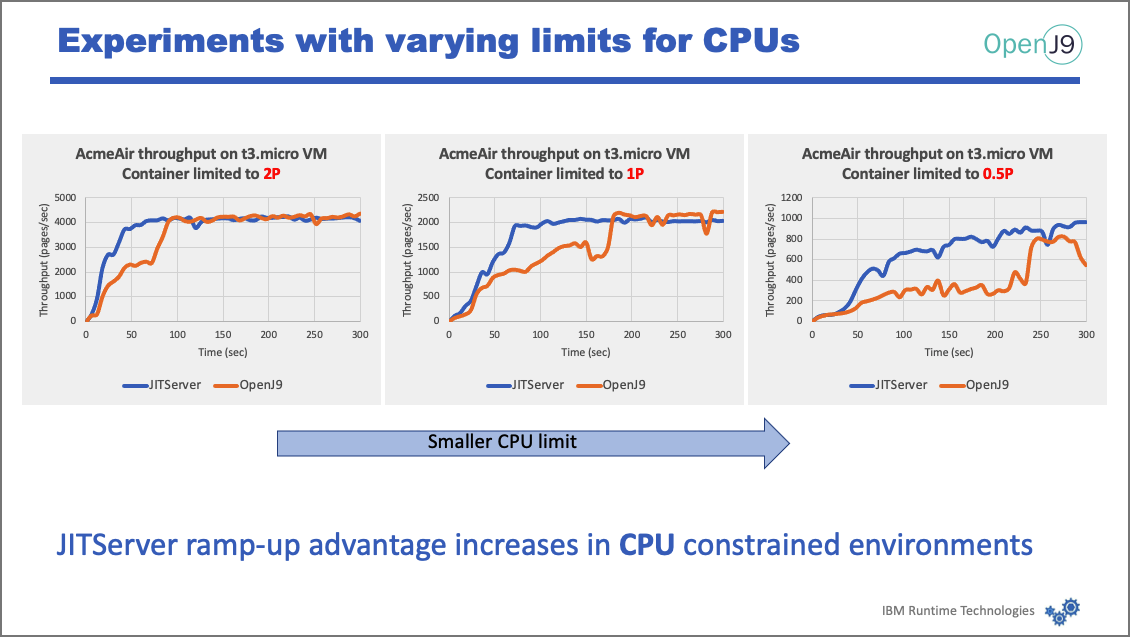
Next, we see the effects of limiting the number of processors, starting with 2, to 1, to .5. As the CPU limit decreases, the advantage of the JITServer solution becomes more pronounced (discrepancy increases between the two). In other words, JITServer is more beneficial as you go into more and more CPU-constrained environments.
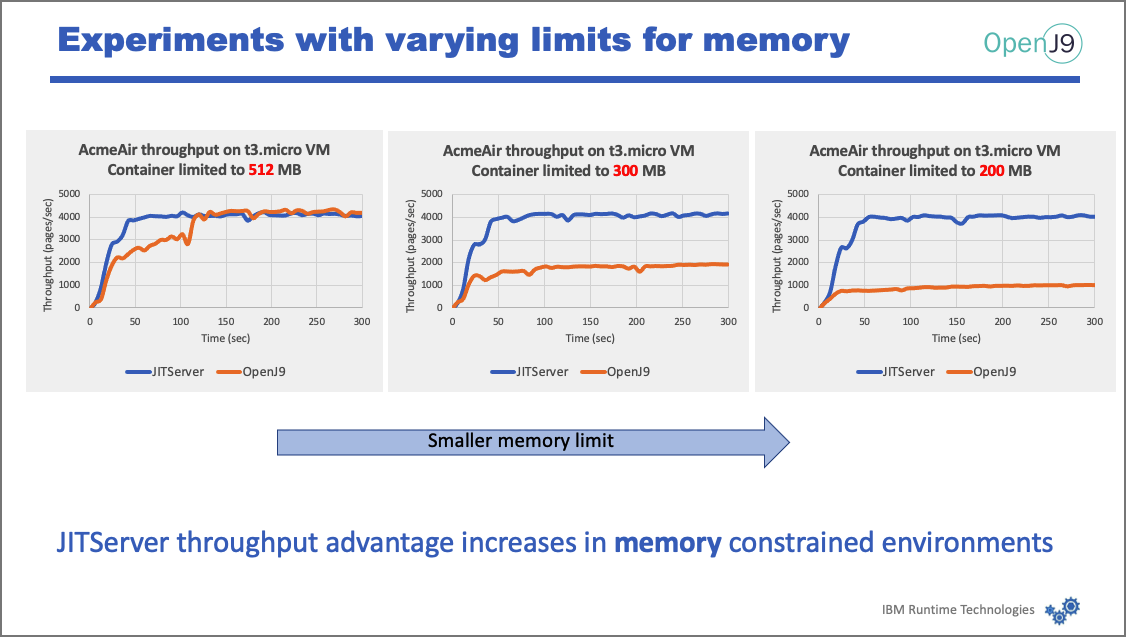
In this last graph, we see that the advantage of the JITServer increases as you go into more and more memory-constrained environments.
