Article
Linear regression from scratch
Learn about linear regression and discovery why it's known for being a simple algorithm and a good baseline to compare more complex models toLinear regression is known for being a simple algorithm and a good baseline to compare more complex models to. In this article, explore the algorithm and turn the math into code, then run the code on a data set to get predictions on new data.
What is linear regression?
The linear regression model consists of one equation of linearly increasing variables (also called parameters or features) along with a coefficient estimation algorithm called least squares, which attempts to determine the best possible coefficient given a variable.
Linear regression models are known to be simple and easy to implement because there is no advanced mathematical knowledge that is needed, except for a bit of linear Algebra. For this reason, many people choose to use a linear regression model as a baseline model to compare if another model can outperform such a simple model.
Multiple linear regression
Multiple linear regression is a model that can capture the linear relationship between multiple variables and features, assuming that there is one. The general formula for the multiple linear regression model looks like the following image.
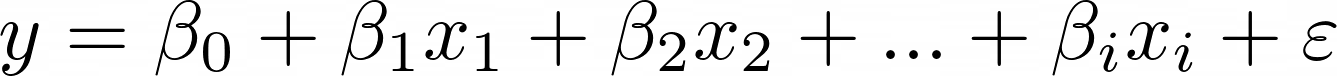
- β0 is known as the intercept.
- β0 to βi are known as coefficients.
- x1 to xi are the features of the data set.
- ε are the residual terms.
You can also represent the formula for linear regression in vector notation. When representing the formula in vector notation, you have the advantage of using some operations from linear Algebra, which in turn makes it easier to code.
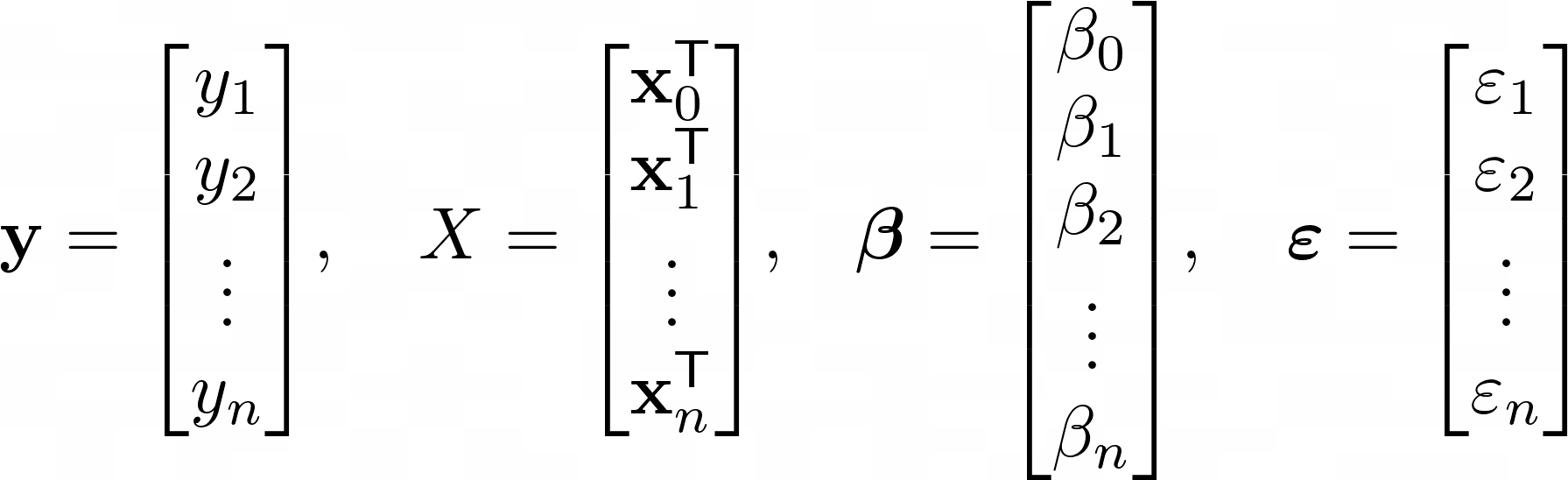
Note that the x0T vector contains just a series of 1s: [1, 1, ..., 1]. This turns the equation into something much more compact, where all of the terms are now represented as matrices. The following equation shows that you can compute the output value for all y, given that you have an estimation of the coefficients β.
