Article
The basics of image processing and OpenCV
Understand the basic concepts and learn why image processing is neededThis article gives a basic understanding of image processing by looking at basic terms, then answering questions such as why this field is needed and what the key stages are. For each part, you'll see the corresponding implementation of OpenCV, which is a library used for image processing.
What is an image?
It's always good to start with the basic definitions before diving into deeper topics. In this subject, the basic term is the image. An image is a function that consists of two real variables, that is, coordinates x and y. This function represents the brightness (or color) at a point with the coordinates x and y. Usually, x and y refer to the horizontal and vertical axes, respectively.
What is a digital image?
When you have a finite x and y, we call this function, f, as a digital image. In other words, a digital image is a representation of a two-dimensional image as a finite set of digital values, which are called pixels. The digital image contains a fixed number of rows and columns of pixels.
The function f(x,y) must be nonzero and finite, that is:
![]()
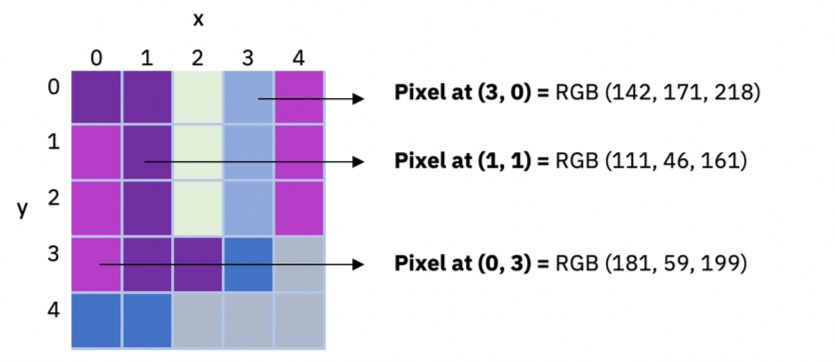
What is a pixel?
The digital image contains a fixed number of rows and columns, and each combination of these coordinates contains a value that represents the color and the intensity of the image. They are also known as picture elements, image elements, and pixels. Also, you might see its abbreviations as px or pel (for picture element).
As stated in Digital Image Processing, "digitization implies that a digital image is an approximation of a real scene." So, the main purpose of pixels is to simulate the real scene by representing the gray levels, colors, heights, and opacities.
What is color?
Let's say we are using an RGB color model and want to represent our color image with the model's components. In the RGB model, we need to separate red, green, and blue components as different color planes (as shown in the following image). However, when we represent a pixel value that is the color, we combine these three values (tuple with three elements).
Depending on the information represented by each pixel, there are mainly four types of images.
Binary images
Binary images are the simplest type of images because they can take only two values: black or white, respectively, 0 or 1. This type of image is referred to as a 1-bit images because it's enough to represent them with one binary digit.
Binary images are used in applications where we need more information about the general shape or outline of the interested scene.

Grayscale images
As the name implies, the image contains gray-level information and no color information. The typical grayscale image contains 8-bit/pixel (bpp) data. In other words, this type of image has 256 different shades of colors in it, varying from 0 - 255, where 0 is black and 255 is white.

Color images
All grayscale and binary images are monochrome because they are made of varying shades of only one color. However, not all monochrome images are grayscale because monochromatic images can be made of any color. Therefore, color images are made of three-band monochrome images. These 8-bit monochrome images represent red, green, and blue (RGB), which means that this type of image has 24 bits/pixel (8 bit for each color band).

