Written by Fang Zheng.
In Streams, consistent regions feature enables guaranteed tuple processing.
Operators in a consistent region periodically persist their internal state under the coordination of the consistent cut protocol, so that a globally consistent checkpoint of the whole consistent region can be saved. Upon failures, the Streams runtime automatically restarts affected operators and resets the state of all operators in the consistent region to the last consistent checkpoint. This coordinated checkpoint/rollback mechanism, coupled with tuple replay, enables guaranteed tuple processing in the consistent region.
If you have written a C++ or Java operator that supports consistent regions, this article will discuss how to enable non-blocking checkpointing so that tuple processing is not interrupted during checkpointing.
Review of Consistent Regions
Before we present the new enhancements in Streams 4.2, let’s first briefly review how consistent region works. In Streams 4.0 and 4.1, a controller is responsible for coordinating the checkpointing and recovery of operators in a consistent region. An operator can implement its own drain(), checkpoint(), reset(), and resetToInitialState() callbacks in the StateHandler interface to specialize the operator’s behavior during the consistent cut protocol.
class StateHandler // StateHandler interface in SPL Operator Runtime C++ API
{
public:
// APIs in Streams 4.0/4.1
virtual void drain() {} // drain() callback is invoked when drain marker reaches the operator
virtual void checkpoint(Checkpoint & ckpt) {} // the callback to checkpoint operator state
virtual void reset(Checkpoint & ckpt) {} // the callback to reset operator state from checkpoint
virtual void retireCheckpoint(int64_t seqId) {} // invoked when checkpoint of the given seq. ID is retired
virtual void resetToInitialState() {} // the callback to reset operator to initial state
// new API introduced in Streams 4.2
virtual void prepareForNonBlockingCheckpoint(int64_t seqId) {} // prepare operator for non-blocking checkpoint.
virtual void regionCheckpointed(int64_t seqid) {} // invoked when the whole region is fully checkpointed.
};
The consistent cut protocol to establish a consistent checkpoint of a consistent region is as follows. For each start operator of the region, the Streams runtime first invokes operator’s drain() callback function (in which operator can do things like finishing any outstanding processing), and then invokes operator’s checkpoint() callback to checkpoint operator state. After checkpointing finishes, a special punctuation called “Drain Marker” is submitted from start operator to downstream. When a Drain Marker reaches an operator, that operator’s drain() callback is invoked, followed by the invocation of its checkpoint() to checkpoint its state; the Drain Marker is then further forwarded downstream. The tuple flow in the consistent region is temporarily blocked and only resumes after all the operators of the region are checkpointed.
The consistent cut protocol to rollback the consistent region to a previous checkpoint is similar. The protocol starts after all failed operators in the region are restarted and become healthy. The Streams runtime first invokes each start operator’s reset() callback to restore the operator state from its previous checkpoint (or resetToInitialState() if the failure occurs before any checkpoint is taken), and then propagate a punctuation called “Reset Marker” though the region. As a Reset Marker travels through an operator, that operator’s reset() or resetToInitialState() callback is invoked to restore its state. When all the operators of the region are restored, the controller asks the start operator(s) to resume the tuple flow.
How does Non-Blocking Checkpointing Work?
In Streams 4.2, we further optimize the consistent cut protocol, and provide a new set of non-blocking checkpointing APIs to C++ and Java operators.
We speed up the consistent cut protocol with several optimizations. First, instead of forwarding Drain or Reset Marker after checkpointing or resetting operator state, each operator now forwards the marker downstream as soon as its drain() is complete, so that multiple operators can checkpoint or reset concurrently. Second, each PE now has a background thread pool dedicated for checkpointing and resetting operators. These optimizations increase the level of concurrency of the protocol.
Another optimization in Streams 4.2 is the new APIs for operators to perform non-blocking checkpointing so that tuple flow can be resumed while operator is being checkpointed in the background. This can reduce the time that the tuple flows have to block when a consistent region is being checkpointed, and allow checkpointing to be performed asynchronously with tuple processing. This can in turn lower the overall fault tolerance overheads and improve end-to-end application performance. This feature is particularly beneficial if the checkpointing of operator state is time consuming (e.g., due to the large checkpoint data size or slowness in congested backend data store).
The non-blocking checkpointing APIs are available in both SPL Operator Runtime C++ API and SPL Java Operator API. They are described in detail in the Streams documentation. In the reminder of this article, we provide additional usage tips of the non-blocking checkpointing APIs. We will use the C++ API as example.
