Written by Michael Kotowski.
An earlier article described the purpose, use cases, high level architecture, and features of Telecommunications Event Data Analytics, using the following example:
A mobile network has hundreds of network elements that generate call detail records or event data for each phone call, text message, internet activity, or even a simple walk from one location to another. The number of records per day varies between millions and billions. In many cases, the network elements are from different vendors. The typical interface to access these records is file-based.
As a telecommunications provider you want to analyze these records to run campaigns, improve user experience, improve your mobile network or call center, or to detect fraud. You need a system that unifies your source data, runs near real-time analytics, and scales with your increasing network traffic.
Telecommunications Event Data Analytics is not focused on this industry alone. It can be applied to other industries with similar challenging requirements. Telecommunications Event Data Analytics accelerates the development of mediation applications allowing you to focus on your core competencies – your data and your business logic.
In this Getting Started article, we will sketch the typical workflow to setup a mediation application that is able to process large volumes of data and run near real-time analytics. We will configure and customize the application to work with data files in the CSV format. You can then run the application to process data files in CSV format.
The Workflow
Using Telecommunications Event Data Analytics (TEDA), you can quickly setup a mediation application. This application comes with sample code and data that can be immediately processed. You can use this sample implementation to become familiar with TEDA, its application framework and the provided tools. But at the end you want to implement your own application that processes your data and applies your business rules.
Clarify Inputs and Outputs
You want to clarify your inputs and outputs as a first step. It is critical to have a complete understanding of the input data that will be processed and the output data that the application will produce.
Input data considerations
- List input data sources
- For each source you need a specification of the data format. If it is ASN.1 you need the ASN.1 spec, if it is CSV you need to understand the column meaning, etc…
- You need to be able to identify the input type. This could be file names, analysis of the actual data content, etc..
- Do you need to support different versions of the data? (When designing an application the best approach is to assume that this answer is yes and plan for that).
- Sample data is important for validating the application.
- Is the input data valid? If not, you may want to add data validation to the application.
- Does the input data contain duplicates that need to be removed?
Output data considerations
- List the output data required
- Identify how the output data will be structured. Is it files? What are the formats of the output data?
- Which input produces which output?
Determine Analytics
After you have clarified the data sources and results you need to determine what analytics are required for the application. Typical questions are:
- Is it possible that the same input file is sent multiple times to your application? With other words: Do you need file name deduplication?
- Can it happen that the same data record occurs multiple times? With other words: Do you need tuple deduplication?
- Do you want to implement a simple mediation application, or do you also want to integrate some near real-time analytic?
- Do you want to enrich your data records with data from a CRM system or data warehouse?
- How do you get this data from the source system? Either you can access the database tables directly (DB2 and Oracle are supported), or you need the data from the source systems as CSV files.
Use TEDA wizards in Studio to create application
As soon as you have answers to the above questions, you use the Studio wizards that come with TEDA, to create one or more ITE applications, and, if you want to enrich your data records with data from a CRM system or data warehouse, a LM application. Afterwards, you configure and customize your applications iteratively. For example, in a first iteration you add the CSV format support, in a second iteration, you add the ASN.1 format support, in a third iteration you implement record validation and enrichment.
The sample applications
Telecommunications Event Data Analytics (TEDA) provides the teda.demoapp and teda.lookupmgr sample applications that can be imported into Streams Studio. These can help you understand how to construct a TEDA application.
teda.demoapp
This application does the following:
- reads call detail records in 3 different formats
- unifies the schemes
- counts any dropped calls
- tabulates voice minutes per subscriber
- generates events based on thresholds (which can be used as triggers for actions). For example, these could be inputs to a marketing campaign.
- applies some business logic
- writes out 2 types of mediated files. These can be loaded into data base tables.
teda.lookupmgr
This application is used to cyclically update the look-up cache (key-value store, which is stored in shared memory).
Creating, configuring, and customizing an ITE application
For this article, we start building a mediation application that is similar to the teda.demoapp application, but focuses on two customization areas only to give you an impression of how to customize. We prepare the application to support three input formats but implement the CSV format only. The customization areas are:
- Determine the file type and process the file with the correct reader.
