Tutorial
Introduction to microservices
Smaller, faster, stronger: Building better cloud applications from the ground upThroughout this article, I’ll cover the foundations of microservices so that you can gain an understanding of how to represent your own microservice-based architecture. I will rely heavily on Martin Fowler’s blog post, as I try to capture the essence of that post, its application to your environments, and how to get there.
What is a microservice? What is a microservice-based architecture?
Starting in 2009 — driven completely by APIs and riding the initial wave of what we would come to know as microservices — Netflix completely redefined its application development and operations models. At the time, the rest of the technology landscape was littered with Enterprise-scale monoliths, however, Netflix doubled down their effort to build more manageable, more scalable, and more resilient distributed systems.
The Netflix definition of microservices is “fine-grained SOA (service-oriented architecture)”. You don’t need to be intimately familiar with SOA (an architecture style coined more than a decade ago), just the terms used in the acronym. Ideally, you are building an entire architecture out of services from day one. In microservices, each of these services has a single solitary purpose with no side effects, enabling you to cover greater scale with fewer overall dedicated engineers.
But what is a microservice? What is a microservice-based architecture?
In essence, microservices and microservices-based architectures are many smaller architectural components, built and delivered faster, becoming stronger, both independently and as a whole.
Microservices are smaller
Microservices means no more monoliths. Monoliths are often big, clunky, slow, and inefficient. We are moving away from a world with 2GB WAR files (yes, just the WAR file—not the application server or operating system components) to a world populated by many services of 500MB each, containing entire applications, servers, and necessary operating system components.
The migration from mainframes to client/server architectures was a large step and one that many companies and developers alike struggled with. The more recent migration from core web-based application servers to SOA adoption was a similar struggle. Many components included in application servers of years past lend themselves to microservices; however, they are still packed inside multi-gigabyte installation binaries.
Microservices are an exercise in integration with all interacting components being much more loosely coupled. The entire idea of microservices becomes plug and play. I will touch on this more in the Stronger section, but essentially a microservices-based system employs the shotgun method at scale, to maintain and secure more small components instead of fewer large components. You remove single points of failure and distribute those points of failure everywhere.
Building for failure can only be done with smaller pieces. If you build a monolith for failure, you spend too much time focusing on the inefficiencies of every edge case. If you build a single service instance for failure, other service instances take over when consumers make requests.
The following figure shows one example of an implementation that uses microservices. It is a conceptual routing example of a video-streaming application.
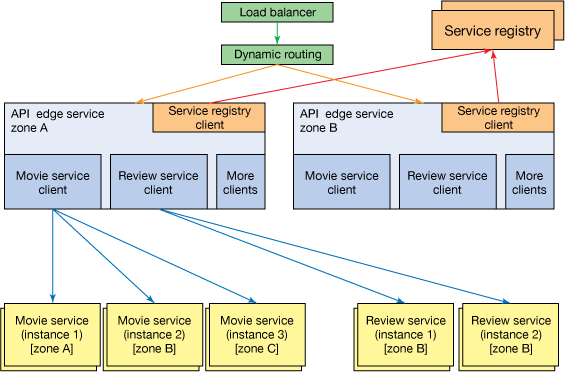
Each individual box is maintained on its own, scales on its own, knows where it sits, and knows where to get the information it needs. Not every microservice architecture requires every component in this diagram, but they do help!
These microservices components that scale independently. I'll touch on the individual components and how they scale in the Faster section, but for now focus on the distributed nature of each component and service. These components are distributed by nature and only provide a single, focused capability, often using different technology from other components. This structure enables the application architecture to evolve much faster and include newer technologies, as well as newer releases, independently of the other components.
To summarize, smaller is better to develop, operate, maintain, and interact with.
Microservices are faster
The DevOps movement empowers developers to control more of their code along the delivery pipeline, integrate continuously, and achieve more visibility. The main phases of the DevOps lifecycle are comprised of the following: planning, development, integration, deployment, operations, and learning. These are all done in a continuous fashion and map perfectly to our goals of speed and size.
What could be better than delivering smaller pieces faster, right? There’s no way you can deliver updates to a monolithic application server instance every two weeks, but in that same time frame you can definitely deliver updates to a single service consumed by many other services. Less overhead is incurred by smaller components when you build new staging environments, move items through your pipelines, and deliver to production environments.
Don’t get me wrong. Continuous delivery and integration can still be done with monoliths. I’ve seen it happen. However, then you’re juggling boulders, not marbles. It’s much easier to recover from dropping a marble than from dropping a boulder.
The development cycles associated with DevOps lend themselves well to microservices. You are aiming for shorter development cycles that continuously add functionality, instead of longer development cycles that build a complete holistic vision at once. This development methodology, known as Agile, is a fundamental practice responsible for the success of DevOps. Whether you choose iterative or incremental development, the combination of microservices, DevOps culture, and Agile planning enables you to quickly build out an entire infrastructure in the time it would have taken you to plan your first waterfall cycle in years past.