In order to enable non-blocking checkpointing, an operator needs to implement two callbacks in the StateHandler interface: prepareForNonBlockingCheckpoint() and checkpoint().
The timing model for non-blocking checkpointing is illustrated in Figure 1. For comparison, we also put the timing model of blocking checkpointing below in Figure 2.
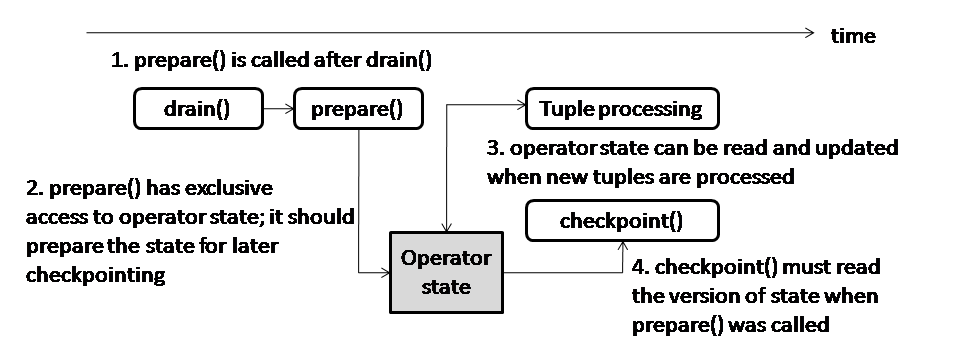
Figure 1: Timing Model for Non-Blocking Checkpointing. Note that prepare() is short for prepareForNonBlockingCheckpoint().
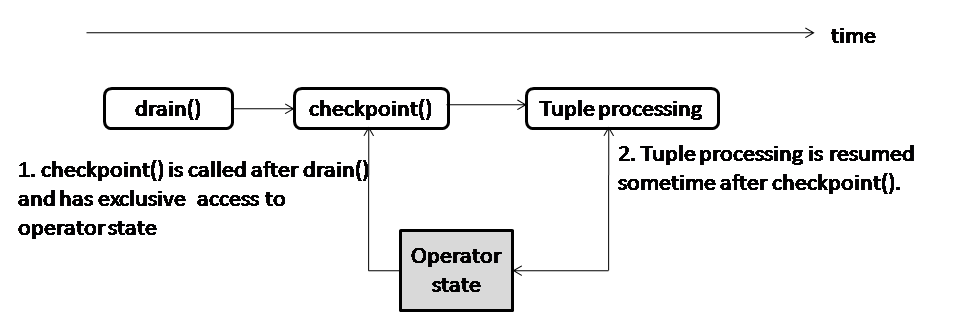
Figure 2: Timing Model for Blocking Checkpointing
Figure 1 shows that an operator is checkpointed in a non-blocking manner in two steps:
Step 1: the operator’s prepareForNonBlockingCheckpoint() callback is invoked by Streams runtime right after the operator’s drain() callback. Within the prepareForNonBlockingCheckpoint() callback, the operator code is guaranteed by the Streams runtime that it has exclusive access to operator’s state. The operator should implement proper logic in this callback to prepare its state so that this version of its state (at this point of time) can be checkpointed later asynchronously while the operator is processing new tuples that arrive after the tuple flow is resumed).
Step 2: the operator’s checkpoint() is called by a background thread after the tuple processing is resumed, meaning that the operator may be processing new tuples while this callback is executed. In the Sheckpoint() callback, the operator should checkpoint the version of its state that was prepared earlier by the prepareForNonBlockingCheckpoint() callback.
Given this two-step model, there are several ways for operator to implement non-blocking checkpointing. Here are some example approaches:
Approach 1 (make a copy of state): The operator can make a copy of its state in its prepareForNonBlockingCheckpoint() callback, and then serialize and checkpoint this copy of state in checkpoint(). Its process() function can directly access and update the original operator state for processing new tuples. Since tuple processing and checkpointing use different copies (and versions) of the operator state, they can proceed concurrently without any synchronization. This approach is easy to implement.
Approach 2 (make a serialized copy of state): Alternatively, the operator can serialize its state into a byte buffer (e.g., SPL::NativeByteBuffer) in its prepareForNonBlockingCheckpoint() callback, and then checkpoint the content of the byte buffer in checkpoint(). Similar to Approach 1, tuple processing and checkpointing use different copies (and versions) of the operator state, so they can proceed concurrently without any synchronization. This approach is also easy to implement, and sample code for this approach can be found in the Streams documentation.