How JITServer can lower costs
To minimize the cost of using Amazon EC2, we will use the cheapest VMs available: the t3.nano and the t3.micro profiles. Both have two CPUs, but with different amounts of memory. These graphs show how the profiles handle a standard OpenJ9 setup and one that adds the JITServer.
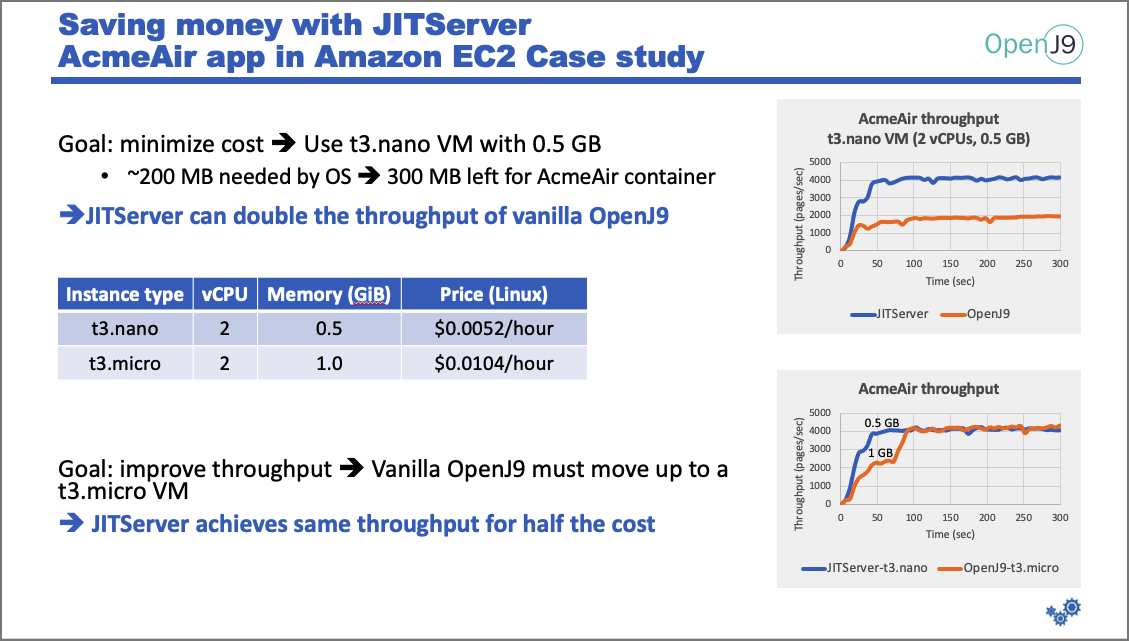
The first graph shows that .5GB is not enough to run AcmeAir with OpenJ9 JVM. Roughly, 200MB is needed by the OS, so only around 300MB is left for the JVM. As you can see, the performance of vanilla OpenJ9 is poor because 300MB is not sufficient to run the Java application and perform the JIT compilations. OpenJ9 prefers to fail the JIT compilations (thus affecting performance) rather than risking a native OOM event. In contrast, when OpenJ9 offloads compilations to the JITServer, the memory pressure drops and throughput increases significantly.
