Article
Stack machine learning models: Get better results
Using your own models, learn how to apply stacking to your own data setsSometimes you discover small tips and tricks to improve your code and make things easier for yourself, such as better maintainability and efficiency. This article gives you an overview of a trick that I use to improve and get better results with my machine learning models, although it takes a little extra thought to implement. My goal is to introduce you to stacking in machine learning. Using your own models, you learn how to apply stacking to your own data sets.
To work through this article, you should be familiar with overfitting, underfitting, and cross-validation.
What is model stacking?
Stacking is the process of using different machine learning models one after another, where you add the predictions from each model to make a new feature.
There are generally two different variants for stacking, variant A and B. For this article, I focus on variant A as it seems to get better results than variant B because models more easily overfit to training data in variant B. This is likely also the reason why many practitioners use variant A, although it does not eliminate overfitting.
Note that there is no correct way of implementing model stacking (David H. Wolpert) because model stacking describes only the process of combining many models with a final generalized model. Variant A has proven to work well in practice, which is why I chose to use it.
The model stacking process
Model stacking should always be accompanied by cross validation to reduce overfitting models to training data. This is common practice.
Model stacking seems like a simple technique to improve your results when you understand what happens inside the algorithm. However, there are many components interacting and keeping track of all of them can be challenging, especially when first learning this concept. For you to fully understand the algorithm, I created a step-by-step image and description.
To start, when performing model stacking with cross-validation, we require three parameters: a Training data set, a Holdout data set (validation data set), and a list of models called models_to_train.
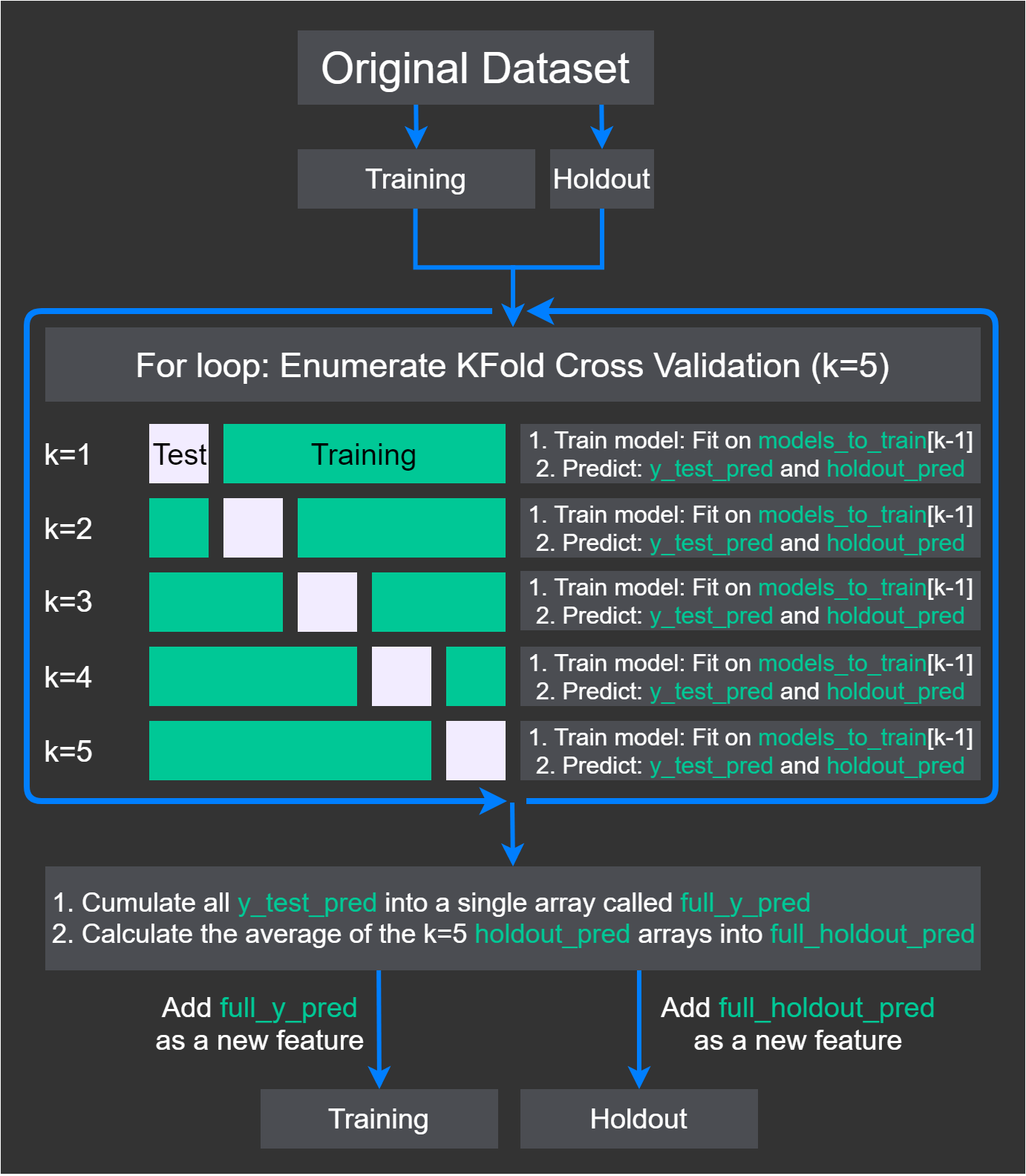
Figure 1. Model stacking diagram
The most essential part here is that each model's predictions becomes a slice of a new feature, such that each model gets to predict a slice of the training data for this new feature.
