Tutorial
Connect a custom machine learning model to a SingleStore
Integrate a SingleStore with a Python machine learning model using a Jupyter notebookData scientists developing machine learning models need a reliable, scalable database to store and access their data. SingleStore offers this capability. In this tutorial, we show you how to:
- Create an instance of SingleStore on a OpenShift Cluster using a Red Hat Marketplace operator.
- Connect a custom machine learning model to a SingleStore hosted on Openshift cluster.
Introduction to SingleStore
SingleStore), which was previously MemSQL, is a distributed, highly-scalable SQL database that ingests data continuously to perform operational analytics for your business. SingleStore ingests millions of events per day with ACID transactions while simultaneously analyzing billions of rows of data in relational SQL, JSON, geospatial, and full-text search formats. Querying is done through standard SQL drivers and syntax, leveraging a broad ecosystem of drivers and applications.
Learning objectives
After completing this tutorial, you will learn how to:
- Deploy a SingleStore operator on an OpenShift cluster from Red Hat Marketplace
- Create a table within a SingleStore
- Configure the database as a data asset in Watson Studio.
- Access the database using Python client
- Create and store data in a SingleStore using Python Client
Prerequisites
- Create a Red Hat Marketplace account
- Have an IBM Cloud account
Estimated time
Completing this tutorial should take about 30 minutes.
Steps to Deploy SingleStore Operator from Red Hat Marketplace on OpenShift Cluster
- Configure an OpenShift cluster with Red Hat Marketplace
- Deploy a SingleStore operator on an OpenShift cluster
- Create a database instance
- Create a new Watson Studio instance on IBM Cloud
- Create a new project on IBM Cloud
- Create a database connection to the project
- Create a new Python notebook for the project
- Configure the notebook
1. Configure an OpenShift cluster with Red Hat Marketplace
Configure a Red Hat OpenShift cluster on Red Hat Marketplace and connect to the OpenShift cluster in your CLI.
2. Deploy a SingleStore operator on an OpenShift cluster
Go to the Red Hat Marketplace catalog and search for SingleStore. Select SingleStore from the results.
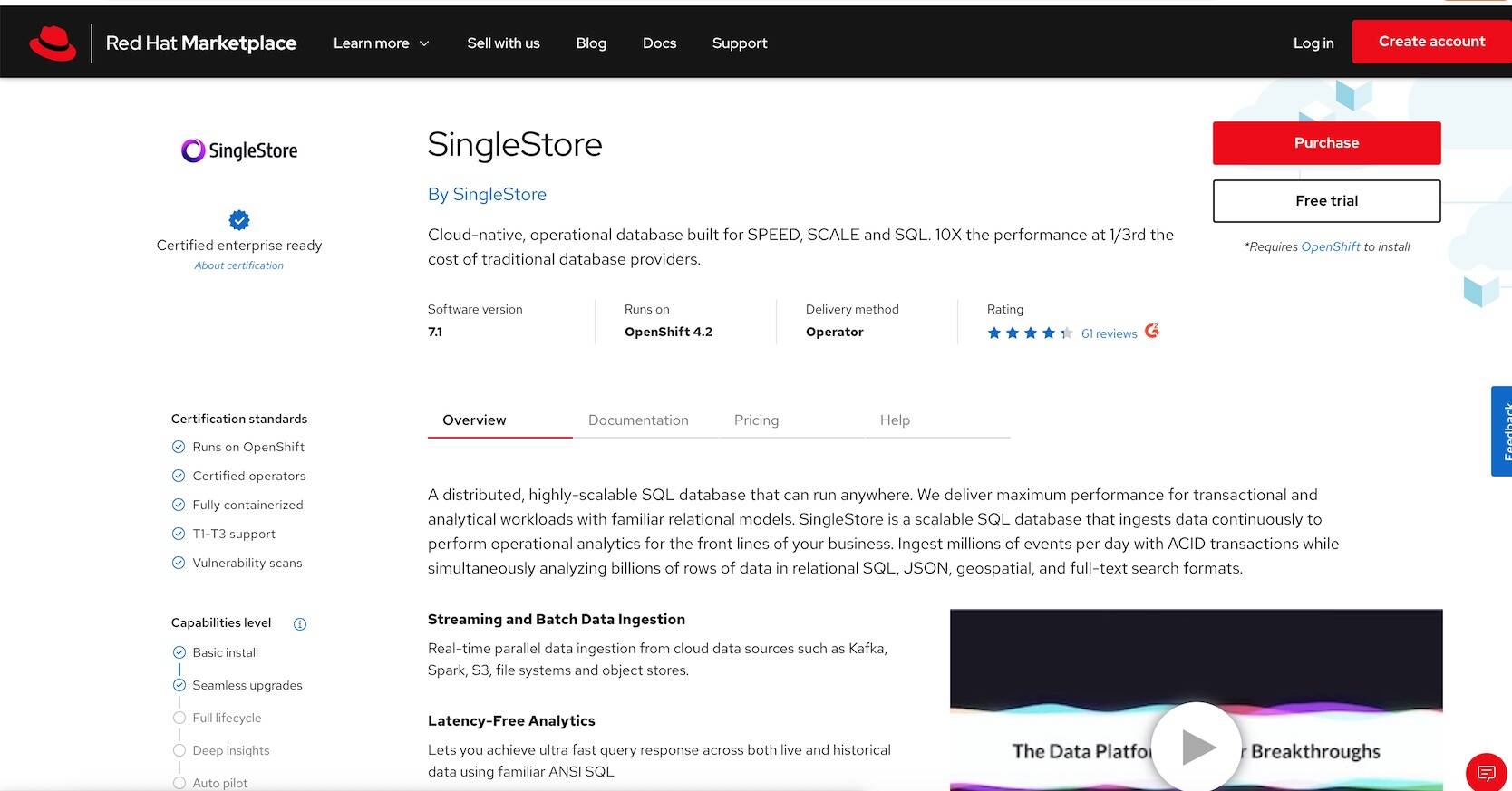
The SingleStore product page gives you an overview, documentation, and pricing options associated with the product. Click on the Free Trial button.
Next, the purchase summary will show the Subscription term and total cost is $0.00. Click Start trial.

A Red Hat login is required. Click Logon with Red Hat credentials.

Now, select Start trial.

You can visit Workspace > My Software to view your list of purchased softwares.
Back in the web dashboard, select the SingleStore tile and then select the Operators tab. Click on the Install Operator button.

Leave the default selection for Update channel and Approval strategy. Select the cluster and namespace scope as
SingleStore-projectfor the operator and click *Install.
A message will appear at the top of your screen indicating the install process initiated in the cluster.

3. Create a database instance
To launch the OpenShift cluster console, navigate to Workspace > Clusters and click the Cluster console.
Note: In the OpenShift cluster web console, you would still see the old name of the operator as MemSQL instead of SingleStore.