Indexed images
Indexed images are widely used in GIF image formats. The purpose is instead of using a large color range (in RGB, we have 256x256x256 = 16777216), we can use a limited number of colors. Every pixel in a GIF image uses a color index. In the lookup table, the index points to a specific color. For example, the maximum number of colors in GIF images is 256. By using indexed images, we can reduce the file size.
What is image processing and why do we need it?
The main purpose of image processing is to gain useful information or to enhance the original image by applying some operations on it. It can be said that image processing is a signal dispensation because the input that is given to the program is the digital image, and the expected output is a new form of the image or the information about it.
When we look at the image processing or computer vision fields, the main purpose is to give the eye functions to machines. From this perspective, it's possible to state that image processing is the conversion of the human visual system (HVS) to digital images. To get the most realistic output from the digital images, we need to do some processing on them.
There are various application areas where image processing is being used. One of the most common use cases is image enhancements, that is, as we defined image processing to improve the quality of the image to gain more information about it. The following image shows one of the image enhancement techniques, equalized histogram, which reforms the image to see more details.
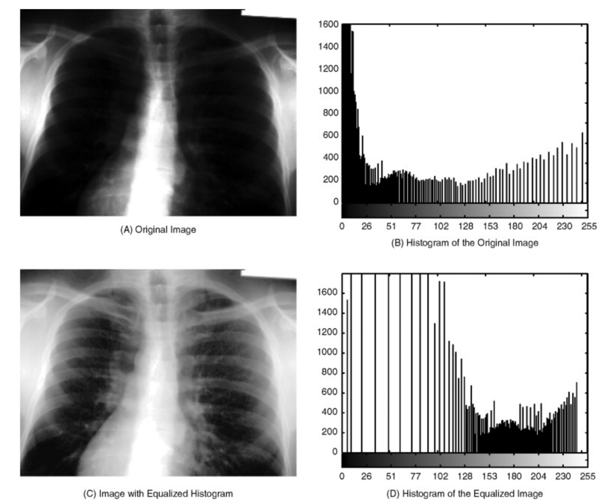
Figure 1: Image Enhancement example [1]
Other application areas can be multispectral images, which include X-rays, gamma rays, ultraviolet, and infrared data. The human eye can detect wavelengths from 380 - 700 nanometers. This range is called visible light. Although we can't see the wavelengths that are out of this range, a sensor or a camera can. By applying image processing, we can see and analyze these types of data to use them in use cases such as medical or astronomical observations.
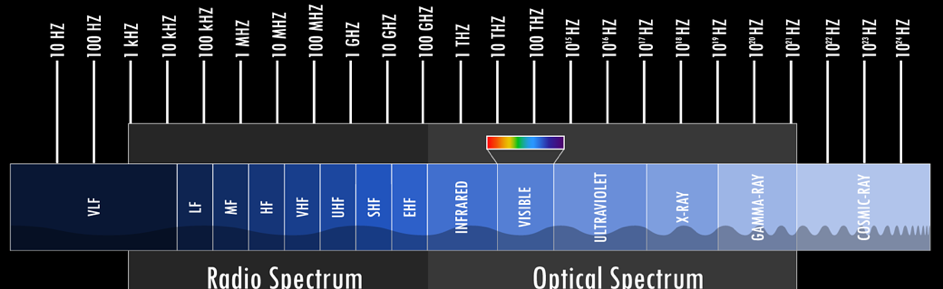
Figure 2: Electromagnetic spectrum [2]
Stages of image processing
Before everything, what is OpenCV?
OpenCV is an open source library for image processing and computer vision that was developed by Intel. OpenCV applications run on Windows™, Android, Linux®, Mac, and iOS systems because it is a platform-independent library. It's commonly used with Python and C++ languages, but we can develop applications by using it with the Java™ language, Perl, and Ruby. OpenCV is great for working in this field because it handles the workload of dealing with the implementation of mathematical formulas.
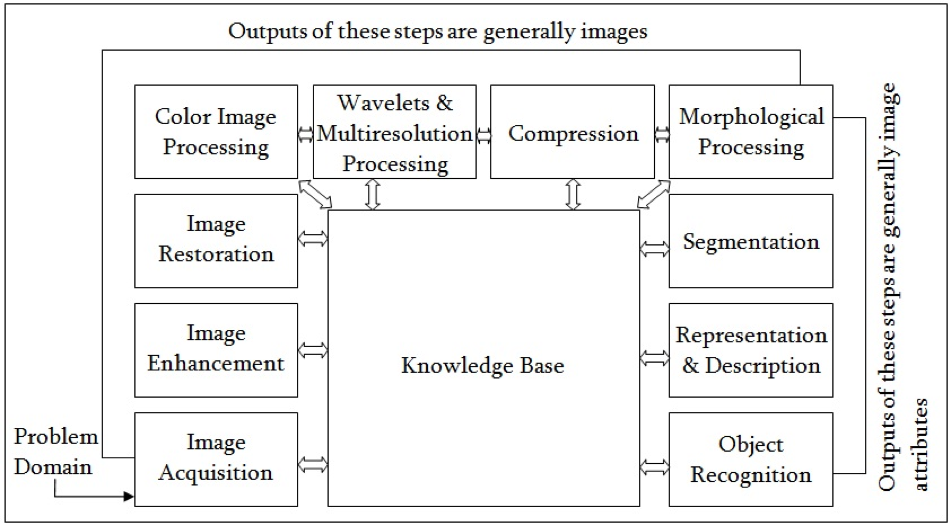
Figure 3: Fundamental steps of image processing [1]
This section covers the main stages of image processing so that you understand what operation can be done with this field and what outputs will be generated after each operation.
Image acquisition: As the name implies, this first key step of digital image processing aims to acquire images in a digital form. It includes preprocessing such as color conversion and scaling.
OpenCV can read the images directly from a camera input feed or a directory path where image is located with its
