Tutorial
Linux virtualization and PCI passthrough
Device emulation and hardware I/O virtualizationArchive date: 2023-03-24
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Platform virtualization is about sharing a platform among two or more operating systems for more efficient use of resources. But platform implies more than just a processor: it also includes the other important elements that make up a platform, including storage, networking, and other hardware resources. Some hardware resources can easily be virtualized, such as the processor or storage, but other hardware resources cannot, such as a video adapter or a serial port. Peripheral Component Interconnect (PCI) passthrough provides the means to use those resources efficiently, when sharing is not possible or useful. This article explores the concept of passthrough, discusses its implementation in hypervisors, and details the hypervisors that support this recent innovation.
Platform device emulation
Before we jump into passthrough, let's explore how device emulation works today in two hypervisor architectures. The first architecture incorporates device emulation within the hypervisor, while the second pushes device emulation to a hypervisor-external application.
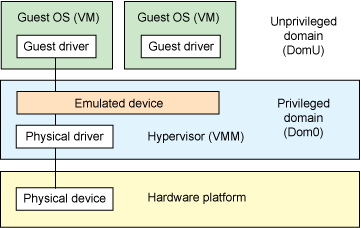
Device emulation within the hypervisor is a common method implemented within the VMware workstation product (an operating system-based hypervisor). In this model, the hypervisor includes emulations of common devices that the various guest operating systems can share, including virtual disks, virtual network adapters, and other necessary platform elements. This particular model is shown in Figure 1.
Figure 1. Hypervisor-based device emulation
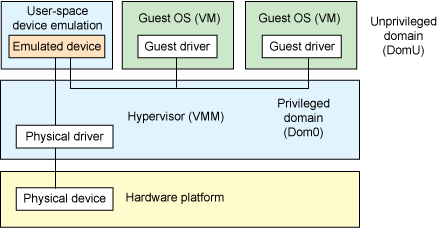
The second architecture is called user space device emulation (see Figure 2). As the name implies, rather than the device emulation being embedded within the hypervisor, it is instead implemented in user space. QEMU (which provides not only device emulation but a hypervisor as well) provides for device emulation and is used by a large number of independent hypervisors (Kernel-based Virtual Machine [KVM] and VirtualBox being just two). This model is advantageous, because the device emulation is independent of the hypervisor and can therefore be shared between hypervisors. It also permits arbitrary device emulation without having to burden the hypervisor (which operates in a privileged state) with this functionality.
Figure 2. User space device emulation
Pushing the device emulation from the hypervisor to user space has some distinct advantages. The most important advantage relates to what's called the trusted computing base (TCB). The TCB of a system is the set of all components that are critical to its security. It stands to reason, then, that if the system is minimized, there exists a smaller probability of bugs and, therefore, a more secure system. The same idea exists with the hypervisor. The security of the hypervisor is crucial, as it isolates multiple independent guest operating systems. With less code in the hypervisor (pushing the device emulation into the less privileged user space), the less chance of leaking privileges to untrusted users.
Another variation on hypervisor-based device emulation is paravirtualized drivers. In this model, the hypervisor includes the physical drivers, and each guest operating system includes a hypervisor-aware driver that works in concert with the hypervisor drivers (called paravirtualized, or PV, drivers).
Regardless of whether the device emulation occurs in the hypervisor or on top in a guest virtual machine (VM), the emulation methods are similar. Device emulation can mimic a specific device (such as a Novell NE1000 network adapter) or a specific type of disk (such as an Integrated Device Electronics [IDE] drive). The physical hardware can differ greatly—for example, while an IDE drive is emulated to the guest operating systems, the physical hardware platform can use a serial ATA (SATA) drive. This is useful, because IDE support is common among many operating systems and can be used as a common denominator instead of all guest operating systems supporting more advanced drive types.
Device passthrough
As you can see in the two device emulation models discussed above, there's a price to pay for sharing devices. Whether device emulation is performed in the hypervisor or in user space within an independent VM, overhead exists. This overhead is worthwhile as long as the devices need to be shared by multiple guest operating systems. If sharing is not necessary, then there are more efficient methods for sharing devices.
So, at the highest level, device passthrough is about providing an isolation of devices to a given guest operating system so that the device can be used exclusively by that guest (see Figure 3). But why is this useful? Not surprisingly, there are a number of reasons why device passthrough is worthwhile. Two of the most important reasons are performance and providing exclusive use of a device that is not inherently shareable.
Figure 3. Passthrough within the hypervisor
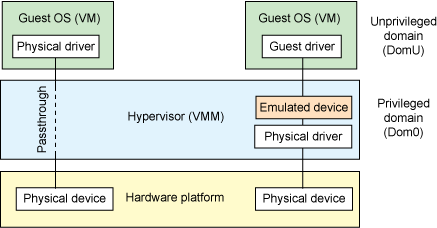
For performance, near-native performance can be achieved using device passthrough. This is perfect for networking applications (or those that have high disk I/O) that have not adopted virtualization because of contention and performance degradation through the hypervisor (to a driver in the hypervisor or through the hypervisor to a user space emulation). But assigning devices to specific guests is also useful when those devices cannot be shared. For example, if a system included multiple video adapters, those adapters could be passed through to unique guest domains.
Finally, there may be specialized PCI devices that only one guest domain uses or devices that the hypervisor does not support and therefore should be passed through to the guest. Individual USB ports could be isolated to a given domain, or a serial port (which is itself not shareable) could be isolated to a particular guest.
Underneath the covers of device emulation
Early forms of device emulation implemented shadow forms of device interfaces in the hypervisor to provide the guest operating system with a virtual interface to the hardware. This virtual interface would consist of the expected interface, including a virtual address space representing the device (such as shadow PCI) and virtual interrupt. But with a device driver talking to a virtual interface and a hypervisor translating this communication to actual hardware, there's a considerable amount of overhead—particularly in high-bandwidth devices like network adapters.