Next, navigate to Operators > Installed Operators to confirm the installation was successful. The operator
MemSQL Operatorshould list under the project/namespaceSingleStore-dtlas shown.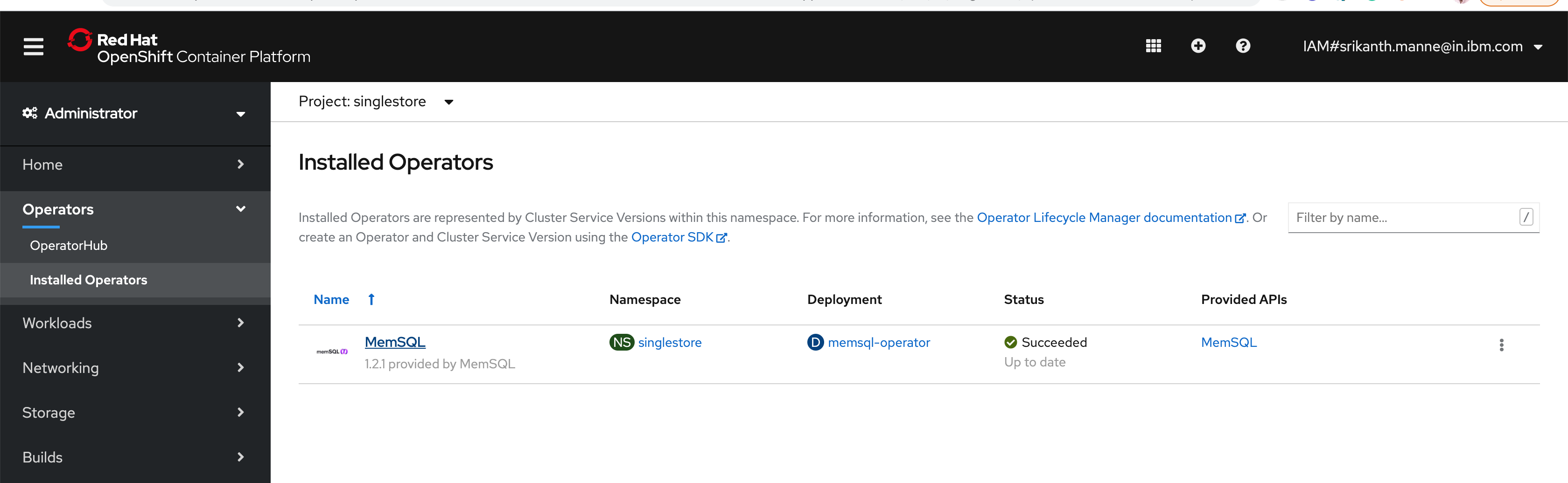
Under Provided APIs, click on the first Create Instance.
The Create MemSQL page will display with the default YAML. Edit the
storageclass_namein the YAML file, and click the Create button. If the default YAML file is not visible, you can copy and paste the following YAML file to replace thestorageclass_name.apiVersion: labs.ai/v1alpha1 kind: MemSQL metadata: name: SingleStore-dtl spec: size: 1 mongodb: environment: prod storageclass_name: <existing_storageclass> storage_size: 20G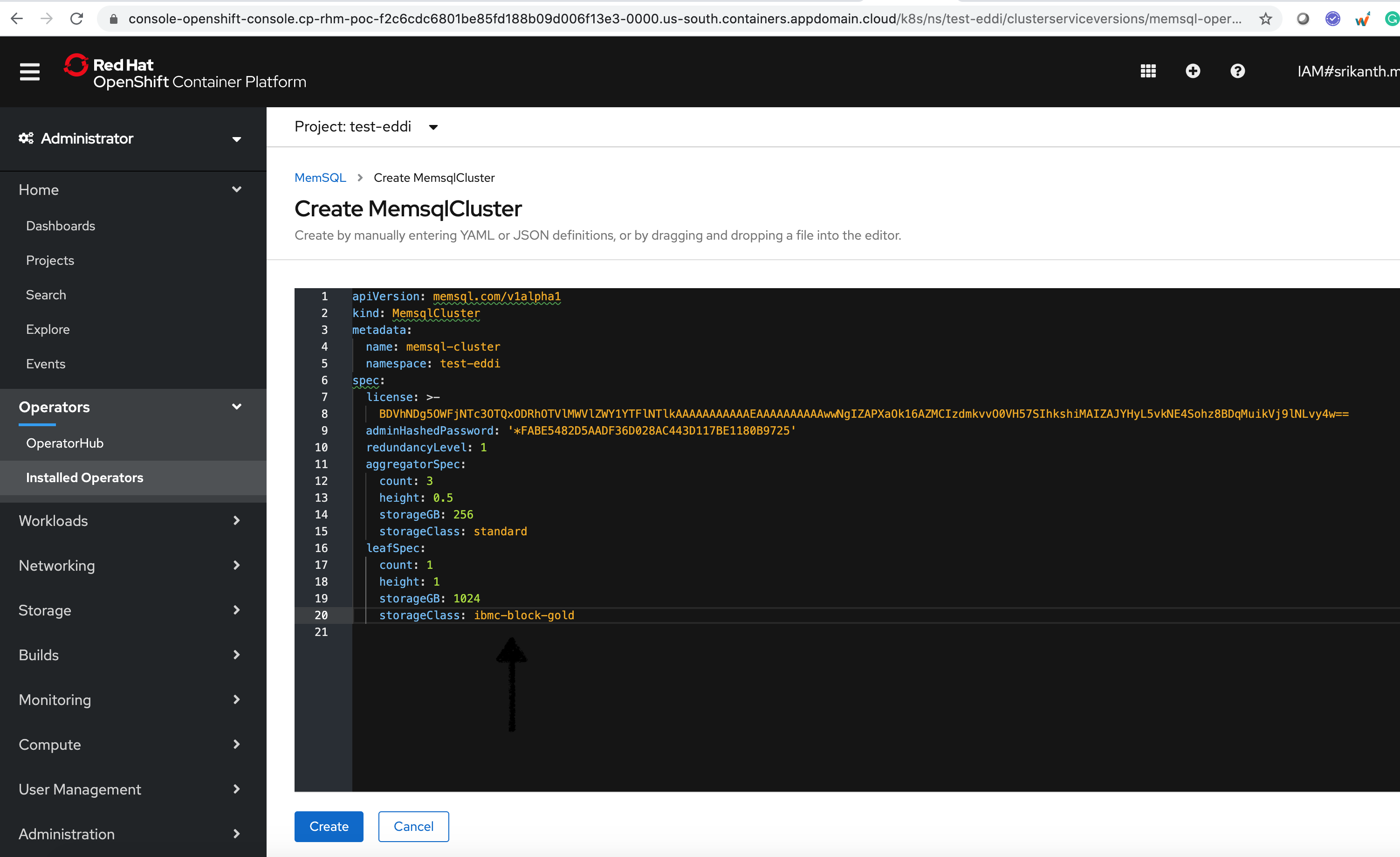
SingleStore Operator pods should come up when the installation is completed.
