Article
Monitoring containerized environments with osquery
Tracking container active process and network activityArchive date: 2023-02-28
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Containers have become more prolific due to their mobility and storage efficiency. Many solutions exist for monitoring traditional systems, but there is not one in place for monitoring containerized environments.
My team, referred to as the "KuberNets," set out to use osquery to widen visibility into containers. We are a group of interns who were tasked with researching available solutions that would enhance visibility into containerized environments. The ultimate goal was to enhance container monitoring capabilities for a security team, providing a solution that would ready for deployment at our departure.
To our knowledge, there was no existing container monitoring solution that satisfied our needs for detecting threats. Some basic monitoring examples include knowing when a process is active, if a file gets deleted, and what network connections are communicating with a container. Most important is knowing which container the activity originated from. Surprisingly, despite both the widespread adoption of Kubernetes and the presence of a large open-source cloud deployment community, there isn't a solution out there that entirely addresses this issue. What is really going on in containers?
Read on if you are a like-minded security individual seeking to improve your Kubernetes monitoring setup. Osquery is not the end all solution for container monitoring, but it is a step forward as we can now view container processes and network activity.
This article is based on work done by the KuberNets, a team of IBM interns who collaborated on the project. Team members were John Do, Zane Doleh, Tabor Kvasnicka, and Joshua Stuifbergen.
Prerequisites
To get the most out of this article, knowledge of Kubernetes, Docker, containers, SQL, Linux, and osquery is ideal.
Estimated time
Take about 10 minutes to read this article.
Containers, Docker, Kubernetes, containerd, and the Proc Pseudo Filesystem
Containers, Docker, Kubernetes, containerd, and the Linux Proc Psuedo Filesystem are the main components of our project. With a basic understanding of their architecture, we were able to properly evaluate osquery. You can skip these sections if you are already familiar with the components mentioned.
Containers
Containers are a standard unit of software. They allow for the separation between application and infrastructure and fully embrace the "deploy anywhere" methodology.
Applications and their dependencies are packaged together into images at build time. These images contain everything required to deploy the application, so they can be deployed on any operating system or hardware. They are deployed to containers at run time, and the engine used to deploy the container configures firewalls and the networking required for users to access the application.
This architecture allows developers to focus more on their application and less on deployment details.
Docker
Docker is an organization that provides enterprise-level containers. The Docker engine is the heart of the solution and allows developers to build, control, and secure applications.
Docker ships with industry-leading container tools, including containerd, a powerful command-line interface, an integrated BuildKit, and other useful features.
For my team's project to track active process and network activity, we primarily used Docker for building images with the BuildKit, which reads Dockerfiles and speeds up building images.
Kubernetes
