Article
Cyrillic in Unicode
Adding Cyrillic (and other) script fonts using Unicode and 8-bit code methods in LinuxArchive date: 2019-08-20
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.The fall of the Soviet Union has led to a burgeoning computer industry in what are now Russia and its neighboring states. Economic and social conditions have led to the adoption of Linux as a leading operating system in this region. Russian and other Slavic languages are written in Cyrillic script, which is most often represented by the use of the KOI8-R or the ISO 8859-5 character sets. These are ASCII-compatible systems that have served well in the past, but create problems of translation and compatibility.
Unicode is an emerging standard that allows for representation of all the world's languages. With its multibyte system, Unicode makes tens of thousands of characters available in a standard, interchangeable format.
This article discusses how to use Unicode-based Cyrillic script and alternatives on a Linux-based computer.
Cyrillic on the computer
Cyrillic can be represented on a Linux computer by four main methods: KOI8-R, ISO 8859-5, Windows 1251 Codepage, and ISO 10646-1 UTF-8 Unicode 3.0.
The Cyrillic script
Clement of Ohrid invented the Cyrillic script as a more legible version of the Glagolitic alphabet invented by Slavonic monks Cyrill and Methodius (who were brothers and his teachers) in Macedonia about 863 A.D. Glagolitic was an encrypted Greek alphabet with extensions for Slavic sounds. Cyrillic script spread and transformed into its current Romanized shape called Grazhdanka under Russian Tsar Peter the Great, and is used by more than 70 languages in Europe and western Asia.
Modern Cyrillic is a small, accent-free alphabet that makes it suitable for use as a computer interface font.
KOI8-R
KOI8-R stands for the Russian term meaning Code for Information Exchange, 8-bit, Russian. The KOI8-R Codepage table is the de facto standard for Internet Mail/News, the World Wide Web, and other interactive services in Russian for all the former Soviet territories. KOI8-R was designed for the Russian and English languages and covers only Russian Cyrillic characters.
Table 1: The KOI8-R Codepage table

KOI8-R is fully compatible with 7-bit ASCII. The Cyrillic characters are located in the upper half of the byte codes (128 through 255 or A0 through FF hexadecimal). The main design advantage of KOI8-R is that the Cyrillic characters' positions correspond to the English characters with the same phonetics. If the eighth bit of the English character 'a' is set, the result is the Cyrillic 'a'. This means Cyrillic text written in KOI8-R can have the eighth bit stripped from each character and the result will still be readable text in English characters. This is significant because of the predominance of Internet applications, specifically mailers that silently strip off the eighth bit. "Star Trek" has trained software designers to believe that every person in the Universe speaks English.
The KOI8-R keyboard layout
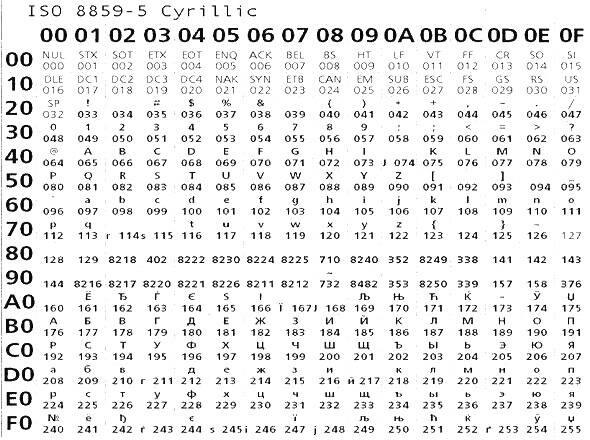
ISO-8859-5
The ISO 8859 character sets were designed by the European Computer Manufacturer's Association (ECMA) in the mid 1980's and are endorsed by the International Standards Organization (ISO).
Table 3: The ISO 8859-5 character set
Windows 1251 Codepage
The Windows 1251 Codepage is the system Microsoft uses to represent Cyrillic in Windows. The 1251 Character set is useful when mounting a Windows file system. It allows compatibility with Cyrillic file names created through Windows.
Table 4: The Windows 1251 Codepage table

ISO 10646-1 UTF-8 Unicode 3.0
The Unicode UTF-8 coding system contains all characters found in the character sets ISO 8859-5, Microsoft Codepage, CP 1251, and KOI8-R systems. UTF-8 is most simply described as a collection of code tables using one integer index to identify the table and another for the character. However, this is an oversimplification as Unicode is more complicated than that. Unicode allows the greatest flexibility and compatibility of all character representation solutions. Unfortunately, the majority of the applications for Linux do not support it.
The international Unicode standard ISO 10646 defines the Universal Character Set (UCS), which is a superset of all other character set standards that allows compatibility among them all. Conversion of any text string to UCS and back will not lose any information.
