Blog post
Analyze your Spark application using explain
Find the execution plan for your Spark queryIt is important that you have some understanding of Spark execution plan when you are optimizing your Spark applications. Spark provides an explain API to look at the Spark execution plan for your Spark SQL query. In this blog, I will show you how to get the Spark query plan using the explain API so you can debug and analyze your Apache Spark application. The explain API is available on the Dataset API. You can use it to know what execution plan Spark will use for your Spark query without actually running it. Spark also provides a Spark UI where you can view the execution plan and other details when the job is running. For Spark jobs that have finished running, you can view the Spark plan that was used if you have the Spark history server set up and enabled on your cluster. This is useful when tuning your Spark jobs for performance optimizations.
Using the explain API in your Spark program
To begin, I will open a Spark shell and run some sample code. You can use the explain API similarly in your Scala program: $ ./bin/spark-shell.
First, let's create some dataset. I have created a temporary view test_agg that has two columns k and v.
scala> sql(
| """
| |CREATE TEMPORARY VIEW test_agg AS SELECT * FROM VALUES
| | (1, true), (1, false),
| | (2, true),
| | (3, false), (3, null),
| | (4, null), (4, null),
| | (5, null), (5, true), (5, false) AS test_agg(k, v)
| """.stripMargin)
res0: org.apache.spark.sql.DataFrame = []
scala> sql("select * from test_agg").show
+---+-----+
| k| v|
+---+-----+
| 1| true|
| 1|false|
| 2| true|
| 3|false|
| 3| null|
| 4| null|
| 4| null|
| 5| null|
| 5| true|
| 5|false|
+---+-----+
Let us run a simple spark sql query that aggregates the number of rows in each v group.
scala> sql("select v,count(*) from test_agg group by v").show
+-----+--------+
| v|count(1)|
+-----+--------+
| null| 4|
| true| 3|
|false| 3|
+-----+--------+
You can use the explain call to find out the physical plan that Spark generated for this query.
Now, let us look at each of the lines printed out. To read this plan, you should go bottom up. Spark reads the input dataset, which is a LocalTableScan in this scenario. Next, Spark used a HashAggregate for the aggregate function computation. The aggregate function is count and the group by key is v. So in the first HashAggregate, Spark will compute the partial count, denoted by partial_count. For each partition, Spark will do a partial count operation and then merge the results in the final count. There is an exchange, a shuffle operation. Spark is doing a hash partitioning for the exchange, and it used 200 as the shuffle partition. The (1) and (2) are for the wholestage codegen stages. Everything with the same index number is in one stage. So stage boundaries can be recognized by exchange operations that involve a shuffle.
scala> sql("select v,count(*) from test_agg group by v").explain
== Physical Plan ==
*(2) HashAggregate(keys=[v#1], functions=[count(1)])
+- Exchange hashpartitioning(v#1, 200), true, [id=#41]
+- *(1) HashAggregate(keys=[v#1], functions=[partial_count(1)])
+- *(1) LocalTableScan [v#1]
scala> sql("select v,count(*) from test_agg group by v").explain(true)
== Parsed Logical Plan ==
'Aggregate ['v], ['v, unresolvedalias('count(1), None)]
+- 'UnresolvedRelation [test_agg]
== Analyzed Logical Plan ==
v: boolean, count(1): bigint
Aggregate [v#1], [v#1, count(1) AS count(1)#35L]
+- SubqueryAlias test_agg
+- Project [k#0, v#1]
+- SubqueryAlias test_agg
+- LocalRelation [k#0, v#1]
== Optimized Logical Plan ==
Aggregate [v#1], [v#1, count(1) AS count(1)#35L]
+- LocalRelation [v#1]
== Physical Plan ==
*(2) HashAggregate(keys=[v#1], functions=[count(1)], output=[v#1, count(1)#35L])
+- Exchange hashpartitioning(v#1, 200), true, [id=#58]
+- *(1) HashAggregate(keys=[v#1], functions=[partial_count(1)], output=[v#1, count#39L])
+- *(1) LocalTableScan [v#1]
Below is another way to get the execution plan using the explain command, which will give the physical plan information. If you use explain extended, it will give you the parsed logical plan, analyzed logical plan, optimized logical plan, and the physical plan information as well.