- Setup a reader that reads CSV files.
You setup the ITE application using the Streams Studio and the ITE Application Project wizard. For more details on how to configure Telecommunications Event Data Analytics for Streams Studio, please see the IBM Knowledge Center: Configuring Telecommunications Event Data Analytics for Streams Studio.
- Open Streams Studio.
- Select from the menu: File > New > Project… > InfoSphere Streams Telecommunications Event Data Analytics> ITE Application Project..
- Provide the teda.demoapp.intro project name and select variant C. The variants are discussed in more detail in the Knowledge Center.
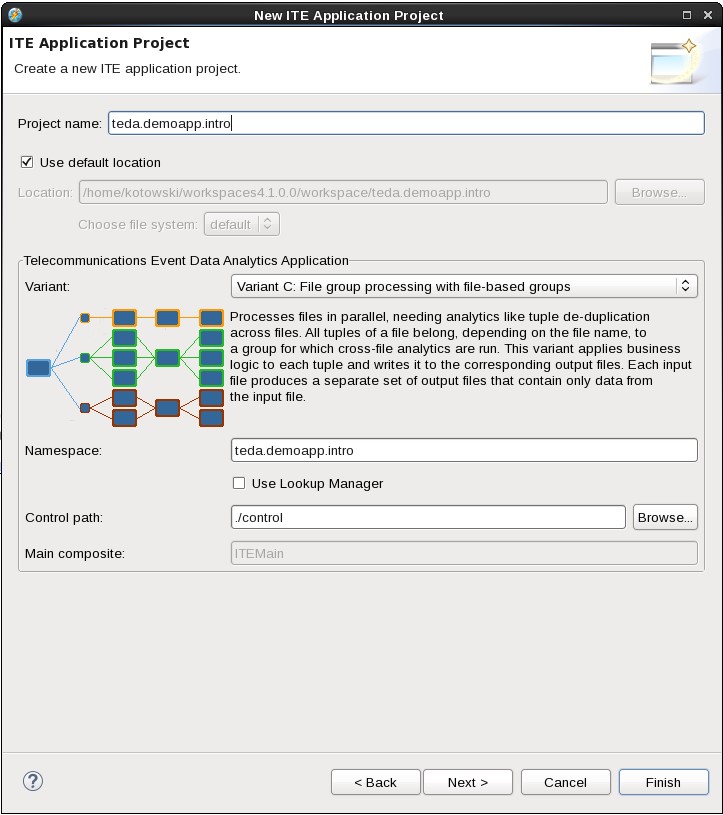
By clicking Finish you create an ITE application that compiles and runs with embedded sample code. In Streams Studio, you see the new project in the Project Explorer view.
Each customization starts with disabling the embedded sample code. Edit the config/config.cfg file in your teda.demoapp.intro project. This configuration file holds all available parameters and detailed descriptions. Typically, if you want to change a setting, you add the parameter assignment below its description.
Insert the following configuration after the description of the parameter to switch off the embedded sample code: ite.embeddedSampleCode=off
# ------------------------------------------------------------------------------
# ite.embeddedSampleCode
#
# Activates sample code in created ITE projects. By default, this parameter is
# enabled (`on`), creating projects with a ready-to-run implementation. When
# coding custom code starts for the custom namespace composites, this parameter
# must be disabled. If you disable the parameter, you must also assign your
# parsers to **ite.ingest.reader.parserList**.
#
# If this parameter is set to `on`, all customized code is disabled.
#
# Properties
# Type: enum
# Default: on
# Cardinality: 0..1
# Provisioning Time: compile-time
# Valid Values: off, on
# Related Parameters:
# Other: ite.businessLogic.group.custom, ite.businessLogic.group.tap, ite.businessLogic.transformation.postprocessing.custom, ite.ingest.customFileTypeValidator, ite.ingest.reader.preprocessing, ite.ingest.reader.schemaExtensionForLookup, ite.storage.auditOutputs, ite.storage.rejectWriter.custom
# ------------------------------------------------------------------------------
ite.embeddedSampleCode=off
The application is prepared to handle three formats: ASN.1, CSV, and fixed-sized structures. The corresponding file name extensions are: .asn, .csv, and .bin. Since this article explains the integration of the CSV format only, you set the ite.ingest.directoryScan.processFilePattern parameter accordingly. The commented line shows the support for all three formats.