Now, let's put Figure 1 into text to explain what goes on. Later on, you'll see a real example in Python.
- Gather models with optimized hyperparameters into a
models_to_trainarray. - Split the original data set into a Training and Holdout data set.
- Let
Traininggo onward into the upcoming loop, and saveHoldoutuntil the last part in the upcoming loop. - Make a
forloop with KFold Cross-Validation where k=5.- In each iteration, split the
Trainingdata set into another training and testing data set. Call themX_train,y_train,X_test, andy_test. The white parts in Figure 1 representX_testandy_test, while the green parts representX_trainandy_train. - Set the current model equal to
models_to_train[k-1]. - Train the current model on
X_trainandy_train. - Make predictions on the test data set
X_testand call themy_test_pred. Extend an arrayfull_y_predwith the predictionsy_test_pred. - Make predictions on the Holdout data set
Holdoutand call themholdout_pred. - Add
full_y_predas a new feature in Training and addfull_holdout_predas a new feature in Holdout for use in the next layer.
- In each iteration, split the
- Average the
holdout_predarrays into afull_holdout_predarray. - Add
full_y_predas a new feature inTrainingand addfull_holdout_predas a new feature inHoldout. - Return the data sets
TrainingandHoldoutwith the new features for use in the next layer.
Notice that we use one model to predict each part of the total training data set. We predict one fold at a time, with a different model each time.
Now that we have some stacked machine learning models, how can we use them? The next steps takes the new Training and Holdout data sets and uses them as input in the next layer.
Introducing layers of model stacks
Stacking machine learning models is done in layers, and there can be many arbitrary layers, dependent on exactly how many models you have trained along with the best combination of these models. For example, the first layer might be learning some feature that has great predictive power while the next layer might be doing something else such as reducing noise.
We put model stacks in layers, and usually with a different purpose. At the end, we get a final data set that we feed into a last model. The last model is called a meta-learner (for example, meta-regressor or meta-classifier), and its purpose is to generalize all of the features from each layer into the final predictions.
Figure 2 gives an illustration of where each level represents a new layer in our total pipeline when applying model stacking (there is a switch between layer and level, although their meaning is the same). The example only shows two levels, where level 2 is the final model that gives the final predictions (the output).
