Tutorial
Explore Node.js basic concepts
Build the foundation you need to start developing Node.js APIsIn this tutorial, I do a deep dive into asynchronous and synchronous programming. To fully understand this concept, I walk you through 3 different scenarios that compare the 2 programming models and demonstrate why Node's asynchronous programming model makes it so powerful.
I also cover some key concepts along the way, including Node.js's module system, performance profiling, and Node's http module.
Get the code
The code you need to follow along with the examples in this learning path is in my GitHub repo.
Node programming style
If you search the web for Node.js, you won't have to scroll through many results before a theme becomes apparent: Node.js uses a non-blocking - asynchronous - coding style. You might be wondering, "Why would Node force developers to do this?" I'll explain the answer to that question in this tutorial and give you a few more Node tools.
But first, I want to tell you a story that illustrates the difference between blocking (synchronous) and non-blocking (asynchronous) coding.
The bank and the coffee shop
This story is about 2 familiar types of business: the bank and the coffee shop. While they serve different purposes, fundamentally, they exist to serve us. How they do that is very different.
The bank (blocking)
You walk into your local bank branch, and in front of you is a queue of customers. In front of the queue are several teller windows, and behind each open window sits a teller assisting a single customer.
The banking model of transaction processing is blocking:
- A single teller can only help one customer at a time.
- The teller handles all steps in your transaction in order.
- If the teller cannot handle a step in your transaction, let's say it requires a supervisor's approval, the teller is blocked waiting for the approval before he or she may proceed.
- When the entire transaction is complete, you leave the teller window.
To serve more customers or serve customers more quickly, this model can scale in 2 ways:
- Vertically: Add more tellers
- Horizontally: Add more bank branches
The nature of a banking transaction is synchronous. The teller alone must complete all steps in the transaction before the teller can assist another customer.
The coffee shop (non-blocking)
You walk into your local coffee shop, and in front of you is a queue of customers. In front of the queue is one counter employee who takes orders and processes payment, and one or more baristas behind the counter are preparing orders.
The coffee shop model of transaction processing is non-blocking:
- A single counter employee can only help one customer at a time.
- A barista prepares one order at a time.
- The counter employee and barista share all the steps to complete your order.
- While the barista prepares your order, the counter employee is not blocked and can take other customer's order.
- Later, when your order is ready, your name is called, and you step forward to collect it.
To serve more customers or serve customers faster, this model can scale in two ways:
- Vertically: Add more baristas
- Horizontally: Add more coffee shops
The nature of a coffee shop transaction is asynchronous. The counter employee simply takes orders, processes payment, and collects enough information so that the customer can be notified when his or her order is ready. The counter employee then helps the next customer, while the barista, in parallel, works on fulfilling orders.
Blocking versus non-blocking
Blocking: At the bank, the teller helps you from start to finish. Customers in the queue behind you must wait until your entire transaction is complete. If there is a step in the transaction that cannot be completed by the teller, the teller is blocked while that step is completed.
Non-blocking: At the coffee shop, the counter employee and the barista work together to complete your order. The counter employee takes your order and is not blocked while the barista completes your order.
I realize this isn't a perfect analogy (some banks use multiple tellers to complete transactions, and some coffee shops have multiple people taking orders), but hopefully you understand the difference between the two programming models.
Node uses the coffee shop model. A single thread of execution runs all of your JavaScript code, and you provide callbacks to wait for results.
Other software stacks use the bank model. To scale, more threads (or processes) are created. Apache web server is one example that uses the bank scalability model.
Both models, of course, can achieve horizontal scalability by adding more servers.
The dark side of asynchronous programming
Now, there is a "dark side" to the non-blocking model: the chatty coffee shop counter employee. What if the employee at the counter is more interested in chatting with each customer than in diligently taking orders and payments? The line backs up, the baristas idle, and the whole process grinds to a halt.
This can happen with Node programming, too, where one application isn't behaving properly, so it stalls or slows the process. In this tutorial, I show you how to profile your JavaScript code to look for those poor-performing "hot spots."
Synchronous versus asynchronous - Act 1
The Node.js defines blocking I/O:
"Blocking is when the execution of additional JavaScript in the Node.js process must wait until a non-JavaScript operation completes. This happens because the event loop is unable to continue running JavaScript while a blocking operation is occurring.
In Node.js, JavaScript that exhibits poor performance due to being CPU intensive rather than waiting on a non-JavaScript operation, such as I/O, isn't typically referred to as blocking."