imreadfunction.#Taking input from a directory path image = cv2.imread(IMAGE_PATH,0)Image enhancement: This stage's main purpose is to extract more detailed information from an image or interested objects by changing the brightness, contrast, and so on. Read more about changing the contrast and brightness of an image.
Image restoration: The purpose of image restoration is to recover defects that degrade an image. There might be many reasons to degrade an image such as camera mis-focus, motion blur, or noise. Restoration gives you the ability to reform these distorted parts for more useful data. Read more about image denoising .
Color image processing: This processing is focused on how humans perceive color, that is, how we can arrange the colors of images as wanted. We can do color balancing, color correction, and auto-white balance with color processing. This tutorial explains more about color spaces.
Wavelets and multi-resolution processing: This is the foundation of representing images in various degrees.
Image compression: Image compression works on the image size and its resolution. It can be done easily with OpenCV's
cv2.resize(image, (new_width, new_height))function.Morphological processing: Morphological processing processes images based on shapes to gain more information about the useful parts of the image. Tasks can be summarized as dilation, erosion, and so on.
For the erosion, we use
cv2.erodeand for the dilation technique we usecv2.dilate. See the official documentation on eroding and dilation.Segmentation: This is one of the most commonly used techniques in image processing. The aim is partitioning an image into multiple regions, often based on the characteristics of the pixels in the image, which generally refers an object (see the following image). It is used in pattern recognition and scene analysis algorithms.

Figure 4: Using semantic segmentation to classifies labels (such as car, road, or building)
Representation and description: After applying segmentation to an image, we need an operation that describes the representation of an object to describe them. Representations and descriptions have two choices: external characteristics (boundary) and internal characteristics (pixels in the segmented region). I don't go into much detail on these techniques because it is beyond the scope of this article. For further information, see Building a Pokedex in Python: Comparing Shape Descriptors with OpenCV (Step 6 of 6).
Object detection and recognition: These processes find instances of objects in images so that we can label them with their classes.

Figure 5: Example of detection and recognition [3]
Conclusion
This article gave you a basic understanding of image processing by looking at basic terms, then answered questions such as why this field is needed and what the key stages are. For each part, you'll saw the corresponding implementation of OpenCV, which is a library used for image processing.
Related link and resources
[1] da Silva, E. A. B. and Mendonca, G. V., "Digital Image Processing", in The Electrical Engineering Handbook, Chapter VII.4, pp. 891-910. Editor: Wai-Kai Chen, Elsevier - Academic Press, 2005, ISBN: 0-12-170960-4