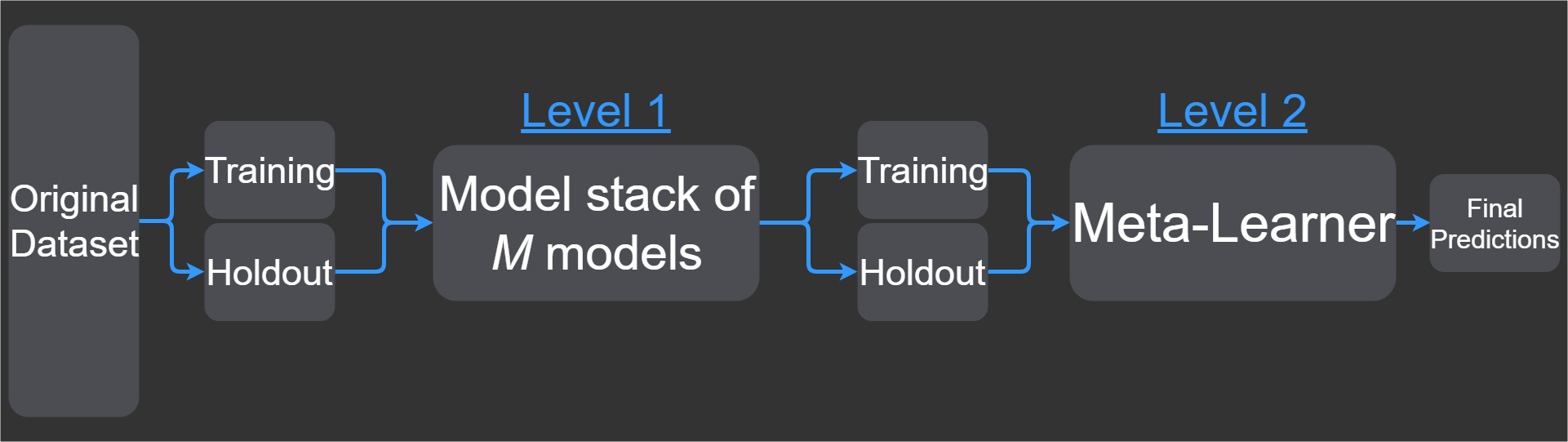
Figure 2. Layers of model stacks (in levels)
If you wanted to add more layers, you could just add another level after level 1 and make the meta-learner level 3. If we were to increase the numbers of layers, level 2 would be another round of model stacking of M models, like level 1. The meta-learner is always present in the last layer, which is why you insert a new level before the meta-learner.
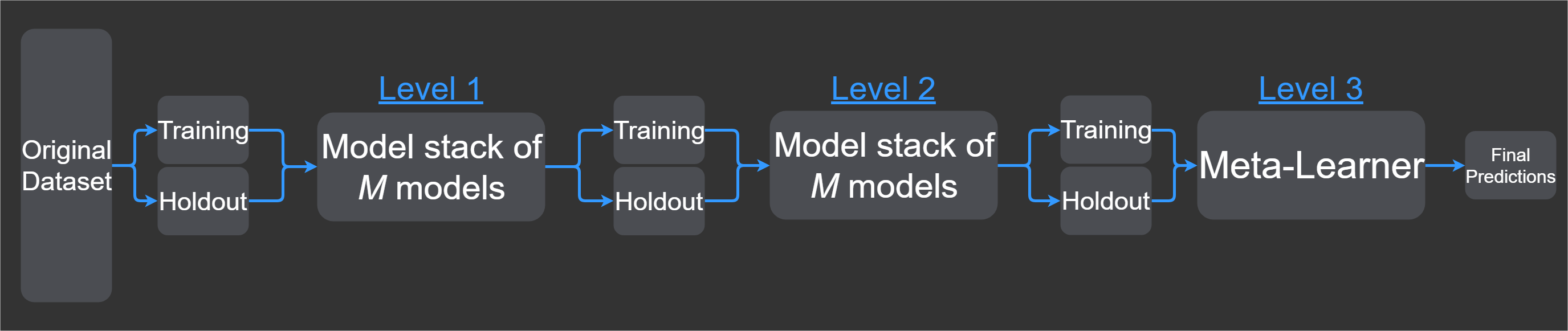
Figure 3. Adding a layer to Figure 2
To summarize, we produce new features by different model stacks, which are combined in a new data set to make final predictions at the end. Sometimes other methods are combined in these model stacks, such as feature selection or normalization, but I do not explore those other methods here.
What is a stack of models?
Quite literally, you define a stack of models for each layer, and you run the first model from the first layer all the way down to the last model in the last layer while making predictions between levels. These stacks of models could be any type of model. For example, you could have a stack with XGBoost, neural networks, and linear regression.
Figure 4 shows how models are stacked in layers even though it is not as specific as the one shown earlier.