The second graph solves the low throughput problem by using a larger VM (the micro-VM has double the memory and double the price). The throughput is now equal, but it winds up costing twice as much.
DISCLAIMER: These graphs do not show that an additional VM is required to run the JITServer, but that is only temporary. The JITServer can be taken down once the compilations have subsided.
In this next example, we show that utilizing the JITServer can lower the number of nodes required to support a set of applications (see this blog for more details).
This example consists of the following:
- Running on Red Hat OpenShift Service on AWS (ROSA).
- The OpenShift Container Platform (OCP) consists of three master nodes, two infra nodes, and three worker nodes.
- The worker nodes have eight vCPUs and 16GB RAM (only ~12.3GB available to applications).
- Nodes will host four different applications:
- A low amount of load was used to simulate real-world environments.
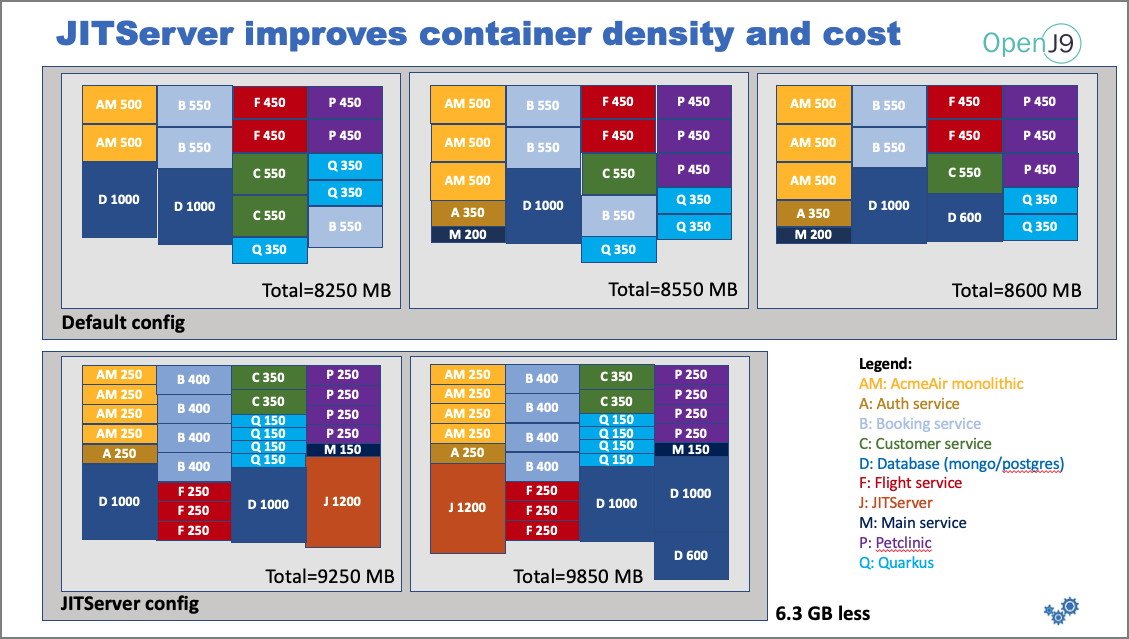
The top graph is using vanilla OpenJ9. Note that three nodes are required to hold all of the containers. Each box represents a container and lists the application and the memory requirements. The limits were determined by experiments to determine the minimum memory required to run without OOM issues. The boxes are scaled to indicate relative size.
The bottom graph has a JITServer configuration. Notice the size of boxes is much smaller, which means less memory is required for each container. Overall, the memory savings amount to 6.3GB, which allows us to fit all of the containers on just two nodes instead of three.
Since you pay by the node, using 33 percent fewer nodes means you save 33 percent in cost to manage this set of applications. But just because you want to maximize savings, you also need to provide the same throughput capabilities. Here, I'll show how the applications perform under different CPU loads:
Peak throughput is the same in both configurations (with and without JITServer), which means we get the same amount of throughput, but with less memory and less cost.
