Tutorial
Install and compile PostgreSQL on IBM Power Systems servers
Compilation of PostgreSQL for optimized performanceIntroduction
The primary focus of this tutorial is to study PostgreSQL database configuration with supported compilers such as GCC , LLVM, and IBM® Advance Toolchain on IBM Power Systems™ servers. Red Hat® Enterprise Linux (RHEL) 8.1 was used as the operating system with PostgreSQL installed on IBM Power Systems featuring the new IBM POWER9™ processor technology. PostgreSQL is an open source database that can handle a wide variety of high-volume transactions and heavy-reporting workloads. At the end of the study, users can understand the different compilers that can be used on IBM Power Systems servers with PostgreSQL. The tutorial briefly describes the testbed topology and shows how the configuration, tuning, and test runs were performed.
Installing and compiling PostgreSQL on IBM Power Systems
This section describes the steps to build PostgreSQL from source using different compilers such as Advance Toolchain, GCC, and LLVM.
Get the PostgreSQL source.
PostgreSQL sources can be obtained from the Source section on their official website: https://www.postgresql.org/download/
After getting the appropriate PostgreSQL version .tar file, extract it.
[root] # tar –zxvf postgresql-X.tar.gz [root] # cd postgresql-XWhere
Xis the version of PostgreSQL. After extracting the content, you can find a directory named, postgresql-X.Configure the source tree.
This step describes how to configure the source tree for the system and enable users to choose the required compiler options. Ensure that the following packages are installed
- make
- readline-devel
zlib-devel
Figure 1. Source code compilation process
Configure PostgreSQL using GCC.
GCC is part of the OS repository, and therefore, ensure that latest version of GCC is installed on the server. Run the following command to install GCC and other dependent packages on the system.
[root] # yum install gcc -yBy default, the configure script compiles using the latest GCC compiler available on the system. In case GCC is not available on the default PATH or multiple versions of GCC are installed, specify the absolute path.
[root] # ./configure CC=<GCC Directory>/bin/config-fileConfigure PostgreSQL using LLVM.
It is important to install the following packages to compile using the LLVM compiler and make sure that the versions of these packages are the same:
- llvm
- llvm-devel
- clang
Run the following command to install LLVM:
[root] # yum install llvm-toolset llvm-devel -yConfigure PostgreSQL using the
--with-llvmparameter. By default, the attribute searches for the llvm-config file under the /usr/bin/llvm-config path. Run the following command to configure PostgreSQL using LLVM.[root] # ./configure --with-llvmNote: If LLVM is installed in a different path, then use the code with the path.
[root] # ./configure --with-llvm=<PATH to llvm-config>[root] # ./configure –with-llvm=/usr/local/llvm-configConfigure PostgreSQL using IBM Advance Toolchain.
To install the latest version of IBM Advance Toolchain, visit: Installing Advance Toolchain for Linux on IBM Power Systems
Make a note of the path where IBM Advance Toolchain is installed. The default location is /opt/atX/bin, where X is the version of IBM Advance Toolchain.
Configure the source code using IBM Advance Toolchain with additional runtime parameters as follows:
[root] # ./configure CC=<PATH to IBM Advance Toolchain> CFLAGS='-O3 -mcpu=power9 -mtune=power9'In our case study, we used IBM Advance Toolchain 13.0
[root] # ./configure CC=/opt/at13.0/bin/powerpc64le-linux-gnu-gcc CFLAGS='-O3 -mcpu=power9 -mtune=power9'Note: For additional configuration options, visit https://www.postgresql.org/docs/
After successful completion of configuration, you can now build and install PostgreSQL using the following commands:
[root] # make all[root] # make installAfter successful installation, you can find the binary files in the /usr/local/pgsql/bin/ folder and the required libraries and header files in the /usr/local/pgsql/include/ folder.
Starting the PostgreSQL server
Perform the following steps to start the PostgreSQL server:
Create a directory to stage the PostgreSQL database files. Create a user (for example, enterprisedb) and set the home directory to the user.
[root] # useradd enterprisedb [root] # mkdir /dbdirectory/ [root] # usermod -d /dbdirectory/ enterprisedb [root] # chown enterprisedb:enterprisedb /dbdirectory/ [root] # chmod -R 755 /dbdirectory/Switch to the enterprisedb user and create a new PosgreSQL database instance under enterprisedb’s home directory using the
initdbcommand.[enterprisedb] # initdb -D /dbdirectory/data/Start the PostgreSQL server using the
pgctlcommand.[enterprisedb] # pg_ctl -D /dbdirectory/ logfile start
Monitor the logfile for status and errors (if any). If no errors, we have successfully started the PostgreSQL server.
Testbed topology
The testbed topology consists of IBM Power® System IC922 server. The custom-built PostgreSQL (binary/library files) were exposed to various combinations of pgbench tests to understand the impact of each supported compiler on PostgreSQL throughput.
