Article
Kubernetes networking for developers
What developers need to know about Kubernetes networkingBack in the day, developers didn't need to concern themselves too much with networking. They wrote their code, made sure it worked locally, and then they deployed to another machine for more testing or production. Typically the application was assigned an IP address, and if there was more than one instance of the application running, each needed its own IP address, and everyone was happy. Performing maintenance was straightforward -- you shut down the application, completed some maintenance steps, and started the application again.
With the advent of containers and container orchestration technologies, things are slightly different today. Some applications aren't affected, and others are. As a developer, what networking information do you need to be aware of in this cloud-native world of Kubernetes and containers? This article aims to answer your questions and give you the basics you need to get your work done.
Kubernetes basics
If you've never worked with Kubernetes or feel that you need a short primer, then continue reading. Otherwise you can jump to the next sections, which address networking concepts.
A container is a single application or process that is run from a self-contained image that has everything it needs to run, including the application. From the application perspective, the container looks and feels like an operating system (OS) running on a server somewhere, with that application as the only process running. It has its own network interface, file system, and everything you would expect for an OS.
A Kubernetes pod is a collection of containers that always run together on the same Kubernetes worker node. For example, if two applications are always installed together and scale together, they would most likely be defined within the same pod. Pods are the most granular point of scalability in Kubernetes. When you hear about "scaling up and scaling down," it's the Pods that are scaling up and scaling down. Kubernetes creates more copies of the same pod and runs them. Do you want three instances of your application running? Define your application in a pod and scale it to three.
Localhost (IP address 127.0.0.1)
All containers within a pod are running on the same worker node. Kubernetes can take advantage of this structure and give the entire pod a shared network namespace. A network namespace is a Linux kernel feature that allows network resources to be put into groups. Processes running within those groups can only see the network resources defined for their group. For example, processes running in Network Namespace A see one set of network resources, while processes running in Network Namespace B see another set. This approach is how Kubernetes isolates pods from each other on the worker node. For example, Pod A listening on port 80 should not keep Pod B from also listening on port 80.
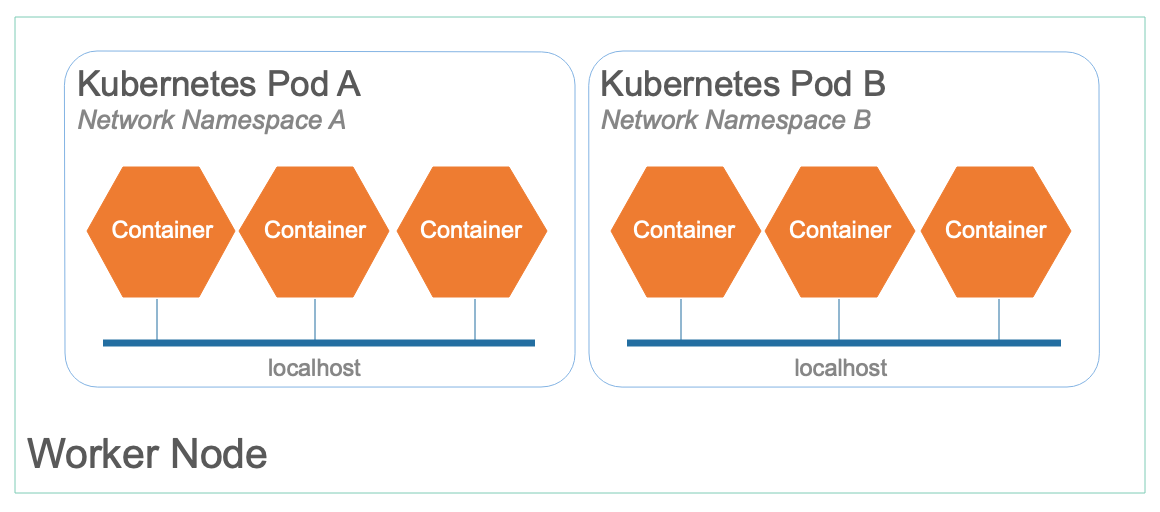
Network namespaces matter because when all containers run in a pod, they all share the same network namespace. While containers inside the same pod can talk to each other over localhost, they can't listen on the same port.