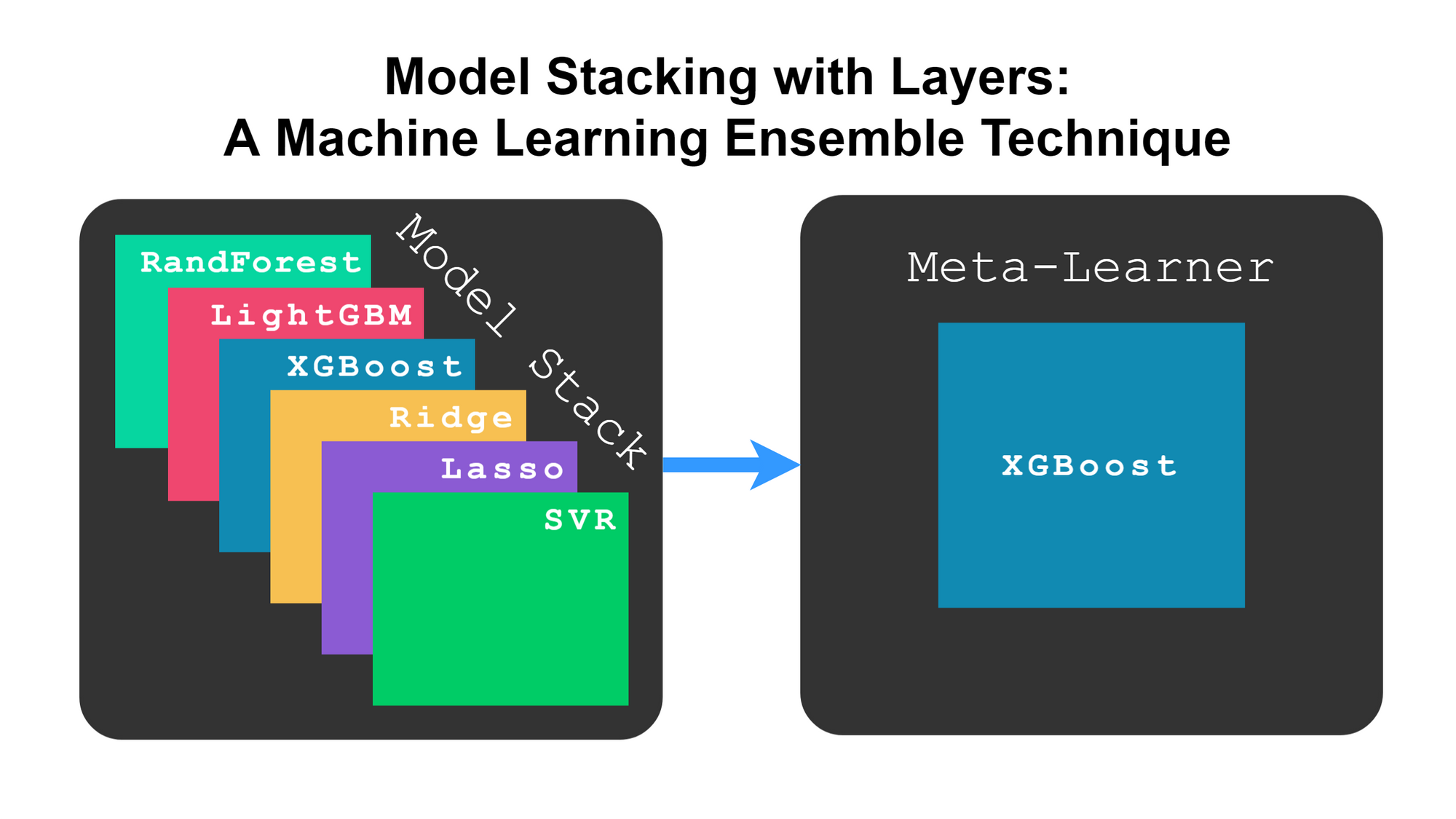
Figure 4. Models stacked in layers
Why should you use stacking?
Throughout this article, I've mentioned better results. Now, let me justify how and why we get better results when using model stacking.
Model stacking is used among competition winners and practitioners, and is simple. Your meta-learner generalizes better than a single model. That is, it makes better predictions on unseen data than just a single model.
A good paper on this topic is Stacked Generalization by David H. Wolpert). Wolpert argues that model stacking deduces the bias in a model on a particular data set so that we later can correct for the bias in a meta-learner.
Before model stacking became popular and more widely used, a technique called Bayes Model Averaging (BMA) existed. In this model, weights were the posterior probabilities of models. However, empirical evidence by Bertrand Clarke has shown that model stacking with cross validation out performs BMA, while being robust because model stacking is less sensitive to changes in a data set.
