Article
Instilling trust in AI
What level of trust can - and should - we place in these AI systems?Artificial intelligence (AI) is everywhere. From Alexa in our homes to recommendations from Netflix to Google's predictive search engine to surgical robots, these AI systems can sense, reason, understand, learn, and interact. The capabilities of artificial intelligence are not hidden. The intelligence of machines is undergoing a major transformation through continuous self-learning improvements. However, these AI models are still a black box, and their decisions are often questioned by the clients. The research is moving faster than ever on improving and optimizing the algorithms, but this alone doesn't suffice.
The conversations around building trust on AI are often a point of interest for developers, sales, and marketing teams who work directly with clients. Therefore, it's important to look into. Imagine owning a computer vision company that builds AI classification models for people in the healthcare industry to diagnose cancer by using MRIs, CT scans, and X-rays. It can be difficult for a doctor to rely on the diagnosis that is suggested by an AI model when a person's life is involved.
With AI providing benefits across industries, enterprises and start-ups are constantly innovating on how to make applications smarter and better. However, advancements in AI can create new challenges and raise legal and ethical questions.
As AI continues to expand its role in our lives and make decisions for us and on behalf of us, an important question comes to mind: What level of trust can - and should - we place in these AI systems?
Three pillars of trusted AI
Building trusted AI pipelines has become increasingly important within AI applications, and there are three main pillars to building trustworthy AI pipelines: fairness, explainability, and robustness.
Fairness
Ensuring fair AI systems means getting rid of (or at least minimizing) bias in the model or data. Bias can be described as the mismatch between the training data distribution and a wanted fair distribution. Bias can easily enter AI systems through the training data that you create, collect, or process. The system can pick them up, encode them, and have the potential to scale, which can result in unfair results. Machine learning algorithms learn from the training data that they are given. As they say - garbage in, garbage out.
Unfair biases can exist in the data that is used to train the model as well as in the model's own decision-making algorithm. Fairness emphasizes the identification and tackling of such biases that are introduced in the data. This ensures that a model's predictions are fair and do not unethically discriminate.
To encourage the adoption of AI, you must ensure that it does not take on and amplify biases and use equitable training data and models to avoid unfair treatment. Establishing tests for identifying, curating, and minimizing bias in training data sets should be a key element to establish fairness in AI systems.
Explainability
Explainability shows how a machine learning model makes its predictions. It gives an improved understanding of the model by clarifying how the model works. It is essential to data scientists for detecting, avoiding, and removing its failure modes; to SMEs and customers for earning public trust in the algorithm; and for introducing effective policies to regulate the technology.
Although a key fundamental of trusted AI, explainability can be challenging to implement. When implementing it, the accuracy of the model is compromised. This is because simpler models that are easy to interpret are pinched in their predictive capacity (for example, linear regression or decision trees). More powerful and complex algorithms such as neural networks or random forests tend to be highly accurate but difficult to understand due to their complex nature.
Another factor to consider is that explainability isn't one-dimensional. Different stakeholders would want to have insights on different aspects of the inner workings of an algorithm, based on purposes and objectives. Therefore, explanations must be tailored.
Robustness
Robustness measures the stability of algorithm performance when a model that is deployed in the real world is attacked and noise is introduced in the training data. It characterizes how effective your algorithm is while being tested on the new independent (but similar) data set. This ensures that the algorithm of the model is able to handle the unseen, perturbed data. It addresses the questions of estimating uncertainties in its predictions and whether the model is robust.
Robustness consists of two factors, safety and security. AI safety is typically associated with the ability of an AI model to build knowledge that incorporates societal norms, policies, or regulations that correspond to well-established safe behaviors. AI security is defending AI systems from malicious attacks. Like any software system, AI systems are vulnerable to adversarial attacks. This raises security concerns as models can be tampered with and data can be compromised or poisoned.

Attackers can steal AI models by studying their outputs or fool the algorithm by introducing noise or adversarial perturbation. If you think this is difficult, check out One Pixel Attack for Fooling Deep Neural Networks, which describes how a deep neural network identifies images incorrectly when one pixel - that's right, only one pixel - is modified in the image.
Security can be improved by exposing and fixing vulnerabilities in the system, identifying new attacks and defenses, designing new adversarial training methods to strengthen against attacks, and developing new metrics to evaluate robustness.
Tools
Now that you know the importance of engendering trust in AI systems and the factors that influence trust, let's look at some tools to help you achieve them.