Pod network
Much like how virtual servers can be assigned an IP address, pods are assigned an IP address. Containers running in a pod can bind to ports on the pod IP address, just like processes running on a virtual server can bind to ports on its IP address. In this way, a Kubernetes pod is very much like a virtual server from a networking perspective.
The IP addresses used come from an addresses block known as the pod network. Each time a pod is spun up, Kubernetes pulls an available IP address from the pod network and assigns it to the pod before turning it on. Pods all appear to be on the same network and can communicate with each other over this network (by default). There are network policies that can limit what a pod can talk to, but by default they are free to talk to each other.
From a development perspective, there are a couple of points to note here. An IP address that is assigned to a pod stays with the pod until the pod is deleted. Therefore, if a container crashes and restarts, it has the same IP address as it did before it crashed. In contrast, when a pod is deleted, it loses its IP address all together.
It's generally a bad development practice to depend on this behavior because pods are commonly deleted and created either during a scaling operation, or when rebalancing the pods in the cluster. Consider a common scenario: when a worker node dies, the pods that were running on the worker node are created again on another worker node, getting a new pod IP address.
The bottom line here is your application needs to be completely independent of IP addresses, or be able to handle IP address changes of application instances. Do not depend on your application IP address to remain static.
Service network
The previous section described how pod IP addresses are dynamic, and change as pods are created and deleted. So how then are pods expected to know where other pods are and communicate with each other? The answer is a Kubernetes Service. A Kubernetes Service is a definition that describes a domain name and which pods traffic is directed to. For example:
kind: Service
apiVersion: v1
metadata:
name: web
namespace: my-app
spec:
selector:
app: web-server
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
The previous service example would create a web.my-app.svc.cluster.local DNS entry that resolves to an IP address on the service network. The service network is similar to the pod network, except that the IPs are assigned to services, not pods. The IP address of the service stays with the service until the service is deleted. The service IP assigned balances the load of traffic to all pods that match the service's spec.selector definition. In the previous example, any pod with metadata.labels.app equal to web-server, would be considered to send traffic to on port 80.
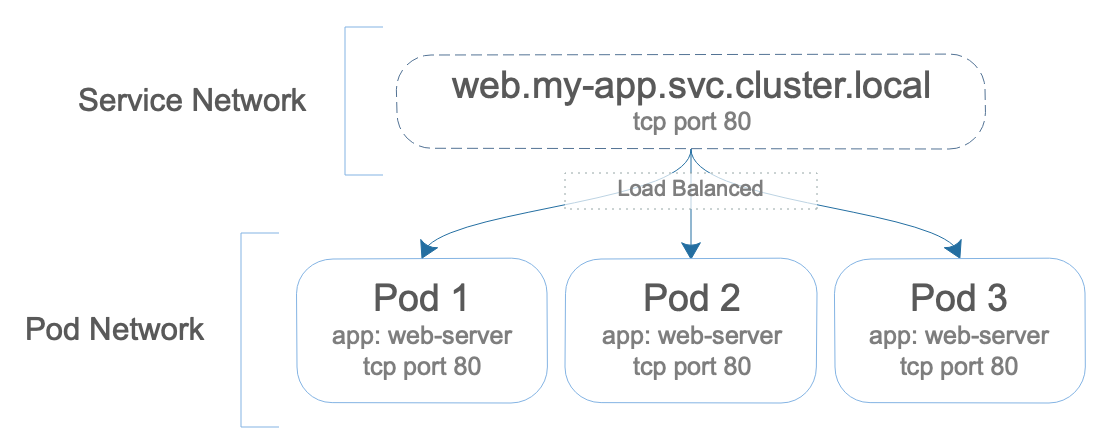
By default, services are the ClusterIP type. However, the following types are supported:
ClusterIPNodePortLoadBalancerExternalName
Most likely, your application depends on external services or applications. Instead of the IP address of those endpoints, use domain names and let Kubernetes worry about the actual IP. So instead of configuring your application to talk to https://172.30.102.188/stuff, configure it to talk to https://web.my-app.svc.cluster.local/stuff and let Kubernetes address the other needed networking tasks.