Kubernetes is an open-source platform, originally developed by Google, for managing workloads and services on pods. Pods are the smallest units of software in Kubernetes, and they consist of one or more containers. Kubernetes orchestrates networking and storage infrastructure to help the workload. The platform is a central management environment for containers that builds an ecosystem of components and tools to deploy, scale, and manage applications.
While this architecture is convenient, it comes with a cost. If attackers gain control over Kubernetes, they have control over the containers within. They can delete or change existing pods, create new pods with malicious intent, or perform essentially any malicious action.
Our project does not focus on securing these systems. However, visibility into these systems can help in identifying potential threats, so they can be mitigated.
Containerd
Containerd is the current industry standard for container runtimes. This Cloud Native Computing Foundation project is used by both Docker and Kubernetes.
Responsible for managing the containers, containerd exposes an API for this work. It is not designed to use with a command-line interface. Kubernetes previously used Docker by default for managing containers. However, because Docker uses containerd under the hood, Kubernetes now uses containerd directly by default.
Proc Psuedo Filesystem
Linux and other Unix-based operating systems embrace the "everything is a file" methodology. This approach is important because any information about a system can be found in a file on the system. It's useful when searching for information about processes running on a system. All of this information can be found in the proc pseudo filesystem, or procfs, usually mounted at /proc.
You can find a variety of information under the procfs, including the CPU info, the memory info, and process statistics. It also contains information about all the processes running on the system. Each folder in this directory contains a process ID where you can get more specific information about that process, such as the process name, the path to the executable, and the user and group IDs. These folders contain network information for these processes. Thus, access to this filesystem is essential when monitoring Linux-based systems.
An introduction to osquery
Osquery is a system monitoring solution developed by Facebook that was open sourced in 2014. It structures the operating system into a relational database that can be queried with SQL. Osquery is available on Mac OS X, Windows, and on many popular Linux distributions.
Changing how you search for information, osquery makes your operating system monitoring routine easier. Querying tables prepackaged with osquery make it easier to check on the performance and state of your machine, such viewing running process or hardware events. Queries run from the osquery container provide information on running process and network traffic of the other containers on the node. This information offers insight into irregular processes or unusual connections.
The following sections show how our team arrived at a working osquery container monitoring solution. But first, get familiar with how osquery works under the hood.
The architecture of osquery
As shown in the following diagram, osquery has two types of tables: virtual tables and event tables.
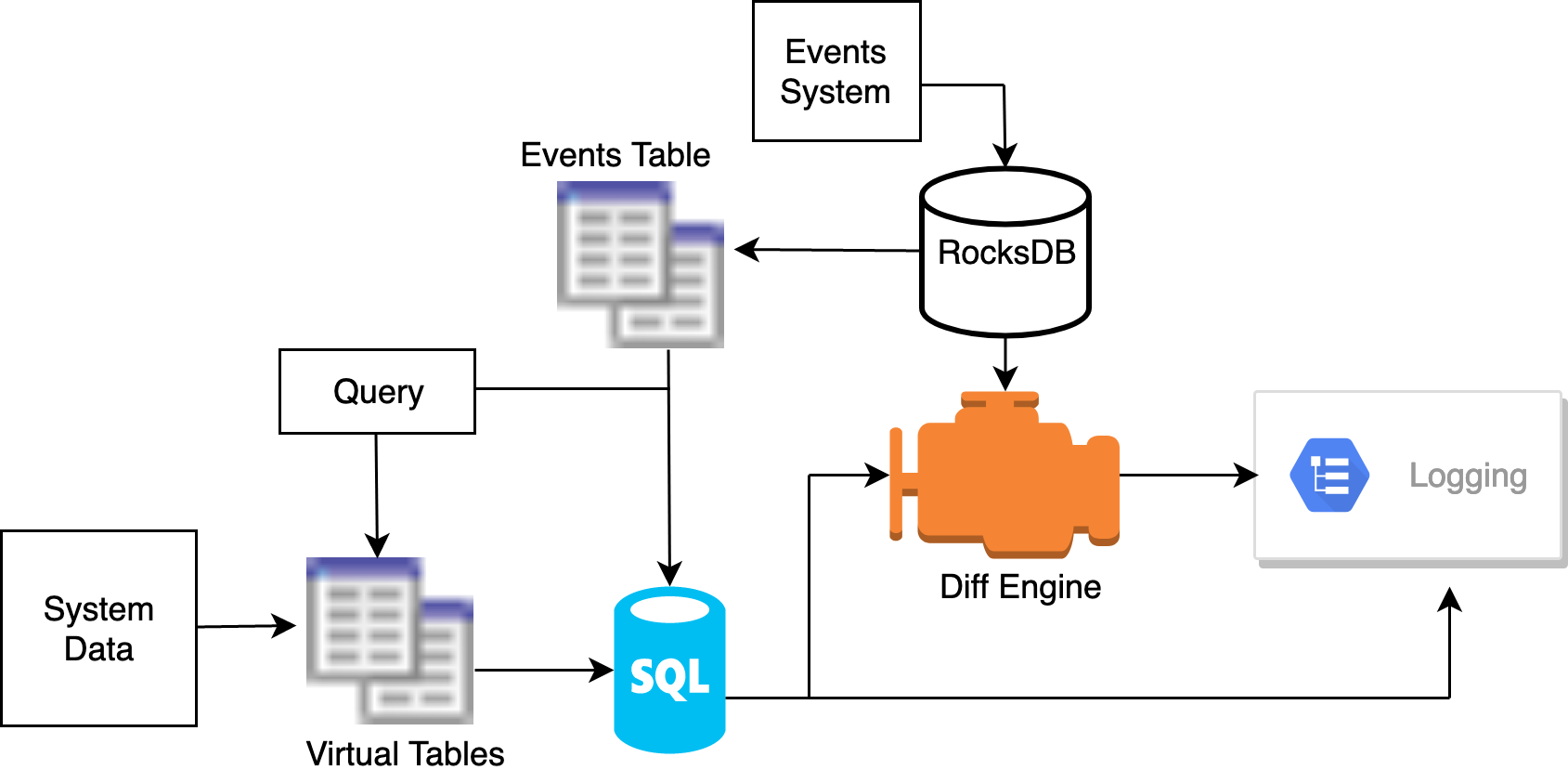
Virtual tables are generated when queries are made. These tables are formed based on syscalls, OS APIs, and config files. Not all types of data work under this paradigm. For example, monitoring the entire filesystem would be infeasible. Generating tables each time the query is run would incur too much overhead. Instead, osquery can use the events system to store data and retrieve the information requested based on existing tables.