Watson OpenScale
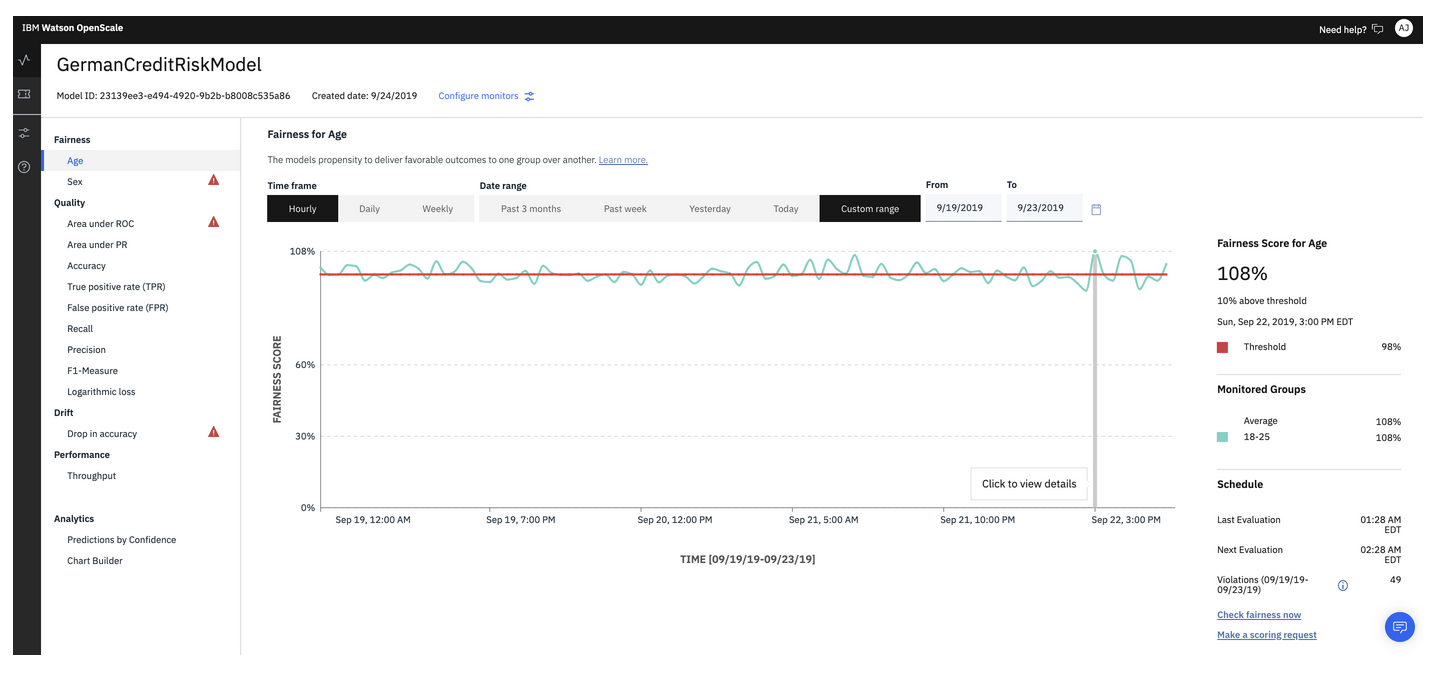
Watson OpenScale is an enterprise-grade environment for AI-infused applications that gives enterprises visibility into how AI is being built and used as well as delivering ROI. OpenScale is open by design and can detect and mitigate bias, help explain AI outcomes, scale AI usage, and give insights into the health of the AI system - all within a unified management console.
AI Explainability 360
We are used to providing explanations to different groups of people - our friends, our kids, our colleagues. We use different words and expressions to convey our thoughts to these various groups. Something similar is happening in the machine learning world as more models are being deployed to make predictions in domains such as finance, telecommunication, healthcare, and others. In many cases, businesses don't fully understand how machine learning models make their predictions. This lack of understanding can be problematic.
Often, businesses and policymakers need to be able to explain how the models are making their predictions. This often becomes more complicated in context of ensemble models and deep neural networks. To address the gap between machine learning models and business users, the AI Explainability 360 toolkit is a collection of algorithms that can help explain machine learning models and their predictions.
These include five different classes of algorithms:
- Data explanation: understand the data
- Global direct explanation: the model itself is understandable
- Local direct explanation: the individual prediction is meaningful
- Global post hoc explanation: an understandable model explains the black box model
- Local post hoc explanation: an explanation is created for the individual prediction
Currently, there are eight algorithms that are spread across these classes available in the toolkit.

The AI Explainability 360 toolkit is an open source Python library that can help comprehend how machine learning models predict labels by various means throughout the AI application lifecycle. Containing eight state-of-the-art algorithms for interpretable machine learning as well as metrics for explainability, it is designed to convert algorithmic research from the lab into the actual practice of domains as wide-ranging as finance, human capital management, healthcare, and education.
Adversarial Robustness 360 Toolbox
The Adversarial Robustness 360 Toolbox is an open source Python library for adversarial machine learning and supports defending deep neural networks against adversarial attacks, making AI systems more secure. Its purpose is to allow rapid crafting and analysis of attacks and defense methods for machine learning models. The Adversarial Robustness 360 Toolbox provides an implementation for many state-of-the-art methods for attacking and defending classifiers.
The Adversarial Robustness Toolbox is designed to support researchers and developers in creating novel defense techniques, as well as in deploying practical defense of real-world AI systems. For developers, the library provides interfaces that support the composition of comprehensive defense systems using individual methods as building blocks.
AI Fairness 360
Underrepresentation of data sets and misinterpretation of the data can lead to major flaws and bias that are critical for decision-making in many industries. These flaws and biases might not be easy to detect without the right tool. AI Fairness 360 is an open source library to help detect and remove bias in machine learning models and data sets.
The AI Fairness 360 Python package includes a comprehensive set of metrics for data sets and models to test for biases, explanations for these metrics, and algorithms to mitigate bias in data sets and models. Containing over 30 fairness metrics and 9 state-of-the-art bias mitigation algorithms developed by the research community, it is designed to convert algorithmic research from the lab into the actual practice of domains as wide-ranging as finance, human capital management, healthcare, and education.
The AI Fairness 360 open source directory contains a diverse collection of Jupyter Notebooks that can be used in various ways.
Summary
This article explained the three main pillars to building trustworthy AI pipelines: fairness, explainability, and robustness. It provided an overview of these pillars, and showed some tools that you can use to build fairness and explainability into your models. This helps the AI models become transparent, bias-free, robust, and explainable.