# ------------------------------------------------------------------------------
# ite.ingest.directoryScan.processFilePattern
#
# Defines a file name pattern. The directory scanner reports matching file names
# to the following ingestion logic. If file name deduplication is turned on,
# these files are checked to determine whether they have been processed.
# If so, the files are moved to the `duplicate` files folder.
#
# Properties
# Type: string
# Default: ".*\.DAT$"
# Cardinality: 0..1
# Provisioning Time: compile-time
# Valid Values: any value matching the .+ regular expression
# Related Parameters:
# Other: ite.ingest.deduplication
# ------------------------------------------------------------------------------
# ite.ingest.directoryScan.processFilePattern=.*_([0-9]{14})\.asn$|.*_([0-9]{14})\.bin$|.*_([0-9]{14})\.csv$
ite.ingest.directoryScan.processFilePattern=.*_([0-9]{14})\.csv$
Every format (file type) requires another reader, so you specify the ite.ingest.customFileTypeValidator parameter to enable the support for multiple readers and file type verification. Later on, you will customize the FileTypeValidator composite operator, which is mentioned in the detailed parameter description. During this customization, you will assign the upper case file name extension to the fileType SPL attribute. That means, the .asn extension results in the ASN fileType value, .csv in CSV, and .bin in BIN.
# ------------------------------------------------------------------------------
# ite.ingest.customFileTypeValidator
#
# Enables file-type validation. File-type validation distinguishes between
# different file types and data formats, for example CSV or ASN.1. Depending
# on the determined file type, the ITE application sends the file name to
# the appropriate parse logic.
#
# If file-type validation is turned `off`, every file is processed. Only
# one parse logic exists that processes all files.
#
# If the file-type validation is turned `on`, file names are determined to be
# valid or invalid. If a file is invalid, it is not processed but logged as
# invalid and moved to the `invalid` directory, which is a subdirectory of
# the input directory that is specified with the
# **ite.ingest.directory.input** parameter.
#
# If the filename is valid, a unique file type ID is stored in the `fileType`
# SPL output attribute of the <namespace>.fileingestion.custom::FileTypeValidator
# composite operator. As a developer, you want to implement an algorithm that
# validates the file name and determines the file type in the
# <namespace>.fileingestion.custom::FileTypeValidator composite operator.
# To activate your algorithm, set this parameter to `on`. You must also set the
# **ite.embeddedSampleCode** parameter to `off`, so the ITE application
# uses your implementation instead of the sample logic that is provided with the
# <namespace>.fileingestion::SampleFileTypeValidator composite operator.
#
# The unique file type IDs that can occur as a result of your algorithm must be
# consistent with the types that are specified with the **ite.ingest.reader.parserList**
# parameter. Any inconsistency is reported as soon as it occurs, either leading
# to an unhealthy processing element or a log message for this file, depending
# on the **ite.resilienceOptimization** parameter.
#
# The easiest algorithm checks for a file name pattern. A more complicated
# algorithm could read and analyze the file contents.
#
# Properties
# Type: enum
# Default: off
# Cardinality: 0..1
# Provisioning Time: compile-time
# Valid Values: off, on
# Related Parameters:
# Other: ite.embeddedSampleCode, ite.ingest.reader.parserList, ite.resilienceOptimization
# ------------------------------------------------------------------------------
ite.ingest.customFileTypeValidator=on
The next step is to connect a file type (remember: ASN, CSV, BIN) to a corresponding reader. Set the ite.ingest.reader.parserList parameter accordingly. Since this article explains the CSV reader only, also specify the mapping for CSV only. The commented line again shows the support for all three formats.
