The Hub and Spoke architecture that is formalized with IBM Z Decision Support V1.9.0 is designed to reduce operational complexity and improve time to value for IBM Z Decision Support (formerly known as IBM Tivoli Decision Support for z/OS).
Introduction
IBM Z Decision Support V1.9.0 improves data management over the previous releases’ deployment paradigm through the introduction of a new, continuous automated data gathering and collection process.
A typical IBM Tivoli Decision Support V1.8.x installation is set up on a single system or a small Sysplex and the user is required to acquire data containing operational metrics from their systems, transport it to the system where IBM Tivoli Decision Support is installed and feed it to the IBM Tivoli Decision Support Log Collector with a sequence of batch jobs.
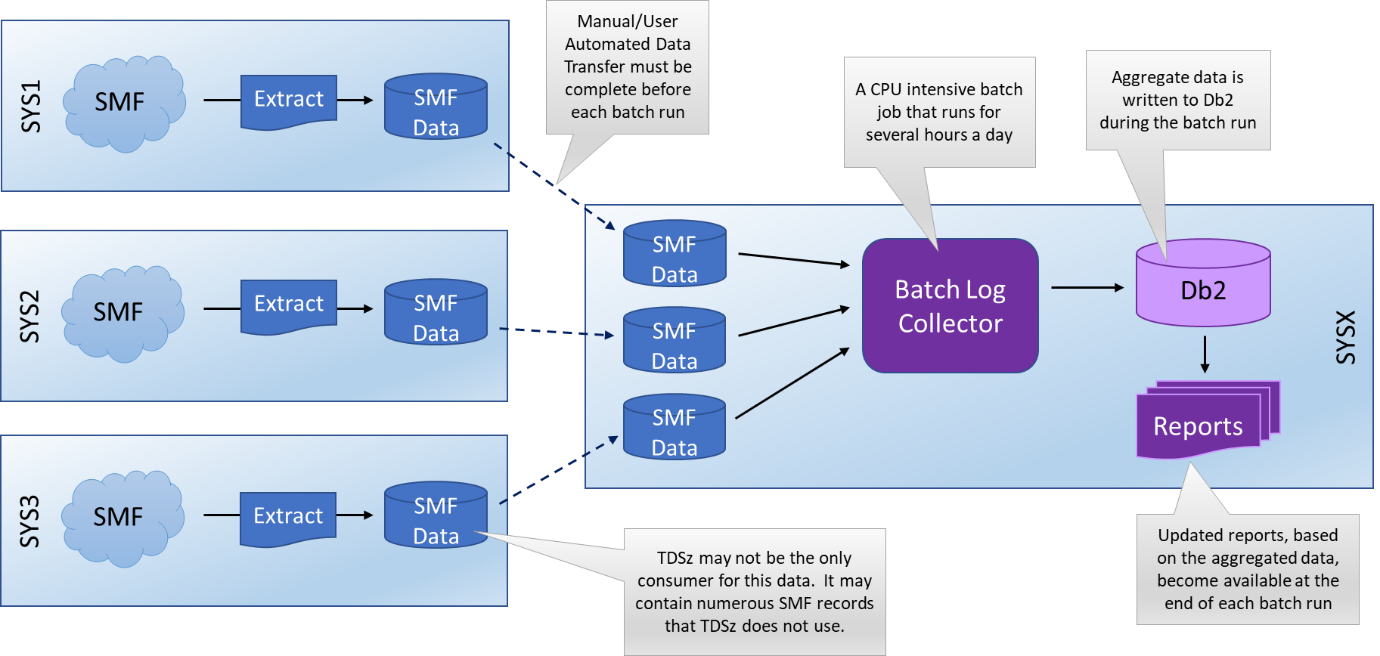
Figure 1 Existing IBM Tivoli Decision Support 1.8.2 Deployment
In IBM Z Decision Support V1.9.0, we are introducing a new data gathering agent (the IBM Z Decision Support Agent) that runs on each of the systems being tracked. This agent acquires SMF data and transports it back to the IBM Z Decision Support Hub, where it gets processed as it arrives rather than waiting for a batch run.
