Tutorial
Build a recurrent neural network using Pytorch
Learn the basics of how to build an RNN by using a Jupyter Notebook written in Python, IBM Watson Studio, and IBM Cloud Pak for DataArchive date: 2023-05-15
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Deep learning is vast field that employs artificial neural networks to process data and train a machine learning model. Within deep learning, two learning approaches are used, supervised and unsupervised. This tutorial focuses on recurrent neural networks (RNN), which use supervised deep learning and sequential learning to develop a model. This deep learning technique is especially useful when handling time series data, as is used in this tutorial.
When creating any machine learning model, it's important to understand the data that you're analyzing so that you can use the most relevant model architecture. In this tutorial, the goal is to create a basic model that can predict a stock's value using daily Open, High, Low, and Close values. Because the stock market can be extremely volatile, there are many factors that can influence and contribute to a stock's value. This tutorial uses the following parameters for the stock data.
Open: The stock's price when the market opens.
High: The highest price at which a stock is trading during market hours.
Low: The lowest price at which a stock is trading during market hours.
Close: The stock's price when the market closes. This price is used by financial institutions as the value of a stock on a particular day because it takes into consideration all of the day's events and any fluctuations that might have occurred during the market.
The overall importance of the Close value and its use as a benchmark for a stock's daily value indicates that this value is the one to use in the prediction. To accomplish this, you can build a model that uses long short-term memory (LSTM), an RNN technique, to store and analyze larger sets of time series data.
This tutorial uses stock market data that is collected by IBM Watson and deployed on IBM Watson Studio on IBM Cloud Pak for Data.