# ------------------------------------------------------------------------------
# ite.ingest.reader.parserList
#
# Enables one or more parsers and specifies the file type ids for which the
# parsers are responsible.
#
# If you disable the parameter **ite.embeddedSampleCode** to start
# your customizing work, you must immediately assign your parsers to this
# parameter.
#
# Properties
# Type: string
# Default: "*|FileReaderCustom"
# Cardinality: 0..n
# Provisioning Time: compile-time
# Valid Values: comma-separated list of any value matching the \[^|\]+\\|\[A-Z\]\[\\w_\]* regular expression
# ------------------------------------------------------------------------------
# ite.ingest.reader.parserList=ASN|FileReaderCustomASN1,BIN|FileReaderCustomBIN,CSV|FileReaderCustomCSV
ite.ingest.reader.parserList=CSV|FileReaderCustomCSV
The following configuration is required if you want to test the application with the data files that are provided with the teda.demoapp application. Change the ite.ingest.fileGroupSplit.pattern parameter value, so it suits the file names of the teda.demoapp application.
# ------------------------------------------------------------------------------
# ite.ingest.fileGroupSplit.pattern
#
# Defines a regular expression that extracts the group ID from the file name.
# The expression must have exactly one group (a pair of parentheses), which
# isolates the group ID from the rest of the file name. If the file name does
# not match the pattern, it is assigned to the `default` group. The group
# configuration is defined in the group configuration file that is specified
# in the **ite.ingest.loadDistribution.groupConfigFile** parameter.
#
# If the **ite.ingest.fileGroupSplit** parameter is set to `on`, this
# parameter is required.
#
# Properties
# Type: string
# Cardinality: 0..1
# Provisioning Time: compile-time
# Valid Values: any value matching the .+ regular expression
# Related Parameters:
# Parent: ite.ingest.fileGroupSplit
# Other: ite.ingest.loadDistribution.groupConfigFile
# ------------------------------------------------------------------------------
ite.ingest.fileGroupSplit.pattern=^.*_RGN([0-9]+)_
The configuration steps are done. The next steps are to customize the FileTypeValidator composite operator and to provide the FileReaderCustomCSV operator. The FileReaderCustomASN1 and FileReaderCustomBIN are not discussed in this article but can be implemented in a similar way as the FileReaderCustomCSV operator.
Open the teda.demoapp.intro.fileingestion.custom::FileTypeValidator composite operator and replace the operator implementation with the following code. The FileTypeValidator is responsible to determine a file type. This can often be done using the file names or their extension. In this case, we map the extensions to their upper case counterpart. Since the file name patterns that are specified with the ite.ingest.directoryScan.processFilePattern parameter, already ensure that each filename has a valid extension, there is no need to send tuples to the output port for invalid file names.
public composite FileTypeValidator
(
input
stream<ProcessFileInfo> FilesIn;
output
stream<ProcessFileInfo> FileOut,
stream<ProcessFileInfo> InvalidOut
)
{
graph
(
stream<ProcessFileInfo> FileOut;
stream<ProcessFileInfo> InvalidOut
) as FileTypePrepare = Custom(FilesIn as FileIn)
{
logic
onTuple FileIn:
{
// The file name pattern that is specified with the
// ite.ingest.directoryScan.processFilePattern parameter,
// ensures that each incoming file name has an extension,
// which is either .asn, .csv, or .bin.
// The extension is used to build the value for the
// fileType attribute, which can be: ASN, CSV, or BIN.
FileIn.fileType = upper(substring(FileIn.filenameOnly, length(FileIn.filenameOnly) - 3, 3));
submit(FileIn, FileOut);
}
onPunct FileIn:
{
if (currentPunct() == Sys.WindowMarker) submit(Sys.WindowMarker, FileOut);
}
}
}
The teda.demoapp sample application processes three input formats but produces one output format only. For each input format, a mapping to the output schema has to be defined as well as the output schema itself. A similar procedure is required for the teda.demoapp.intro application.
Open the teda.demoapp.intro.streams.custom/TypesCustom.spl file. Here you add the following type definition, which is the common schema to which all input formats shall be mapped.
/**
* Unique message schema after reading from file.