After the deployment completes, run the following command to display the two SingleStore service endpoints that are created during the deployment.
$ oc get svc
The output will resemble the following (actual values will vary):
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-memsql-cluster ClusterIP None <none> 3306/TCP 42h
svc-memsql-cluster-ddl LoadBalancer 172.21.29.233 169.46.26.10 3306:32278/TCP 42h
svc-memsql-cluster-dml LoadBalancer 172.21.6.77 169.46.26.11 3306:30922/TCP 42h
You can now access the SingleStore.
4. Create a new Watson Studio Instance on IBM Cloud
Visit the IBM Watson Studio page to create an instance of IBM Watson Studio. Click the Create button.
After the Watson Studio page loads, click on Get Started.
5. Create a new project on IBM Cloud
Once you log into your IBM Watson Studio instance. Click on the (☰)
menuicon in the top left corner of your screen and click Projects.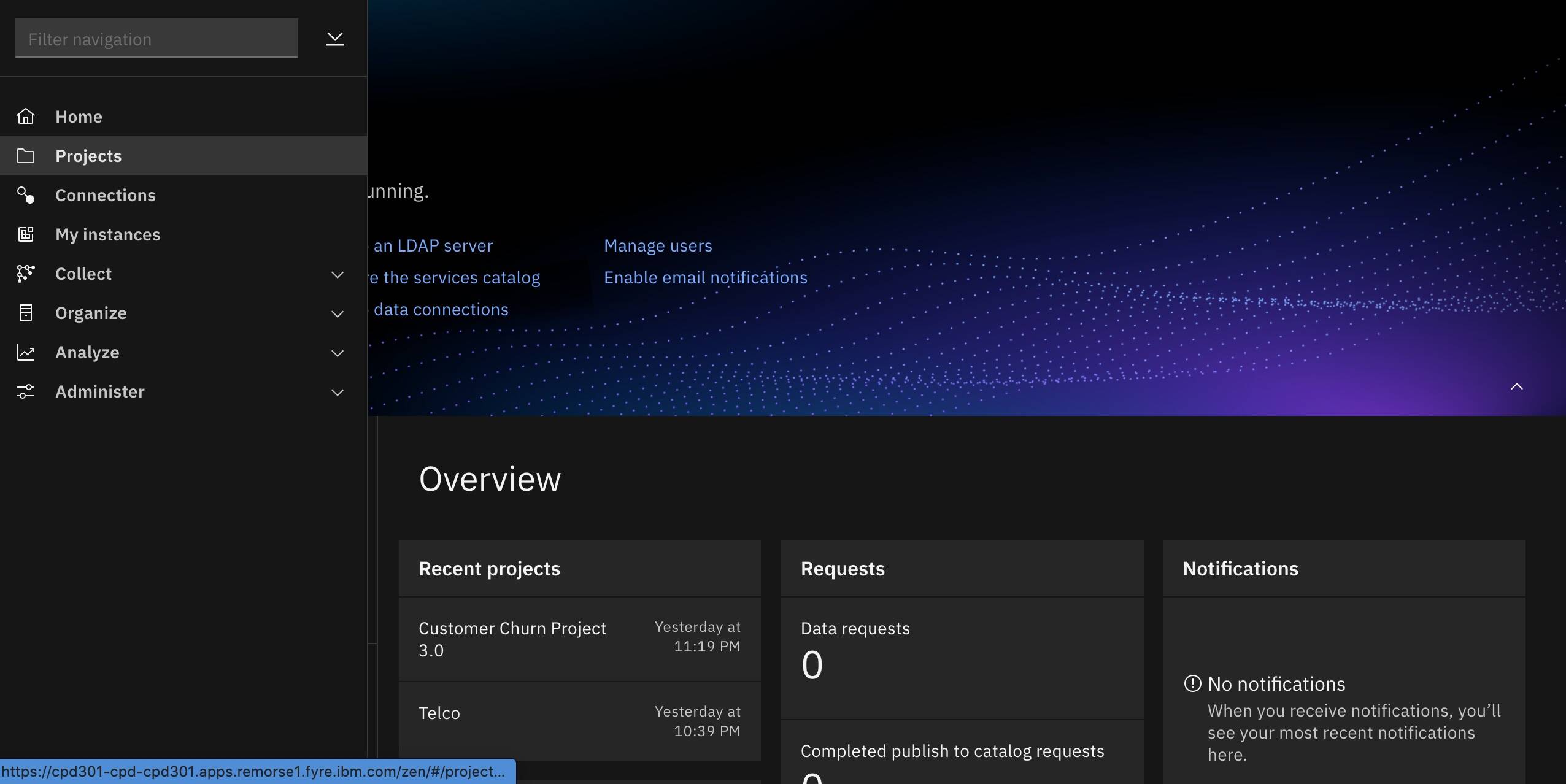
When you reach the Project list, click on Create an Empty Project. You will be navigated to a new page where you can enter the desired name(or
