Tutorial
Getting started: Using IBM DataStage SaaS
Create a joined dataset that contains COVID-19 case counts for a city's collegesDataStage is a true SaaS, cloud-native, cloud-first experience and has been re-built using shared/common services across the IBM Data and AI platform. Common concepts such as flows, jobs, projects, connections, environments, and more are utilized across the product. The DataStage flow canvas was built leveraging an open source project called Elyra, and the flow schema is an open source JSON standard.
Learning objectives
The purpose of this tutorial is to design a DataStage flow to satisfy the following problem statement:
As a data engineer, you have been asked by the line of business that you support to create a joined dataset that contains the COVID-19 case counts for colleges in the city of Providence, RI. You also need to enrich the dataset by adding the FIPS codes, a standard geographic identifier, to the target dataset.
In this tutorial, you will learn how to:
- Get started with the DataStage service
- Utilize a sample project that works with two COVID-19 datasets from The New York Times
- Work with a data connection
- Run a job
- View logs
- Import existing DataStage jobs
Prerequisites
You will need an IBM Cloud account to complete this tutorial.
Estimated time
Completing this tutorial should take about 30 minutes.
About the data
Learn how to get started with the DataStage service and work with a sample project that works with two COVID-19 public datasets. You can get more information about The New York Times COVID-19 datasets at Coronavirus in the U.S.: Latest Map and Case Count.
We will be working with two datasets:
- U.S. County data from The New York Times, based on reports from state and local health agencies
- The New York Times survey of U.S. Colleges and Universities
| Column Name | Data Type |
|---|---|
| DATE_FIPS | DATE |
| COUNTY | VARCHAR(60) |
| STATE_FIPS | CHAR(30) |
| FIPS | INTEGER(6) |
| CASES_FIPS | INTEGER(6) |
| DEATHS | INTEGER(6) |
| CONFIRMED_CASES | INTEGER(6) |
| CONFIRMED_DEATHS | INTEGER(6) |
| PROBABLE_CASES | INTEGER(6) |
| PROBABLE_DEATHS | INTEGER(6) |
| Column Name | Data Type |
|---|---|
| DATE | DATE |
| STATE | CHAR(30) |
| COUNTY | VARCHAR(60) |
| CITY | CHAR(30) |
| IPEDS | INTEGER(6) |
| COLLEGE | VARCHAR(200) |
| CASES | INTEGER(6) |
| NOTES | VARCHAR(200) |
Steps
Step 1. Create or utilize an existing IBM account
Start by creating or utilizing an existing IBM account and provisioning the required services on IBM Cloud®. Once registered, you will be re-directed to the IBM Cloud Pak for Data as a Service.
Step 2. Navigate to IBM Cloud Pak for Data as a Service
- Navigate to the IBM Cloud Pak for Data as a Service.
- Start by creating a new project.

- Select Create a project from a sample or file.

- Select the From Sample tab and pick the COVID-19 Tracking with IBM DataStage project from the gallery.
- Once the project is created, take a moment to explore the different capabilities of your project. Select the Assets tab and click the Add to project + blue button.

This displays all the assets available to be added to your IBM Cloud Pak for Data project. Notice the new DataStage flow asset. This is the main asset type that we will be working with.
Step 3. Utilize data connections
- Under the Data Assets section, select the pre-configured COVID Tracking: Colleges Connection.
- Select Test to test the connection.

