Tutorial
Backing up etcd data from a Red Hat OpenShift Container Platform cluster to IBM Cloud Object Storage
Learn how to back up your cluster’s etcd data regularly and store in a secure location outside the OpenShift Container Platform environmentIntroduction
Back up and restore refers to the process of creating and storing copies of data that can be used to protect your cluster against data loss. When you work on Red Hat® OpenShift® Container Platform, in case the cluster goes into an unrecoverable state, you will need a backup to go back to the previous stable state of the cluster. It is a good practice to back up your cluster's etcd data regularly and store it in a secure location ideally outside the OpenShift Container Platform environment, say, on IBM® Cloud Object Storage. Later, you can use the previously backed up etcd snapshot in order to restore the cluster state.
This tutorial explains the procedure to perform the backup and restore operation of etcd data on your OpenShift Container Platform cluster to or from IBM Cloud Object Storage.
Prerequisites
Before beginning to perform the backup or restore operation of etcd data on your OpenShift Container Platform cluster, you need to make sure that the following prerequisites are fulfilled:
A running OpenShift Container Platform 4.x cluster on IBM Power Systems™
Access to the OpenShift cluster as a user with the cluster-admin role
Proxy details for the OpenShift cluster
Make a note of the proxy details of the OpenShift cluster by running the following commands on the bastion host or from any other host having CLI ( oc ) access to the OpenShift cluster.
Get the configured HTTP proxy.
echo "export HTTP_PROXY=$(oc get proxy/cluster -o template --template {{.spec.httpProxy}})" >> proxy-envGet the configured HTTPS proxy.
echo "export HTTPS_PROXY=$(oc get proxy/cluster -o template --template {{.spec.httpsProxy}})" >> proxy-envGet the
noProxysettings.echo "export NO_PROXY=$(oc get proxy/cluster -o template --template {{.spec.noProxy}})" >> proxy-env
The following output shows the cluster settings used for this tutorial.
$ cat proxy-env export HTTP_PROXY=http://mjulie-ocp461-t1-6640-bastion-0:3128 export HTTPS_PROXY=http://mjulie-ocp461-t1-6640-bastion-0:3128 export NO_PROXY=.mjulie-ocp461-t1-6640.ibm.com,192.168.26.0/24IBM Cloud API Key Refer to the following documentation to create an API key: https://cloud.ibm.com/docs/account?topic=account-userapikey
An instance of Cloud Object Storage Refer to the following instructions at: https://cloud.ibm.com/docs/cloud-object-storage?topic=cloud-object-storage-getting-started-cloud-object-storage
Estimate time
The approximate time to complete the backup/restore operation on an OpenShift Container Platform cluster is around 30 minutes.
Back up etcd data
etcd is the key-value store for OpenShift Container Platform, which persists the state of all resource objects. Perform the following steps to back up etcd data by creating an etcd snapshot and backing up the resources for the static pods.
Note: Save a backup only from a single master host. Do not create a backup from each master host in the cluster.
Run the following command on the bastion host or from any other host having CLI (
oc) access to the OpenShift cluster.oc debug node/master-0You would see an output similar to the following example.
Creating debug namespace/openshift-debug-node-4j6rn ... Starting pod/master-0-debug ... To use host binaries, run `chroot /host` Pod IP: 192.168.26.139 If you don't see a command prompt, try pressing enter. sh-4.4#Run the
chroot /hostcommand on the shell so that we can run host binaries.sh-4.4# chroot /hostRun the cluster-backup.sh script and specify the location to save the backup.
sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/dec-11-2020 a2cd2ee5a65e79db098cdf8c02a15d62a01e3e248ffefa933da207f67b3dc125 etcdctl version: 3.4.9 API version: 3.4 found latest kube-apiserver-pod: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-15 found latest kube-controller-manager-pod: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-6 found latest kube-scheduler-pod: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-7 found latest etcd-pod: /etc/kubernetes/static-pod-resources/etcd-pod-4 {"level":"info","ts":1607688398.3691008,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/dec-11-2020/snapshot_2020-12-11_120637.db.part"} {"level":"info","ts":"2020-12-11T12:06:38.382Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1607688398.3829315,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://192.168.26.139:2379"} {"level":"info","ts":"2020-12-11T12:06:41.466Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1607688401.5957787,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://192.168.26.139:2379","size":"194 MB","took":3.226621037} {"level":"info","ts":1607688401.5960164,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/dec-11-2020/snapshot_2020-12-11_120637.db"} Snapshot saved at /home/core/dec-11-2020/snapshot_2020-12-11_120637.db snapshot db and kube resources are successfully saved to /home/core/dec-11-2020 sh-4.4#In this example, the following two files are created under /home/core/dec-11-2020 on the master host.
snapshot_<datetimestamp>.db: This file is the etcd snapshot.
static_kuberesources_<datetimestamp>.tar.gz: This file contains the resources for the static pods. If etcd encryption is enabled, it also contains the encryption keys for the etcd snapshot.