Learning objectives
In the tutorial, you import a Jupyter Notebook that is written in Python into IBM Watson Studio on IBM Cloud Pak for Data, then run through the Notebook. The Notebook creates an RNN using PyTorch and uses stock market data from IBM Watson. After running the Notebook, you should understand the basics of how to build an RNN. You'll learn how to:
- Run a Jupyter Notebook using Watson Studio on IBM Cloud Pak for Data
- Build an RNN using PyTorch
- Train and evaluate the model by performing validation and testing
Prerequisites
To follow this tutorial, you need:
- An account on a cloud platform. This tutorial uses an IBM Cloud account.
- IBM Cloud Pak for Data.
Estimated time
It should take you approximately 1 hour complete the tutorial.
Steps
- Set up IBM Cloud Pak for Data.
- Create a new project and import the Notebook.
- Import the stock data CSV file to your newly imported Notebook.
- Read through the Notebook.
- Run the Notebook.
Set up IBM Cloud Pak for Data
Open a browser, and log in to IBM Cloud with your IBM Cloud credentials.
Enter
Watson Studioin the search bar. If you already have an instance of Watson Studio, it should be visible. If so, select it. If not, click Watson Studio under the Catalog results to create a new service instance.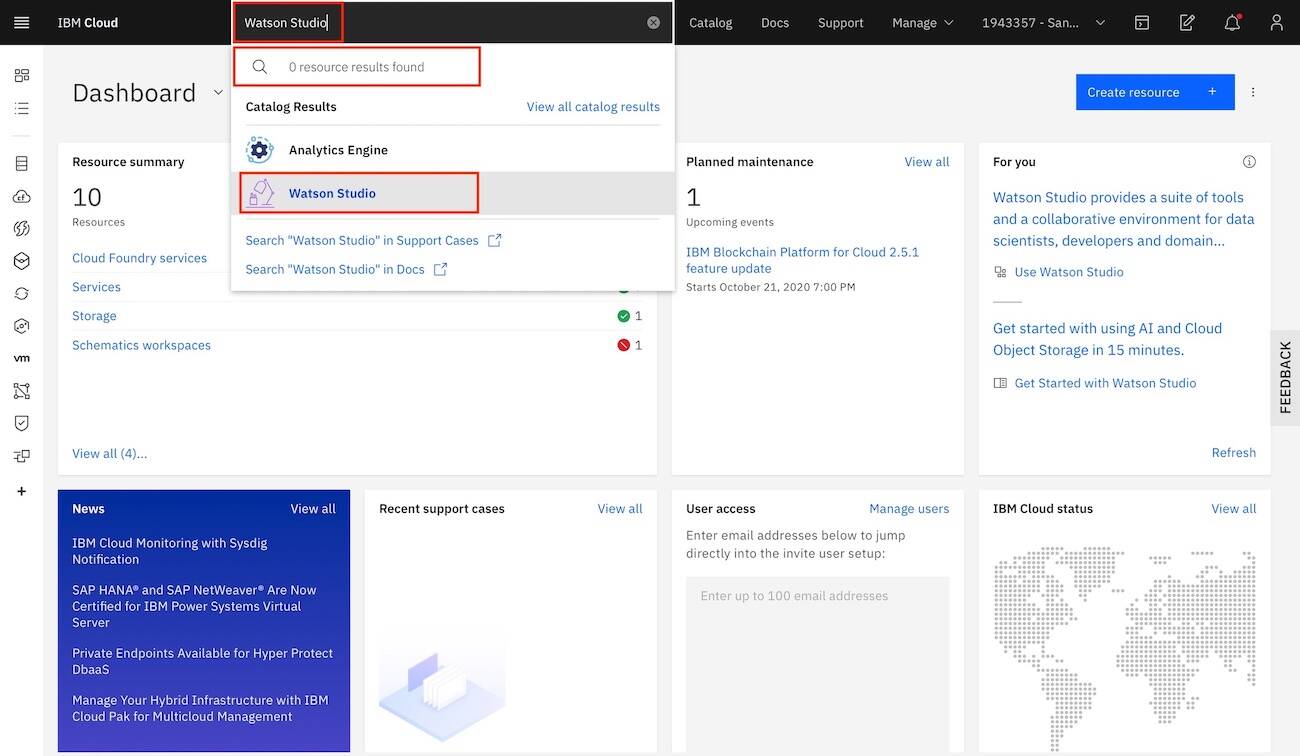
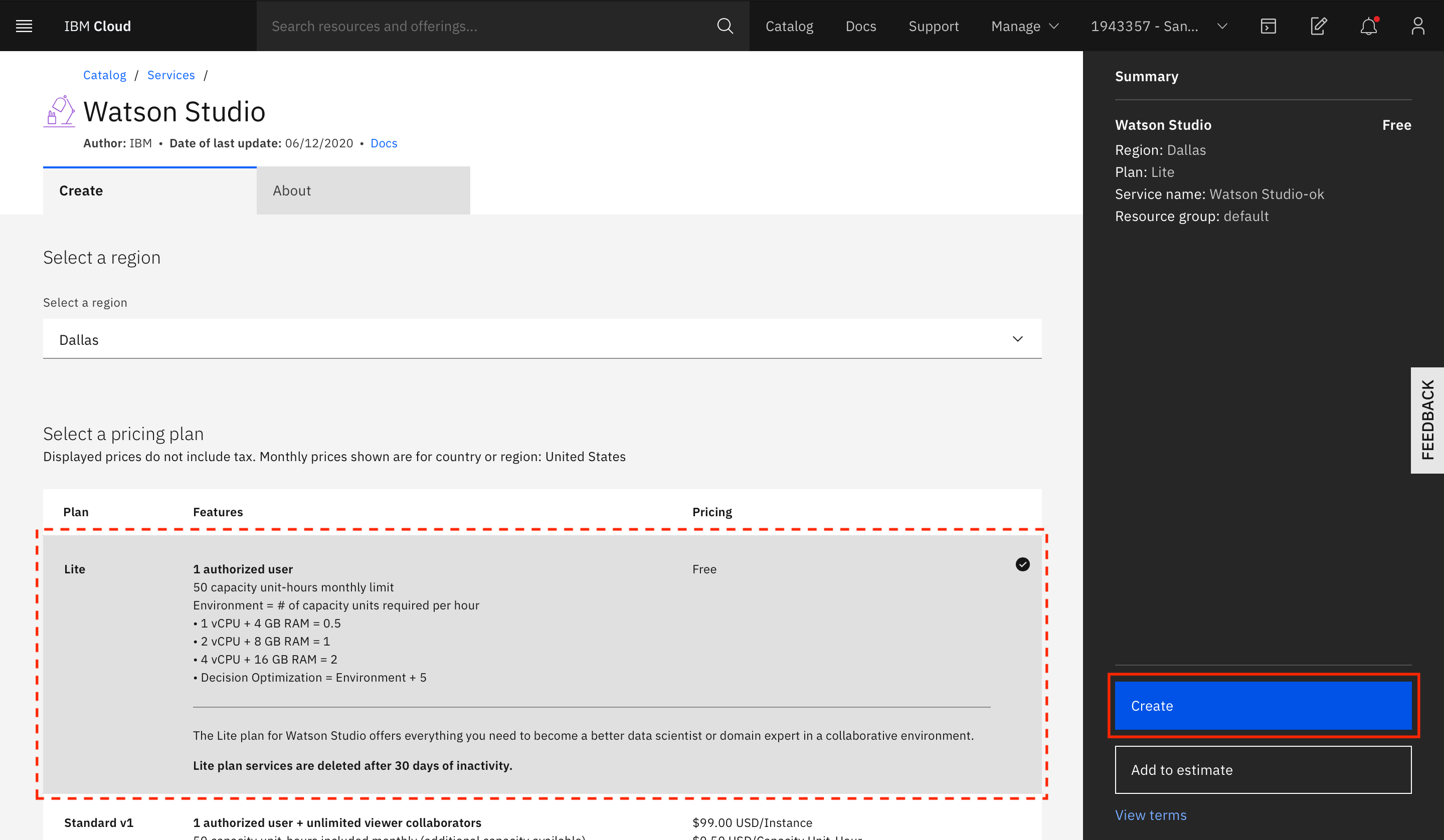
Select the type of plan to create if you are creating a new service instance, and click Create.
Click Get Started.
This takes you to the landing page for IBM Cloud Pak for Data.
Click your avatar in the upper right, then click Profile and settings under your name.
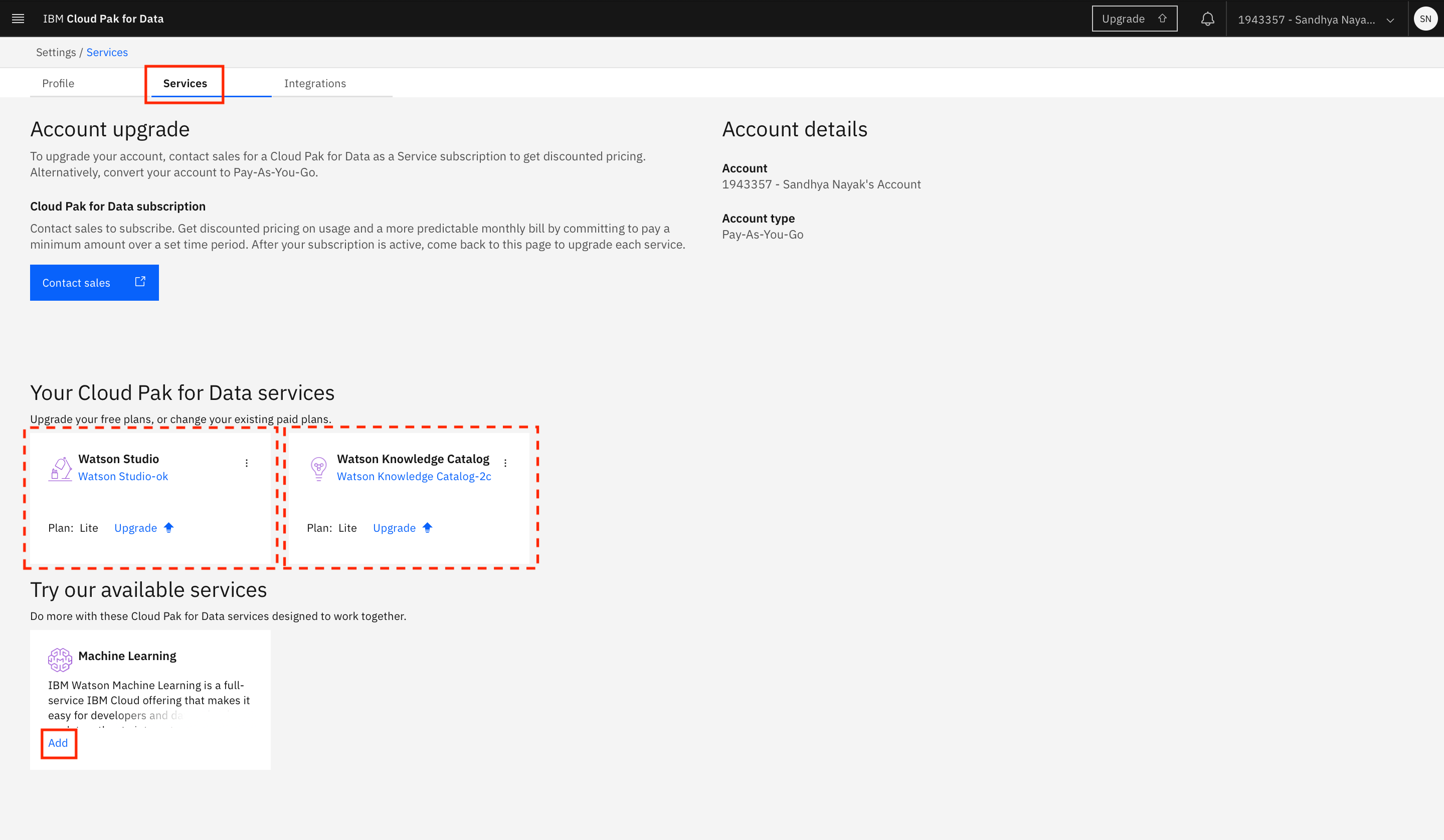
Switch to the Services tab. You should see the Watson Studio service instance listed under Your Cloud Pak for Data services.
You can also associate other services such as Watson Knowledge Catalog and Watson Machine Learning with your IBM Cloud Pak for Data account. These are listed under Try our available services.