Telco_CallDrop). Once you click onOkyou will go to a new screen. Click onCreateto complete your project creation.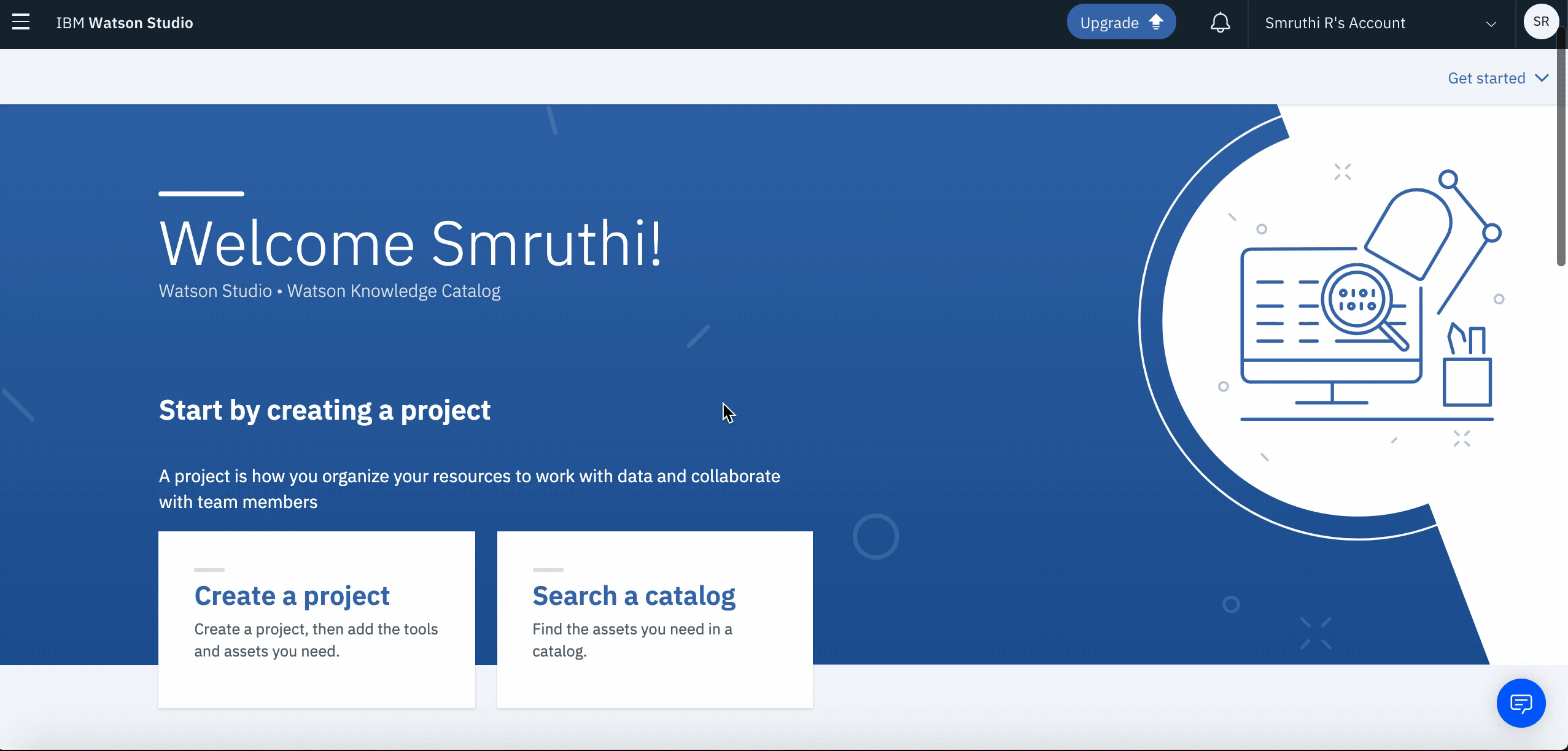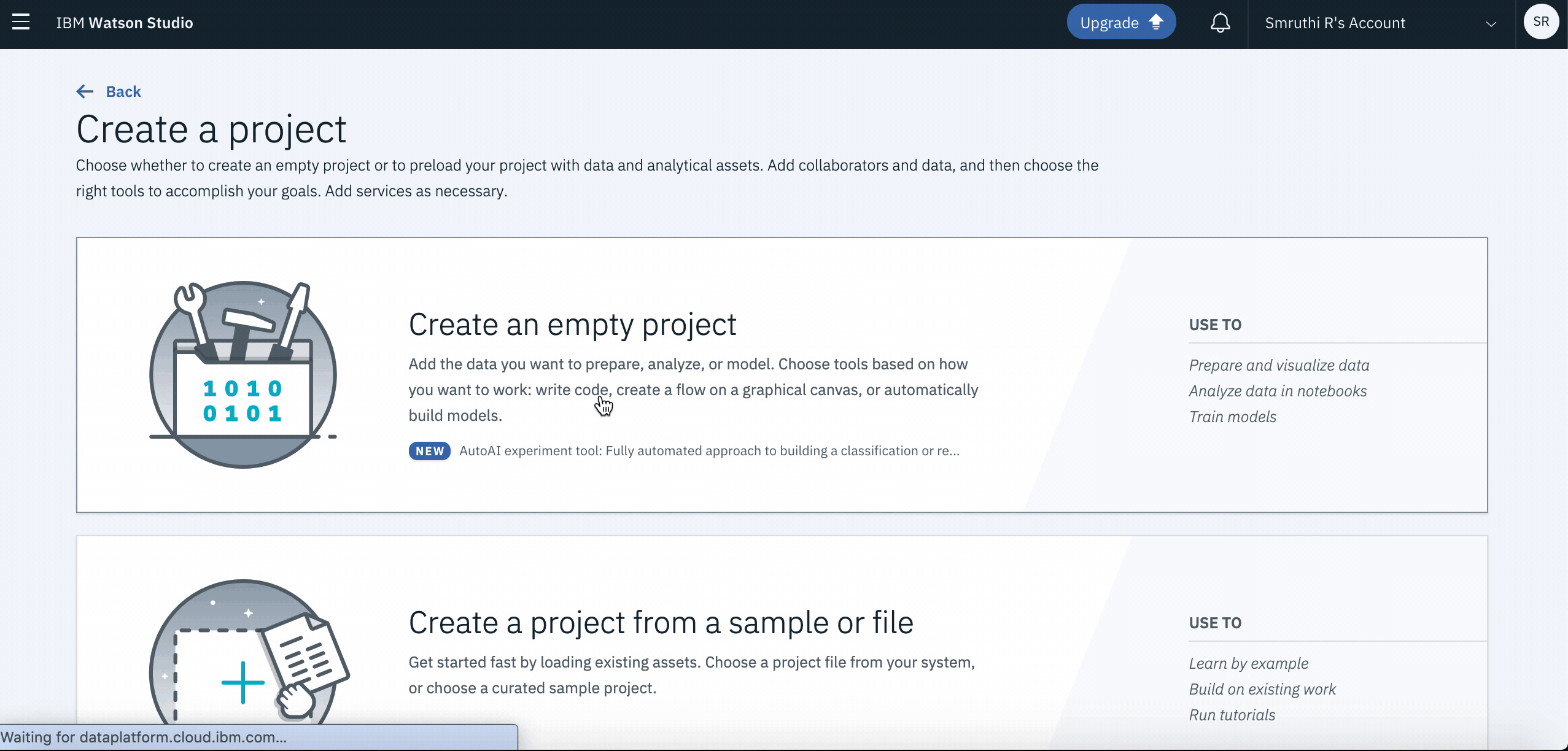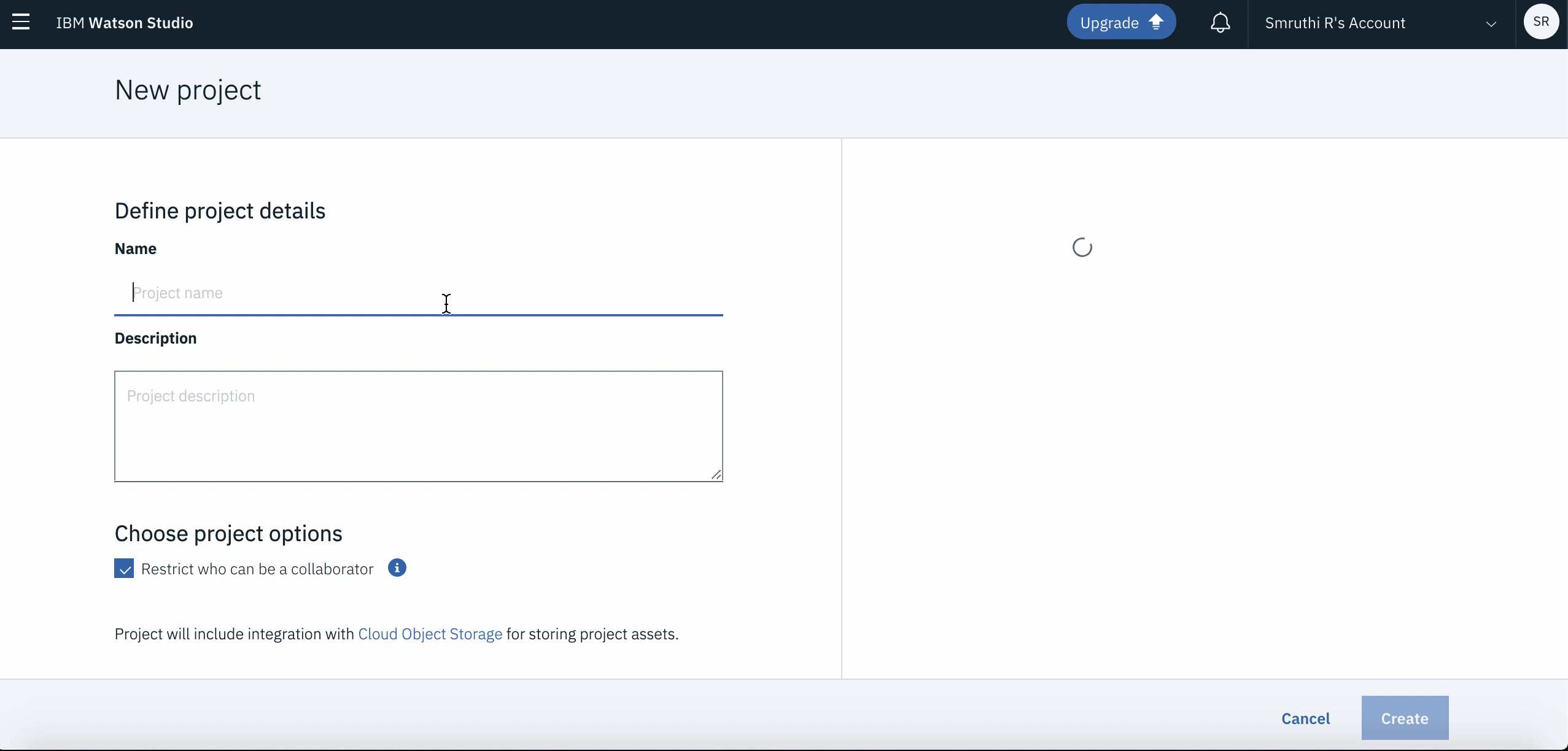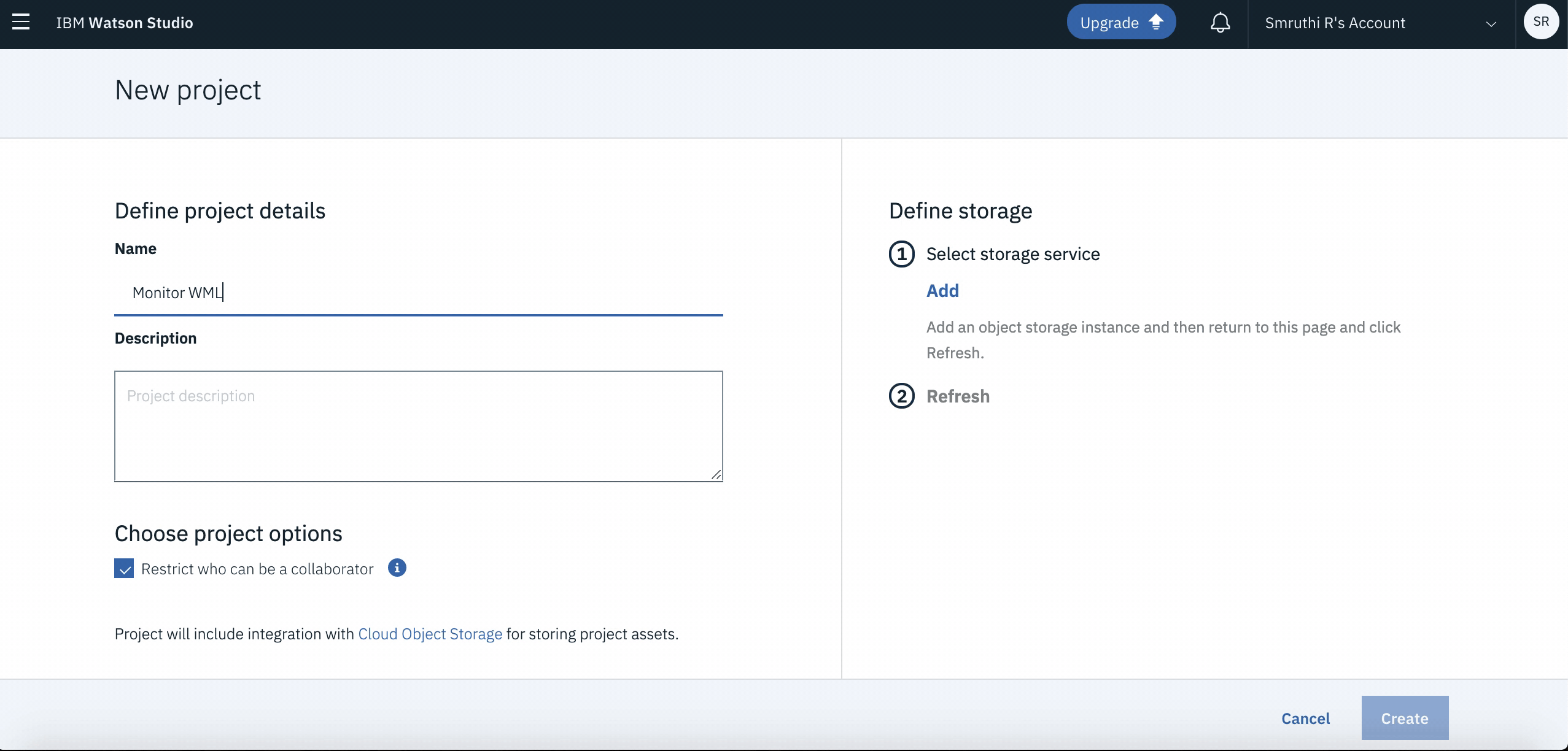
6. Create a database connection to the project
Once your new project is created, go to the project's landing page click on Add to Project. A menu will open; click on Connection.