The events system records data as events occur, and it stores them in the RocksDB instance. When a query is made to one of the events tables, the virtual tables are generated from the RocksDB data rather than from the data collected from the system at query time. This approach allows for more intensive monitoring -- and for near real-time monitoring. The process_events table uses the Linux Audit System to receive these events from the kernel and records them in RocksDB. When a query is made to process_events, the tables are generated from this data.
After the tables are generated, they are processed by the SQLite Engine, allowing for the usual features of a relational database. There are some optimizations in place for collecting data. In some queries of a table using a WHERE SQL clause, osquery handle some of the filtering so that it does not collect unneeded data. This approach is more efficient than collecting all of the data and the SQLite engine discarding most of it.
Our implementation
You can run osquery in two different modes: as an interactive shell (osqueryi) and as a daemon (osqueryd). The terms osquery daemon and osqueryd are used interchangeably. The interactive shell allows for manually querying the system. This shell is useful for testing queries or gathering quick information on a system. However, for the purposes of our project, we used the osquery daemon. You can configure it to run queries periodically. We did this by adding new queries to the configuration file.
You can configure osquery to log the differences in query results rather than the entire query results. The results are fed into the diff engine, which compares the current query results to the previous results and determines what rows are added or removed. These differences (instead of the entire results) are then output. This approach gives better scalability when you are dealing with many systems forwarding data. In our project, we used osqueryd, which uses the diff engine by default.
Our primary challenge with osquery is that we wanted to use it in a way that it was not built for. It can only monitor its host system. Ideally, we should deploy osquery as a DaemonSet that can monitor all containers on each node. But, in order for this deployment to work, we needed osquery to see outside of the container.
An additional blocker came from the Kubernetes environment we were using. Osquery has built-in tables for viewing Docker, but Kubernetes does not use Docker by default anymore. Instead, it abstracted away Docker and now uses containerd as the container runtime environment. We used the IBM Cloud Kubernetes service deployment for our evaluation of osquery, which also adopted containerd.
We did the necessary research and found out how to extend osquery for more visibility. Because the nodes' host operating systems are Linux-based, they have the Proc Pseudo Filesystem. Additionally, studying the osquery source code reveals that they are simply enumerating /proc to collect process information. We used this information -- combined with the fact that all containers are simply containerd-shim processes that enumerate the host's procfs.
We were able to get the information about the container processes that are on the current node. We mounted the proc pseudo filesystem of the node onto the container where osquery was deployed as /host/proc (as shown in the previous image). We then wrote an osquery extension in Go to read /host/proc and return the node's process information in a new host_processes table, effectively replicating the processes table. We built our extension using the osquery-go repository (made by Kolide) as a template.
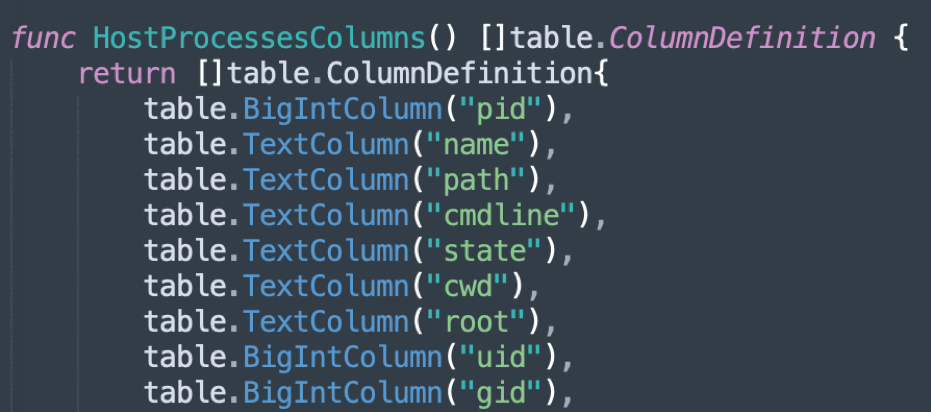
The following code shows the new host_processes table pulling data from /host/proc.