Connection assets can be created to a variety of data sources and targets. Check out the source and targets supported by DataStage as a Service. A connection asset contains the information necessary to create a connection to a data source or target. Connection assets can be used from within the connectors on the DataStage flow canvas. The same connection can also be used in other products, such as IBM Watson® Studio or Watson Knowledge Catalog.
Step 4. Work with a DataStage flow
Navigate back to the Assets tab in your Project. We will now work with the DataStage flow canvas. Select the existing flow, COVID Tracking: Colleges in Providence, to open the canvas.
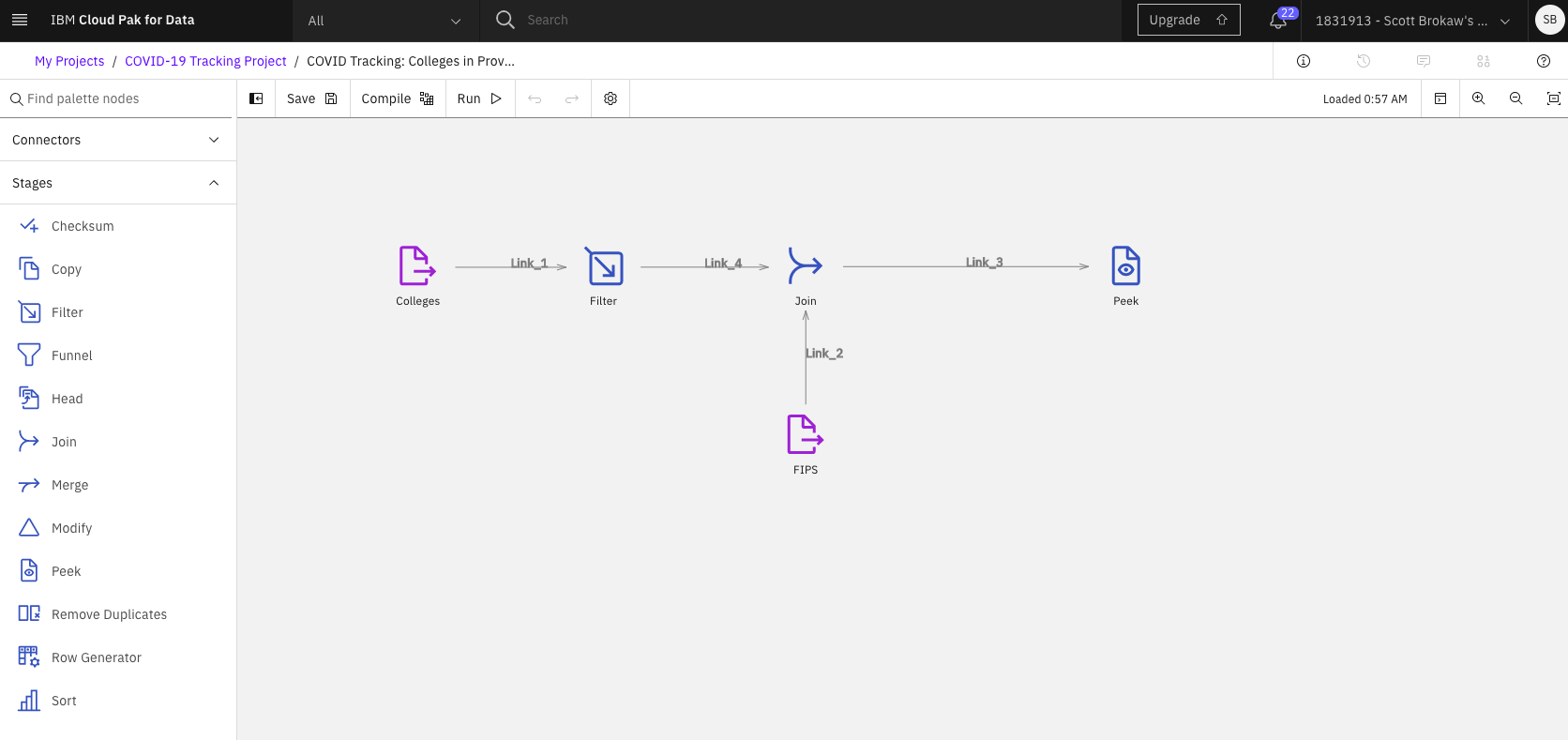
Explore the palette of connectors and stages that can be used to build DataStage flows. Interact with the canvas by dragging connectors and Stages around, detaching links and double clicking on Connectors or Stages to see their configuration properties.