* Independent from file format (ASN1 / BIN)
*/
static MobileSampleMsgFlat = tuple
<
uint8 cdrRecordType, /* 01 */
uint64 cdrRecordNumber, /* 02 */
rstring cdrCallReference, /* 03 */
rstring cdrCallingImsi, /* 04 */
rstring cdrCallingImei, /* 05 */
rstring cdrCallingNumber, /* 06 */
rstring cdrCalledImsi, /* 07 */
rstring cdrCalledImei, /* 08 */
uint8 cdrCalledNumberTon, /* 09 */
uint8 cdrCalledNumberNpi, /* 10 */
rstring cdrCalledNumber, /* 11 */
rstring cdrCallingSubsFirstLac, /* 12 */
rstring cdrCallingSubsFirstCi, /* 13 */
rstring cdrCauseForTermination, /* 14 */
uint8 cdrCallType, /* 15 */
uint64 cdrSamMczDuration, /* 16 */
uint8 cdrCallingNumberTon, /* 17 */
uint8 cdrCallingNumberNpi, /* 18 */
rstring cdrCallReferenceTime, /* 19 */
uint64 cdrCallingSubsFirstMcc /* 20 */
>;
Open the teda.demoapp.intro.streams.custom/ReaderTypes.spl file and set the ReaderRecordType alias to the just defined common schema.
/**
* ReaderRecordType
* This stream type is used in FileReader and contains custom record stream attributes.
*/
type ReaderRecordType = TypesCustom.MobileSampleMsgFlat;
The next step is to setup the FileReaderCustomCSV composite operator. Go to the teda.demoapp.intro.chainprocessor.reader.custom namespace. Either copy the FileReaderCustom.spl template file or create your own FileReaderCustomCSV composite operator with the following content:
namespace teda.demoapp.intro.chainprocessor.reader.custom;
use teda.demoapp.intro.chainprocessor.reader::FileReaderCSV;
use teda.demoapp.intro.streams::*;
use teda.demoapp.intro.streams.custom::*;
public composite FileReaderCustomCSV
(
input
stream<TypesCommon.FileIngestSchema> FileIn;
output
stream<TypesCommon.ReaderOutStreamType> ReaderRec,
stream<TypesCommon.ParserStatisticsStream> ReaderStat
)
{
param
expression<rstring> $groupId;
expression<rstring> $chainId;
graph
(
stream<TypesCommon.ReaderOutStreamType> ReaderRec;
stream<TypesCommon.ParserStatisticsStream> ReaderStat
) = FileReaderCSV(FileIn as IN)
{
param
groupId : $groupId;
chainId : $chainId;
parserRecordOutputType: TypesCustom.MobileSampleMsgFlat;
mappingDocument: "etc/demo_csv_mapping.xml";
}
}
For the built-in ASN.1, CSV, and fixed-sized structure formats, TEDA provides composite operators that can be used within your custom code. You can override the default values for certain parameters. For example, for the CSV format, you specify the parserRecordOutputType and the mappingDocument. Other parameters that can be overridden are the separator, ignoreEmptyLines, ignoreHeaderLines, quoted, and eolMarker parameters. For the ASN.1 and fixed-size structure formats, you use another set of parameters.
Create the etc/demo_csv_mapping.xml document with the following content, which is taken from the teda.demoapp sample application. The format of the mapping document is described in the CSVParse operator description.