In the first example (Act One), I take liberties with this definition just as a way of introducing the topic. Thank you in advance for this leeway while I move the discussion toward true blocking vs non-blocking examples. We will get there.
Get the code
All of the source code examples below are available in the GitHub repo for the learning path. To save space in the listings, I removed the comments and added line numbers where it helps me explain specific lines of code. I encourage you to clone the code from GitHub and run the examples with me as you move through each tutorial in the learning path.
Synchronous programming style
Example 1 is a run-of-the-mill synchronous style program. It runs from top to bottom on the V8 thread and just chews up some CPU (again, this is not technically blocking, but bear with me).
Example 1. Normal synchronous programming style
'use strict'
console.log(Date.now().toString() + ': mainline: BEGIN');
const startTime = Date.now();
let endTime = startTime;
while (endTime < startTime + 20) {
endTime = Date.now();
}
console.log(Date.now().toString() + ': mainline: END');
If you run example1.js (go ahead, try it!), its output looks like this:
$ node example1
1529596824055: mainline: BEGIN
1529596824077: mainline: END
After chewing up 20 milliseconds of CPU time (by constantly checking the system time), the loop terminates. Because there are no callbacks in the event loop, the program ends.
Asynchronous programming style
Example 2 is similar to Example 1, but it uses asynchronous programming.
Example 2. Asynchronous programming style
'use strict'
console.log(Date.now().toString() + ': mainline: BEGIN');
setTimeout(() => {
console.log(Date.now().toString() + ':event loop (callback): Asynchronous processing complete.');
}, 20);
console.log(Date.now().toString() + ':mainline: END');
When you run example2.js, its output looks like this:
$ node example2
1529597656500: mainline: BEGIN
1529597656502:mainline: END
1529597656525:event loop (callback): Asynchronous processing complete.
This output shows the telltale footprint of asynchronous code: Output is not in top-to-bottom order (as it appears in the source file, I mean). The program:
- Shows the
BEGINmessage. - Invokes
setTimeout(), telling it to time out in 20 milliseconds. - Shows the
ENDmessage. - After no less than 20 milliseconds, the event loop invokes the anonymous callback function provided to
setTimeout()and it runs, showing theAsynchronous processing completemessage.
Conclusion to Act 1
So what's the difference? If you look at the output from Example 1, you can see that the synchronous code ran in about 22 milliseconds, but the asynchronous code (Example 2) ran in about 25. Each message contains a timestamp in milliseconds.
Asynchronous is slower! Should you be worried? Not at all!
As you move through this tutorial, keep this in mind: The asynchronous programming style isn't about pure speed; it's about scalability (think coffee shop, not bank).
Node's module system
Before I move on to my next comparison of the two programming models, you need to learn about Node's module system. In previous tutorials, I mentioned modules without really defining them, so I do that now.
Node modules defined
In simple terms, a Node module is any JavaScript file that executes on the Node runtime. You saw two examples of this already: example1.js and example2.js.
There are two ways to make Node aware of a module:
Pass the name of that module to Node to execute the JavaScript code inside it:
$ node example1This is how you ran Examples 1 and 2.
Pull in JavaScript from some other module through the
require()function.const fs = require('fs');This method tells Node that you want to use the
fsmodule, through therequire()function, which I discuss shortly.
Why the Node module system exists
Modularization is a key concept in modern software development. With modularization, you can build more robust code and reuse code in multiple places, instead of having to write the same code again and again.
Node modularization gives you all these benefits, plus it provides the following:
- Automatic encapsulation: By default, all code in a module is wrapped in a function wrapper so it's hidden from other JavaScript code outside of the module.
- A way to expose a module's interface: You must expose functions, variables, and other constructs within a module through
module.exports(or its shortcut:exports) to JavaScript modules outside of the module.
Types of Node modules
There are different categories of Node modules, even though they all contain JavaScript code:
- Node API built-in modules. Examples include:
- The File System module:
fs - The Crypto module:
crypto - The HTTP module:
http
- The File System module:
- Community contrib modules. Examples include:
- Custom modules such as those used in this tutorial:
- File Processor:
file-processor - Simple Logger:
simple-logger
- File Processor:
As you move through this learning path, you will look at each type of module above in detail.
How to use Node modules
To use a module, you need a reference to it, which you obtain through the require() function.