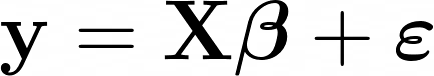
But, how exactly can you estimate the coefficient values?
Ordinary least squares
Linear least squares (LLS) is the main algorithm for estimating coefficients of the formula just shown. In machine learning language, this is known as fitting your model to the data set. I focus on the most popular variant called ordinary least squares (OLS).
The OLS algorithm minimizes the sum of squares of residuals.
One residual is the distance from one data point to the line in 2D or plane in 3D, so when I minimize the total sum of the squared residuals, I am minimizing the average distance from a data point to the line I am fitting to.
The formula for the algorithm can be quite intimidating if you are not familiar with linear Algebra: permuted matrices, dimensionality, dot product, and the inverse of a matrix. This is not a topic for this article, but you can read the full derivation of the formula by Arthur S. Goldberger, also called the normal equation, if you want to be more knowledgeable on those topics.
The following formula ensures that the resulting coefficients define a minimum for the normal equation, which means that the result is the minimized total sum of squared residuals.
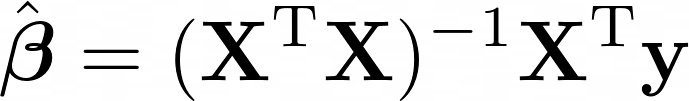
The formula can be coded in one line of code because it's just a few operations. You'll see this later in the coding section.
The outcome of the algorithm, beta β with a hat (^) on top, is a vector containing all of the coefficients that can be used to make predictions by using the formula presented in the beginning for multiple linear regression. To give an example in 3D, you might have this set of coefficients [2.1, 5.3, 9.2], which can be plugged into the equation for multiple linear regression.

This means that the intercept is at 2.1, while there are two variables that have their estimated coefficients as 5.3 and 9.2. To estimate an output variable y, you must put two variables x1 and x2 into the equation, and then you have made a prediction.
The coding section shows more examples for this, though there is one important thing missing. Assuming that you have a number of predictions for some observed data, how can you measure how well the model predicted the ground truth?
R squared: Accuracy of the multiple linear regression model
You can measure the accuracy of how well the multiple linear regression model performs by using a metric called r squared.
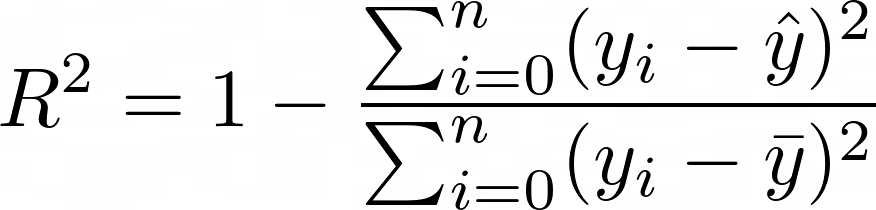
- yi is one value of y at index i.
- ŷ is pronounced as y hat and is the predicted values of y.
- y̅ is pronounced as y bar and is the average of y.
The metric measures the relationship between the residual sum of squares (RSS) and the total sum of squares (TSS). The RSS is computed as the ground truth minus the predicted ground truth, while the TSS is computed as the ground truth minus the average of the ground truth.
Code for multiple linear regression
I made a single class called MultipleLinearRegression in a multiple_linear_regression.py file that represents all of what I have talked about until this point.