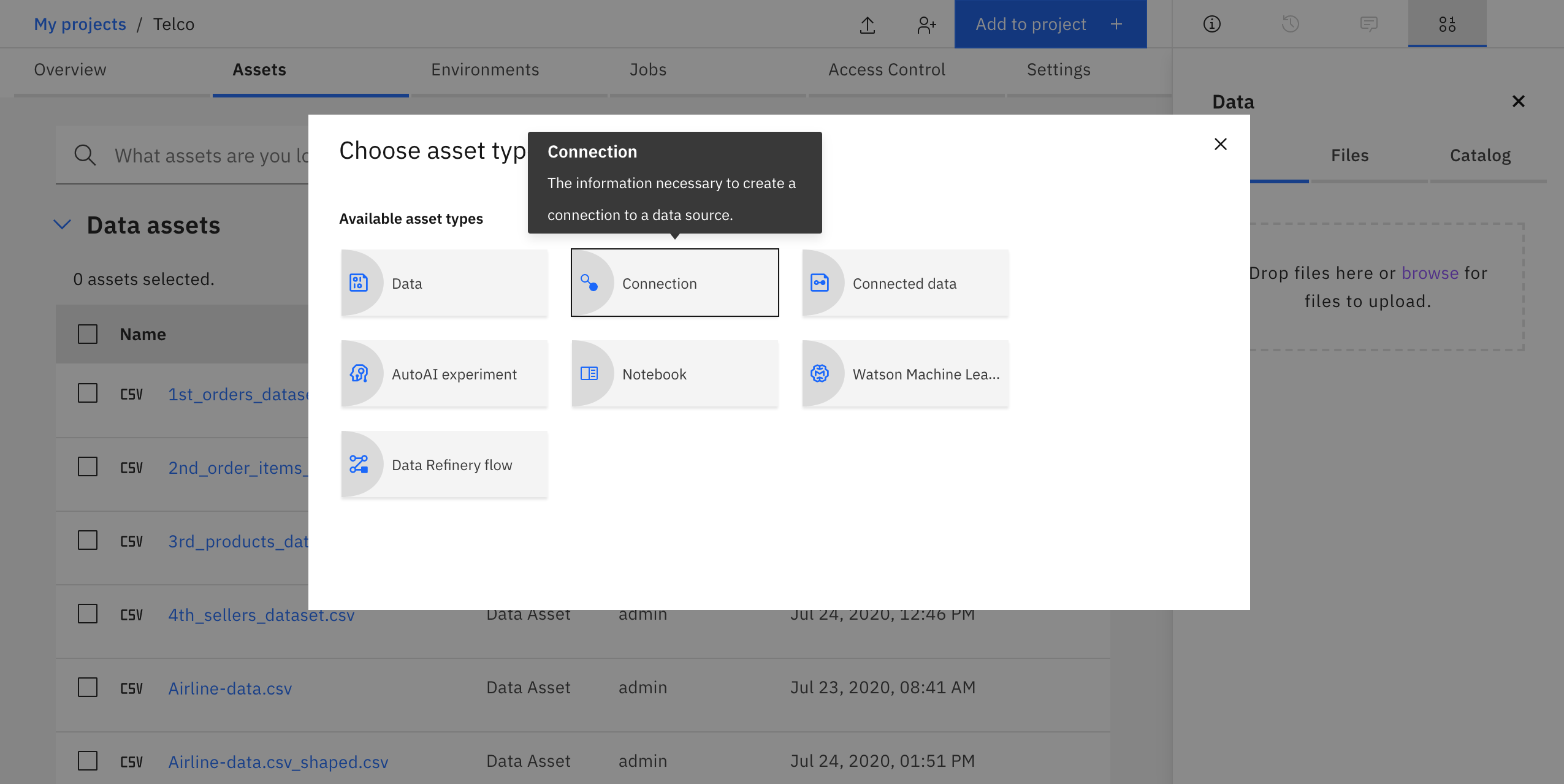
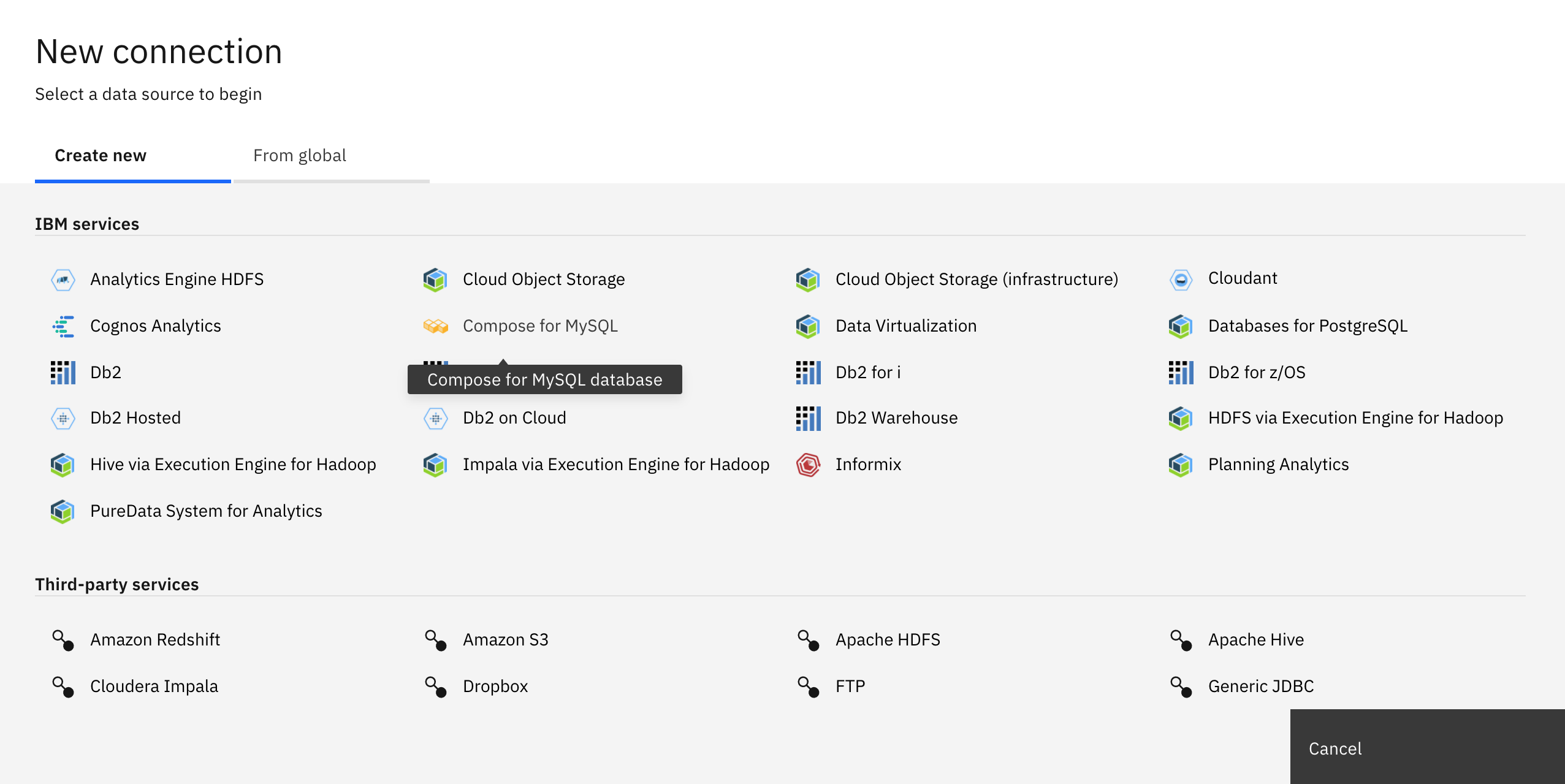
Select the desired database connection: Compose for MySQL Database.