scala> sql("explain select v,count(*) from test_agg group by v").show(false)
+-------------------------------------------------------------------------------------------------------------------------+
|plan |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|== Physical Plan ==
*(2) HashAggregate(keys=[v#1], functions=[count(1)])
+- Exchange hashpartitioning(v#1, 200), true, [id=#121]
+- *(1) HashAggregate(keys=[v#1], functions=[partial_count(1)])
+- *(1) LocalTableScan [v#1]
|
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
If you have wholeStage disabled, you will not see the wholeStage codegen stage indexes in the plan.
scala> spark.conf.set("spark.sql.codegen.wholeStage", false)
scala> sql("select v,count(*) from test_agg group by v").explain(true)
== Parsed Logical Plan ==
'Aggregate ['v], ['v, unresolvedalias('count(1), None)]
+- 'UnresolvedRelation [test_agg]
== Analyzed Logical Plan ==
v: boolean, count(1): bigint
Aggregate [v#1], [v#1, count(1) AS count(1)#78L]
+- SubqueryAlias test_agg
+- Project [k#0, v#1]
+- SubqueryAlias test_agg
+- LocalRelation [k#0, v#1]
== Optimized Logical Plan ==
Aggregate [v#1], [v#1, count(1) AS count(1)#78L]
+- LocalRelation [v#1]
== Physical Plan ==
HashAggregate(keys=[v#1], functions=[count(1)], output=[v#1, count(1)#78L])
+- Exchange hashpartitioning(v#1, 200), true, [id=#138]
+- HashAggregate(keys=[v#1], functions=[partial_count(1)], output=[v#1, count#82L])
+- LocalTableScan [v#1]
Using the Spark UI
Now we will look at the execution plan for your Spark job after Spark has run it or when it is running it. Open up the Spark UI in your browser. Please note, you will need to consult your Spark cluster setup to find out where you have the Spark UI running. If you have a local Spark setup, and you have Spark shell up and running, you can get to the Spark UI at port 4040 by default (http://localhost:4040). Go to the SQL tab and find the query you ran.
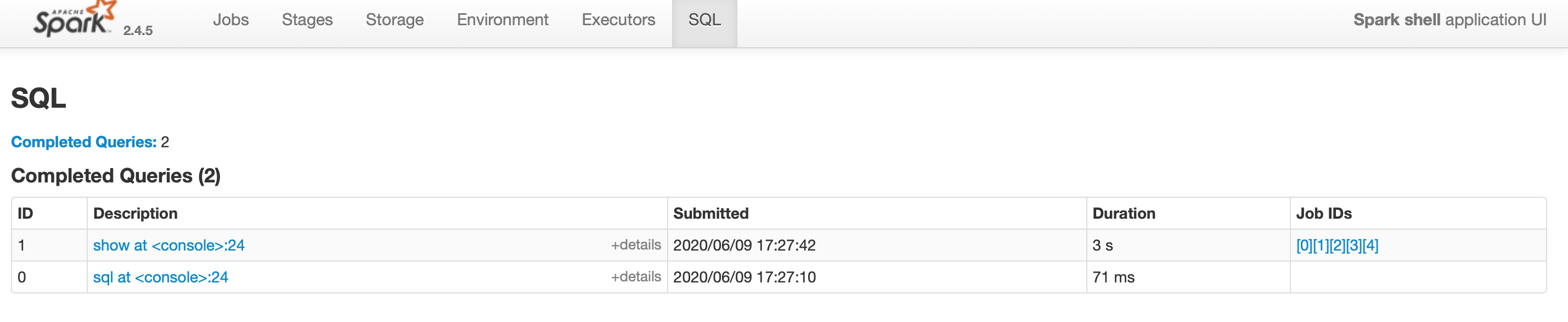
Click on the description to view the visualization of the Spark Directed Acyclic Graph (DAG) for your query execution. You need to read this from top to bottom. You can expand the details at the bottom of the page to view the execution plan for your query. This information is similar to what you can see when you run the explain API programmatically.