import numpy as np
import copy
class MultipleLinearRegression():
def __init__(self):
self.coefficients = None
self.intercept = None
def fit(self, x, y):
# prepare x and y values for coefficient estimates
x = self._transform_x(x)
y = self._transform_y(y)
betas = self._estimate_coefficients(x, y)
# intercept becomes a vector of ones
self.intercept = betas[0]
# coefficients becomes the rest of the betas
self.coefficients = betas[1:]
def predict(self, x):
'''
y = b_0 + b_1*x + ... + b_i*x_i
'''
predictions = []
for index, row in x.iterrows():
values = row.values
pred = np.multiply(values, self.coefficients)
pred = sum(pred)
pred += self.intercept
predictions.append(pred)
return predictions
def r2_score(self, y_true, y_pred):
'''
r2 = 1 - (rss/tss)
rss = sum_{i=0}^{n} (y_i - y_hat)^2
tss = sum_{i=0}^{n} (y_i - y_bar)^2
'''
y_values = y_true.values
y_average = np.average(y_values)
residual_sum_of_squares = 0
total_sum_of_squares = 0
for i in range(len(y_values)):
residual_sum_of_squares += (y_values[i] - y_pred[i])**2
total_sum_of_squares += (y_values[i] - y_average)**2
return 1 - (residual_sum_of_squares/total_sum_of_squares)
def _transform_x(self, x):
x = copy.deepcopy(x)
x.insert(0, 'ones', np.ones( (x.shape[0], 1) ))
return x.values
def _transform_y(self, y):
y = copy.deepcopy(y)
return y.values
def _estimate_coefficients(self, x, y):
'''
β = (X^T X)^-1 X^T y
Estimates both the intercept and all coefficients.
'''
xT = x.transpose()
inversed = np.linalg.inv( xT.dot(x) )
coefficients = inversed.dot( xT ).dot(y)
return coefficients
I needed a data set to put the new multiple linear regression algorithm to use, so I loaded in a data set called Boston Housing Prices from scikit-learn. I split the data set into inputs x and outputs y, and I further split x and y into data that I train on and data that I test on. This is in a load_dataset.py file.
from sklearn.datasets import load_boston
import pandas as pd
from sklearn.model_selection import train_test_split
def sklearn_to_df(data_loader):
X_data = data_loader.data
X_columns = data_loader.feature_names
X = pd.DataFrame(X_data, columns=X_columns)
y_data = data_loader.target
y = pd.Series(y_data, name='target')
return x, y
x, y = sklearn_to_df(load_boston())
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=42)
The following code is the start of the main.py file for running the multiple linear regression. The code shows the following steps.
- Load all dependencies and data.
- Initialize the
MultipleLinearRegression()class as an object. - Fit the object to the data by
mlr.fit(x_train, y_train). - Make predictions on a test set that is unseen to the algorithm by
mlr.predict(x_test). - Compute the r squared score by
mlr.r2_score(y_test, pred).
from load_dataset import x_train, x_test, y_train, y_test
from multiple_linear_regression import MultipleLinearRegression
from sklearn.linear_model import LinearRegression
# # # # # # # # # # # # # # # # #
# Our Multiple Linear Regression #
# # # # # # # # # # # # # # # # #
mlr = MultipleLinearRegression()
# fit our LR to our data
mlr.fit(x_train, y_train)
# make predictions and score
pred = mlr.predict(x_test)
# calculate r2_score
score = mlr.r2_score(y_test, pred)
print(f'Our Final R^2 score: {score}')
The following code shows what the output score turns out to be.
Our Final R^2 score: 0.6687594935355938
Although I did just implement multiple linear regression, let's compare how well the implementation works in comparison to scikit-learn's linear regression.
# # # # # # # # # # # # # # # # # #
# Scikit-Learn's Linear Regression #
# # # # # # # # # # # # # # # # # #
sk_mlr = LinearRegression()
# fit scikit-learn's LR to our data
sk_mlr.fit(x_train, y_train)
# predicts and scores
sk_score = sk_mlr.score(x_test, y_test)
print(f'Scikit-Learn\'s Final R^2 score: {sk_score}')
The output from their model to mine is almost identical, except after the 13th decimal.
Scikit-Learn's Final R^2 score: 0.6687594935356329
Special case 1: Simple linear regression
Simple linear regression can be expressed in one simple equation.