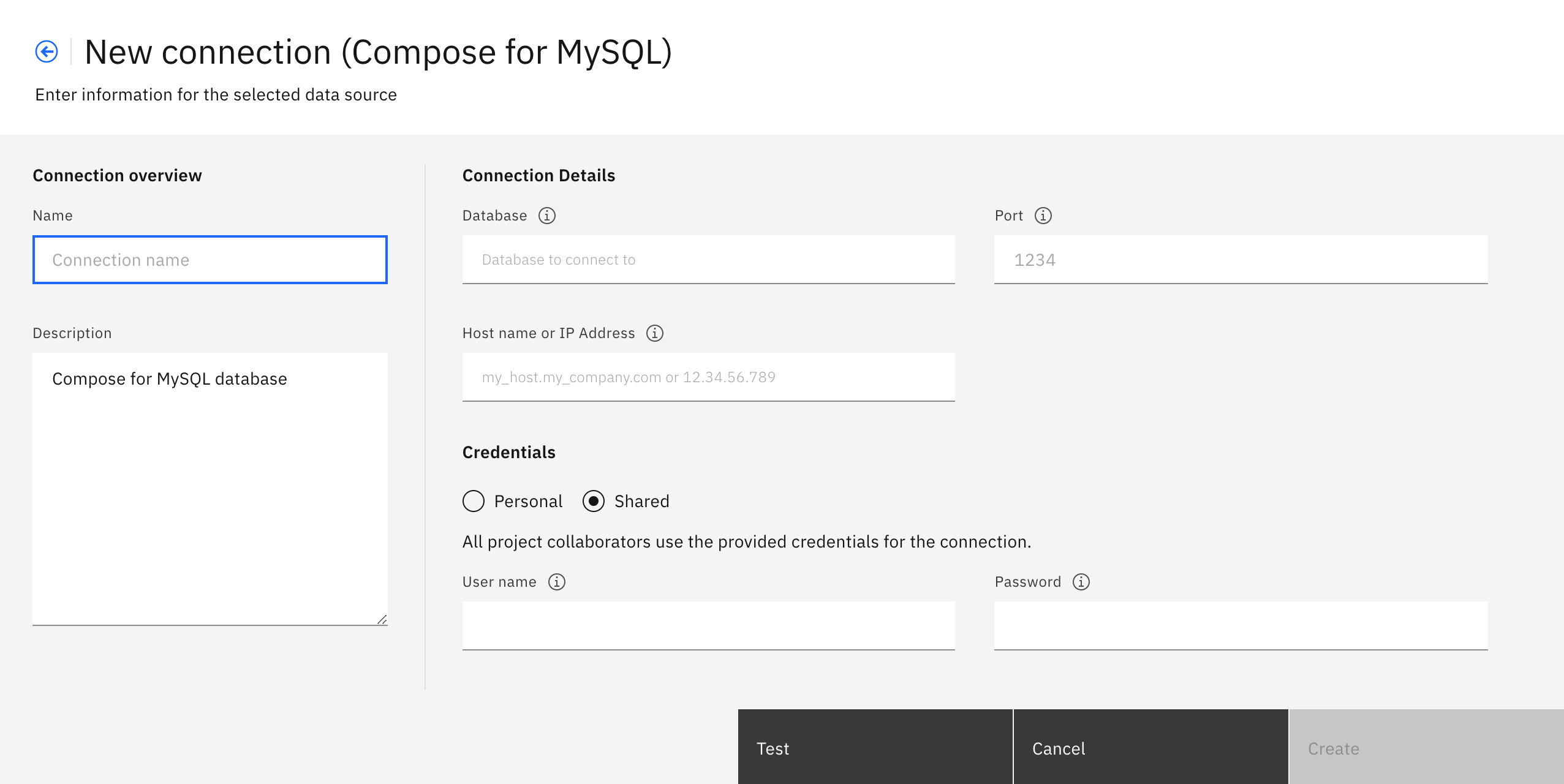
Enter the credentials of the database. Click on Test and then select Create.
7. Create a new Python notebook for the project
In the created project page, click on the Add to Project button. Then click on Notebook.
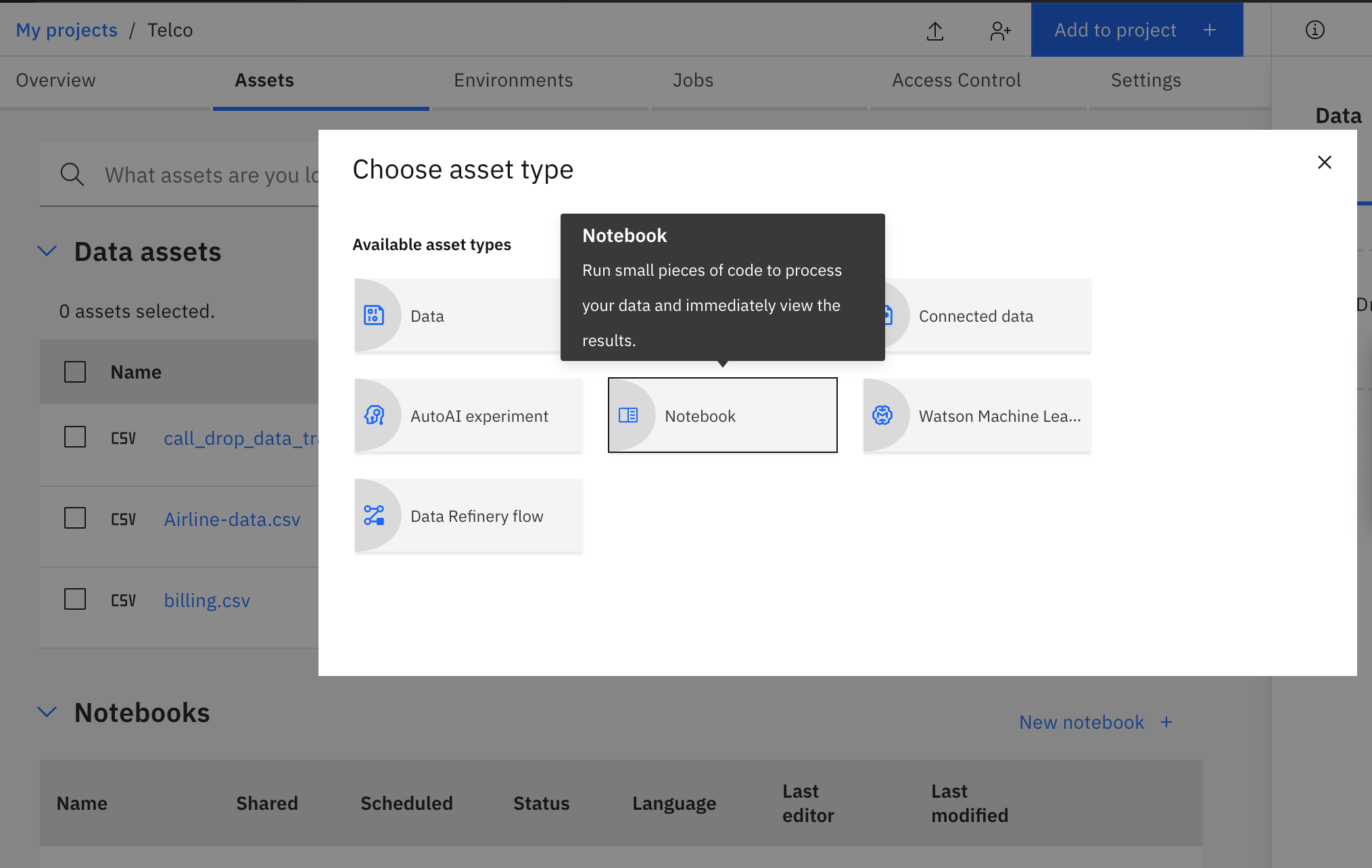
You will be taken to a new page. Click on the From URL tab. Enter this URL: https://github.com/IBM/icp4d-telco-manage-ml-project/blob/master/notebooks/Multivariate_Time_Series_MemSQL_DB.ipynb
8. Configure the notebook
Download the Telco_training_final.csv file and load it into a table named
call_drop_datain SingleStore. Refer to the documentation for instructions on how to load .CSV data into a SingleStore (using MySQL client).Select the cell which says "Insert Db2 Connection Credentials here", click on Connections in the assets tab and select
Insert to code > Insert Credentialsfrom your SingleStore Connection variable.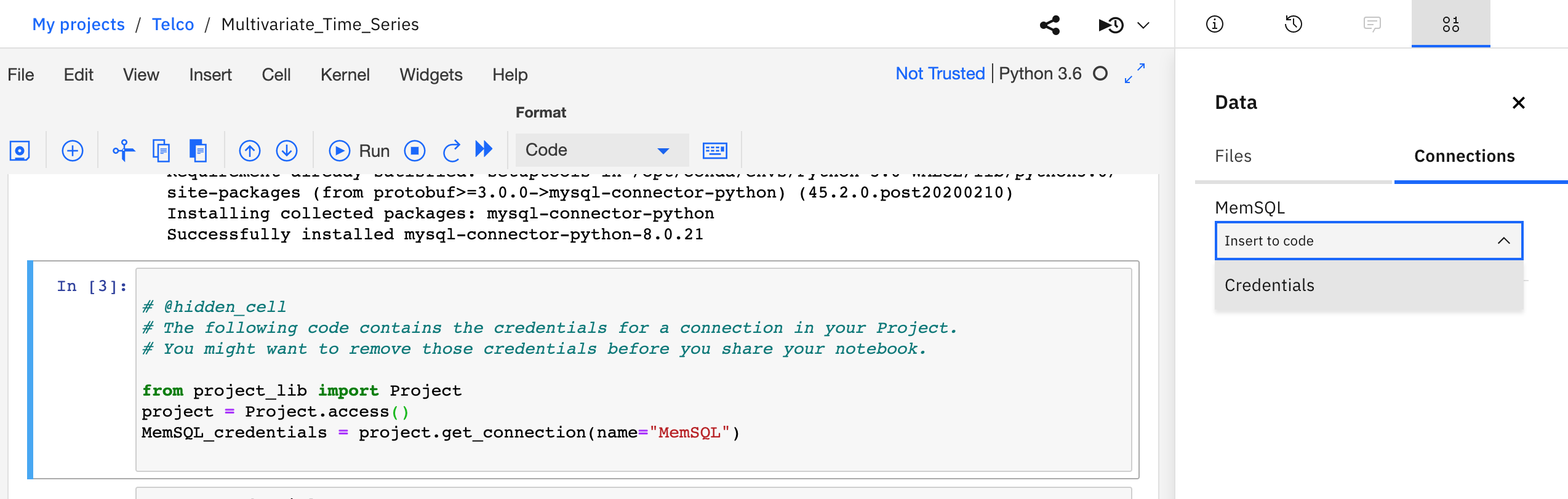