The following output shows the files created under the /home/core/dec-11-2020 directory.
sh-4.4# ls -l /home/core/dec-11-2020 total 189320 -rw-------. 1 root root 193789984 Dec 11 12:06 snapshot_2020-12-11_120637.db -rw-------. 1 root root 69279 Dec 11 12:06 static_kuberesources_2020-12-11_120637.tar.gz sh-4.4# tar czvf dec-11-2020.tar.gz dec-11-2020/ dec-11-2020/ dec-11-2020/static_kuberesources_2020-12-11_120637.tar.gz dec-11-2020/snapshot_2020-12-11_120637.db sh-4.4# ls -l /home/core/ total 26964 drwxr-xr-x. 3 root root 31 Nov 10 10:13 assets drwxr-xr-x. 2 root root 123 Dec 7 17:48 backup-nov9 drwxr-xr-x. 2 root root 96 Dec 11 12:06 dec-11-2020 -rw-r--r--. 1 root root 27595315 Dec 11 12:15 dec-11-2020.tar.gz -rw-r-----. 1 core core 12209 Nov 10 14:45 kubeconfig
Upload the backup data to IBM Cloud Object Storage
The next set of steps show how to upload the backed up data to IBM Cloud Object Storage.
The commands are run from the container shell. If you are not in the container shell, just re-run the following command:
oc debug node/master-0
Run the following commands to upload the backup tar.gz file to IBM Cloud.
sh-4.4# export HTTPS_PROXY=http://mjulie-ocp461-t1-6640-bastion-0:3128 sh-4.4# export APIKEY="<IBM_CLOUD_API_KEY>" sh-4.4# TOKEN=$(curl -X "POST" "https://iam.cloud.ibm.com/oidc/token" -H "Accept: application/json" -H "Content-Type: application/x-www-form-urlencoded" --data-urlencode "apikey=$APIKEY" --ata-urlencode "response_type=cloud_iam" --data-urlencode "grant_type=urn:ibm:params:oauth:grant-type:apikey" | jq .access_token) % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 2679 100 2544 100 135 9284 492 --:--:-- --:--:-- --:--:-- 9777 sh-4.4# ACCESSTOKEN=$(eval $TOKEN) sh-4.4# export FILENAME=/home/core/dec-11-2020.tar.gz sh-4.4# export ENDPOINT=s3.us-south.cloud-object-storage.appdomain.cloud sh-4.4# export BUCKET=bucket-validation-team sh-4.4# export OBJKEY=dec-11-2020.tar.gz sh-4.4# curl -X "PUT" "https://$ENDPOINT/$BUCKET/$OBJKEY" -H "Authorization: bearer $ACCESSTOKEN" -H "Content-Type: file" -F "file=@$FILENAME"If there are no errors, then it means that the backup is successfully copied to IBM Cloud Object Storage.
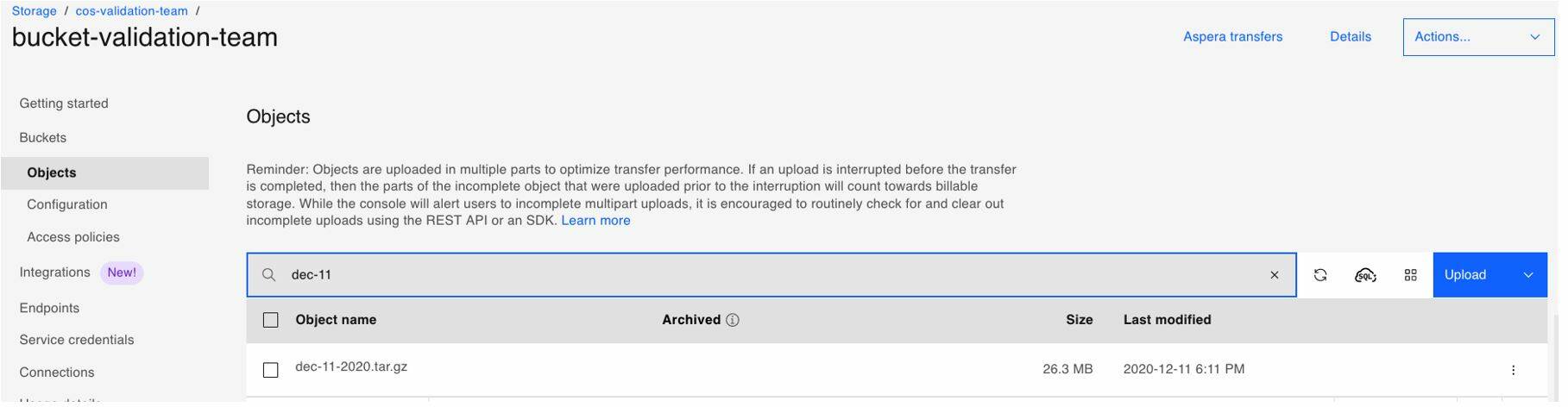
Log in to the IBM Cloud console and navigate to your instance of Cloud Object Storage to verify the uploaded files. Figure 1 shows the backed up files in the Cloud Object Storage bucket.