The other aspect of faster relates to execution. Microservices are built on the notion that if you need to go faster, just throw more resources at it. A manager's dream! By building every service to be independently scalable, you allow for interaction among components to take advantage of a pool of resources instead of single component interfaces.
Returning to the previous example, in Figure 2 you see Service Registry servers and clients. This capability is critical in a microservices-based application. In this example, the edge services contain Movie Service and Review Service references. Based on load, these services scale at different rates; therefore you can no longer manage them all the same way at the same scale.
As the Movie Services scale, the Service Registry automatically knows about the new service instances that get created. When an Edge Service tries to handle a request, it makes a call to the Service Registry and gets client references for all the services it depends on. The Movie Service client reference is more likely a new one that has been created fairly recently, whereas an old instance of the Review Service previously used could be returned. This Service Registry capability allows your microservices to truly function as “one of many,” with a loosely coupled dependency between your components, but a highly reliable capability to get more copies of a component when needed.
The following figure shows the same conceptual architecture for the video-streaming application presented earlier, with the addition of scaled-out microservices for the Movie Service.
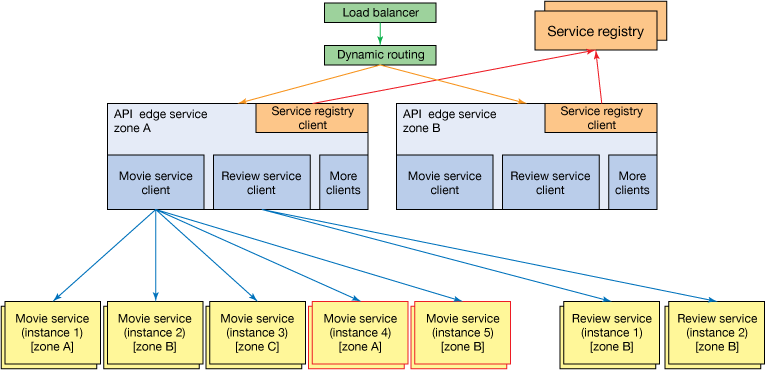
Efficiently scaling as needed, with systems that are self-aware of new instances. It's what makes applications built on microservice architectures that much stronger.
Microservices are stronger
Not all systems are meant to be long-lived. They are created when needed and removed when they no longer serve a purpose. As I mentioned before, this removes single points of failure by distributing those points throughout the system, knowing that you need mechanisms to account for services and instances that are unavailable or performing poorly.
Creating microservices leads to creating services that are many of one, as well as one of many. No longer do we count service instances on one hand or manage long-term instances and worry about maintaining state, storage, system modifications, and so on. Don’t get me wrong — we are still very much interested in performance tuning and configuration, but these things now happen much earlier in the development cycle instead of in staging or production. This approach gives us many services, and many instances of each service.
To validate this pillar of strength, in its journey, Netflix began harnessing chaos — a Chaos Monkey to be exact. The Chaos Monkey is a cloud application component that Netflix uses to introduce systematic chaos into application operations.
This capability would go through the infrastructure and purposefully turn off services and service instances that were critical to production. Why would Netflix do this? How could it do this and survive?
First, the why. It’s a way of making it easy to identify where you need to fail fast. Are new services too slow? Do they need to scale more efficiently? What happens when an external service provider goes down, not just internal services? All of these things need to be accounted for in a microservices architecture.
Second, the how. Netflix can survive thanks to the shotgun method I mentioned earlier. The idea is simple: Provision enough service instances that 99.9999 percent of requests will complete successfully. Any failed requests will work on a retry. Pull the plug on a service instance, and another local one will take its place. Pull the plug on an entire service, and your system should compensate or reroute users to other availability zones or regions with that specific service. If nothing else is available, the user or request should fail fast and not wait to time out.
Netflix expanded the Chaos Monkey concept and released the capability as Simian Army, to include Chaos Monkeys, Janitor Monkeys, Conformity Monkeys, and Latency Monkeys — cloud application components that introduce specific chaos into operations, including latency and compliance issues. The Simian Army project has since been deprecated, as Netflix moved its capability to other service components, as each area of chaos testing proved itself invaluable along the way.
As you can see, Netflix (and other companies adopting microservices) subscribes to the idea that what kills your application makes it stronger.
Conclusion
In the end, the main benefits for using microservices are:
- The smaller size of microservices enables developers to be more productive.
- It’s faster and easier for developers to understand and test each microservice.
- They are stronger such that developers can correctly handle failure of any dependent service, and they reduce the impact of correlated failures.
Acknowledgments and images credits
I'd like to thank Jonathan Bond for his presentation, which allowed me to capture and orient my thoughts and also borrow a few images.