<mappings xmlns="http://www.ibm.com/software/data/infosphere/streams/csvparser">
<!-- this mapping is applied if the first CSV field contains the string "1", the CSV line must have at least 20 fields -->
<mapping name="voice" filterIndex="0" filterValue="1" itemCountMin="20">
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
<assign/>
</mapping>
<!-- this mapping is applied if the first CSV field contains the string "2", the CSV line must have at least 15 fields -->
<mapping name="sms" filterIndex="0" filterValue="2" itemCountMin="15">
<assign attribute="cdrRecordType" index="0"/>
<assign attribute="cdrRecordNumber" index="1"/>
<assign attribute="cdrCallReference" index="2"/>
<assign attribute="cdrCallingImsi" index="3"/>
<assign attribute="cdrCallingImei" index="4"/>
<assign attribute="cdrCallingNumber" index="5"/>
<assign attribute="cdrCalledNumberTon" index="6"/>
<assign attribute="cdrCalledNumberNpi" index="7"/>
<assign attribute="cdrCalledNumber" index="8"/>
<assign attribute="cdrCallingSubsFirstCi" index="9"/>
<assign attribute="cdrCauseForTermination" index="10"/>
<assign attribute="cdrCallType" index="11"/>
<assign attribute="cdrCallingNumberTon" index="12"/>
<assign attribute="cdrCallingNumberNpi" index="13"/>
<assign attribute="cdrCallReferenceTime" index="14"/>
</mapping>
</mappings>
The final required step is related to the enabled tuple de-duplication. The tuple de-duplication requires a hash value, which is calculated from the attributes that uniquely identify a record. Open the teda.demoapp.intro.chainprocessor.transformer.custom::DataProcessor composite operator and replace the graph with the following content:
(
stream<TypesCommon.TransformerOutType> OutRec as OutData;
stream<TypesCommon.FileStatistics> OutStat;
stream<TypesCommon.RejectedDataStreamType> OutRej;
stream<TypesCommon.BundledTransformerOutputStreamType> OutTap // use only if ite.businessLogic.transformation.tap=on
) as TransformerOut = Custom(InRec as IN; InStat)
{
logic
state:
{
// For best performance, declare tuple variables once.
mutable OutRec otuple = {};
}
onTuple IN:
{
// Assign input attributes to output attributes that have the
// same and type.
assignFrom(otuple, IN);
// For the tuple deduplication, we need a hash value from
// input attributes that uniquely identify a record.
otuple.hashcode = sha2hash160((rstring) cdrRecordNumber + cdrCallingNumber + cdrCalledNumber + cdrCallReferenceTime);
// Submit the enriched tuple.
submit(otuple, OutData);
}
onTuple InStat:
{
submit(InStat,OutStat);
}
onPunct IN:
{
if (currentPunct() == Sys.WindowMarker)
{
submit(Sys.WindowMarker, OutRec);
submit(Sys.WindowMarker, OutRej);
submit(Sys.WindowMarker, OutTap);
}
}
}
You are done. You can now build, run, and monitor the application. As soon as it is started, you can move the data files from the teda.demoapp application to the input directory of your application.
For more details about the
Summary:
- Using a Studio wizard, you create a mediation application with sample code.
- To start the customization, you disable the embedded sample code.
- To prepare the ITE application to handle three different input formats, you specify the file name patterns, enable the support for multiple readers, modify an SPL composite operator that maps the input file names to a fixed set of file type ids, and specify the connection between file type ids and SPL composite operators. Finally, you specify a common SPL schema.
- For each input format you provide an SPL composite operator that reads input files, and decodes or parses the content. For the built-in formats ASN.1, CSV, and fixed-size structure, you can reuse the already prepared composite operator that you can parametrize.
For ASN.1, you provide an ASN.1 specification.
For fixed-size structures, you provide a structure definition and a mapping document.
For CSV, you provide a mapping document.
- Because of the enabled tuple deduplication, a minimal implementation in the business rules section (DataProcessor composite operator) is required.
- Run the mediation application.
Conclusion
With few steps (5 parameters, 2 type definitions, 1 mapping document, 3 simple composite operators) we created a mediation application that can process CSV files, generates an output file with a unified format for each input file, and produces statistics. With few more steps, you can integrate the support for ASN.1 and fixed-size structure support. Further enhancements are done in a similar way: You set configuration parameters to enable, disable, or configure features. You implement code snippets in already prepared SPL composite operators. You can do these steps in iterations.
For sure, you must be aware of the built-in features and the areas, to which you can apply your own algorithms. For the customization of the ITE application, it is recommended to be familiar with the customizable composites and stream type, for which you can find an overview figure at Reference > Toolkits > SPL standard and specialized toolkits > com.ibm.streams.teda > Developing applications > Customizing applications > Customizing the ITE application > Customizable composite operators and their inputs and outputs.
Next Steps
After running this sample, you can follow the detailed TEDA tutorial to learn how to develop your own TEDA-based applications. The tutorial describes the required configuration and customization to setup a mediation application that is identical to the
teda.demoapp and
teda.lookupmgr applications.
Follow the TEDA tutorial.#CloudPakforDataGroup