Tutorial
Network file systems and Linux
NFS: As useful as ever and still evolvingArchive date: 2023-03-24
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.A network file system is a network abstraction over a file system that allows a remote client to access it over a network in a similar way to a local file system. Although not the first such system, NFS has grown and evolved into the most powerful and widely used network file system in UNIX®. NFS permits sharing of a common file system among a multitude of users and provides the benefit of centralizing data to minimize needed storage.
This article begins with a short history of NFS, its origins, and how it has evolved. It then explores the NFS architecture and where NFS is going.
A short history of NFS
The first network file system—called File Access Listener—was developed in 1976 by Digital Equipment Corporation (DEC). An implementation of the Data Access Protocol (DAP), it was part of the DECnet suite of protocols. Like TCP/IP, DEC published protocol specifications for its networking protocols, which included the DAP.
NFS was the first modern network file system (built over the IP protocol). It began as an experimental file system developed in-house at Sun Microsystems in the early 1980s. Given the popularity of the approach, the NFS protocol was documented as a Request for Comments (RFC) specification and evolved into what is known as NFSv2. As a standard, NFS grew quickly because of its ability to interoperate with other clients and servers.
The standard continued to evolve into NFSv3, defined by RFC 1813. This iteration of the protocol was much more scalable than previous versions, supporting large files (larger than 2GB), asynchronous writes, and TCP as the transport protocol, paving the way for file systems over wide area networks. In 2000, RFC 3010 (revised by RFC 3530) brought NFS into the enterprise setting. Sun introduced NFSv4 with strong security along with a stateful protocol (prior versions of NFS were stateless). Today, NFS exists as version 4.1 (as defined by RFC 5661), which adds protocol support for parallel access across distributed servers (called the pNFS extension).
The timeline of NFS, including the specific RFCs that document its behavior, is shown in Figure 1.
Figure 1. Timeline of NFS protocols

Amazingly, NFS has been under development for almost 30 years. It represents an extremely stable (and portable) networked file system that's scalable, high performing, and enterprise quality. As network speeds increase and latencies decrease, NFS continues to be an attractive option for serving a file system over a network. Even in local network settings, virtualization drives storage into the network to support more mobile virtual machines. NFS even supports the latest computing models to optimize virtualized infrastructures.
The NFS architecture
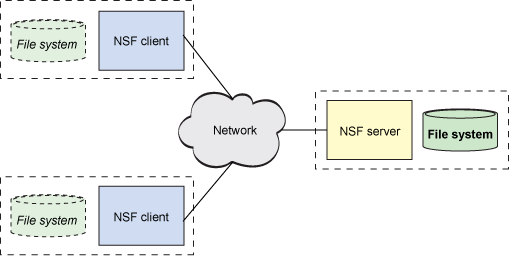
NFS follows the client-server model of computing (see Figure 2). The server implements the shared file system and storage to which clients attach. The clients implement the user interface to the shared file system, mounted within the client's local file space.
Figure 2. The client-server architecture of NFS
Within Linux®, the virtual file system switch (VFS) provides the means to support multiple file systems concurrently on a host (such as International Organization for Standardization [ISO] 9660 on a CD-ROM and ext3fs on the local hard disk). The VFS determines which storage a request is intended for, then which file system must be used to satisfy the request. For this reason, NFS is a pluggable file system just like any other. The only difference with NFS is that input/output (I/O) requests may not be satisfied locally, instead having to traverse the network for completion.
Once a request is found to be destined for NFS, VFS passes it to the NFS instance within the kernel. NFS interprets the I/O request and translates it into an NFS procedure (OPEN, ACCESS, CREATE, READ, CLOSE, REMOVE, and so on). These procedures, which are documented within the particular NFS RFC, specify the behaviors within the NFS protocol. Once a procedure is selected from the I/O request, it is performed within the remote procedure call (RPC) layer. As the name implies, RPC provides the means to perform procedure calls between systems. It marshals the NFS request and accompanying arguments together, manages sending them to the appropriate remote peer, and then manages and tracks the response, providing it to the appropriate requester.