Consider this example:
var fs = require('fs');
var fileContents = fs.readFileSync('../data/50Words.txt', 'utf8');
var numberOfWords = fileContents.split(/[ ,.\n]+/).length;
To access the File System API, you get a reference to the fs module by calling require() on it. At that point, you can use its interface, such as calling readFileSync().
How to create a Node module
First, create a JavaScript file. We'll call it
foo.js:'use strict' function hello() { console.log('Hello from ' + __filename + '!'); }Then, create a second JavaScript file, for example
bar.js. To reference thefoomodule from thebarmodule userequire():bar.js:'use strict' const foo = require('./foo'); foo.hello();
Go ahead and create these files and paste the JavaScript code above into the respective files, then run node bar (they are also in this learning path's GitHub repo). You see something like this:
$ node bar
/Users/sperry/home/development/projects/IBM-Code/Node.js/Course/Unit-4/bar.js:5
foo.hello();
^
TypeError: foo.hello is not a function
at Object.<anonymous> (/Users/sperry/home/development/projects/IBM-Code/Node.js/Course/Unit-4/bar.js:5:5)
at Module._compile (internal/modules/cjs/loader.js:702:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:713:10)
at Module.load (internal/modules/cjs/loader.js:612:32)
at tryModuleLoad (internal/modules/cjs/loader.js:551:12)
at Function.Module._load (internal/modules/cjs/loader.js:543:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:744:10)
at startup (internal/bootstrap/node.js:238:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:572:3)
How do we fix this TypeError? By using module.exports and require('./foo').
Use module.exports
Remember when I said that, by default, all of the code in a module is hidden from the outside? You are seeing this in action: The foo hello() function cannot be seen by the bar code.
To expose the hello() function to the outside world, you must export it. Add this line to the bottom of foo.js:
module.exports.hello = hello;
Now run bar again:
$ node bar
Hello from /Users/sperry/home/development/projects/IBM-Code/Node.js/Course/Unit-4/foo.js!
Require the relative path of the referenced module
You might have noticed that when we reference a Node built-in module such as fs, we require() it like this:
const fs = require('fs');
But in the previous example, you had to require() the foo module from bar like this:
bar.js:
.
.
const foo = require('./foo');
Why do we have to specify the relative path to the foo module?
require() has a very lengthy search algorithm it uses to resolve a module's location when it needs to load that module. For custom modules, if you want to reference a module you've written (foo) from another module you've written (bar), the referencing modules must use the referenced module's relative path as the argument to require().
One more thing: __filename
As I mentioned earlier, every Node module is wrapped in a function wrapper that looks like this:
(function(exports, require, module, __filename, __dirname) {
// Module code actually lives in here
});
foo.js, when modularized by Node, effectively looks like this:
(function(exports, require, module, __filename, __dirname) {
// Module code actually lives in here
'use strict'
function hello() {
console.log('Hello from ' + __filename + '!');
}
module.exports.hello = hello;
});
__filename, which is the fully qualified name of the module's JavaScript source file, is passed to the function wrapper by Node, along with several other parameters:
exports: Short formodule.exportsrequire: Our old friend that lets us include other modulesmodule: Reference to the current module__dirname: The full path to the directory of the module's JavaScript source file
I recommend that you check out the Modules API docs if you want to learn more about Node's module system.
Modules used in this tutorial
Going forward, the examples I show use modules to encapsulate common code, in particular:
File processing logic: All of the code that reads and processes files is located in the
file-processormodule.Message logging: All of the code that outputs messages to the console is located in the
simple-loggermodule.
Before we dive into another head-to-head performance comparison of the programming models (Act 2), let's look a little closer at these two modules, as they give you a pattern to follow when you want to write your own Node modules.
The file processing module: file-processor
The file-processor module contains most of the business logic for the examples in this tutorial. I named the functions in file-processor to match the naming style of the Node API: a function that behaves synchronously has the word Sync appended to the function name, an asynchronous function does not.
Listing 1 shows the function whose business logic is used to "process" a file synchronously. The function is called processFileSync():
Listing 1. The processFileSync() function of the process-file module, which behaves synchronously
01 function processFileSync(fileName) {
02 let startTime = process.hrtime();
03 logger.trace('processFileSync(): START', startTime);
04 let fileContents = fs.readFileSync(fileName, 'utf8');
05 let derivedKey = crypto.pbkdf2Sync(fileContents.toString(), SALT, NUMBER_OF_ITERATIONS, KEY_LENGTH, DIGEST);
06 let derivedKeyAsString = derivedKey.toString('hex');
07 logger.debug('processFileSync(): Computed hash: \'' + derivedKeyAsString + '\'', startTime);
08 logger.trace('processFileSync(): END', startTime);
09 return derivedKeyAsString;
10 };
Note: The constants SALT, NUMBER_OF_ITERATIONS, and so on, are at the top of file-processor.js. Their values are not really relevant for these examples, but I wanted to point out where the source can be found in case you're interested.