The host_processes table mimics that information taken from the processes table. The following screen capture is an example of some of the information retrieved.
We could see the processes, so then the next step was to monitor network activity.
Because this information is also in the procfs, it should be trivial to add an additional table for this information. However, the library we used for the extension did not natively support enumerating network information. This situation led us to the idea of replacing all of the instances of /proc with /host/proc in the osquery code base and building from source. This change gave us the results we were seeking.
Another issue arose: After processes were visible to osquery, the container processes were seen, but there was no way to see which containers they belonged to. Therefore, in addition to monitoring the processes, we extended osquery to see pod and container information using the Kubernetes API. Then we could match the container ID provided by the processes to a container name by matching the information between two separate queries.
The following code sample shows the information that the kubernetes_pods table populates from the Kubernetes API:
func KubernetesPodsColumns() []table.ColumnDefinition {
return []table.ColumnDefinition{
table.TextColumn("uid"),
table.TextColumn("name"),
table.TextColumn("namespace"),
table.IntegerColumn("priority"),
table.TextColumn("node"),
table.TextColumn("start_time"),
table.TextColumn("labels"),
table.TextColumn("annotations"),
table.TextColumn("status"),
table.TextColumn("ip"),
table.TextColumn("controlled_by"),
table.TextColumn("owner_uid"),
table.TextColumn("qos_class"),
}
}
The following code sample shows the information that the kubernetes_containers table populates from the Kubernetes API:
func KubernetesContainersColumns() []table.ColumnDefinition {
return []table.ColumnDefinition{
table.TextColumn("id"),
table.TextColumn("name"),
table.TextColumn("pod_uid"),
table.TextColumn("pod_name"),
table.TextColumn("namespace"),
table.TextColumn("image"),
table.TextColumn("image_id"),
table.TextColumn("state"),
table.IntegerColumn("ready"),
table.TextColumn("started_at"),
// table.TextColumn("env_variables"),
}
}
Our next goal was to create a query that combines this information and can be viewed in one log. We are still working on this goal.
A note on the Dockerfile and extension configuration: We followed the osquery-go repository documentation to autoload the extension with osqueryd. We made an extension.load file with the path to the extension and renamed the extension to include .ext. The Dockerfile instructions placed the configuration file, extension autoload file, the osqueryd binary, and the custom extension into the default directories that osqueryd looks for when starting up, as shown in the following screen capture. The extension and osqueryd required execution privileges to run without error.
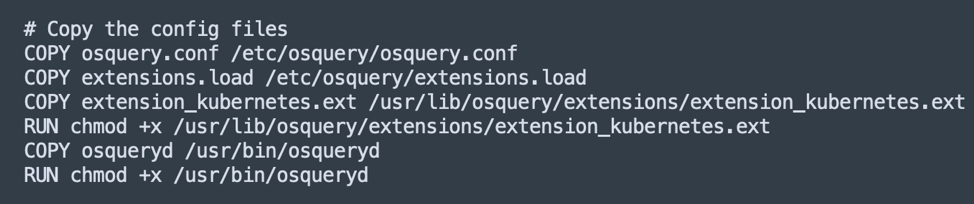
Two flags in the configuration file were necessary to load the extension. We included a flag to enable extensions and a flag to identify where the autoload extension is located (as shown in the following screen capture). There are many other important flags described in the osquery documentation.