Figure 1: Backed up data in Cloud Object Storage
 View a larger version of this figure
View a larger version of this figureNote: You can create a backup of the etcd data on your cluster on a scheduled basis with the help of cronjob and upload it to IBM Cloud Object storage.
For example, refer to the following repo: https://github.com/ocp-power-demos/openshift-backup
Restore the cluster using the backup data
Use a saved etcd backup to restore a single control plane host to its previous state. Then the etcd cluster operator handles scaling to the remaining master hosts.
Before beginning to perform the restore operation of etcd data on your OpenShift Container Platform cluster, you need to make sure that the following prerequisites are fulfilled:
Download the back up files from IBM Cloud Object Storage instance on to the bastion (helper) node of your OpenShift Container Platform cluster
Use Secure Shell (SSH) to access the master nodes on the OpenShift Container Platform cluster
Perform the following steps to complete the restore operation:
Select a control plane host to use as the recovery host.
Note: In this example, master-0 is used as the recovery host, master-1 and master-2 are the other two control plane hosts.
Establish an SSH connectivity to each of the control plane nodes, including the recovery host.
Use the SCP (secure copy) command-line utility to securely copy the backup file from the bastion (helper) node on to the recovery control plane host (for example, master-0). Extract the .tar file and you should see two files in the formats: snapshot_
.db and static_kuberesources_.tar.gz .[core@master-0 ~]$ tar zxvf dec-11-2020.tar.gz dec-11-2020/ dec-11-2020/static_kuberesources_2020-12-11_120637.tar.gz dec-11-2020/snapshot_2020-12-11_120637.dbStop the static pods on all other control plane nodes.
Access a control plane host that is not the recovery host (for example, master-1).
Move the existing etcd pod file out of the kubelet manifest directory.
sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmpVerify that the etcd pods are stopped.
sudo crictl ps | grep etcdThe output of this command should be empty. If not, wait for a few minutes and check again.
Move the existing Kubernetes API server pod file out of the kubelet manifest directory:
sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpVerify that the Kubernetes API server pods are stopped.
sudo crictl ps | grep kube-apiserverMove the etcd data directory to a different location.
sudo mv /var/lib/etcd/ /tmpRepeat this step on each of the other two control plane hosts (master-1 and master-2).
Connect to the recovery control plane host (for example, master-0) using SSH.
Set the
NO_PROXY,HTTP_PROXY,HTTPS_PROXYenvironment variables from the values saved earlier (in file proxy-env).Run the restore script on the recovery control plane host and pass in the path to the directory with the backup files.
sudo -E /usr/local/bin/cluster-restore.sh /home/core/dec-11-2020Restart the kubelet service on all master hosts.
Connect to all the master hosts using SSH and run the following command:
sudo systemctl restart kubelet.serviceVerify that the single member control plane has started successfully.
From the recovery host, verify that the etcd container is running.
sudo crictl ps | grep etcdFrom the recovery host, verify that the etcd pod is running.
oc get pods -n openshift-etcd | grep etcd
Force etcd redeployment by running the following command on the bastion node.
oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeNote:
- The
forceRedeploymentReasonvalue must be unique, which is why a timestamp is appended. - When the etcd cluster operator performs a redeployment, the existing nodes are started with new pods similar to the initial bootstrap scale up.
- The
Verify that all nodes are updated to the latest revision.
oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Note:
Review the
NodeInstallerProgressingstatus condition for etcd to verify that all nodes are at the latest revision. After a successful update, the output showsAllNodesAtLatestRevision.After etcd is redeployed, force new rollouts for the control plane. The Kubernetes API server will reinstall itself on the other nodes because the kubelet is connected to API servers using an internal load balancer.
In a terminal that has access to the cluster as a cluster-admin user, say, on the bastion node, perform the following steps:
Update the
kubeapiservercomponent in the master node.oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVerify that all nodes are updated to the latest revision.
oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Note:
Review the
NodeInstallerProgressingstatus to verify that all nodes are at the latest revision. After a successful update, the output showsAllNodesAtLatestRevision.Update the
kubecontrollermanagercomponent in the master node.oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVerify that all nodes are updated to the latest revision.
oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Note:
Review the
NodeInstallerProgressingstatus to verify that all nodes are at the latest revision. After a successful update, the output showsAllNodesAtLatestRevision.Update the
kubeschedulercomponent in the master node.oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVerify that all the nodes are updated to the latest revision.
oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Note:
Review the
NodeInstallerProgressingstatus to verify that all nodes are at the latest revision. After a successful update, the output showsAllNodesAtLatestRevision.
Verify that all master hosts have started and joined the cluster.
On the bastion node, run the following command:
oc get pods -n openshift-etcd | grep etcdCheck the status of all nodes, cluster operators, and pods to make sure that everything is working fine.
oc get nodes oc get co oc get pods --all-namespaces
Summary
It is a good practice to back up your cluster's etcd data regularly and store in a secure location, ideally outside the OpenShift Container Platform environment. This tutorial shows how you can save the backup data in IBM Cloud Object Storage and use the same for recovery if needed.