Further, RPC includes an important interoperability layer called external data representation (XDR), which ensures that all NFS participants speak the same language when it comes to data types. When a given architecture performs a request, the data type representation may differ from the target host that satisfies the request. XDR takes care of converting types to the common representation (XDR) so that all architectures can interoperate and share file systems. XDR specifies the bit format for types such as float and the byte ordering for types such as fixed and variable-length arrays. Although XDR is best known for its use in NFS, it's a useful specification whenever you're dealing with multiple architectures in a common application setting.
Once XDR has translated the data into the common representation, the request is transferred over the network given a transport layer protocol. Early NFS used the Universal Datagram Protocol (UDP), but today TCP is commonly used for greater reliability.
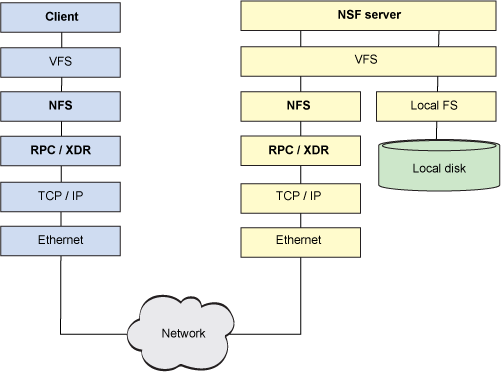
At the server, NFS operates in a similar fashion. The request flows up the network stack, through RPC/XDR (to translate the data types to the server's architecture), and to the NFS server. The NFS server is responsible for satisfying the request. The request is passed up to the NFS daemon, which identifies the target file system tree needed for the request, and VFS is again used to get to that file system in local storage. This entire process is shown in Figure 3. Note here that the local file system at the server is a typical Linux file system (such as ext4fs). As such, NFS is not a file system in the traditional sense but instead a protocol for accessing file systems remotely.
Figure 3. The client and server NFS stack
For higher-latency networks, NFSv4 implements what's called the compound procedure. This procedure essentially permits multiple RPC calls to be embedded within a single request to minimize the transfer tax of the request over the network. It also implements a callback scheme for responses.
The NFS protocol
From the client's perspective, the first operation to occur within NFS is called a mount. Mount represents the mounting of a remote file system into the local file system space. This process begins as a call to mount (a Linux system call), which is routed through the VFS to the NFS component. After establishing the port number for the mount (via the get_port request RPC call to the remote server), the client performs an RPC mount request. This request occurs between the client and a special daemon responsible for the mount protocol (rpc.mountd). This daemon checks the client request against the server's list of currently exported file systems; if the requested file system exists and the client has access, an RPC mount reply establishes the file handle for the file system. The client side stores the remote mount information with the local mount point and establishes the ability to perform I/O requests. This protocol represents a potential security issue; therefore, NFSv4 replaces this ancillary mount protocol with internal RPC calls for managing the mount point.
To read a file, the file must first be opened. There's no OPEN procedure within RPC; instead, the client simply checks to see if the directory and file exist within the mounted file system. The client begins with a GETATTR RPC request for the directory, which results in a response with the attributes of the directory or an indication that the directory does not exist. Next, the client issues a LOOKUP RPC request to see if the requested file exists. If so, a GETATTR RPC request is issued for the requested file that returns the attributes for the file. Based upon successful GETATTRs and LOOKUPs, the client creates a file handle that is provided to the user for future requests.
With the file identified in the remote file system, the client can issue READ RPC requests. The READ consists of the file handle, state, offset, and count for the read. The client uses the state to determine whether the operation can be performed (that is, whether the file is locked). The offset indicates where to begin reading, and the count identifies the number of bytes to read. The server may or may not return the number of bytes requested but identifies the number of bytes returned (along with the data) within the READ RPC reply.
Innovation in NFS
The last two versions of NFS (4 and 4.1) are among the most interesting and important for NFS. Let's look at some of the most important aspects of NFS's evolution.