This sample DataStage flow will extract data from two HTTP sources, filter the results of one of the sources, join the two datasets together on a common key, and write the resulting output dataset to the job log using a Peek Stage.
View the connections
- Once you've become familiar with the canvas, open the Colleges HTTP Connectors by double-clicking on the connector on the canvas.
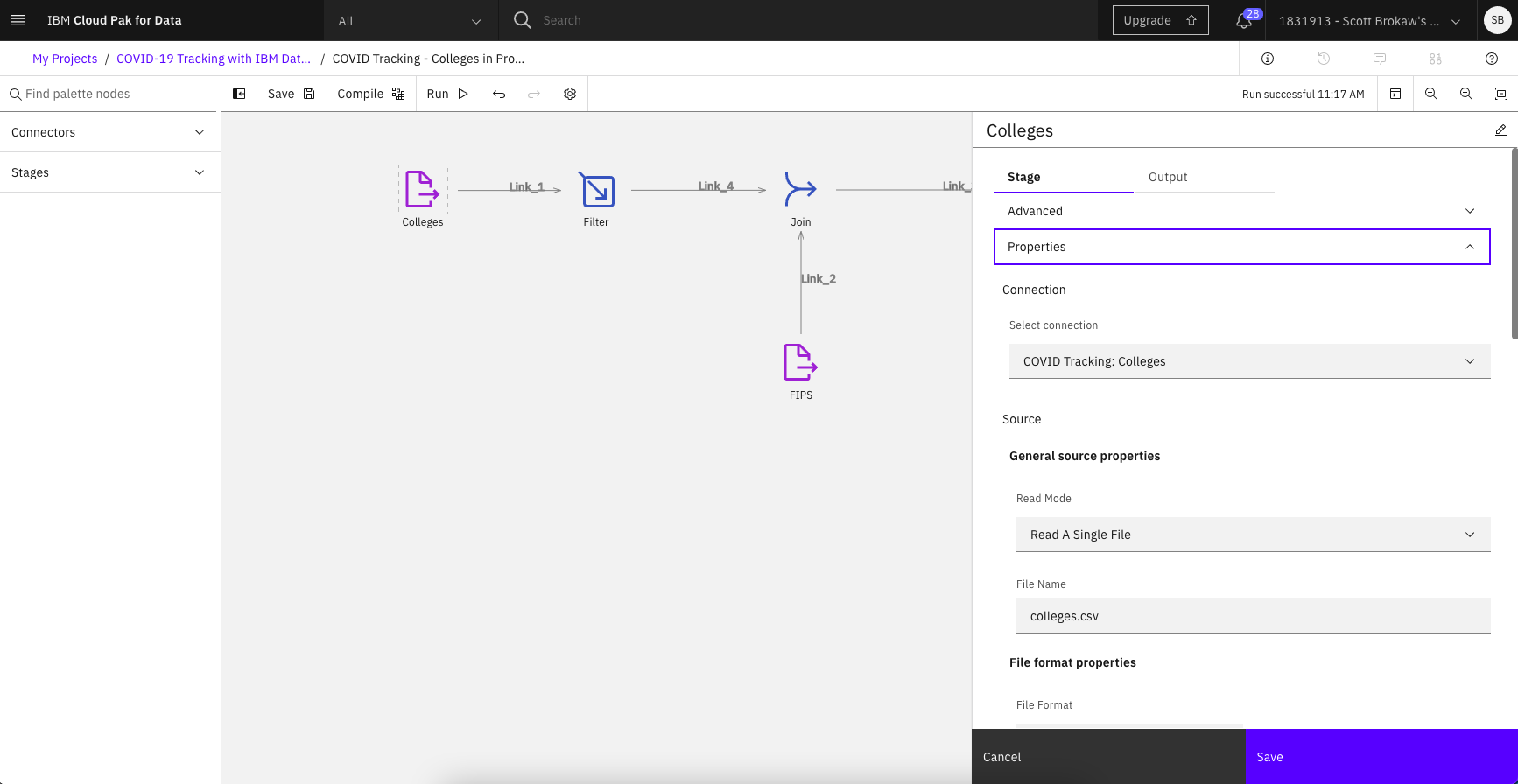 Notice the Select connection drop-down that allows you to select from existing HTTP connections that were defined within the project. Selecting the connection will populate all connection property configurations within the connector.
Notice the Select connection drop-down that allows you to select from existing HTTP connections that were defined within the project. Selecting the connection will populate all connection property configurations within the connector. - Select the Output tab within the connector properties, then click Edit Output Columns.