You can configure osquery to output logs in a variety of ways, whether to files or to an end point. We configured osquery to output to files, by installing a Filebeat module and then forwarding the data to Elasticsearch so we could view the logs in Kibana.
Demonstration
Any unusual network connection, or unknown process would be deemed suspicious on a deployed container. This section shows how osquery catches the actions of an attacker running a Netcat backdoor shell. This example merely demonstrates that osquery detects the processes and network activity from another container on the same node.
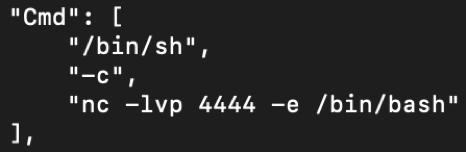
As you may recognize in the following screen capture, the command initiates a Netcat listener. When deployed, this soon-to-be container becomes the target. The number 4444 indicates the local port it listens on. When attackers connect, they enter a bash shell session.
You begin by deploying a Netcat application, nc-app with the following command:
kubectl create deployment nc-app --image=<docker_image>

To check to see that the pod is running, use the following command:
kubectl get pods

You expose the Netcat service so that a connection from outside the cluster can reach the container, and you open up port 4444, with the following command:
kubectl expose deployment nc-app --type=LoadBalancer --name=nc-service --port 4444
An external IP also is created.

To verify the service is active, you use the following command:
kubectl get services nc-service
From an external environment, you run the following Netcat client command using the external IP of the service:
nc 46.102.66.23 4444
You can see the output from the query, host_processes_query:

It sees the nc-app container's command line /bin/sh -c nc -lvp 4444 -e /bin/bash and the name of the processes sh. This information came from the custom host_processes table that read from the osquery container. The significance of this information is that one container can now report on another containers actions.
Here is the output from the kubernetes_container query:

This information includes the name, pod name, namespace, image, state, and when is what started.
And here is the output from the kubernetes_pod query:

This information includes the UID, name, namespace, node, status, start time, and pod IP.
Notice that the following IP 172.30.71.203 matches the pod IP from the kubernetes_pod log:

Summary
We had a goal to get more visibility into containers. Osquery is usually deployed on a host system, and this deployment creates a restriction on what you can see within containers. With our changes we can now see network activity that is useful for detecting anomalous connections from one infected container to another. We can also see active processes and the containers they came from.
Have our osquery modifications helped us find out what's really going on in containers? Yes, but not completely.
We expanded our visibility into containers but there is more to do. An important feature of osquery is the events system, but these tables use the Linux Audit System, which depends on having direct access to the system. Thus, we were not able to use the events system to allow near real-time monitoring. To monitor a Linux system in the same way as the Linux Audit System but from the outside, we would need a new system developed, if it does not yet exist. Then osquery could be extended to use that system.
If you found osquery enticing, try it on your own and further explore the capabilities. If you are unfamiliar with osquery, I recommend installing it to determine if it's useful for monitoring your cloud environment. There is an active slack community, osquery.slack.com. You might also want to look into Uptycs, a company applying proprietary enhancements to osquery.
There are many other container monitoring solutions available, and you might want to consider a hybrid approach for setting up your monitoring. Like we saw with osquery, even though it was not built to monitor containers with Docker abstracted away, we found a way to work around this design. Our example can likely be replicated elsewhere with traditional monitoring solutions.