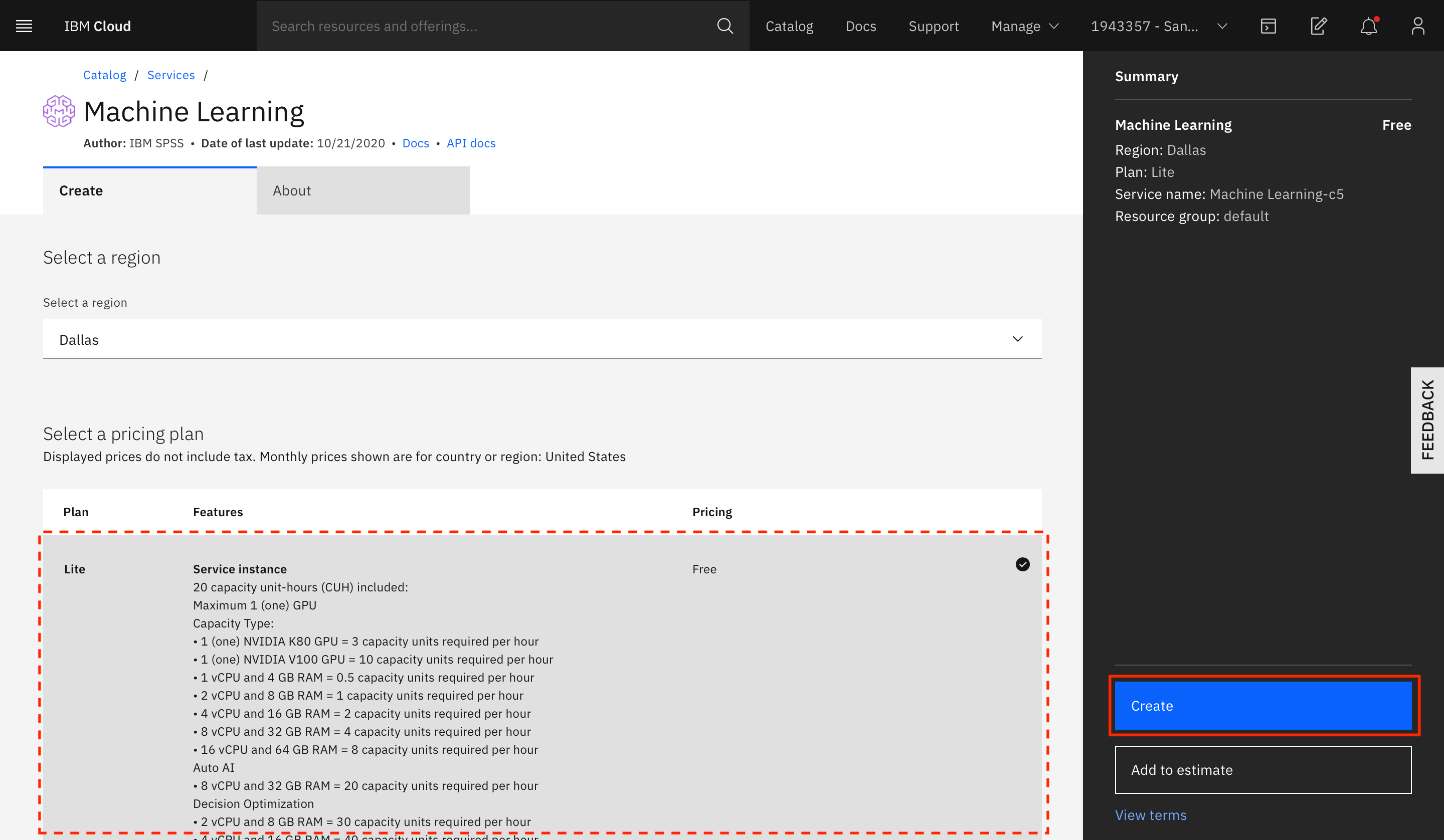
In the example shown below, a Watson Knowledge Catalog service instance exists in the IBM Cloud account, so it's automatically associated with the IBM Cloud Pak for Data account. To add any other service (Watson Machine Learning in this example), click Add within the tile for the service under Try our available services.
Select the type of plan to create, and click Create.
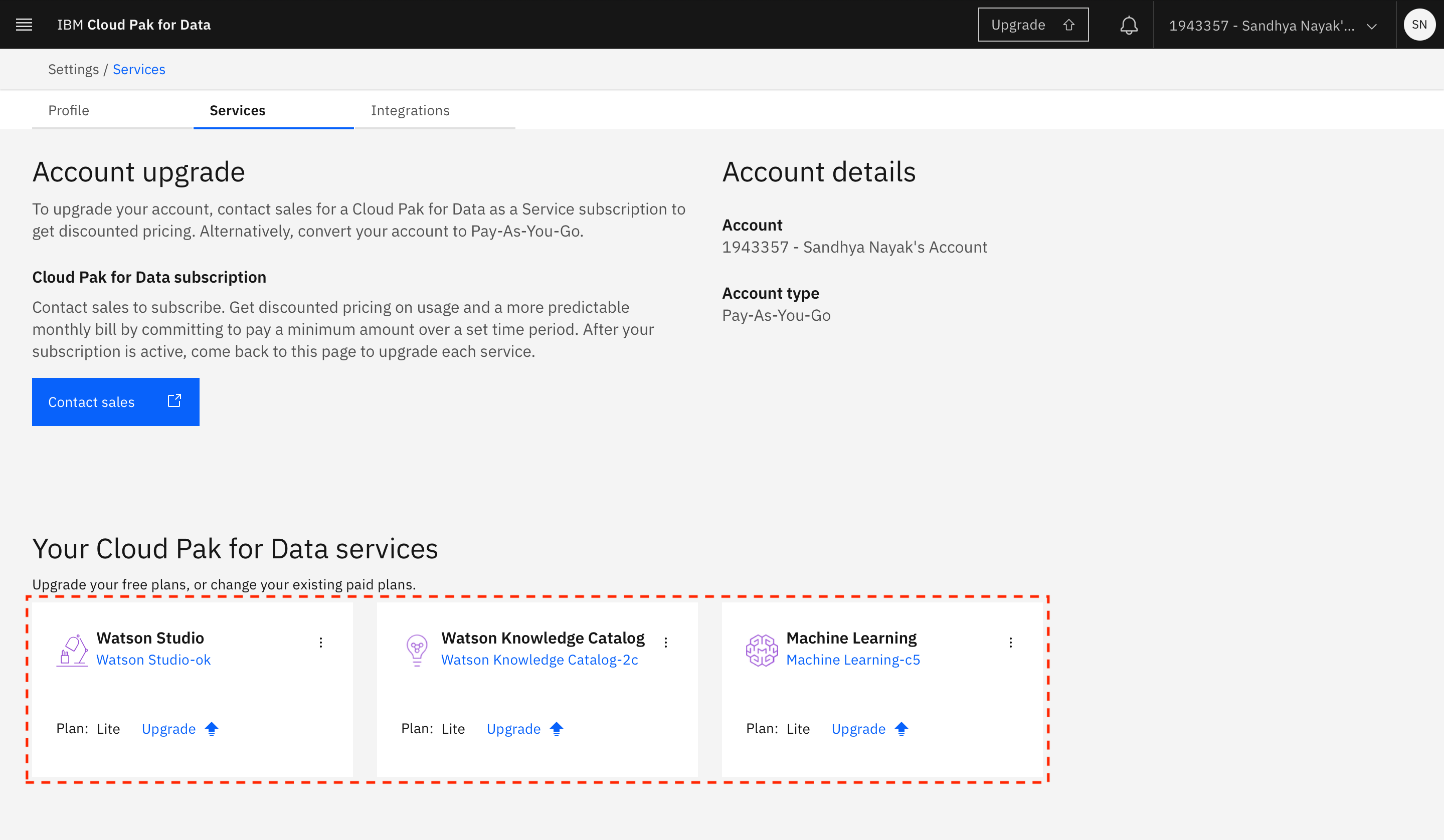
After the service instance is created, you are returned to the IBM Cloud Pak for Data instance. You should see that the service is now associated with Your Cloud Pak for Data account.
Create a new project and import the Notebook
Navigate to the menu (☰) on the left, and choose View all projects. After the screen loads, click New + or New project + to create a new project.
Select Create an empty project.