- Launch the column metadata tearsheet experience.
 Selecting columns also allows you to easily re-order or remove columns in bulk.
Selecting columns also allows you to easily re-order or remove columns in bulk. - Click Apply and return to return to the HTTP connector properties.
- Click Save to close the connector properties panel.
Understand the filter condition
- Double-click on the Filter stage to open the stage properties.

- Expand the Properties section and note the filter condition.
sql
city = 'Providence'
Filter conditions support standard SQL expressions. This expression will return all records pertinent to the city of Providence.
Understand the join condition
- Double-click on the Join stage to open the stage properties.

- Expand the Properties section and note the join key. This the key that will be used to perform a left outer-join of the two input streams, College and FIPS datasets.
- Select the Output tab in the Join stage properties, then click Edit Output Columns to view the column-mapping details.
 This view displays the joined dataset and how the inputs into the join stage will make up the target metadata. This is how you can select and map columns from the inputs to the target dataset.
This view displays the joined dataset and how the inputs into the join stage will make up the target metadata. This is how you can select and map columns from the inputs to the target dataset.
Step 5. Run a job
- Click the Run button on the canvas to save, compile, and run the DataStage flow.
- Click the Logs button to open the new log panel.

 Once the job completes, you will see a green successful banner indicating that the job is finished. The log panel has a type-ahead search and filtering capability that will refresh as new entries come into the log. In the example above, we're displaying all of the Peek messages, which represent the resulting target dataset.
Once the job completes, you will see a green successful banner indicating that the job is finished. The log panel has a type-ahead search and filtering capability that will refresh as new entries come into the log. In the example above, we're displaying all of the Peek messages, which represent the resulting target dataset. - To proceed to the next step, return to the project dashboard by clicking the project name in the breadcumb view on the top of the canvas.

Step 6. Interacting with jobs and viewing logs
A job is a platform runtime asset that is related and associated with a flow. There can be multiple jobs associated with the same flow. Jobs can be scheduled or run ad-hoc.
Jobs are automatically created for you when editing/working with a DataStage flow in the canvas. When you click Run on the canvas, a job is created and invoked. Jobs maintain their past invocations, and logs and can be viewed via the jobs dashboard.
There can be any number of jobs associated with a single flow. For this reason, we can say a flow has a one-to-many relationship with the job asset type.
Creating a job
- To create a job, select the expansion options off of a flow.

- The job creation wizard will take you through the available options for a job, including specifying a scheduled run.

Viewing job history
- Within the project dashboard, select the Jobs tab to display all jobs across your project. Select a job from the list to view past executions.
 From this display, you can also edit the properties of a job, including any schedule associated with it. You can also run the job ad-hoc.
From this display, you can also edit the properties of a job, including any schedule associated with it. You can also run the job ad-hoc. - Click on an execution to view additional details about the run.

- To proceed to the next step, return to the Project dashboard.
Step 7. Import existing DataStage jobs
The import and conversion of existing DataStage Jobs is paramount to the direction for DataStage as a Service. Our intention is to allow for the 20+ years of DataStage Parallel Job development to be seamlessly brought forward. As part of this commitment, the DataStage experience offers a preview into the integrated import experience.
The import service consumes a DataStage archive file (ISX) that can be generated from the traditional Information Server Manager Client or the istool CLI.
Kicking off an import
Invoking the import service is simple and can be accessed from the DataStage flow action. Once invoked, navigate to the ISX File Import tab.