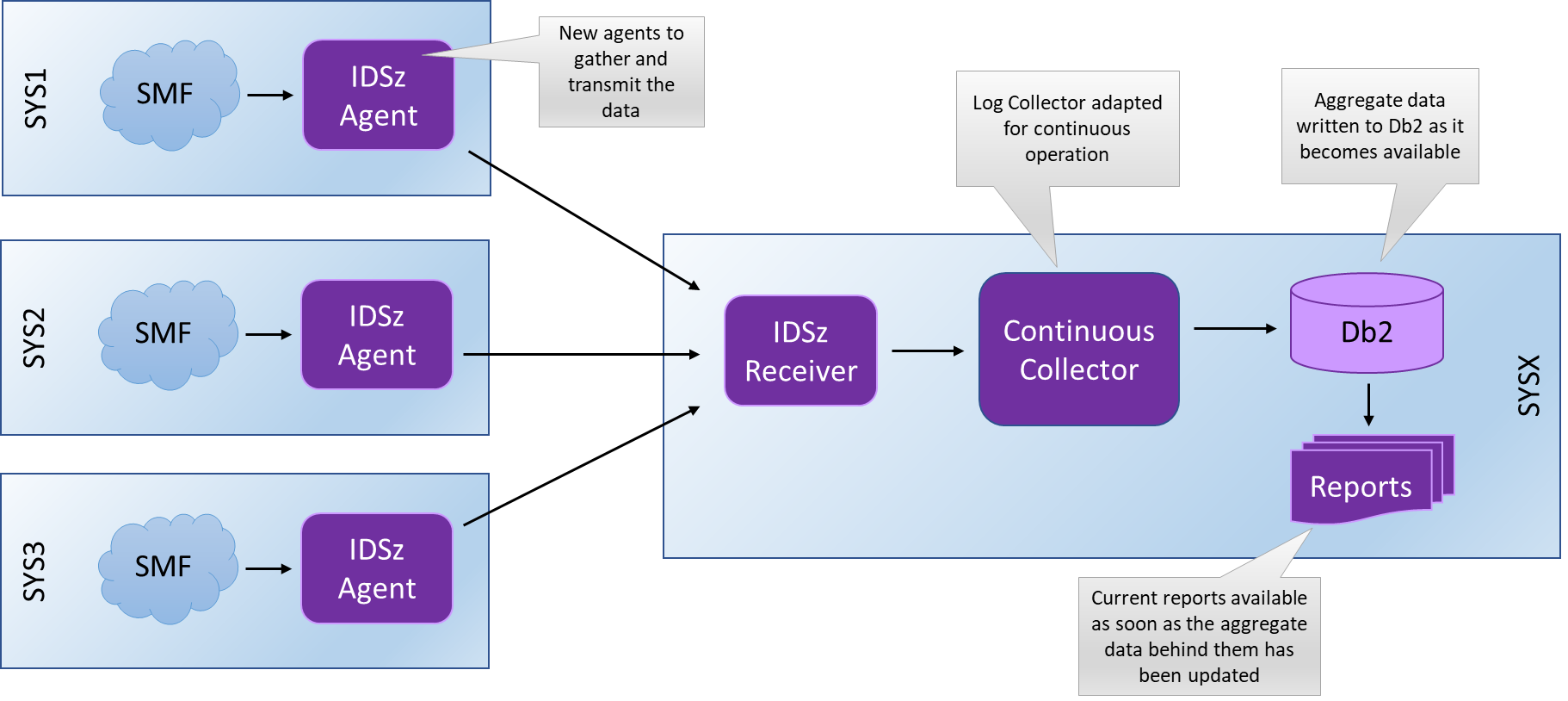
Figure 2 - IBM Z Decision Support (IDSz) Automated SMF Data Gathering and Collection
The benefits of this new approach are significant:
• Customers don’t have to worry about scheduling, gathering, or transporting the SMF data.
• The data is available for reporting as soon as its aggregation period is complete – no need to wait for the data to be moved and the overnight batch run to finish. Data fetched by the Agent will typically be available in IBM Z Decision Support reports within a few minutes of the aggregation interval closing.
• The peak system load that occurs during batch processing of SMF data is eliminated. As the data is now being processed continuously the load for processing it gets spread across the day, giving a much lower peak and thus a reduced impact upon the systems four hour rolling average and total cost of ownership.