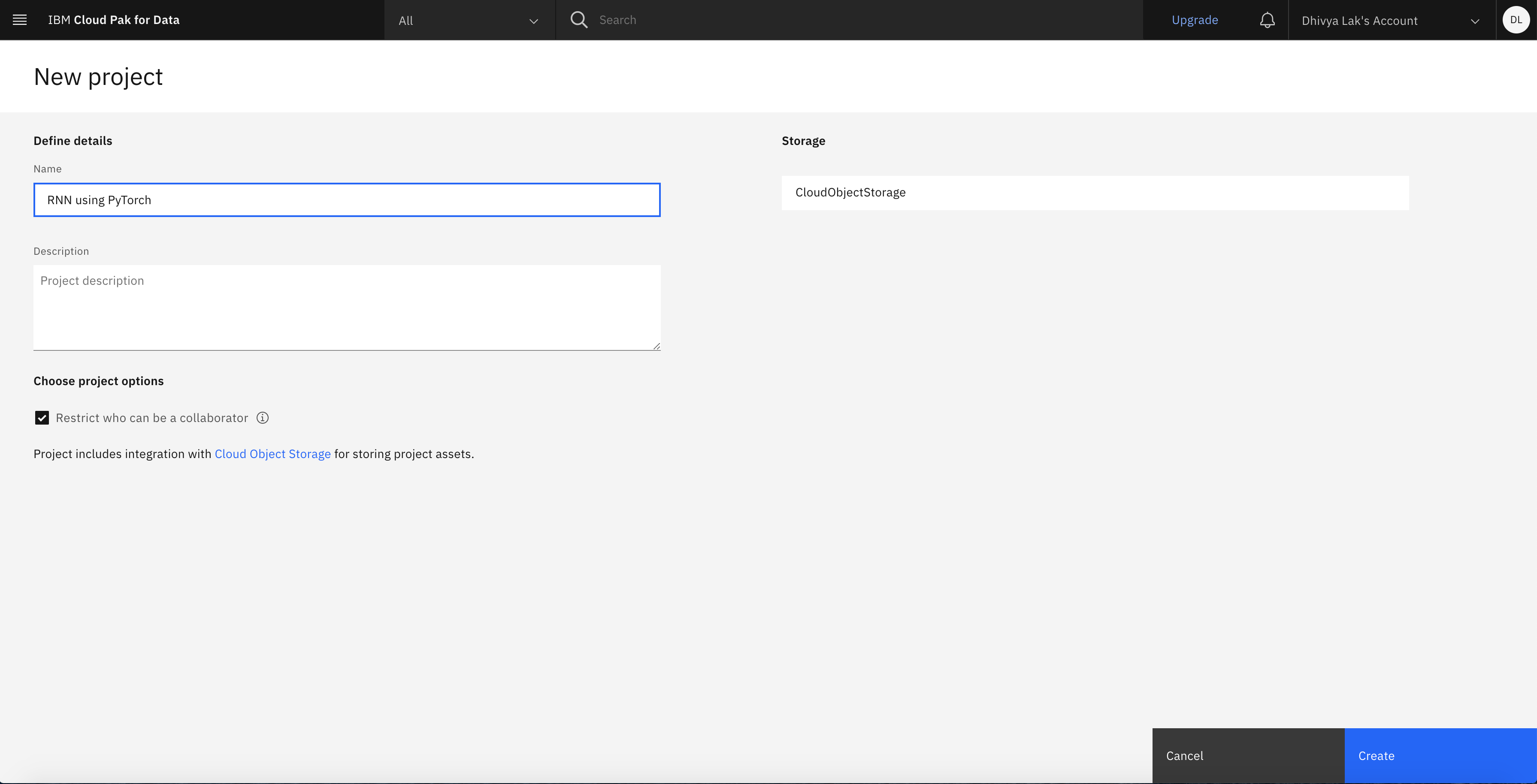
Name the project. In this example, it's named "RNN using PyTorch." You must associate an IBM Cloud Object Storage instance with your project. If you already have an IBM Cloud Object Storage service instance in your IBM Cloud account, it should automatically be populated here. Otherwise, click Add.
Select the type of plan to create, and click Create.
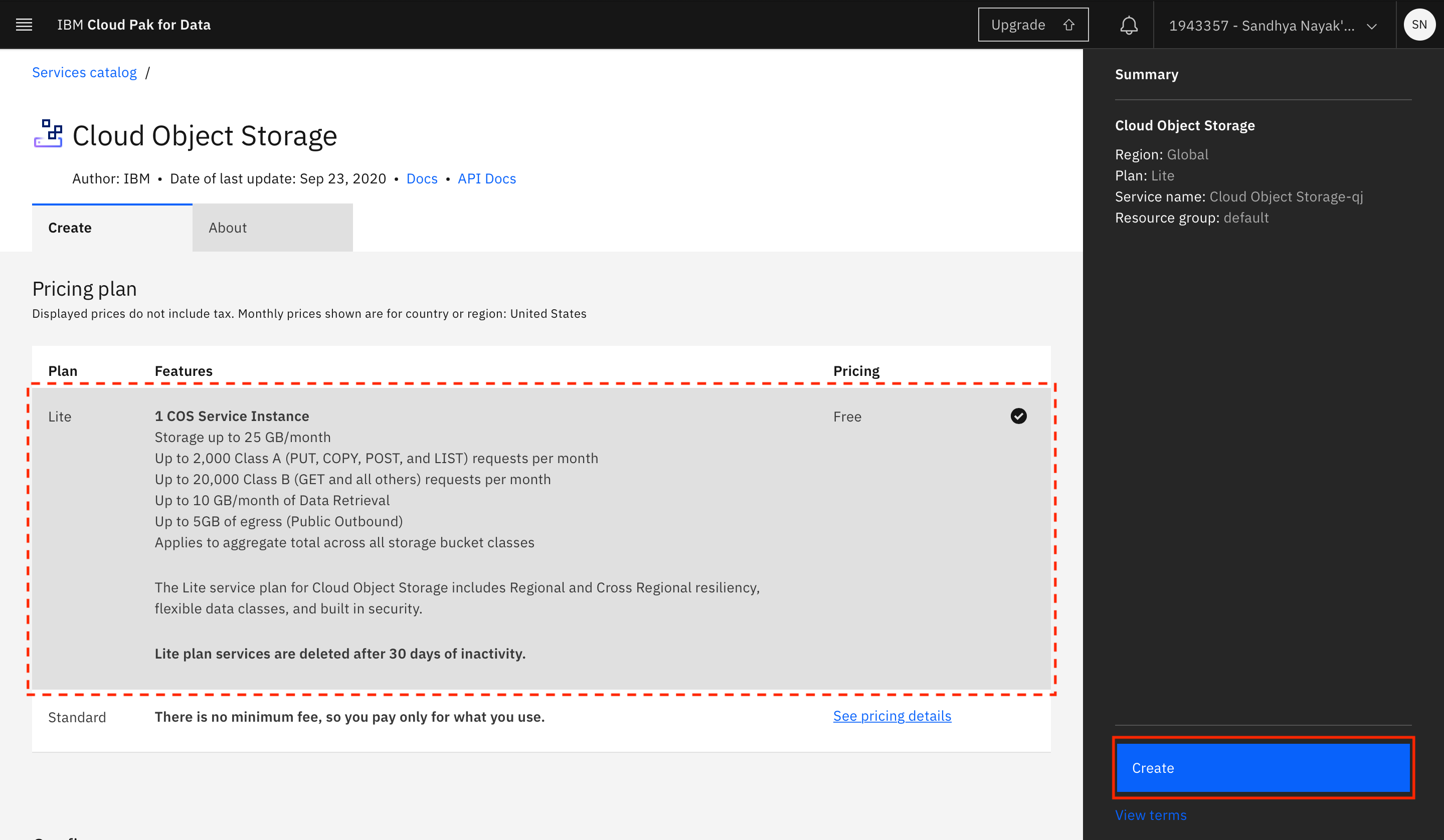
Click Refresh on the project creation page.