If your application exposes an endpoint, you should expect to create a Kubernetes service to expose it to the cluster. Also note that you can include any combination of ports and protocols in a single service in case you need to listen on multiple ports.
Inside and outside traffic
So far, this article dealt with traffic within a Kubernetes cluster. This section discusses how services can communicate outside the cluster. Both the pod network and service network are address spaces that only exist within the Kubernetes cluster. You can't reach these addresses from the outside.
In order to accommodate external traffic, Kubernetes created constructs that allow its services to join with real address spaces outside the cluster. These constructs build on one another and are denoted by the service type (such as ClusterIP, NodePort, LoadBalancer). A service of the type NodePort includes the functionality of the type ClusterIP. A service of the type LoadBalancer includes the functionality of the type NodePort. (The only exception is ExternalName, which is not discussed in this article.)
NodePort type
Each worker node in the cluster has one or more IP addresses assigned to it. These IP addresses are the physical IPs (instead of the virtualized pod and service networks) that the worker nodes communicate over. Worker nodes have a private IP assigned, but if your cluster is exposed to the oustide world, it might have both a private and a public IP address assigned.
When a service is of the type NodePort, it picks a random port with a range (default: 30000-32767) to expose the traffic on. This port is opened up on all worker nodes. When traffic hits that port, it balances the load of traffic to a pod, just like it does when the service is of type ClusterIP. NodePort. Effectively, it just binds a random port on all worker nodes to your service, allowing external services to communicate with it. Sending traffic to any worker node on that port gets the traffic to the right place.
LoadBalancer type
While NodePort gets the job done, it's not very useful by itself. It's not great to tell users to talk to you service at http://some.external.domain:31633/stuff. Kubernetes allows external load balancers to integrate by creating the service of the type LoadBalancer. The options available for this type are dependent on the cloud provider. Basically, it allows you to define an external IP address on a port of your choosing, and have that traffic automatically directed to the auto-assigned port on the worker node.
LoadBalancer type services are NodePort type services, except they orchestrate an external non-worker node IP to point to the randomly assigned port on the worker node.
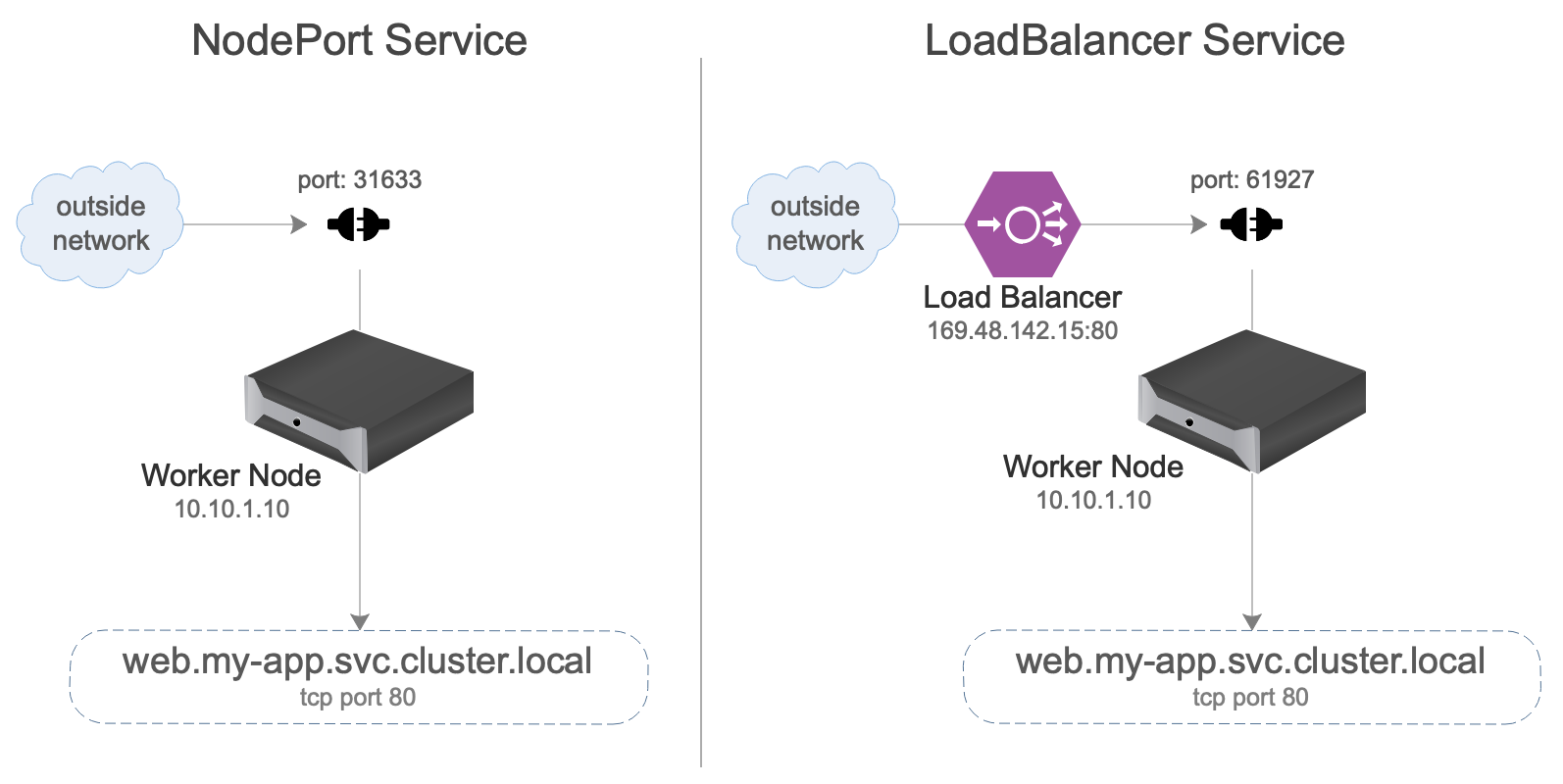