At present the IBM Z Decision Support Agent only collects SMF data, so other types of data will still have to be collected and processed the traditional way.
Note that you can continue the collect SMF data the traditional way. You can even collect some systems data using the IBM Z Decision Support Agent and other systems data using the traditional approach. This flexibility allows you to make a gradual cutover to using the IBM Z Decision Support Agent to collect data from all systems.
Configuring the Hub
On the Hub you make a traditional IBM Z Decision Support installation, with the product and Db2. There is an additional started task to configure though – the Continuous Collector. This is the part of IBM Z Decision Support that performs data aggregation throughout the day.
The data from the IBM Z Decision Support Agent is received by a new IBM Z Decision Support Data Mover configured as a receiver – that also runs as a started task. This is a Java program and is configured to set itself up as a server to receive data from the Agents on the spoke systems and pass it to the Continuous Collector.
Communications between the Data Mover and the Continuous Collector uses a new log stream – which you will be required to define. A log stream is used here because it provides a lossless communication system that can rapidly expand to buffer data when things are busy. In the event of an outage of the Continuous Collector, the log stream will comfortably buffer the SMF data until the Continuous Collector is restarted.
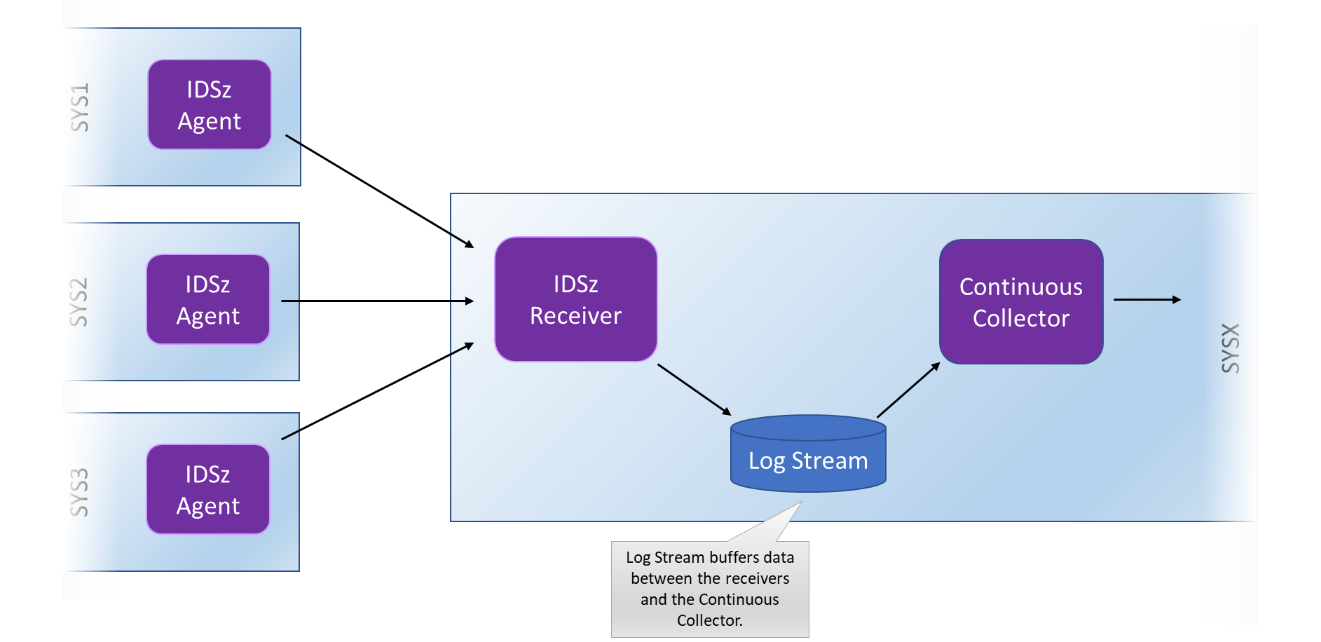
Figure 3 - A Log Steam is used to buffer the data
Here is a sample configuration for a Data Mover running as a receiver:
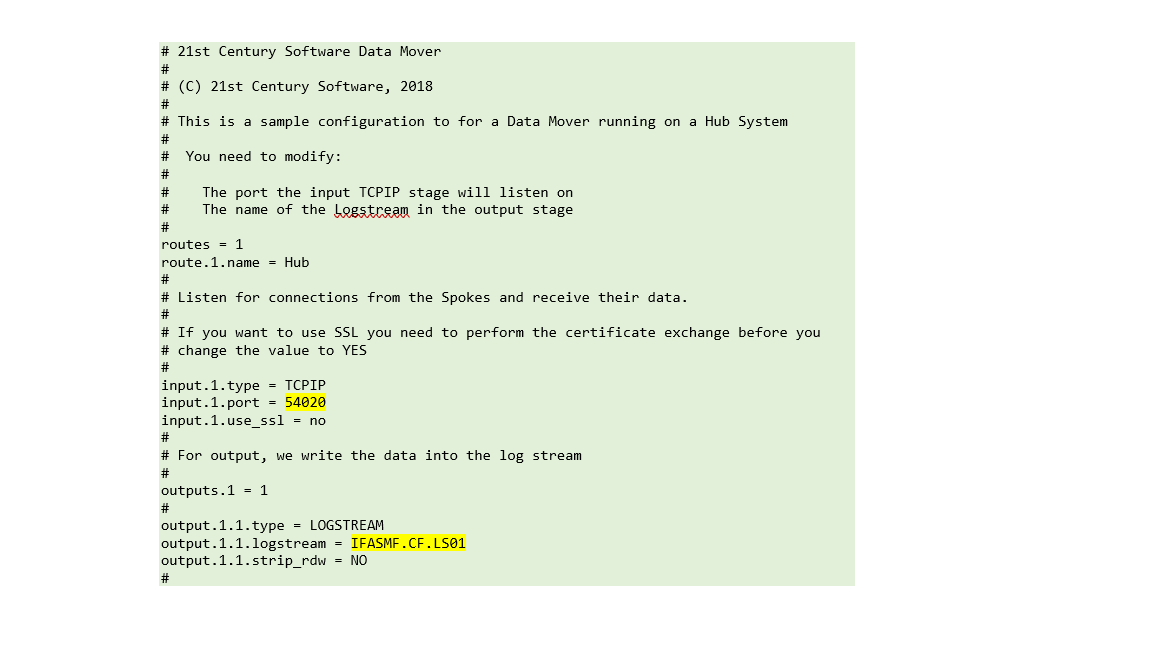
Sample code 1: sample configuration for a Data Mover running as a receiver
You must specify the TCP/IP port that it is going to use and the name of the log stream that you have provided for it to communicate with the Continuous Collector. The same log stream must be specified to the Continuous Collector itself. The Data Mover supports encrypted communications across the TCP/IP connection between the Agent and the Receiver.
Advanced Configuration – Multiple Receivers
The number of Data Mover receivers you need to configure and run will depend on how many systems you have, the volume of data that those systems are feeding to the IBM Z Decision Support Hub and the network they are feeding it across. If you are selective about the data to be collected, you could configure a single receiver to serve many Agents. If, however, you configure the Agents to send a large volume of SMF records, you can set up multiple receivers and direct small groups of agents (or even single agents) to each one.