Approach 3 (copy-on-write): Both approaches 1 and 2 require a full extra copy of operator state. The memory consumption may be too high in some cases. One way to avoid full copy is to implement specialized data structures for the operator state to enable user-level copy-on-write. The basic idea is the following: i) The prepareForNonBlockingCheckpoint() callback adds additional bookkeeping information to the data structure to mark that the whole content of the data structure will be under checkpointing (read access). ii) The checkpoint() reads the content of the data structure as it is when prepareForNonBlockingCheckpoint() was called. iii) Operator’s process() may read or update (or way write) the same data structure while processing new tuples; whenever it writes to a portion of the data structure, the internal bookkeeping would make a copy of that portion, and apply the write to the new copy; checkpointing still reads the original copy.
To give a concrete example for the copy-on-write approach, we provide a sample application in the Streams samples github repository. In this application, we implement a C++ class template for an undered map of key-value pairs (modeled after the std::unordered_map). The class template internally track which entries are being checkpointed. When operator’s process() function invokes any of the member functions that would change an entry of the map (e.g., update an entry via iterator), that entry is internally copied so that the update is performed on the new copy, while checkpointing still have valid access to the old copy. Due to space limit, we skip the details and encourage interested reader to directly play with the sample code.
Besides implementing the prepareForNonBlockingCheckpoint() and checkpoint() callbacks, the operator should also call the CheckpointContext::enableNonBlockingCheckpoint() function in its constructor so that the Streams runtime knows the operator enables non-blocking checkpointing.
Operators that are used as the start of consistent regions can implement the regionCheckpointed() callback. This callback is invoked by the Streams runtime once all the operators in the consistent region have been checkpointed. Within the regionCheckpointed() callback function, the start operator can implement logic such as:
– Printing log messages, for example to record that a consistent state was established for the consistent region.
– Cleaning up certain resources, for example purging any buffered input tuples received before this drain, because those tuples were reflected in the persisted state of the consistent region and are no longer needed for replay upon recovery from a failure.
Please note that an operator that does not make use of the new non-blocking checkpointing APIs still works without any code change in Streams 4.2 (as shown in Figure 2), although the tuple flow would resume after the operator finishes checkpointing. In a general, a single consistent region can contain a mix of operators that perform blocking checkpointing, and operators doing non-blocking checkpointing. In such a consistent region, the tuple flow is resumed once the operators that perform blocking checkpointing have finished checkpoint() and the operators that perform non-blocking checkpointing have finished prepareForNonBlockingCheckpoint(). The start operator(s) of the region would be notified via the regionCheckpointed() callback when all the operators have completed checkpoint().
From the Streams Studio, user can monitor the status of a consistent region. Figure 3 is an example snapshot that shows a consistent region is in “CHECKPOINT_PENDING” state, i.e., the tuple flow has be resumed and meanwhile there is ongoing non-blocking checkpointing in the background. In this example, the “MyOp” operator has non-blocking checkpointing enabled, and we put a sleep(10) call in the “MyOp” operator’s checkpoint() callback so that its checkpointing takes a relatively long time (10 seconds). The consistent region is able to resume tuple processing while the “slow” checkpointing is being performed asynchronously in the background.
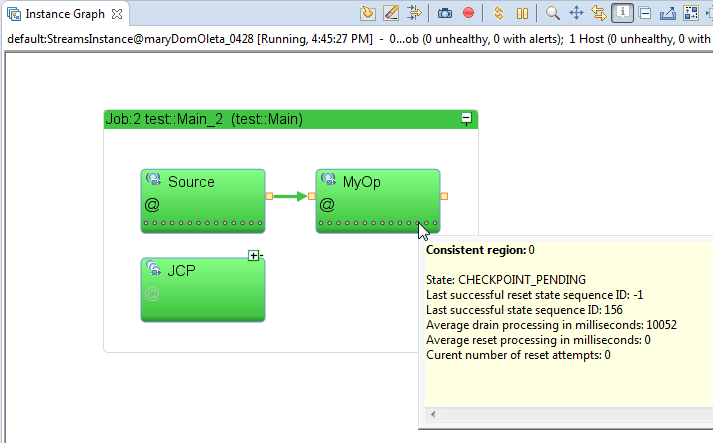
Figure 3: Monitoring Consistent Region’s Non-Blocking Checkpointing from Streams Studio
How well does it perform?