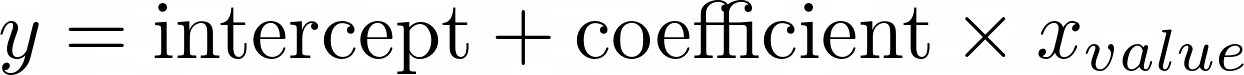
The intercept is often known as beta zero (β0) and the coefficient as beta 1 (β1). The equation is equal to the equation for a straight line
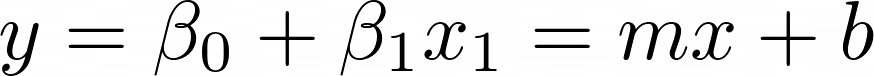
That is all there is to a simple linear regression equation. However, how do you determine the intercept and coefficient? This is where I introduce the least squares algorithm.
Ordinary least squares
Ordinary least squares is known to minimize the sum of squared residuals (SSR). There are two central parts to ordinary least squares in this special case: estimating the coefficients and estimating the intercept.
Estimating the coefficient
You can estimate the coefficient (the slope) by finding the covariance between x and y and dividing it by the variance of x. Note that this is a special case of linear regression, derived using calculus from the formula as seen in the multiple linear regression section earlier in this article.
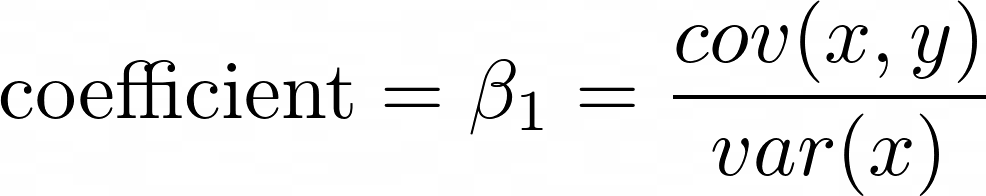
This turns into something slightly more complex. Any time that you have a summation symbol Σ, the equivalent in programming is summing the elements of an array. I start by adding the first element to the sum, where index i=0, and I go all the way to the length of the array n. The covariance and variance can be expanded to the following formula.
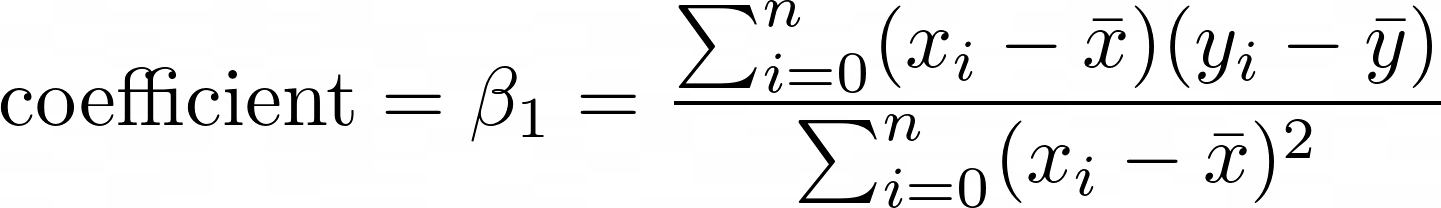
- xi is one value of x at index i.
- yi is one value of y at index i.
- x̅ is pronounced as x bar and is the average of x.
- y̅ is pronounced as y bar and is the average of y.
Estimating the intercept
The estimate of the intercept β0 should be easier to understand than the estimate of the coefficient β1.
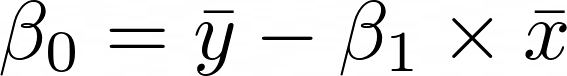
- x̅ is pronounced as x bar and is the average of x.
- y̅ is pronounced as y bar and is the average of y.
- β1 is the coefficient that I estimated from earlier.
Code for simple linear regression
I made a single class called SimpleLinearRegression in a simple_linear_regression.py file that implements the special case of simple linear regression.
import numpy as np
class SimpleLinearRegression():
def __init__(self):
self.coefficient = None
self.intercept = None
def fit(self, x, y):
'''
Given a dataset with 1 input feature x and output feature y,
estimates the coefficient and compute the intercept.