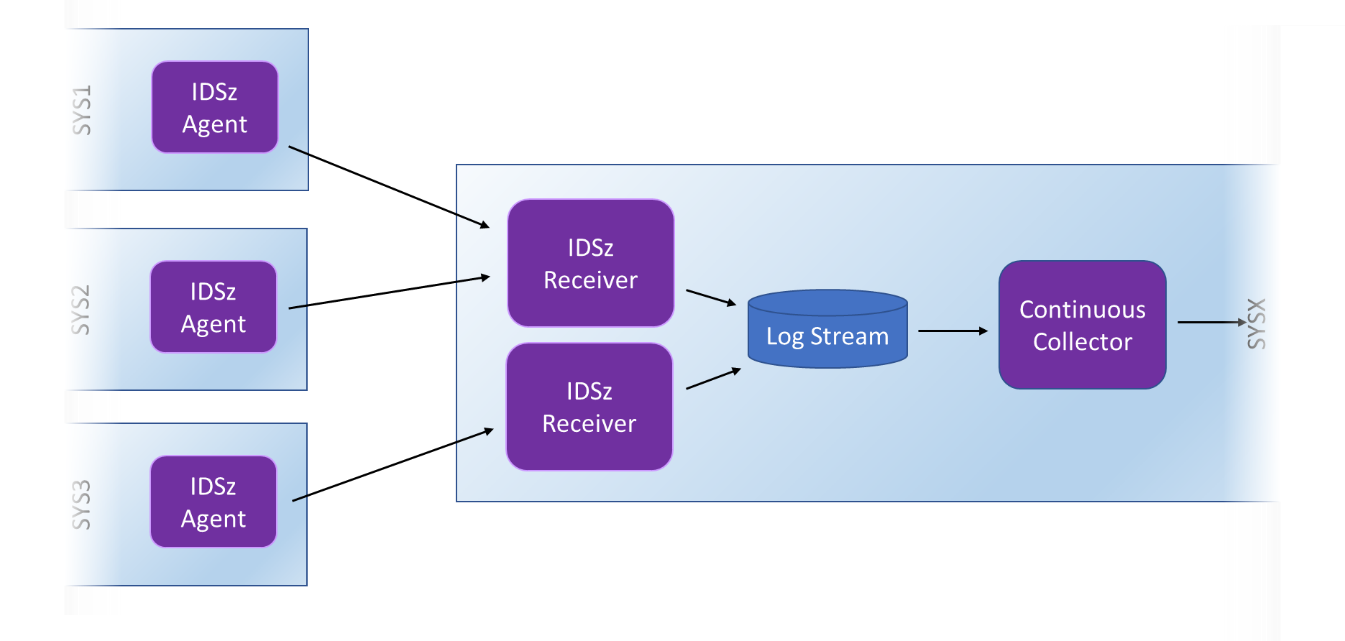
Figure 4 - Multiple Receivers may be needed
Each receiver requires its own working directory under OMVS. Creating a new working directory is very much a case of simply repeating the basic installation steps:
1. Allocate a new directory for the Data Receiver to run under and unpack the shipped DataMover.tar file into it.
2. In the IDSz/DataMover subdirectory, edit the DataMover.sh script and update the working directory specification to match the directory it is in.
3. Duplicate the proc for the Data Mover started task and change the working directory specification in the new copy.
4. Update the Hub config file in the new IDSz/DataMover/config directory to specify the TCPIP port your new Data mover is to use for input and ensure it has the correct log stream for output (they all write to the same log stream).
Advanced Configuration – IBM Z Decision Support Hub on a Sysplex
If you are running an IBM Z Decision Support Hub on a Sysplex, you can configure it to run multiple Continuous Collectors, one on each system. In this scenario, you would create a separate log stream for each system’s Continuous Collector and the Data Mover receivers running on that system would be configured to output into that systems log stream.