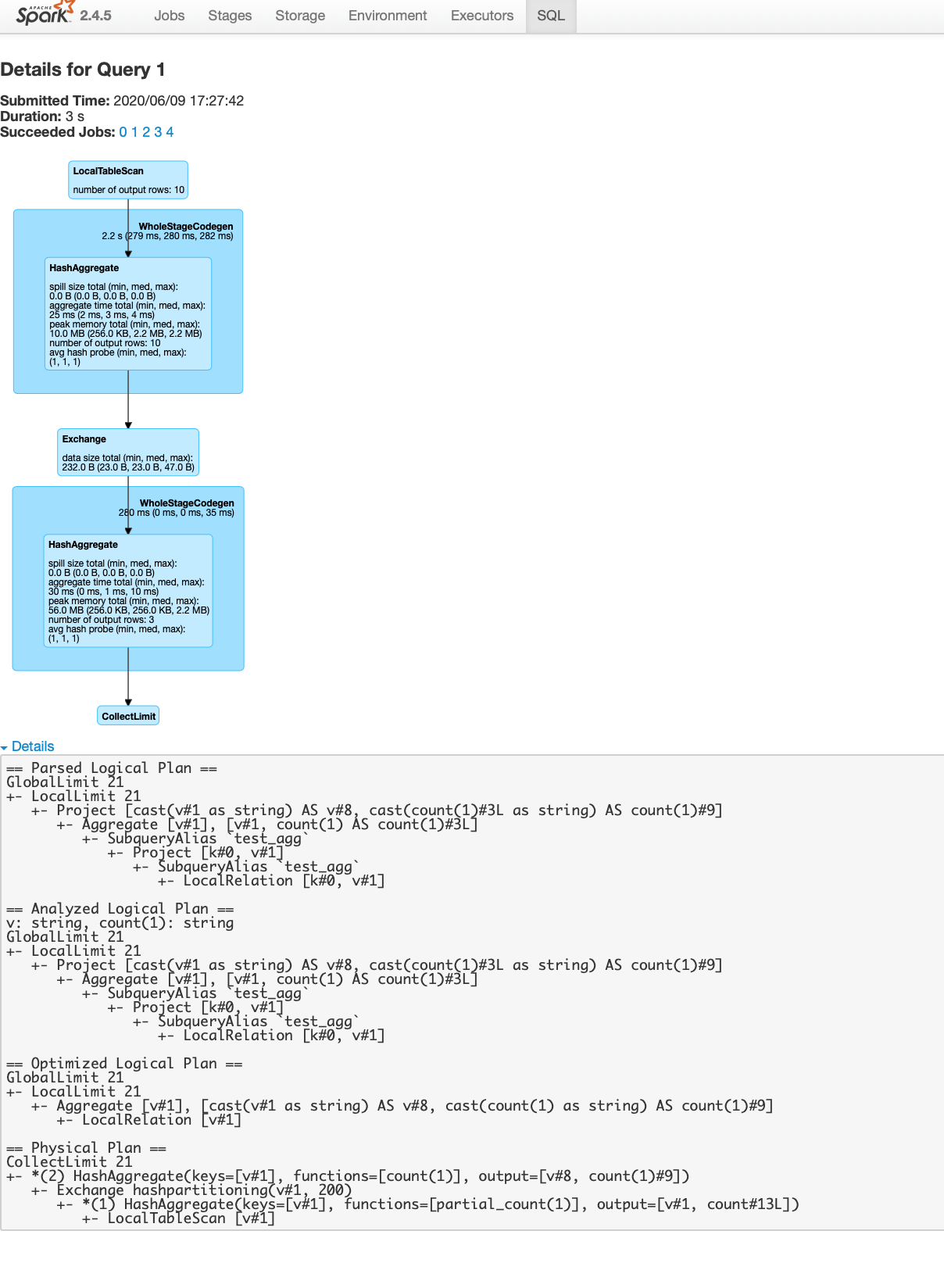
Hope this blog was helpful to you to learn how to find the execution plan for your Spark query. Happy developing!