Click Create after you see the IBM Cloud Object Storage instance that you created displayed under Storage.
After the project is created, you can add the Notebook to the project. Click Add to project +, and select Notebook.
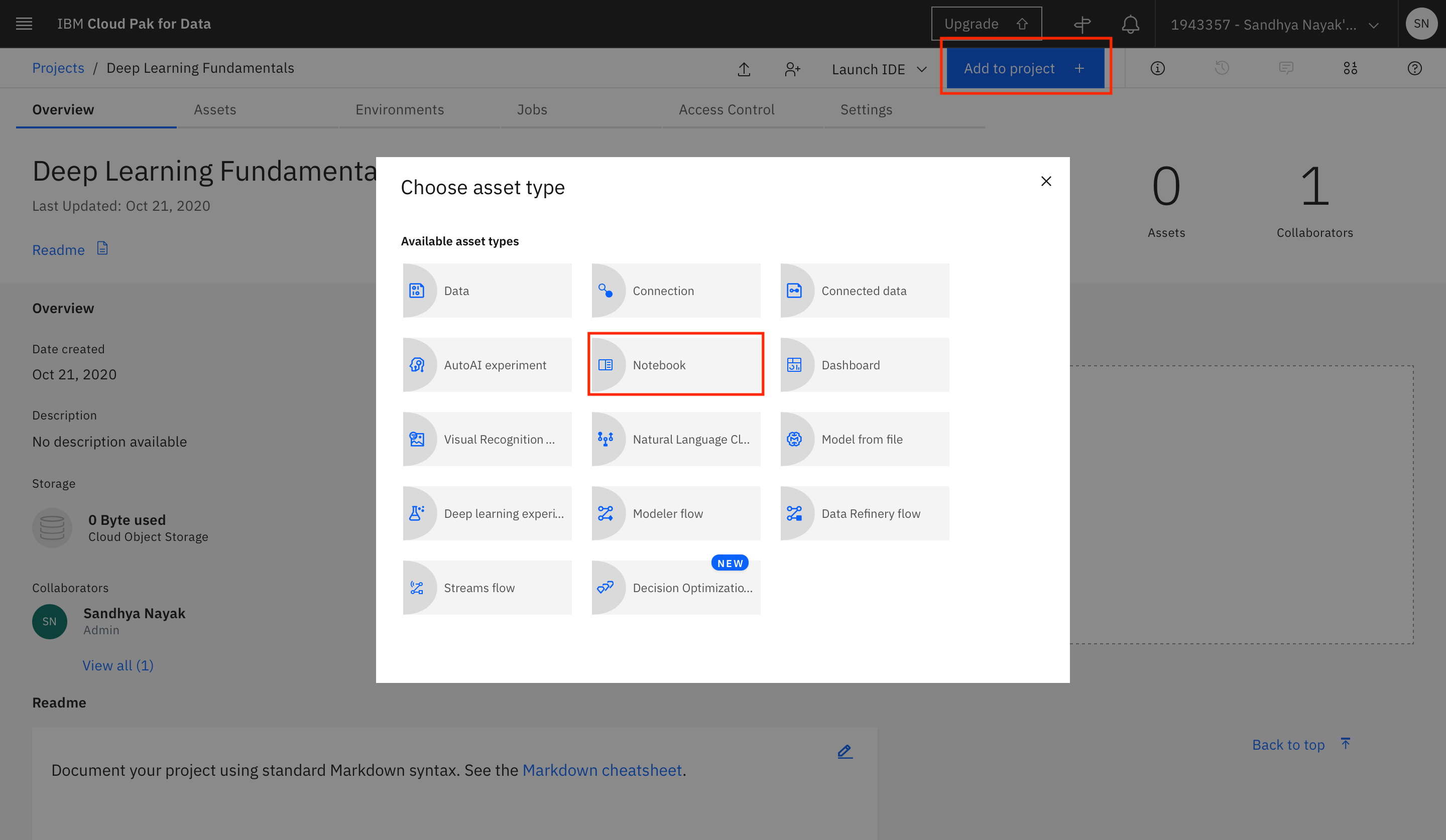
Switch to the From URL tab. Provide the name of the Notebook as RNN Implementation using Pytorch, and the Notebook URL as
https://raw.githubusercontent.com/IBM/dl-learning-path-assets/main/supervised-deeplearning/notebooks/RNNPyTorch.ipynb.Under the Select runtime drop-down menu, select Default Python 3.7 S (4 vCPU 16 GB RAM), and click Create.
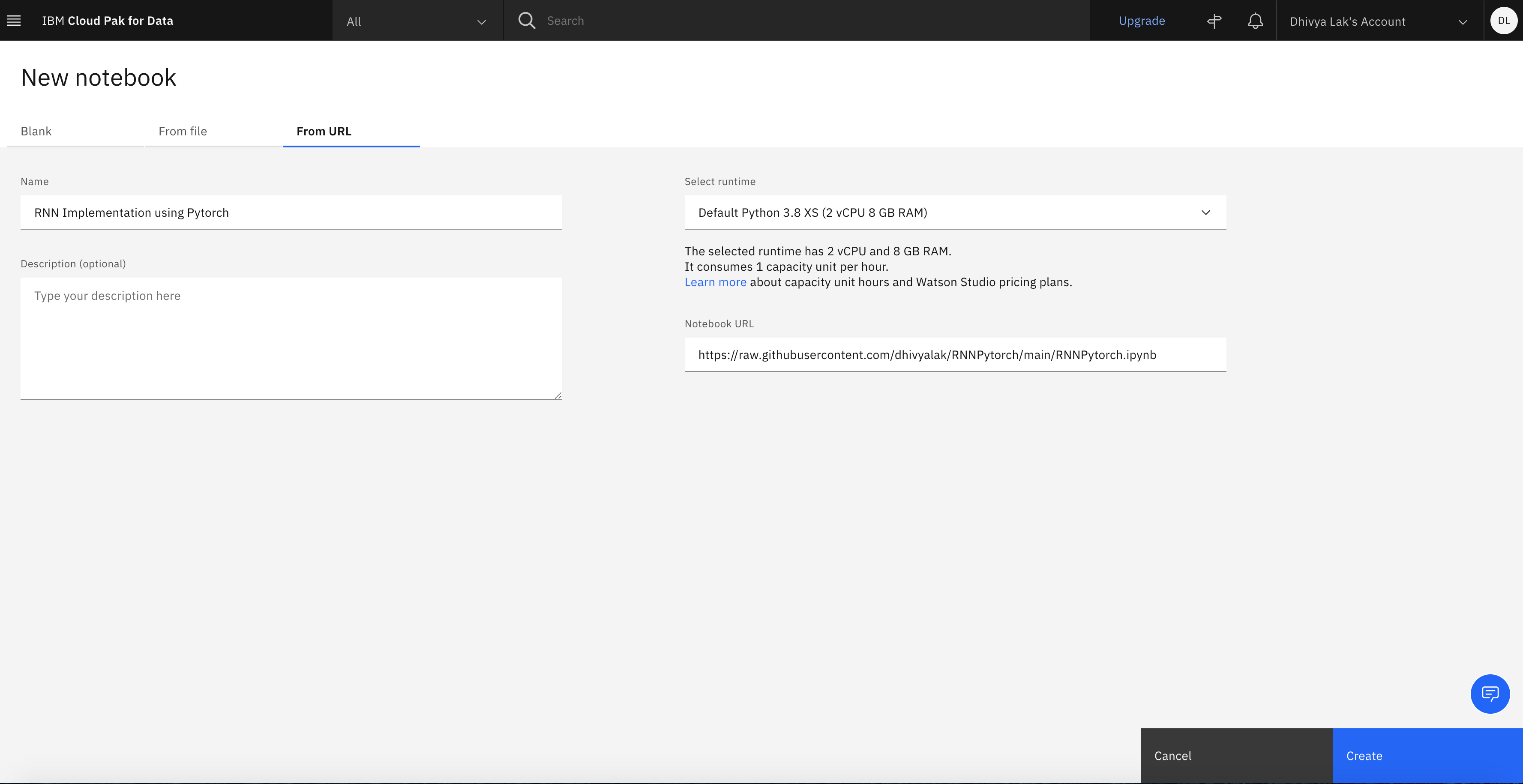
After the Jupyter Notebook is loaded and the kernel is ready, you can start running the cells in the Notebook.