'''
self.coefficient = self._coefficient_estimate(x, y)
self.intercept = self._compute_intercept(x, y)
def predict(self, x):
'''
y = b_0 + b_1*x
'''
x_times_coeff = np.multiply(x, self.coefficient)
return np.add(x_times_coeff, self.intercept)
def r2_score(self, y_true, y_pred):
'''
r2 = 1 - (rss/tss)
rss = sum_{i=0}^{n} (y_i - y_hat)^2
tss = sum_{i=0}^{n} (y_i - y_bar)^2
'''
y_average = np.average(y_true)
residual_sum_of_squares = 0
total_sum_of_squares = 0
for i in range(len(y_true)):
residual_sum_of_squares += (y_true[i] - y_pred[i])**2
total_sum_of_squares += (y_true[i] - y_average)**2
return 1 - (residual_sum_of_squares/total_sum_of_squares)
def _compute_intercept(self, x, y):
'''
intercept = y_bar - coefficient*x_bar
WHERE: y_bar = average(y),
x_bar = average(x),
coefficient = coefficient already estimated
'''
# find the average of the array x
x_average = np.average(x)
# multiply the coefficient and the average of the x values
mul = self.coefficient*x_average
return np.average(y) - mul
def _coefficient_estimate(self, x, y):
'''
coefficient_{x,y} = ∑_{i=0}^{n} (x_i - x_bar) * (y_i - y_bar)
_________________________________________
∑_{i=0}^{n} (x_i - x_bar)^2
'''
numerator = 0
denominator = 0
for i in range(len(x)):
x_value = x[i]
y_value = y[i]
x_average = np.average(x)
y_average = np.average(y)
numerator += (x_value - x_average) * (y_value - y_average)
denominator += (x_value - x_average)**2
return numerator / denominator
As shown in the Code For Multiple Linear Regression section, I load a data set from scikit-learn.
The following code is my main.py file that loads the data set, picks one feature, and runs the simple linear regression model. After experimentation, I found that the feature called LSTAT performed the best in terms of the r2 score.
from load_dataset import x_train, x_test, y_train, y_test
from simple_linear_regression import SimpleLinearRegression
# pick a single feature to estimate y
x_train = x_train['LSTAT'].values
x_test = x_test['LSTAT'].values
y_train = y_train.values
y_test = y_test.values
# fit to data
slr = SimpleLinearRegression()
slr.fit(x_train, y_train)
# make predictions and score
pred = slr.predict(x_test)
score = slr.r2_score(y_test, pred)
print(f'Final R^2 score: {score}')
I did conveniently pick the feature that gave me the highest r squared score, but compared to the multiple linear regression, the model is not that far off.
Final R^2 score: 0.5429180422970383
Special case 2: Polynomial regression
Another case of multiple linear regression is polynomial regression, which might look like the following formula.
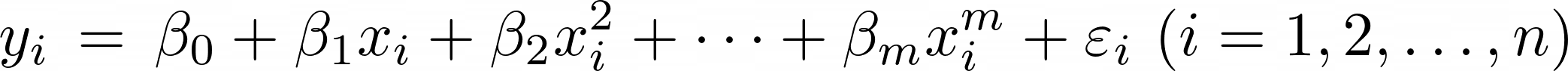
The formula is flexible in the exponents so that it can be changed to model specific problems better. The code for polynomial regression is the same as for multiple linear regression, except for the predict function. I increase the degree of the exponent by one for each feature, and use those as the values instead.
def predict_polynomial(self, x):
'''
y = β0 + β1*x + β2*x^2 + ... + βm*x_i^m
'''
predictions = []
for index, row in x.iterrows():
# treating each feature as a variable that needs to be raised to the power of m
polynomial_values = [feature**i+1 for i, feature in enumerate(row.values)]
pred = np.multiply(polynomial_values, self.coefficients)
pred = sum(pred)
pred += self.intercept
predictions.append(pred)
return predictions
One of the drawbacks of polynomial regression is that you must determine which formula might work for you, and that gets quite hard as the number of variables grows because we don't really have much intuition for what a 4-, 7-, or 100-dimensional space looks like.
Perhaps a naive solution to the problem is finding the best polynomial by brute force; trying all different permutations that you can think of, for example, with a varying degree from 1 - 5.
Conclusion
In this article, you learned about linear regression and why it's known for being a simple algorithm and a good baseline to compare more complex models to. You explored the algorithm and turned the math into code, then ran the code on a data set to get predictions on new data.