Like I said, functions in the Node API that are asynchronous have no name qualifier because asynchronous is Node's default.
The asynchronous counterpart to processFileSync() (shown in Listing 1) is called processFile(). Listing 2 shows this:
Listing 2. The processFile() function, which behaves asynchronously
01 function processFile(fileName, resultsCallback) {
02 const startTime = process.hrtime();
03 logger.trace('fs.readFile(): START', startTime);
04 fs.readFile(fileName, 'utf8', function(err, fileContents) {
05 if (err) throw err;
06 crypto.pbkdf2(fileContents, SALT, NUMBER_OF_ITERATIONS, KEY_LENGTH, DIGEST, (err, derivedKey) => {
07 var derivedKeyAsString;
08 if (err) {
09 logger.error('Something went horribly wrong: ' + err.message);
10 } else {
11 derivedKeyAsString = derivedKey.toString('hex');
12 logger.debug('crypto.pbkdf2(): derivedKey: \'' + derivedKeyAsString + '\'', startTime);
13 }
14 resultsCallback(err, derivedKeyAsString);
15 });
16 logger.trace('fs.readFile(): END', startTime);
17 });
18 };
The message logging module: simple-logger
The simple-logger module contains all of the code that handles message logging for the examples in this tutorial. Messages are only logged to the console, though that detail is hidden behind the implementation, which is another reason to modularize your JavaScript code wherever possible.
The simple-logger consists of four internal components:
- Log Level, implemented by the
Levelobject, which is associated with every message and allows any callers that are dependent on this module to throttle the message logging. - The current Log Level, set to
INFOby default, but can be changed by callers. - The
log()function, which is the internal implementation that selectively logs to the console. - Helper functions, such as
info(), which logs informational messages,debug()for more fine-grained debug messages,warn()for warnings, and so on.
To use simple-logger, modules call require(./simple-logger) to obtain a reference to the module. Optionally, call setLogLevel() (if the default of Level.INFO is not acceptable) to set the current log level. Finally, call various helper functions to perform the actual logging.
Listing 3 shows how the Log Levels are defined:
Listing 3. The various Levels supported by simple-logger
const Level = {
TRACE : { priority : 0, outputString : 'TRACE' },
DEBUG : { priority : 100, outputString : 'DEBUG' },
INFO : { priority : 200, outputString : 'INFO' },
WARN : { priority : 300, outputString : 'WARN' },
ERROR : { priority : 400, outputString : 'ERROR' },
FATAL : { priority : 500, outputString : 'FATAL' },
OFF : { priority : 1000, outputString : 'OFF'}
};
Every message that is a candidate for logging has an associated Level. If a message's Level.priority is at or above the current Log Level's priority it is logged. Otherwise, it is ignored.
Any module that wishes to require() the simple-logger can set the current Log Level through the setLogLevel() function, as Listing 4 shows:
Listing 4. The setLogLevel() function
.
.
// The current Log level
var logLevel = Level.INFO;
.
.
function setLogLevel(newLevel) {
logLevel = newLevel;
}
The setLogLevel() function is used to set the current log threshold, which is stored in a module-scoped variable called logLevel.
Listing 5 shows the private log() function. It is not exported, so it is visible only within the simple-logger module:
Listing 5. The log() function
function log(messageLogLevel, message, startTime) {
if (messageLogLevel.priority >= logLevel.priority) {
let now = Date.now();
let outputString = now.toString() + ':' + messageLogLevel.outputString;
let computedMessage;
if (startTime) {
let stopTime = process.hrtime(startTime);
computedMessage = outputString + ':' + message + ': (elapsed time: ' + `${1000 * (stopTime[0] + stopTime[1] / 1e9)}` + 'ms)';
} else {
computedMessage = outputString + ':' + message;
}
console.log(computedMessage);
}
}
For each Level there is one helper function, each of which delegates to the log() method, passing its corresponding Level. Listing 6 shows the helper functions.