Under such a configuration, it is important that agents from the same remote Sysplex are all told to route their data through the same system (and thus Continuous Collector) on the Hub.
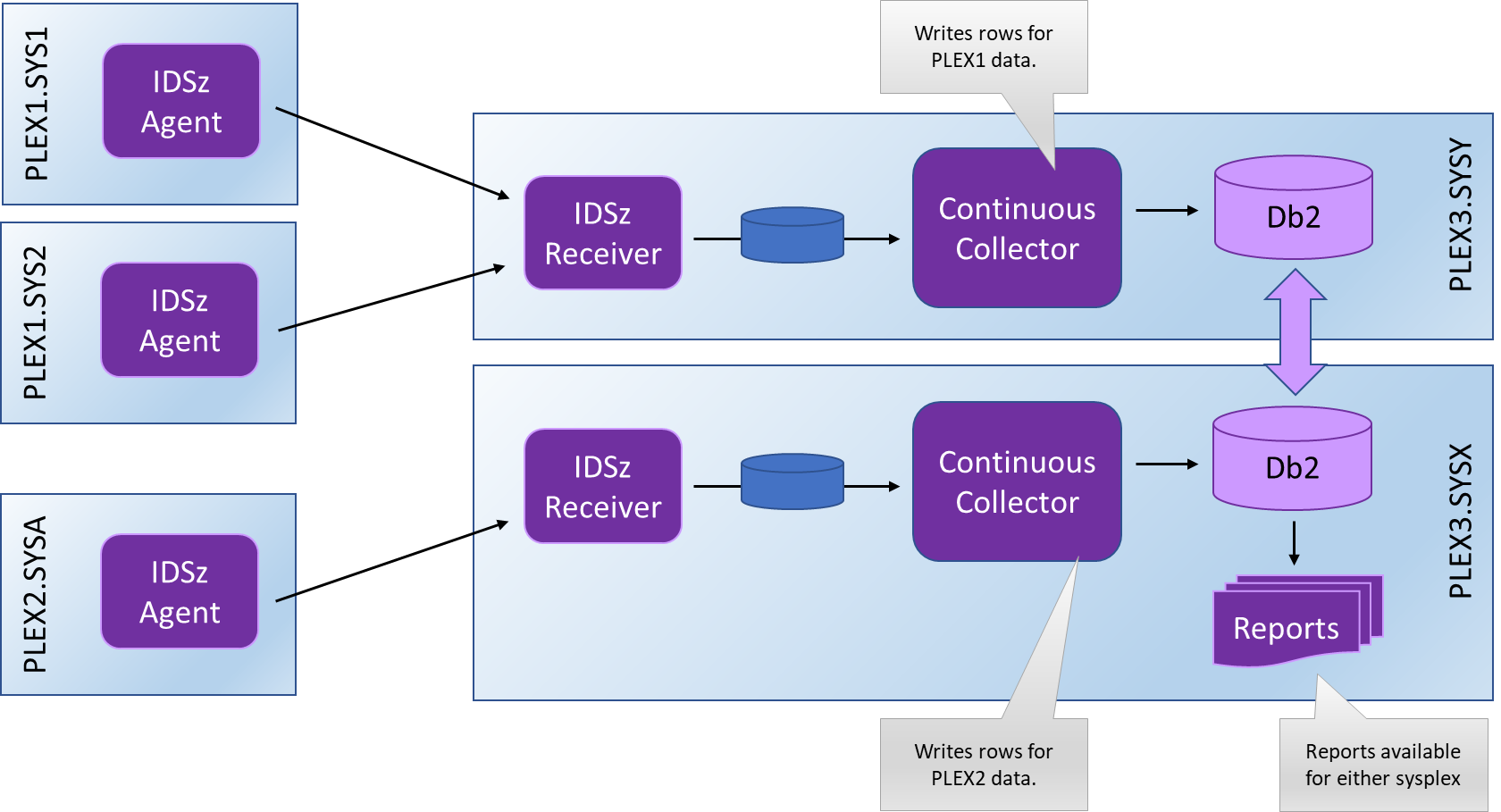
Figure 5 - IBM Z Decision Support (IDSz) Sysplex Deployment
Start small (on a test system) and work up to the simplest configuration that will support your enterprise.
Configuring a Spoke
On a Spoke system, there are three components of the IBM Z Decision Support Agent that you need to set up:
• The IBM Z Decision Support SMF Extractor
• The IBM Z Decision Support Data Mover
• A log stream so they can talk to each other.
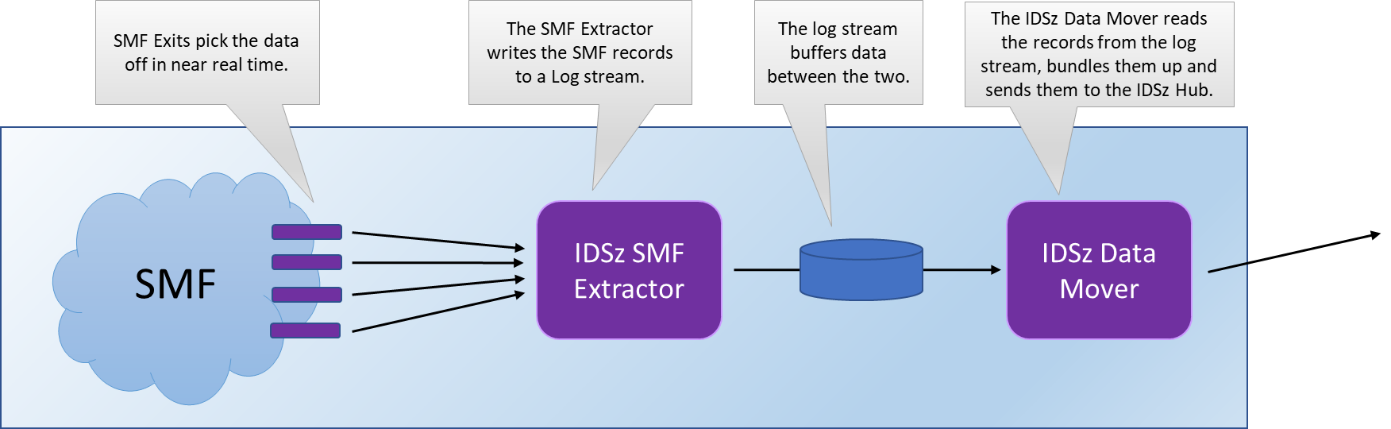
Figure 6 - IBM Z Decision Support (IDSz) Agent Deployment
Setting up the IBM Z Decision Support SMF Extractor
The SMF extractor is a set of SMF Exits and policy logic that will gather a specified set of SMF records in real time and write them out to a log stream. It will work with any SMF installation, whether it is writing to SYS1.MANx datasets or to log streams.