I think the argument that you should pay most attention to is the first point. Most people use model stacking to get better results. But if you are looking for an explanation of why it works, I recommend reading the paper by Wolpert.
Step by step: Code for stacking in Python
Now for what most developers would consider the fun part. The part where we apply what we just learned from reading about what model stacking is and how exactly it improves the predictive power. You can find the entire code in this GitHub repository.
The first thing to do in a machine learning project is find a data set. For this article, I'm using a toy data set (one that requires no data cleaning or transforming).
Importing and preparing data
Before you can import a data set, you must import some of the basic packages for handling the data sets.
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
import warnings
The next step is loading the data set into Pandas so that you can index and inspect the data set easily. You provide the load_boston function from sklearn and input it into the function as seen in the following code. This returns a dataframe containing all of the features and samples in the Boston Housing data set.
def dataset_to_df(load):
# Load the input data into the dataframe
df = pd.DataFrame(load.data, columns=load.feature_names)
# Add the output data into the dataframe
df['label'] = pd.Series(load.target)
# Return the dataframe
return df
df = dataset_to_df(load_boston())
After loading the data set, we typically want to inspect it and learn what the features mean. This task is omitted here, but the following table provides five samples of data along with the meaning of each feature in the data set. You can also find a description of all of the features.
Inspecting the first five rows in the data set, we can see some values. But, we don't know what they mean yet.
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
1-13 is our input and 14 is the output that we are trying to predict as precisely as possible given an unseen test data set.
- CRIM: Per capita crime rate by town
- ZN: Proportion of residential land zoned for lots over 25,000 square feet
- INDUS: Proportion of non-retail business acres per town
- CHAS: Charles River dummy variable (1 if tract bounds river; 0 otherwise)
- NOX: Nitric oxide concentration (parts per 10 million)
- RM: Average number of rooms per dwelling
- AGE: Proportion of owner-occupied units built prior to 1940
- DIS: Weighted distances to five Boston employment centers
- RAD: Index of accessibility to radial highways
- TAX: Full-value property tax rate per $10,000
- PTRATIO: Pupil-teacher ratio by town
- B: 1000(Bk-0.63)^2 where Bk is the proportion of blacks by town
- LSTAT: % lower status of the population
- MEDV (label): Median value of owner-occupied homes in $1000's
Grid search before stacking
Before we start doing model stacking, we want to optimize the hyperparameters for each algorithm for a baseline comparison. This is commonly done by a searching algorithm. For example, scikit-learn offers grid search and random search algorithms.
If you cannot exceed the baseline predictions from the baseline models, then you should not try model stacking. Sometimes though, model stacking cannot improve results by that much, either because of a low number of samples or the data is not complex enough.
Before we start stacking, we split the data set df into four variables X_train, X_test, y_train, and y_test. Any variable named X is typically our input data, while y is what we want to predict (the output data).
from sklearn.model_selection import train_test_split
# Getting the output variable
y = df['label']
# Getting the input variables
X = df.drop(['label'], axis=1)
# Diving our input and output into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.33,
random_state=42
)
I made a function for doing hyperparameter tuning. This function gives us exactly what we want, the best model, the predictions, and the score of the best model on the test data set. It uses imports from the scikit-learn package (sklearn), which makes it easier to run the grid search algorithm.
As parameters to the function, you can pass in your data, a model, and different hyperparameters for tuning.
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import r2_score
def algorithm_pipeline(X_train_data, X_test_data, y_train_data, y_test_data,
model, param_grid, cv=10, scoring_fit='neg_mean_squared_error',
scoring_test=r2_score, do_probabilities = False):
gs = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=cv,
n_jobs=-1,
scoring=scoring_fit,
verbose=2
)
fitted_model = gs.fit(X_train_data, y_train_data)
best_model = fitted_model.best_estimator_
if do_probabilities:
pred = fitted_model.predict_proba(X_test_data)
else:
pred = fitted_model.predict(X_test_data)
score = scoring_test(y_test_data, pred)
return [best_model, pred, score]
Next, we define the hyperparameters for tuning along with the models. We use random forest, LightGBM, and XGBoost in the following code because they typically perform the best. First, we import and instantiate the classes for the models, then we define some parameters to input into the grid search function.