Xen popularized the PV approach (discussed in the previous section), which reduced the degradation of performance by making the guest operating system driver aware that it was being virtualized. In this case, the guest operating system would not see a PCI space for a device (such as a network adapter) but instead a network adapter application programming interface (API) that provided a higher-level abstraction (such as a packet interface). The downside to this approach was that the guest operating system had to be modified for PV. The upside was that you can achieve near-native performance in some cases.
Early attempts at device passthrough used a thin emulation model, in which the hypervisor provided software-based memory management (translating guest operating system address space to trusted host address space). And while early attempts provided the means to isolate a device to a particular guest operating system, the approach lacked the performance and scalability required for large virtualization environments. Luckily, processor vendors have equipped next-generation processors with instructions to support hypervisors as well as logic for device passthrough, including interrupt virtualization and direct memory access (DMA) support. So, instead of catching and emulating access to physical devices below the hypervisor, new processors provide DMA address translation and permissions checking for efficient device passthrough.
Hardware support for device passthrough
Both Intel and AMD provide support for device passthrough in their newer processor architectures (in addition to new instructions that assist the hypervisor). Intel calls its option Virtualization Technology for Directed I/O (VT-d), while AMD refers to I/O Memory Management Unit (IOMMU). In each case, the new CPUs provide the means to map PCI physical addresses to guest virtual addresses. When this mapping occurs, the hardware takes care of access (and protection), and the guest operating system can use the device as if it were a non-virtualized system. In addition to mapping guest to physical memory, isolation is provided such that other guests (or the hypervisor) are precluded from accessing it. The Intel and AMD CPUs provide much more virtualization functionality. You can learn more in the resources section.
Another innovation that helps interrupts scale to large numbers of VMs is called Message Signaled Interrupts (MSI). Rather than relying on physical interrupt pins to be associated with a guest, MSI transforms interrupts into messages that are more easily virtualized (scaling to thousands of individual interrupts). MSI has been available since PCI version 2.2 but is also available in PCI Express (PCIe), where it allows fabrics to scale to many devices. MSI is ideal for I/O virtualization, as it allows isolation of interrupt sources (as opposed to physical pins that must be multiplexed or routed through software).
Hypervisor support for device passthrough
Using the latest virtualization-enhanced processor architectures, a number of hypervisors and virtualization solutions support device passthrough. You'll find support for device passthrough (using VT-d or IOMMU) in Xen and KVM as well as other hypervisors. In most cases, the guest operating system (domain 0) must be compiled to support passthrough, which is available as a kernel build-time option. Hiding the devices from the host VM may also be required (as is done with Xen using pciback). Some restrictions apply in PCI (for example, PCI devices behind a PCIe-to-PCI bridge must be assigned to the same domain), but PCIe does not have this restriction.
Additionally, you'll find configuration support for device passthrough in libvirt (along with virsh), which provides an abstraction to the configuration schemes used by the underlying hypervisors.
Problems with device passthrough
One of the problems introduced with device passthrough is when live migration is required. Live migration is the suspension and subsequent migration of a VM to a new physical host, at which point the VM is restarted. This is a great feature to support load balancing of VMs over a network of physical hosts, but it presents a problem when passthrough devices are used. PCI hotplug (of which there are several specifications) is one aspect that needs to be addressed. PCI hotplug permits PCI devices to come and go from a given kernel, which is ideal—particularly when considering migration of a VM to a hypervisor on a new host machine (devices need to be unplugged, and then subsequently plugged in at the new hypervisor). When devices are emulated, such as virtual network adapters, the emulation provides a layer to abstract away the physical hardware. In this way, a virtual network adapter migrates easily within the VM (also supported by the Linux® bonding driver, which allows multiple logical network adapters to be bonded to the same interface).
Next steps in I/O virtualization
The next steps in I/O virtualization are actually happening today. For example, PCIe includes support for virtualization. One virtualization concept that's ideal for server virtualization is called Single-Root I/O Virtualization (SR-IOV). This virtualization technology (created through the PCI-Special Interest Group, or PCI-SIG) provides device virtualization in single-root complex instances (in this case, a single server with multiple VMs sharing a device). Another variation, called Multi-Root IOV, supports larger topologies (such as blade servers, where multiple servers can access one or more PCIe devices). In a sense, this permits arbitrarily large networks of devices, including servers, end devices, and switches (complete with device discovery and packet routing).
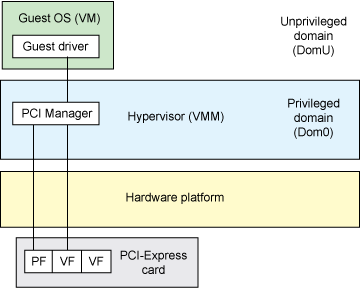
With SR-IOV, a PCIe device can export not just a number of PCI physical functions but also a set of virtual functions that share resources on the I/O device. The simplified architecture for server virtualization is shown in Figure 4. In this model, no passthrough is necessary, because virtualization occurs at the end device, allowing the hypervisor to simply map virtual functions to VMs to achieve native device performance with the security of isolation.
Figure 4. Passthrough with SR-IOV
Going further
Virtualization has been under development for about 50 years, but only now is there widespread attention on I/O virtualization. Commercial processor support for virtualization has been around for only five years. So, in essence, we're on the cusp of what's to come for platform and I/O virtualization. And as a key element of future architectures like cloud computing, virtualization will certainly be an interesting technology to watch as it evolves. As usual, Linux is on the forefront for support of these new architectures, and recent kernels (2.6.27 and beyond) are beginning to include support for these new virtualization technologies.