Figure 2. Testbed topology
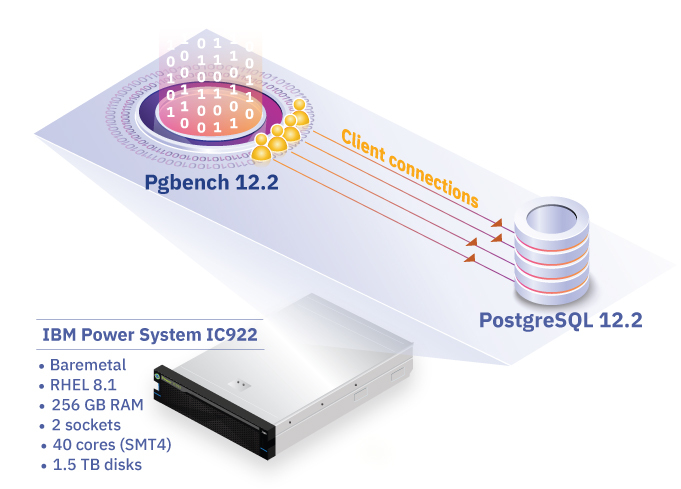
IBM Power Systems
For this case study, we have used an IBM POWER9 processor-based server with 20 cores per socket on a two-socket system with a frequency of (2.9 GHz to 3.8 GHz).
The testbed system is configured to include 256 GB memory, 3.6 TB hard disk space, and 40 physical processor cores. RHEL 8.1 is the operating system installed on the Power IC922 server for this study.
Software stack
The software stack used in this study consists of:
- RHEL 8.1 (4.18.0-147.5.1.el8_1.ppc64le)
- PostgreSQL version 12.2
- IBM Advance Toolchain 13.0.1
- GCC 8.3.1
- LLVM 8.0.1
Tuning parameters
It was proven that the following kernel and OS settings has shown better performance on POWER9 processor-based servers.
Kernel tuning
The following parameters allow us to tune kernel for optimal performance on IBM Power Systems servers.
fs.file-max=65535
vm.zone_reclaim_mode=0
vm.drop_caches=3
vm.dirty_ratio=60
vm.dirty_background_ratio=60
vm.dirty_background_bytes=37108864
vm.dirty_bytes=296870912
vm.hugetlb_shm_group=`id -g <group_name>`
vm.hugepages_treat_as_movable=0
vm.nr_hugepages=2000
vm.nr_overcommit_hugepages=512
kernel.sched_autogroup_enabled=1
vm.swappiness=0
Set the following parameters based on the memory available on your system memory:
shmall – Sets the total amount of shared memory pages that can be used system wide.
shmall=$(( `grep MemTotal /proc/meminfo |awk '{print $2}'` * 1024 * 9 / (`getconf PAGE_SIZE` * 10))) sudo sysctl -w kernel.shmall=$shmallshmmax – Sets the upper limit of shared memory a process can request.
shmmax=$(( `grep MemTotal /proc/meminfo |awk '{print $2}'` * 1024 * 8 / 10 )) sudo sysctl -w kernel.shmmax=$shmmax
OS tuning
The following parameters allow us to tune the operating system for better performance on IBM Power Systems servers.
ppc64_cpu --smt-snooze-delay=0
ppc64_cpu --dscr=1
systemctl stop firewalld
systemctl disable firewalld
Workload execution
This section shows how to run the workload and gather performance results by running an auto-run-test.sh script available in the appendix section.
Before running the auto-run-test.sh script, create a copy of the postgresql.conf file on the parent folder of $HOME/.
[enterprisedb] $ cd $HOME [enterprisedb] $ cp /dbdirectory/data/postgresql.conf /dbdirectory/postgresql.confCreate a directory named, tc, which would contain the input variables passed to auto-run-test.sh.
[enterprisedb] $ mkdir /dbdirectory/tcCreate a file, named t1.tc, under the /dbdirectory/tc directory, which redirects the custom variable information to the workload.
runname=<name of the run> SCALE=<The workload i.e number of rows> runtime=<the duration for which pgbench is run> thread="Number of worker threads within pgbench" smtlist=<sets smtlist value> mode=select recreateinstance=<Reinitializing the DB yes or no> recreateduringrun=< Recreate and populate DB before each run > warmup=<Warm up the cache yes or no> perf_stat=< Start Perf Data collection yes or no> PGSQL=/path/to/pgsql/bin PGPORT=<pgsql port number> cores=<number of cores>Sample t1.tc file
runname=select-1000run3 SCALE=1000 runtime=300 thread="200 260 320 380 440" smtlist="4" mode=select recreateinstance=yes recreateduringrun=yes warmup=no perf_stat=yes PGSQL=/usr/local/pgsql/bin PGPORT=5432 cores=40Run the auto-run-test.sh script.
[enterprisedb] $ /dbdirectory/auto-run-test.shThis custom script is tailored to trigger different scales of pgbench workload and also allows multiple users to query the database. The values pertaining to workload and users can be supplied from the t1.tc file. Upon completion of the workload, a summary is displayed on the screen.
Sample output
Number of cores online = 40 CPU(s): 160 SMT=4 MemTotal: 263783488 kB Client TPS ------ --- XXX YYYYY.YYYYY
Conclusion
This study explains the steps involved in configuration of PostgreSQL with LLVM, GCC, and IBM Advance Toolchain compilers and also describes the behavior of PostgreSQL on IBM Power Systems servers using the pgbench workload generator. It is advised to always use the latest version of IBM Advance Toolchain on IBM Power Systems servers for optimal performance.
Appendix
This section provides additional reference for users to better understand about the study.
-
Refer to the postgres.conf parameter that was used while starting the PostgreSQL instance.
-
This file was used to start the PostgreSQL instance.