The UTF-8 standard (UCS Transformation Format) uses from one to six bytes to represent a character. Other Unicode methods are UCS-2 and UCS-4. These use two or four bytes to represent a character. Most Linux/UNIX tools cannot handle 16- or 32-bit words as characters. UTF-8 allows the ASCII characters to be represented as a single byte.
UTF-8 offers much more flexible programming capabilities. WIN32 programming provides support for UCS-2 or ASCII but not both. A program either has #define UNICODE in the source and uses TCHAR instead of char where needed for Unicode, or it does not. This makes it necessary to build two versions of a program. UTF-8 allows one program to handle both ASCII and Unicode.
All of the UCS characters from U+007F (Unicode 128) are in encoded variant multibyte sequences. No ASCII byte (0x00-0x7F) can appear as part of any other character, thus any multibyte sequence that represents a non-ASCII character is always in the range 0xC0 to 0xFD and tells how many bytes follow for this character. All further bytes in a multibyte sequence are in the range 0x80 to 0xBF. With six bytes available, 2^31 UCS codes can be represented. This allows Unicode to work in a Posix (Linux/UNIX) system.
See the Resources section for the Linux Unicode fonts that are freely available.
Choosing a character representation system
Windows 1251 gives the user compatibility with MS Windows. ISO-8859-5 has the best support and is the easiest to set up. KOI8-R is the standard for Russia and other ex-Soviet Block countries. Unicode is the standard that will be used in the future on all computers and platforms; it offers truly universal language support.
Today the most popular choices are ISO-8859-5 or KOI8-R. The latter is by far the most popular in Russia and probably should be used by anyone currently working with text of Russian origin.
The problem with KOI8-R is that it is not a universal standard and suffers from a plethora of variations to accommodate many Slavic language flavors. Unicode will replace it, but it will take several years before it becomes predominant.
The non-Unicode Cyrillic solutions allow immediate Slavic language support without the problems of having to modify Linux for multibyte character support.
Linux Unicode Cyrillic setup
To use UTF-8 Unicode in Linux, you need a system that's capable of encoding and decoding UTF-8 Unicodes. Many parts of Linux require no modifications, patches, or replacements at all. Byte stream applications like cat just process 8-bit sequences and remain ignorant of the encodings. Programs that generate, display, count, and read characters need to be modified to handle UTF-8 multibyte data by adding routines to encode/decode UTF-8 characters.
User interfaces like Gnome and KDE must change the interface displays. Most Linux distributions now support UTF-8 and Cyrillic script in the as-shipped configurations.
How the system is changed to support UTF-8 depends on whether Linux is used in console character device mode or is running a GUI-like GNOME or KDE. To try the console altering commands, switch to an alternate console and log in as "root" by pressing the CTRL+ALT+functionkey combination. This can be used from the GUI. Do not confuse this with the ALT+functionkey, which changes the virtual desktops.
UTF-8 support
unicode_start
set font /usr/lib/kbd/consolefonts/UniCyr_8x16.psf.gz
loadkeys /usr/lib/kbd/keymaps/i386/qwerty/ru.kmap
The mapscrn command is not used when Unicode is being used.
An interesting test of the Unicode fonts that are available can be done as follows:
# Test for checking the unicode maps corresponding to various fonts. Try
for i in 01 02 03 04 05 06 07 08 09 10
do
unicode_start iso$i.f16 iso$i
less -r utflist #display this file
done
unicode_stop
Eight-bit character support
To change the characters on the console, build a script file by creating a file that loads the appropriate keymaps and fonts from their directories. An example is:
if [ notset.$DISPLAY != notset. ]; then
echo "`basename $0`: cannot run under X11"
exit
fi
loadkeys /usr/lib/kbd/keymaps/i386/qwerty/ru.kmap # load the Russian keymap file
setfont /usr/lib/kbd/consolefonts/koi8-8x16.psf # Load the koi8 Cyrillic fonts
mapscrn /usr/lib/kbd/consoletrans/koi8-r.acm.gzÂ
echo -ne "\033(K" # This is the sequence that enables character set G0Â
the mapscrn loads
#\033 is the escape character
echo -ne "\007" #beep
echo "Use the right Ctrl key to switch the mode..." #notify the user of the change
The command: mapscrn [ -o map.orig ] mapfile is used to load a user-defined character mapping table into the console driver. This allows the user to place the console driver into a user-defined mapping table mode by sending the escape sequence "(K" for the G0 character set and ")K" (see Listing 3) for the G1 character set. When the -o option is given, the old map is saved in map.orig (or any name you pick). The font used has been set by the setfont command. For more information on the mapscrn command, see Resources).