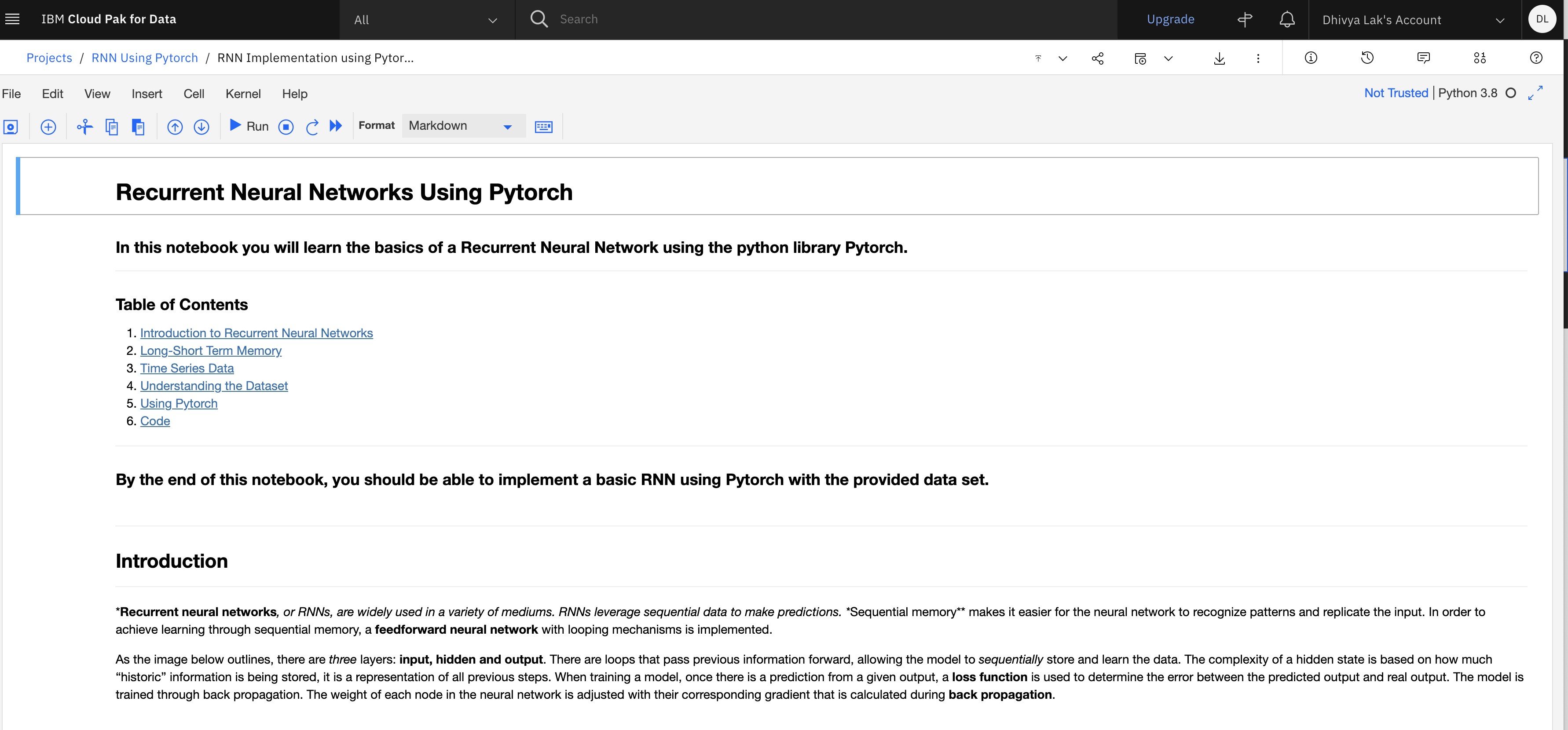
Important: Make sure that you stop the kernel of your notebooks when you are done to conserve memory resources.
Note: The Jupyter Notebook included in the project has been cleared of output. If you would like to see the Notebook that has already been completed with output, refer to the example Notebook.
Import stock data CSV file
This tutorial uses a stock market data set from IBM Watson.
Download the stock data CSV file, and name it StockData.csv.
Go to your Deep Learning Fundamentals project.
To add the stock data CSV file to the project, click Add to project +, and select Data.
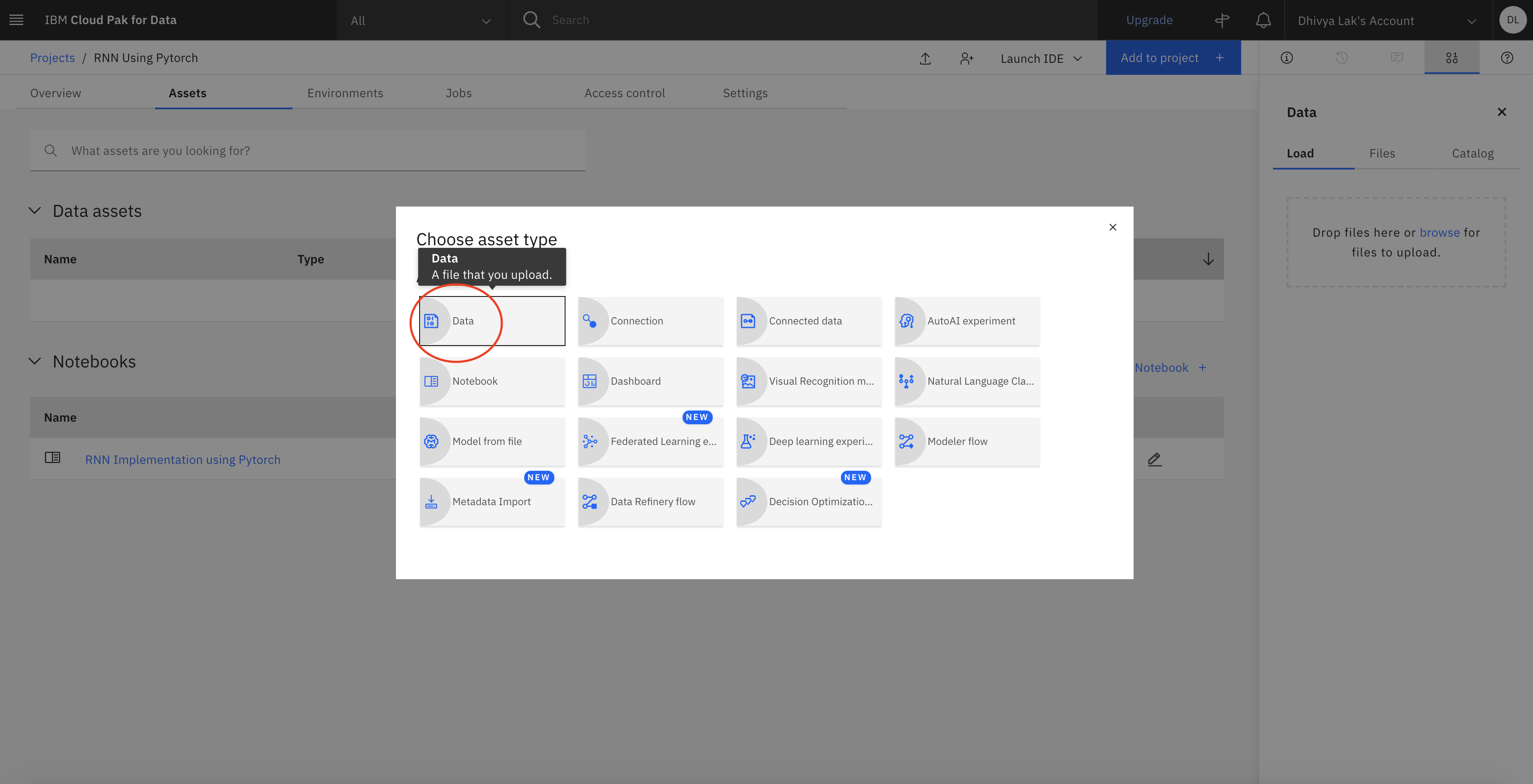
Under the load tab, add your locally downloaded version of the CSV file.