Because the IP address used is external to the Kubernetes cluster, it doesn't matter if that IP is a public IP or a private IP. The behavior is the same.
Ingress resource
Ingress is not a type of Kubernetes Service, but it works in conjunction with them. An ingress is a Kubernetes resource that allows HTTP/HTTPS traffic to be routed to services based on the HTTP routes in the request. It allows you to route https://my-domain.com/service_a to service_a.my-app.svc.cluster.local, and https://my-domain.com/service_b to service_b.my-app.svc.cluster.local.
For application design and development, the ingress resource can affect how you expose your applications to the outside world and affect the service architecture you decide to use.
Tips and tricks
Things don't always go as planned. As a developer, you need to troubleshoot what's going on with the application when it's running in Kubernetes. The following sections describe a few tricks that can help you when tracking down an issue.
Port forwarding
If you need to communicate directly with a container or pod without going through the service or ingress, you can using the kubectl port-forward command. This command uses the Kubernetes API to route a port on your local machine to a port within a pod. For example, if you want to talk to your web application container directly, you could run the following command:
$ kubectl port-forward pod/my-app 8080:80
This command allows you to connect to http://localhost:8080 on your local machine, where the traffic is sent over to the Kubernetes pod my-app. It also works for services. If you want to route traffic from your local machine to a service (instead of a pod), you can run the following command:
$ kubectl port-forward svc/my-service 8080:80
Network utilities
If you want to get a shell into a container that has some network tools on it, run the following command:
$ kubectl run -it --image=amouat/network-utils --attach network-utils -- /bin/bash
This command creates a deployment and a pod. Then it drops you right into a shell where you can run commands. When you are done, run the following command:
root@network-utils-5cff9856f6-w52qc:/# exit
$ kubectl delete deployment network-utils
Summary
Kubernetes networking should be very familiar if you're used to developing in environments with traditional server networking. Knowing the various ways users can and will connect to your application affects how you design and build your applications. The tips you learned in this article can help you make design decisions during development.
If you are curious and want to dive deeper into Kubernetes networking (or even to just validate what you've just read), check out the following links to guides that go deeper.