Listing 6. Helper methods from simple-logger.js
function trace(message, startTime) {
log(Level.TRACE, message, startTime);
}
function debug(message, startTime) {
log(Level.DEBUG, message, startTime);
}
function info(message, startTime) {
log(Level.INFO, message, startTime);
}
function warn(message, startTime) {
log(Level.WARN, message, startTime);
}
function error(message, startTime) {
log(Level.ERROR, message, startTime);
}
function fatal(message, startTime) {
log(Level.FATAL, message, startTime);
}
That covers the custom modules you use in this tutorial (though, simple-logger appears regularly throughout the learning path).
Now, it's time for another head-to-head comparison between synchronous and asynchronous coding styles, which I call Act Two.
Synchronous vs asynchronous - Act 2
The examples we looked at earlier are too simple to be real-world examples. Real-world code uses modules and does interesting things like read files and encrypt things.
Synchronous
In Listing 1, we saw two synchronous Node API calls made by processFileSync() on lines 4 and 5:
01 function processFileSync(fileName) {
. . .
04 let fileContents = fs.readFileSync(fileName, 'utf8');
05 let derivedKey = crypto.pbkdf2Sync(fileContents.toString(), SALT, NUMBER_OF_ITERATIONS, KEY_LENGTH, DIGEST);
. . .
10 };
When the code on line 4 executes, V8 is blocked waiting for the I/O to finish before executing line 5.
Let's run it now, using an example wrapper I've provided called example3.js.
You should see output like this:
$ node example3
1529618304278:INFO:mainLine(): Start processFile() calls... ***
1529618304280:DEBUG:mainline(): Processing file: ../data/1mWords.txt...
1529618304442:DEBUG:processFileSync(): Computed hash: '77da510b16c1503d47b6afadda86a039499547485ee4c10c5a3b3a3ce4f2c64e': (elapsed time: 161.794277ms)
1529618304442:DEBUG:mainline(): Derived key as string: '77da510b16c1503d47b6afadda86a039499547485ee4c10c5a3b3a3ce4f2c64e'
1529618304442:INFO:mainline(): End ***: (elapsed time: 164.579688ms)
Note: You might notice that I've beefed up the logging output a bit, including computing an elapsed time so we can compare elapsed times between synchronous and asynchronous. That's the simple-logger module at work.
Let's compare the performance of example3 with its asynchronous counterpart.
Asynchronous
Listing 2 has several lines of code that illustrate the asynchronous coding style, which I show here:
01 function processFile(fileName, resultsCallback) {
. . .
04 fs.readFile(fileName, 'utf8', function(err, fileContents) {
05 if (err) throw err;
06 crypto.pbkdf2(fileContents, SALT, NUMBER_OF_ITERATIONS, KEY_LENGTH, DIGEST, (err, derivedKey) => {
07 var derivedKeyAsString;
. . .
14 resultsCallback(err, derivedKeyAsString);
15 });
16 logger.trace('fs.readFile(): END', startTime);
17 });
18 };
When V8 executes this function on the mainline of example4.js, line 4 executes and passes an anonymous callback function (to be invoked when the I/O finishes), and then the method returns.
When the I/O is complete (at some later time), execution begins on line 5, and on line 6 another asynchronous Node API call is made to the crypto API (again, passing an anonymous callback function), which uses the file's contents as the "password" to create a derived key. Then line 16 executes, and the function returns.
When the crypto function completes (at some still later time), execution begins on line 7, where eventually on line 14 the resultsCallback is invoked, passing the results (along with an err object) to the caller.
Whoa! So in actuality, there is not one trip through the code in processFile() but 3 trips (executing different lines of code each trip through, of course)! Welcome to Node and asynchronous programming!
So now, let's run it. I've provided another wrapper called example4.js that runs the processFile() function (see Listing 2).
You should see output like this:
$ node example4
1529618298372:INFO:mainline(): Start... ***: (elapsed time: 0.146585ms)
1529618298374:DEBUG:mainline(): Processing file: ../data/1mWords.txt...
1529618298375:INFO:mainline(): End. ***: (elapsed time: 2.887165ms)
1529618298551:DEBUG:crypto.pbkdf2(): Derived key: '77da510b16c1503d47b6afadda86a039499547485ee4c10c5a3b3a3ce4f2c64e': (elapsed time: 176.644805ms)
1529618298552:INFO:(callback)(): Derived key as string: '77da510b16c1503d47b6afadda86a039499547485ee4c10c5a3b3a3ce4f2c64e': (elapsed time: 179.45526ms)
Conclusion - Act 2
On my Macbook Pro, example3.js (synchronous) ran in about 165ms, compared to example4.js (asynchronous), which ran in about 180ms. Seems like the synchronous code is faster again.