To demonstrate the performance benefit of non-blocking checkpointing, we run a synthetic application that has one source operator sending tuples to a chain of 64 downstream operators. One of the downstream operators maintains a sliding window for incoming tuples. We implement two versions of this operator: (i) the blocking checkpoint version serializes and persists the sliding window in checkpoint(); whereas (ii) the non-blocking checkpoint version makes a copy of the window in prepareForNonBlockingCheckpoint() and persists the copy in the background. We run the application without consistent regions to form a baseline. We then set the whole application in a consistent region and run the blocking and non-blocking checkpoint versions, respectively. We vary the sliding window size but fix the consistent region checkpoint period to 8 seconds. Figure 4 shows the throughputs with blocking and non-blocking checkpoint, both normalized to the same baseline throughput.
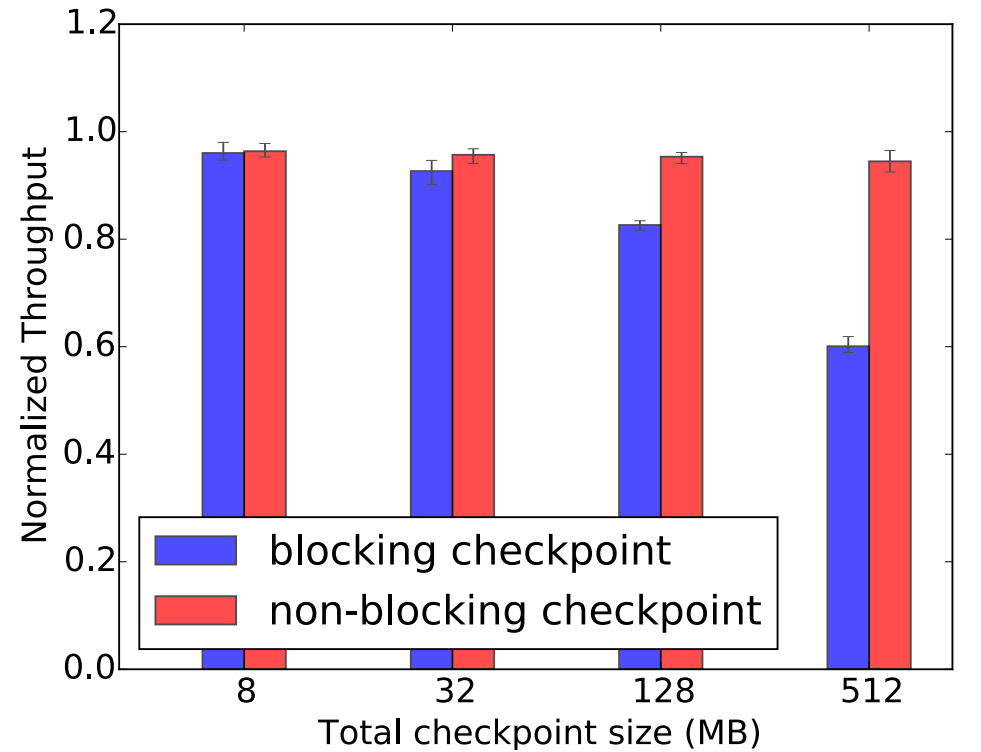
With blocking checkpoint, the throughput degrades more severely with larger checkpoint sizes (from 4% with 8MB checkpoint to 40% with 512MB). This is because the tuple processing is paused until the checkpoint() completes. On the other hand, non-blocking checkpoint resumes tuple processing shortly after prepareForNonBlockingCheckpoint() finishes, and checkpointing occurs asynchronously in the background. As a result, non-blocking checkpoint can sustain high normalized throughput even with large checkpoints (e.g., 94% with 512MB checkpoint).
Summary
In summary, the non-blocking checkpointing APIs enable overlapping checkpointing with tuple processing to reduce the tuple flow blocking time. The non-blocking checkpointing capability, together with the new optimizations in the consistent cut protocol, not only directly reduces checkpointing overheads during normal processing, but also allows applications to afford more frequent checkpointing, which in turn reduces the recovery latency as well.
References
Non-blocking checkpointing in the Knowledge CenterStateHandler C++ interface documentation StateHandler Java interface documentation#CloudPakforDataGroup