The SMF Extractor is set up as an APF authorized Started Task and needs to be started as early as possible after an IPL to maximise the number of SMF records it captures.
The SMF Extractor is configured with a simple text file.

Sample code 2: SMF Extractor configuration
Ensure you are extracting all the SMF types required for the target Continuous Collector configuration. Review the SMF record type requirements for all the installed IBM Z Decision Support components and make sure those records are being extracted.
Setting up the IBM Z Decision Support Data Mover as a Forwarder
As with the Hub you must setup the IBM Z Decision Support Data Mover as a started task, although it can’t be started until after OMVS and TCPIP are up. When it comes up, it’ll pick up all the data that the SMF Extractor has written to the log stream before it was started.
You must configure the Data Mover to forward its data to the IBM Z Decision Support Hub:
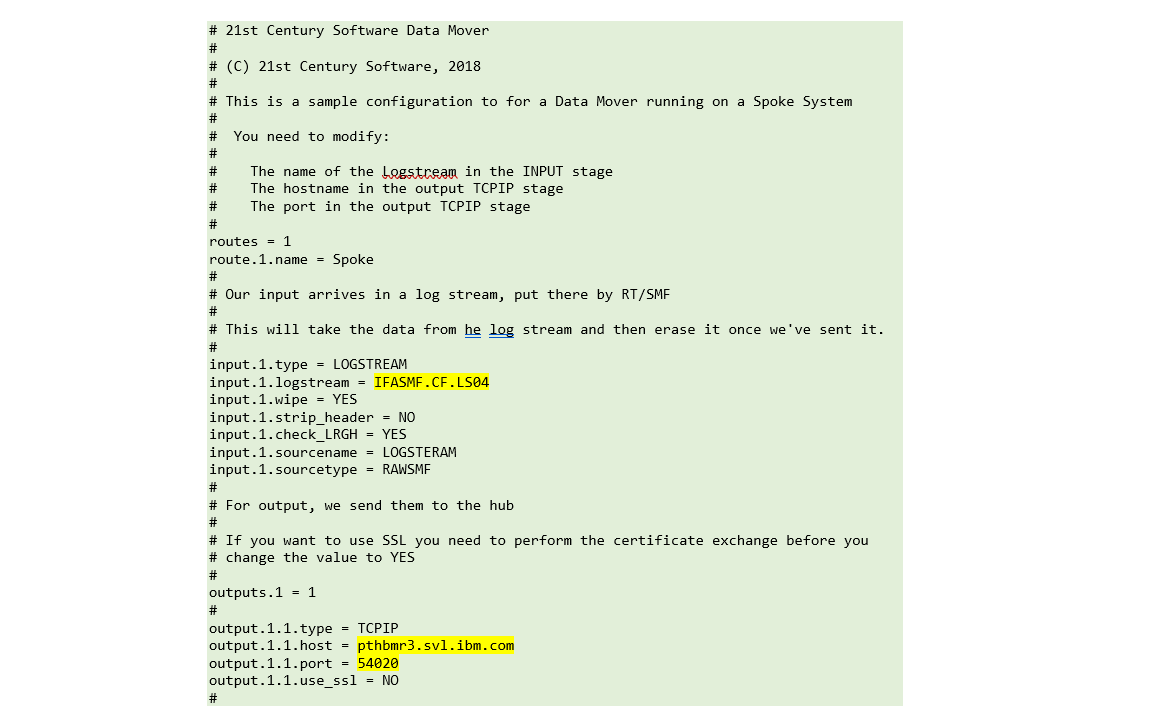
Sample code 3: Data Mover configuration
This tells the Data Mover to read data from the log stream, pack it up and send it over TCP/IP to the IBM Z Decision Support Hub.