Go to the "RNN Implementation using Pytorch" Notebook.
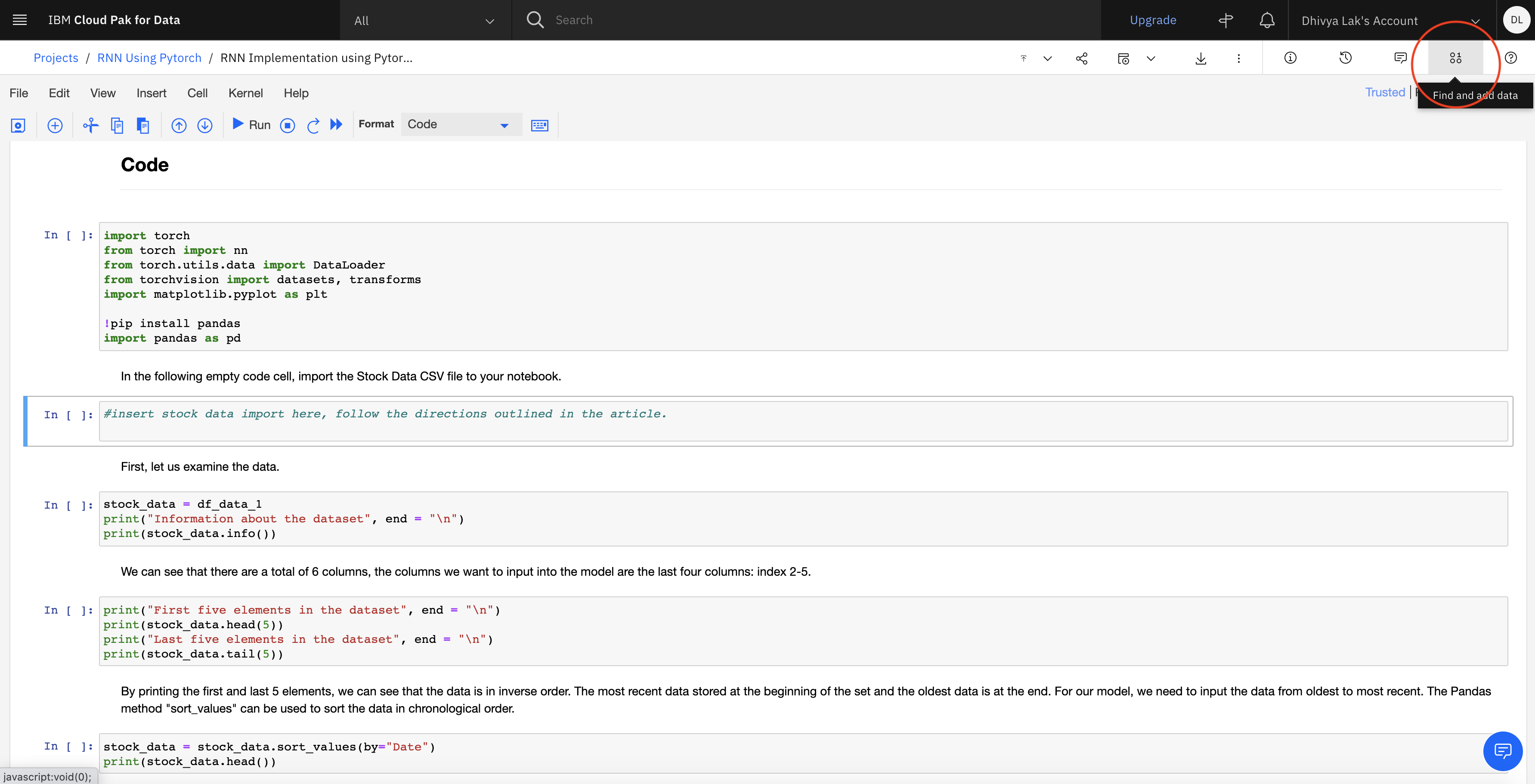
Go to the second Code cell under the Code section of the Notebook.
Click the Data Import icon in the upper right of the action bar.
Select the StockData.csv file, and add it as a Pandas DataFrame.