from sklearn.ensemble import RandomForestRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
# Defining our estimator, the algorithm to optimize
models_to_train = [XGBRegressor(), LGBMRegressor(), RandomForestRegressor()]
# Defining the hyperparameters to optimize
grid_parameters = [
{ # XGBoost
'n_estimators': [400, 700, 1000],
'colsample_bytree': [0.7, 0.8],
'max_depth': [15,20,25],
'reg_alpha': [1.1, 1.2, 1.3],
'reg_lambda': [1.1, 1.2, 1.3],
'subsample': [0.7, 0.8, 0.9]
},
{ # LightGBM
'n_estimators': [400, 700, 1000],
'learning_rate': [0.12],
'colsample_bytree': [0.7, 0.8],
'max_depth': [4],
'num_leaves': [10, 20],
'reg_alpha': [1.1, 1.2],
'reg_lambda': [1.1, 1.2],
'min_split_gain': [0.3, 0.4],
'subsample': [0.8, 0.9],
'subsample_freq': [10, 20]
},
{ # Random Forest
'max_depth':[3, 5, 10, 13],
'n_estimators':[100, 200, 400, 600, 900],
'max_features':[2, 4, 6, 8, 10]
}
]
Now that we have defined all of the models and hyperparameters for tuning, we can simply input our data into the function defined earlier.
models_preds_scores = []
for i, model in enumerate(models_to_train):
params = grid_parameters[i]
result = algorithm_pipeline(X_train, X_test, y_train, y_test,
model, params, cv=5)
models_preds_scores.append(result)
Inspecting the results, we can run the following code to see which models performed the best.
for result in models_preds_scores:
print('Model: {0}, Score: {1}'.format(type(result[0]).__name__, result[2]))
As we can see from the results, XGBoost clearly outperformed the two other algorithms. Therefore, we will use XGBoost as the meta-learner.
Model: XGBRegressor, Score: 0.8954
Model: LGBMRegressor, Score: 0.8679
Model: RandomForestRegressor, Score: 0.8697
We have a score to beat, the XGBRegressor score of 0.8954. The point of stacking is that we can improve results. Let me show you how to make that happen.
Stacking models
After doing some research on existing packages, I found pystacknet and mlxtend. For this article, I used mlxtend because it integrates nicely with scikit-learn, which defines a great API that XGBoost, LightGBM, and other packages follow.
We start with importing the classes from the packages that we need to run this code. We assume no hyperparameters for the stacking. This means that we use the predefined hyperparameters for each model.
from mlxtend.regressor import StackingCVRegressor
from sklearn.linear_model import Ridge, Lasso
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
xgb = XGBRegressor()
lgbm = LGBMRegressor()
rf = RandomForestRegressor()
ridge = Ridge()
lasso = Lasso()
svr = SVR(kernel='linear')
Now that we have defined all of our models, we can begin improving our results by stacking some models. As we can see here, we defined two levels, where the first level has 6 models and the second level has the meta-learner.
Note: XGBoost/mlxtend has a bug when trying to mix the packages. That's why we edit the names of the columns of the X_test to f0, f1, and so on. XGBoost internally renames the features of X_train, and if we don't provide the exact same names, it will not run. We also use shuffle=False and random_state=42 for the sake of reproducing the same results displayed in this article.
stack = StackingCVRegressor(regressors=(ridge, lasso, svr, rf, lgbm, xgb),
meta_regressor=xgb, cv=12,
use_features_in_secondary=True,
store_train_meta_features=True,
shuffle=False,
random_state=42)
stack.fit(X_train, y_train)
X_test.columns = ['f0', 'f1', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f8', 'f9', 'f10', 'f11', 'f12']
pred = stack.predict(X_test)
score = r2_score(y_test, pred)
Finally, after solving some small tasks throughout the code, we get to a result.
0.9071
Approximately, 0.01 better in the r2 score, which makes sense. The data set used here is highly linear, which means it's hard to capture any patterns that the baseline algorithms couldn't capture already. But it still demonstrates the effect of stacking, which is better results, even on highly linear data sets.
Summary
The possibilities for optimizing results for more complex data sets are much greater, and if you want to compete on Kaggle, I suggest picking up a version of model stacking. This is a rather simple case. On Kaggle, you will see stacking of 100+ models in a single layer. Gilberto and Stanislav on Kaggle optimized 33 models from scratch and combined them in a model stack to win the first place award of $5000. This was some years back. Today, there are prices of up to $1,000,000 for detecting Deepfakes.