The import service will take care of converting existing DataStage Jobs into the DataStage flow schema format. Once the ISX is uploaded and the import is kicked off, the import summary page will display. This page will update as the import progresses, or the URL can be bookmarked or accessed via the notifications bell to check on the status of the import later.

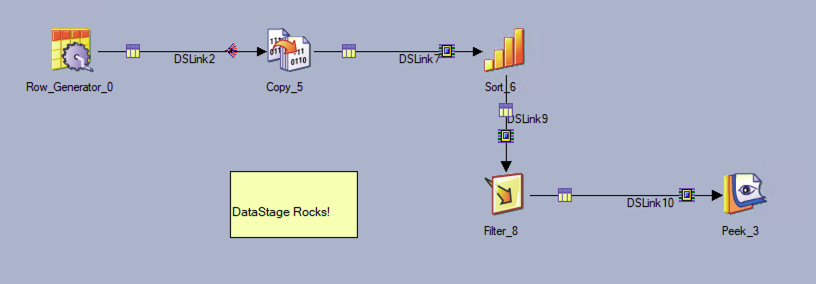
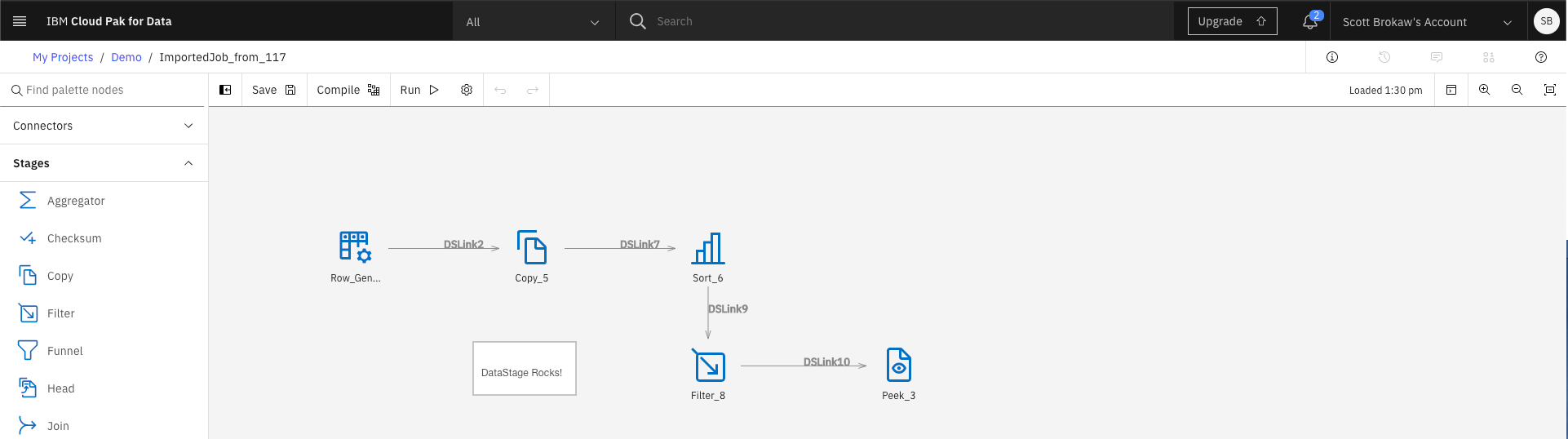
Example import
DataStage job as seen in the DataStage Windows Designer Client:
Converted DataStage flow:
Summary
This tutorial has shown you an example of how you can utilize the power of DataStage on IBM Cloud Pak for Data to perform Extract Transform Load (ETL) transformations in a SaaS environment.