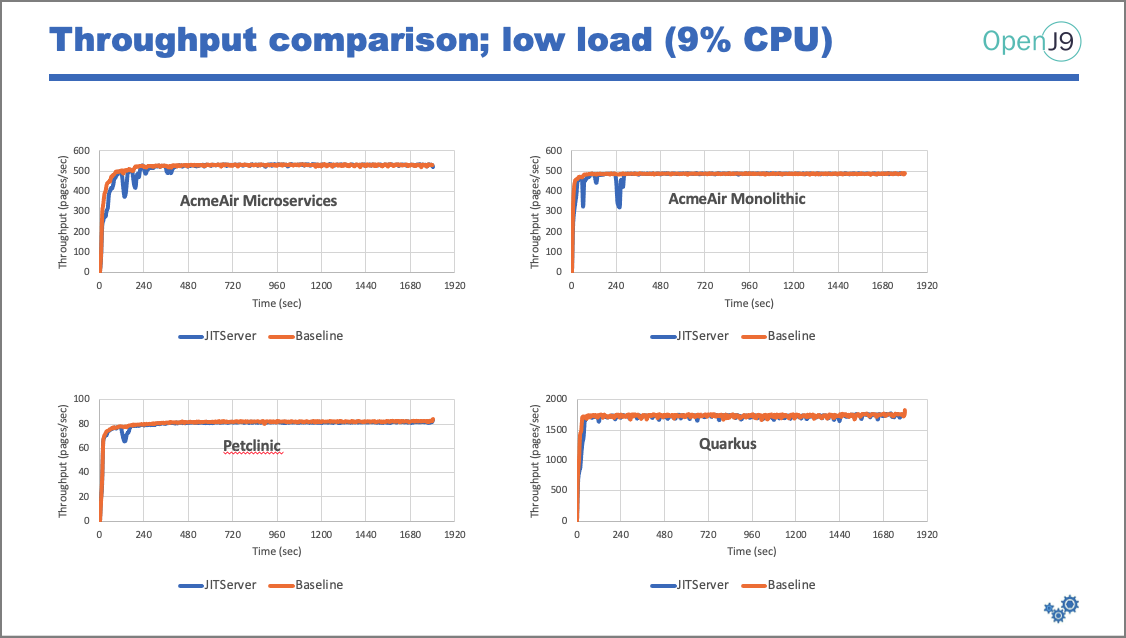
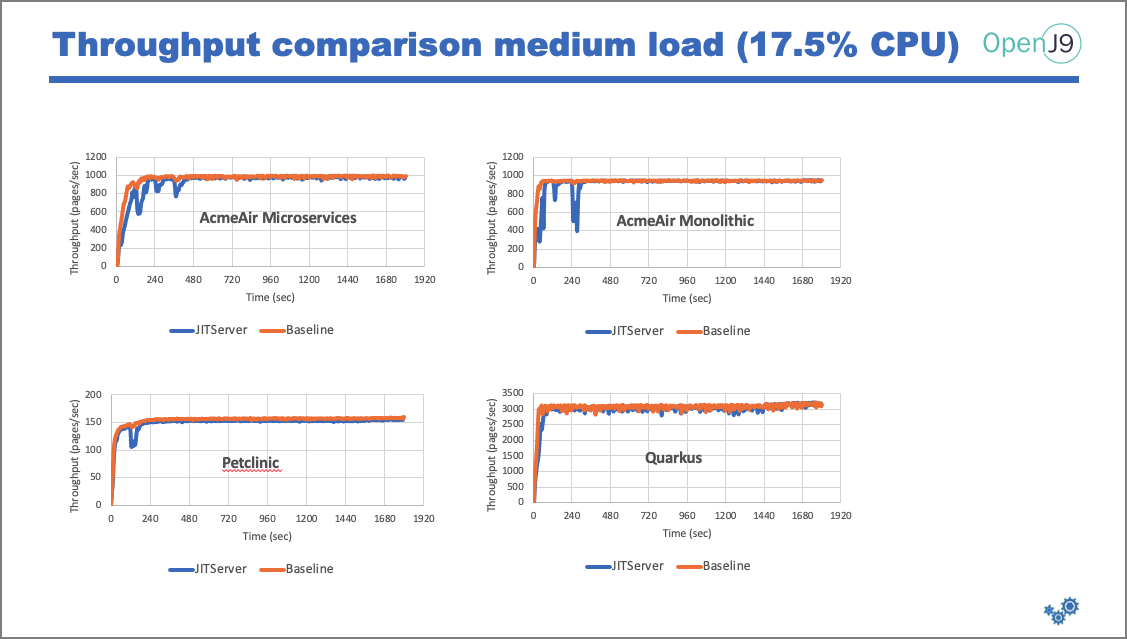
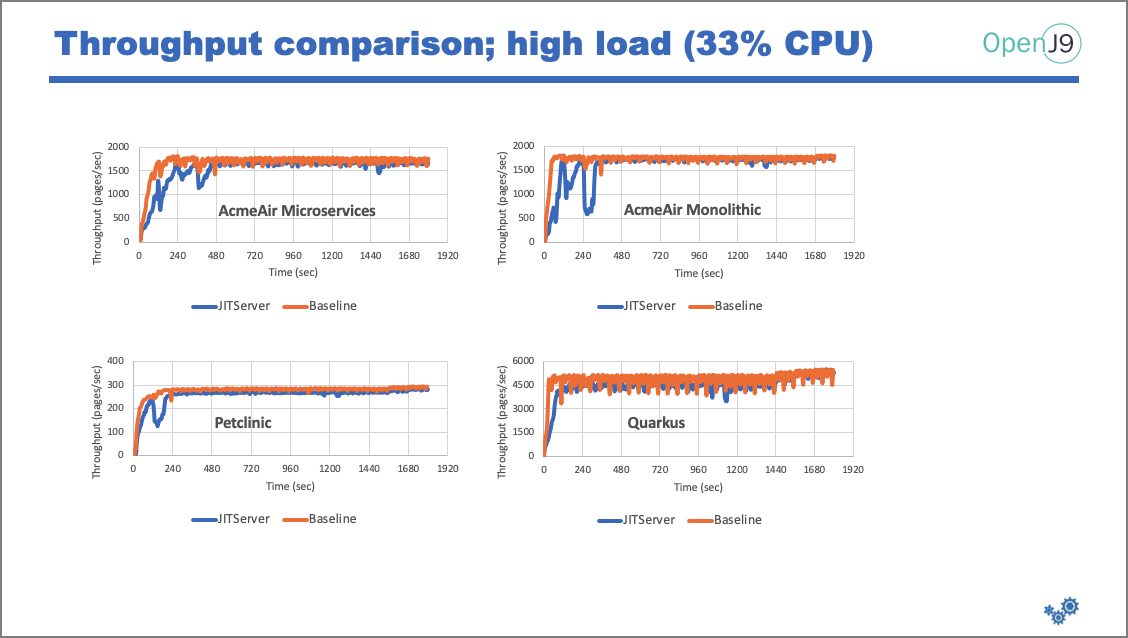
Key takeaways:
- JITServer can improve container density and reduce operational costs of Java applications running in the cloud by 20-30 percent.
- Ramp-up speed can be slightly affected in high-density scenarios, depending on the level of load and number of pods concurrently active (for example, the noisy-neighbor effect occurs when CPU resources are low and all applications want to compile at the same time (ramp-up), which rarely happens in reality).
Best use cases for implementing JITServer
There are trade-offs with using the JITServer. Here are the conditions where the JITServer provides the most value:
- Java application is required to compile many methods in a relatively short time.
- The application is running in a constrained environment with limited CPU or memory, which amplifies the interference from the local JIT compiler.
- The network latency between JITServer and client VM is relatively low (<1ms).
Competing technologies
Currently, the only other product with a functionality somewhat similar to OpenJ9 JITServer is the Cloud Native Compiler (CNC) from Azul. In contrast to OpenJ9 JITserver, CNC is a paid offering, uses proprietary code, and requires a non-disclosure license to use.
Where to get the JITServer
As mentioned, the JITServer is a part of the Eclipse OpenJ9 JVM that comes with IBM Semeru Runtimes.
IBM Semeru Runtimes is IBM's supported open source version of the Java SDK and fully implements the Java Standard Edition (SE) APIs, and can be freely downloaded, even for production use.
The central download repository can be found on IBM Developer.