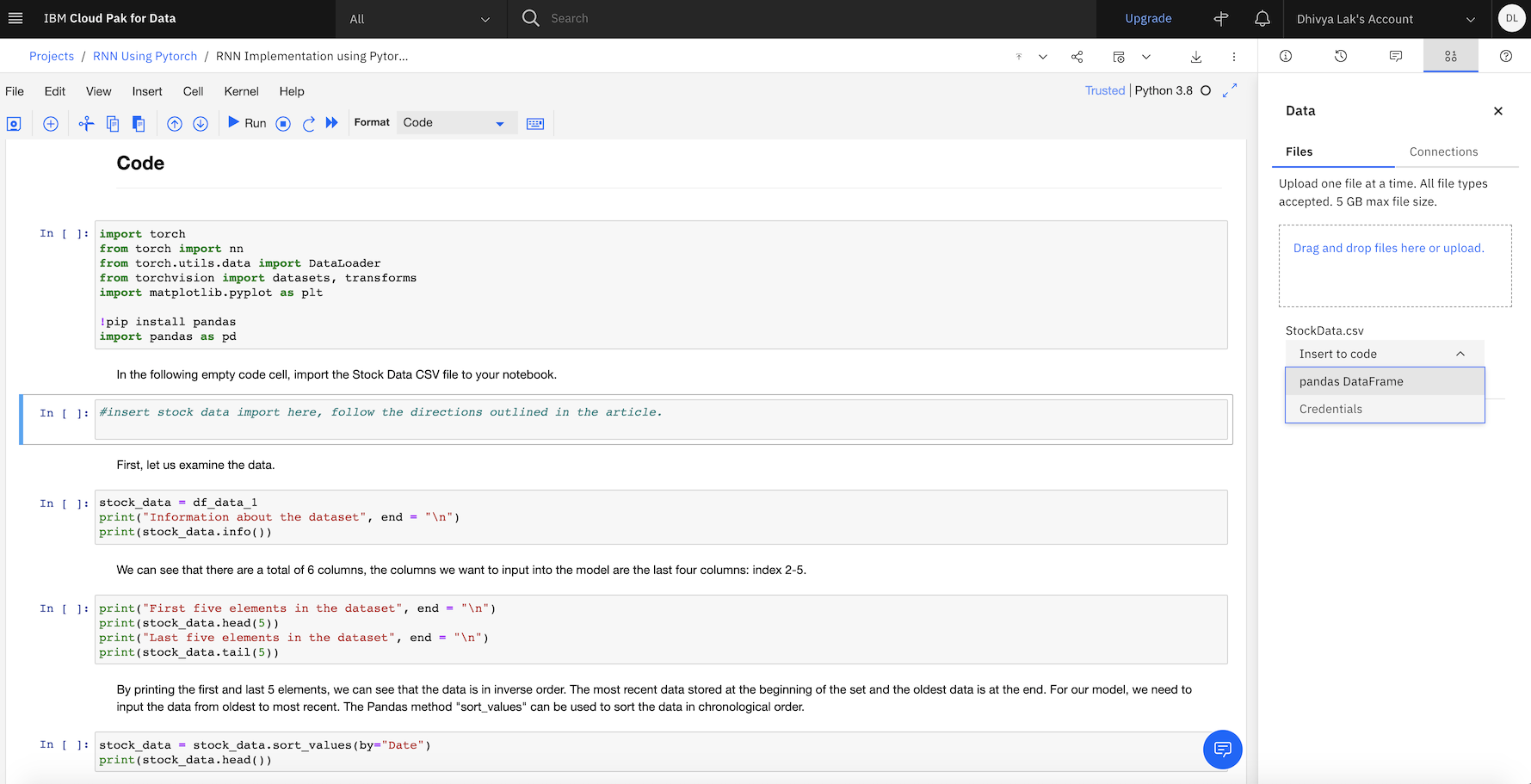
Your data should successfully be imported.
Note: Do not share the Notebook with the newly imported data. Each import contains a personalized and secure API key. Do not publish the notebook with the API key to any public version control systems (for example, GitHub). This compromises the security of your account because the Notebook contains sensitive keys that are unique to your account.
Read through the Notebook
Spend some time looking through the sections of the Notebook to get an overview. A Notebook is composed of text (markdown or headings) cells and code cells. The markdown cells provide comments on what the code is designed to do.
You run cells individually by highlighting each cell, then either click Run at the top of the Notebook or use the keyboard shortcut to run the cell (Shift + Enter, but this can vary based on the platform). While the cell is running, an asterisk ([*]) appears to the left of the cell. When that cell has finished running, a sequential number appears (for example, [17]).
Note: Some of the comments in the Notebook are directions for you to modify specific sections of the code. Perform any changes as indicated before running the cell.
The Notebook is divided into multiple sections.
- Introduction to recurrent neural networks
- Long short-term memory
- Time series data
- Understanding the data set
- Using Pytorch
- Code
The code section is where you can find the code pattern and RNN implementation.
Run the Notebook
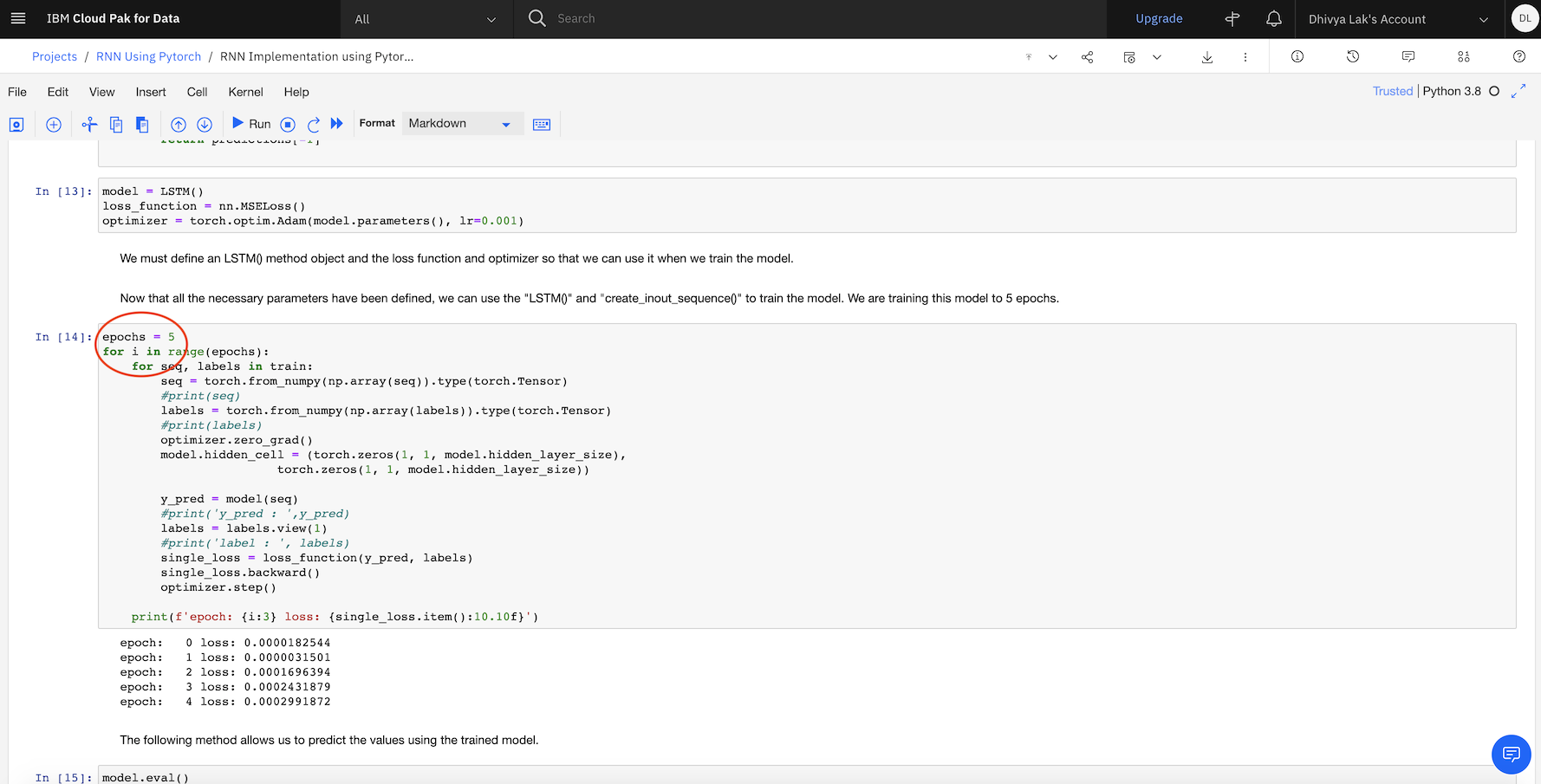
Run the code cells in the Notebook starting with the cells in section 4. The first few cells bring in the required modules such as TensorFlow, Numpy, reader, and the data set.
The model's training, validation, and testing does not happen until the last code cell. Running all 5 epochs takes approximately 10 minutes.
Summary
In this tutorial, you learned about RNNs and ran an implementation on a Jupyter Notebook using a stock market data set that is collected by IBM Watson and deployed on IBM Watson Studio on IBM Cloud Pak for Data. Using Python libraries such as PyTorch, MatPlotLib, and NumPy were also key in creating the model.