Another example is the following:
setfont uni-511-14.psf
loadkeys UniBalt.kmap
mapscrn /usr/lib/kbd/consoletrans/koi8-u.acm.gz
echo -ne "\033)K"Â # \033 is the escape character.)K Loads the G1 map
The KOI8-U codeset may be better than KOI8-R, as it is identical to KOI8-R but adds more obscure Ukrainian symbols.
Creating script files for loading fonts
Make sure the script file you create has the attribute for permissions set to executable. Login to an alternate console and run the script: "./scriptname". Now when the right CTRL key is pressed the Cyrillic characters are displayed. Pressing it again toggles the display back to ASCII. The "if" statement prevents running this script under the X11 GUI. If you try it, the file name and the "cannot run under X11" message will be displayed and the script will be aborted.
UTF-8 can be enabled and disabled with the commands unicode_start and unicode_stop. Do not run these in a terminal emulation shell under X11; the system will crash. These commands come with the kbd package. If this package is not available on your distribution, see Related topics for a site where kdb and the extended version (the console-tools-0.2.3 package) can be obtained.
The unicode_start [ font [ screen font map ] ] command sets the console's screen output as UTF-8, and the keyboard is put into Unicode mode (for details type man kbd_mode at the command prompt).
If an appropriate screen-font map is not loaded the keyboard may be made unusable.
Installation of script fonts
It is a good idea to install as many different script fonts as possible. Even if the font is not UTF-8 specific, it can be used to display Cyrillic and other scripts.
To display characters from different scripts on the same screen, use a Unicode console font download and install the packages. See Related topics for download and install links.
These contain a font (LatArCyrHeb-{08,14,16,19}.psf) which contains Latin, Cyrillic, Hebrew, and Arabic scripts. The ISO 8859 parts 1-6, 8, 9, and 10 (5 is Cyrillic) are included. To install this font, copy it to /usr/lib/kbd/consolefonts/ and execute "/usr/bin/setfont usr/lib/kbd/consolefonts/LatArCyrHeb-14.psf".
Font installation commands
Installation of fonts is a simple procedure that can be done in a few quick steps. Here is a typical installation procedure:
gunzip unifont.hex.gz # uncompress the font
hex2bdf < unifont.hex > unifont.bdf # change it to bdf format
bdftopcf -o unifont.pcf unifont.bdf # create the pcf format for use
gzip -9 unifont.pcf # compress it using best method
cp unifont.pcf.gz /usr/X11R6/lib/X11/fonts/unifont # copy it to the font directory
cd /usr/X11R6/lib/X11/fonts/unifont
mkfontdir # set the font for X11 use xset fp rehash
The following programs are also used to install fonts:
dumpkeys -l | lessdisplays all the available keys.mkfontdir directoryprepares a font directory for use by the X server. It needs to be executed after installing fonts in a directory.xset fp+ directoryadds a directory to the X server's current font path. To add a directory permanently, add aFontPathline to your /etc/XF86Config file in section "Files".xset fp rehashneeds to be executed after calling mkfontdir on a directory that is already contained in the X server's current font path.xfontselallows you to browse the installed fonts by selecting various font properties.xlsfonts -fn fontpatternlists all fonts matching a font pattern. It also displays various font properties. The command,xlsfonts -ll -fn fontlists the font properties CHARSET_REGISTRY and CHARSET_ENCODING, which together determine the font's encoding.
UTF-8 cut and paste
Cut and paste with UTF-8 consoles requires the patch linux-2.3.12-console.diff from Edmund Thomas Grimley Evans and Stanislav Voronyi.
The patch command is used with the diff file to add the changes to their original file thus patching the file. The diff file header explains the changes made to the console.c source code.
UTF-8 support in applications
UTF-8 is well-supported in many Linux applications, and most programs can be easily configured to support it.
Many browsers will display HTML documents that use UTF-8. The following definition needs to be in the document header:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
Other applications that are already UTF-8 aware are editors like vi, Emacs and xedit. These are ready for and can be configured for UTF-8.
Another application that is specifically designed to use UTF-8 is the Mined 2000 editor (see Resources). The makefile is a little tricky to adjust to Linux. Send me an e-mail if you have trouble and I will walk you through the adaptation.
Internet mail programs seem to create a large number of problems when used with UTF-8. It is a matter of making sure that the eighth bit is not stripped off and the font support is set for Unicode UTF-8.
Conclusion
Although neither the most common nor the most popular solution, Unicode UTF-8 is the most flexible option and the only one that preserves ASCII compatibility and all of the established character code sets. In a few years, UTF-8 should predominate as the standard code system in all Linux distributions. This will make Linux the first truly international operating system while preserving the ability to handle ASCII code.