Prior to NFSv4, there existed a number of ancillary protocols for mounting, locks, and other elements in file management. NFSv4 simplifies this process to one protocol and removes support for UDP as a transport protocol. NFSv4 also integrates support for UNIX and Windows®-based file access semantics, extending NFS for native integration into other operating systems.
NFSv4.1 introduces the concept of parallel NFS (pNFS) for higher scaling and higher performance. To support greater scaling, NFSv4.1 implements a split data/metadata architecture with striping in a manner similar to clustered file systems. As shown in Figure 4, pNFS breaks the ecosystem down into three parts: the client, the server, and storage. You can see that two paths exist: one for the data and one for control. pNFS splits the layout of the data from the data itself, permitting the dual-path architecture. When a client wants to access a file, the server responds with the layout. The layout describes the mapping of the file to the storage devices. When the client has the layout, it can directly access the storage without having to work through the server (which permits greater scaling and performance). When the client is finished with the file, it commits the data (changes) and the layout. If needed, the server can request the layout back from the client.
pNFS implements a number of new protocol operations to support this behavior. LayoutGet and LayoutReturn get and release the layout from the server, respectively, while LayoutCommit commits the data from the client to the storage so that it's available to other users. The server recalls the layout from a client using LayoutRecall. The layout is spread across some number of storage devices to enable parallel access and higher performance.
Figure 4. NFSv4.1's pNFS architecture
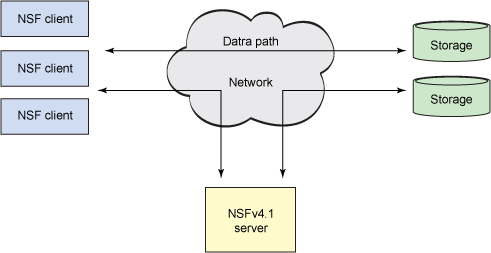
Both the data and metadata are stored in the storage area. The clients may perform direct I/O given receipt of the layout, and the NFSv4.1 server handles metadata management and storage. Although this behavior isn't necessarily new, pNFS adds the ability to support multiple access methods for the storage. Today, pNFS supports the use of block-based protocols (Fibre Channel), object-based protocols, and NFS itself (even in a non-pNFS form).
Work continues on NFS, with the requirements for NFSv2 being published in September 2010. Some of the new advancements address the changing world of storage in virtualization environments. For example, duplication of data is very likely in hypervisor environments (many operating systems read/writing and caching the same data). For this reason, it's desirable for the storage system as a whole to understand where duplication occurs. This would preserve cache space at the client and capacity at the storage end. NFSv4.2 proposes a block map of shared blocks to deal with this problem. Because storage systems have begun to integrate processing capabilities in the back end, server-side copy is introduced to offload the interior storage network of data copy when it can be done efficiently at the storage back end itself. Other innovations are appearing, as well, including sub-file caching for flash memory and client-side hints for I/O (potentially using mapadvise as the path).
Alternatives to NFS
Although NFS is the most popular network file system on UNIX and Linux systems, it's certainly not the only choice. On Windows® systems, Server Message Block [SMB], also known as CIFS) is the most widely used option (though Windows also supports NFS, as Linux supports SMB).
One of the latest distributed file systems, which is also supported in Linux, is Ceph. Ceph was designed from the ground up as a fault-tolerant distributed file system with Portable Operating System Interface for UNIX (POSIX) compatibility. You can learn more about Ceph in resources on the right.
Other examples include OpenAFS, an open source version of the Andrew distributed file system (from Carnegie Mellon and IBM), GlusterFS, which focuses on a general-purpose distributed file system for scalable storage, and Lustre, which is a massively parallel distributed file system focusing on cluster computing. All are open source software solutions for distributed storage.
Going farther
NFS continues to evolve, and similar to the evolution of Linux (supporting low-end, embedded, and high-end performance), NFS implements a scalable storage solution for consumers and enterprises. It will be interesting to see what's ahead for NFS, but given its history and a peek into the near term, it will change the way we view and use file storage.