Advanced Configuration - Feeding Multiple IBM Z Decision Support Hubs
It is possible to configure the agent to send its data to multiple IBM Z Decision Support hubs. You might do this if you wanted to make the data from one hub available to a small set of users and have a larger hub that had all the data.
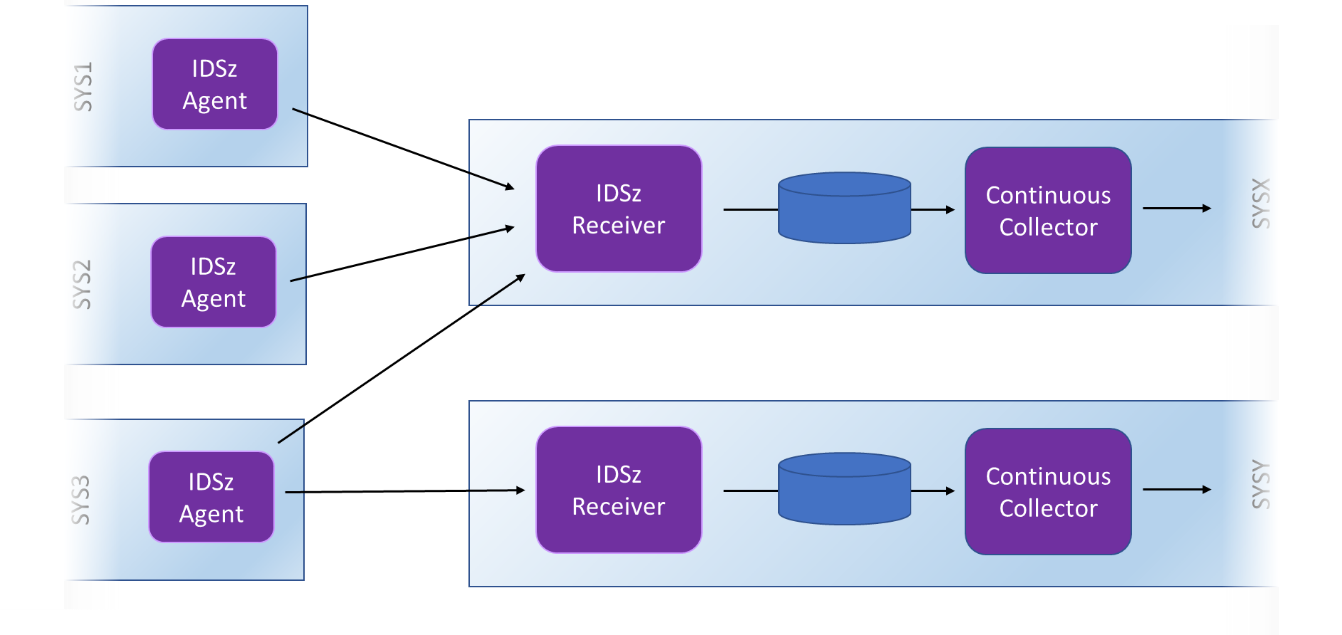
Figure 7: Feeding Multiple IBM Z Decision Support Hubs
To do this, you duplicate the output stage definition in the Data Movers configuration and specify the address of the second IBM Z Decision Support hub.

Sample code 4: Data Mover configuration for multiple Hub
Conclusion
IBM Z Decision Support V1.9.0 provides a new agent to gather SMF data from Spoke systems in near real time and transport it back to the IBM Z Decision Support Hub for continuous processing.
• This automates previously manual data gathering, transporting and collection tasks, providing reduced cost of ownership and simpler operation.
• IBM Z Decision Support reports that are based on the SMF data are now available on the day the data was gathered.
• The system load for processing the SMF Data on the hub has been distributed throughout the day, reducing its peak contributions to the systems 4HRA.