Your credentials will look something like the ones below:
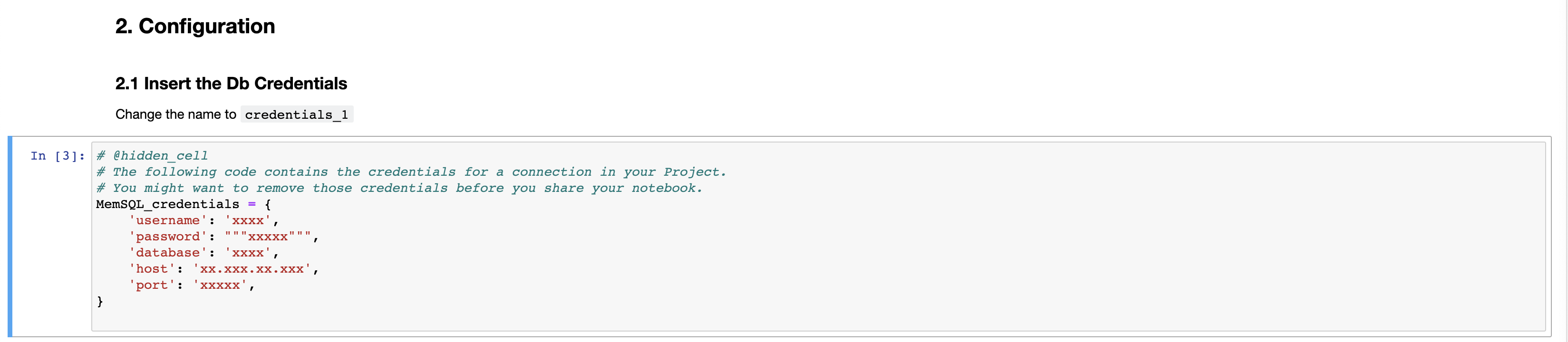
Run the notebook by selecting
Cell > Run all.
Note: You will run cells individually by highlighting each cell. Then, click the
Runbutton at the top of the notebook. While the cell is running, an asterisk ([*]) will show up to the left of the cell. When that cell has finished executing, a sequential number will appear (i.e.[17]).
After you have run the notebook you should be able to see the machine learning model output as below, which will be loaded into SingleStore.

References
- Want to learn more? Refer to the following documentation from SingleStore to learn more about the operator and its features.
- Refer to https://docs.singlestore.com/managed-service/en/reference/sql-reference/data-definition-language-ddl.html and SingleStore DB Data Manipulation Language (DML) for more information.
- Refer to the SingleStore (MemSQL) Operator Reference Overview for detailed configuration information.