If you're getting worried that asynchronous code just doesn't perform, I totally get it. But I encourage you to reserve judgment until Act 3.
Using the built-in V8 profiler
As a professional Node developer, you should know how to run a performance analysis (called a profile) on your code. This profile tells you where in the code V8 is spending the most time executing. These locations are sometimes called "hot spots".
An entire tutorial series could be dedicated to V8 profiling, so I'm only going to cover the basics here:
- How to run the profiler
- How to read profiler output
The V8 Engine has a built-in profiler that Node.js hooks into. To run the profiler, pass the --prof argument to the node program when you run it. The profiler also takes several other arguments, which I suggest you use to tailor the output:
--no-logfile-per-isolate: Each time you runnode, the instance of V8, called an isolate because the state of each V8 instance is isolated from all others, is assigned an ID. By default, this ID is part of the log file name. This argument tells the profiler to produce a single log file (calledv8.log) each time it runs, overwriting the previous log file.--log: Creates minimal logging (for example, no garbage collection samples)--logfile=exampleX.log: Creates a log file calledexampleX.login the current directory. Combined with the--no-logfile-per-isolateflag, it overrides the default filename (that is,v8.log) and uses the value of the--logfileargument.
Now, run the profiler for example3.js by executing this command:
node --prof --no-logfile-per-isolate --log --logfile=example3.log example3
This produces a file called example3.log in the current directory. Take a look at it just for fun. It contains lines like this:
v8-version,6,7,288,45,-node.7,0
shared-library,/Users/sperry/.nvm/versions/node/v10.4.1/bin/node,0x100001000,0x100c59dba,0
shared-library,/System/Library/Frameworks/CoreFoundation.framework/Versions/A/CoreFoundation,0x7fff54ef8860,0x7fff550eb9ac,759017472
shared-library,/usr/lib/libSystem.B.dylib,0x7fff7aaa194a,0x7fff7aaa1b2e,759017472
shared-library,/usr/lib/libc++.1.dylib,0x7fff7acd5f40,0x7fff7ad1d2b0,759017472
shared-library,/usr/lib/libDiagnosticMessagesClient.dylib,0x7fff7a72af08,0x7fff7a72b90c,759017472
shared-library,/usr/lib/libicucore.A.dylib,0x7fff7b800fd4,0x7fff7b9b82e6,759017472
shared-library,/usr/lib/libobjc.A.dylib,0x7fff7c159000,0x7fff7c17a65a,759017472
.
.
code-creation,Builtin,3,6831,0xfc7d5d21840,2456,HasProperty
code-creation,Builtin,3,6842,0xfc7d5d22220,1036,DeleteProperty
code-creation,Builtin,3,6852,0xfc7d5d22680,25,Abort
code-creation,Builtin,3,6862,0xfc7d5d226e0,40,AbortJS
code-creation,Builtin,3,6872,0xfc7d5d22760,15,EmptyFunction
code-creation,Builtin,3,6882,0xfc7d5d227c0,15,Illegal
code-creation,Builtin,3,6896,0xfc7d5d22820,15,StrictPoisonPillThrower
code-creation,Builtin,3,6907,0xfc7d5d22880,15,UnsupportedThrower
code-creation,Builtin,3,6918,0xfc7d5d228e0,21,ArrayConstructor
code-creation,Builtin,3,6928,0xfc7d5d22940,9,InternalArrayConstructor
code-creation,Builtin,3,6939,0xfc7d5d229a0,15,ArrayConcat
.
.
code-creation,LazyCompile,10,272952,0x1cdb2ff4e60a,57,finishMaybe _stream_writable.js:635:21,0x1cdb269306c0,~
code-creation,LazyCompile,10,272998,0x1cdb2ff4e82a,55,emitAfterScript internal/async_hooks.js:354:25,0x1cdb00e391c8,~
code-creation,LazyCompile,10,273064,0x1cdb2ff4eaa2,198,popAsyncIds internal/async_hooks.js:402:21,0x1cdb00e393d0,~
code-creation,LazyCompile,10,273210,0x1cdb2ff4efaa,287,emitPromiseRejectionWarnings internal/process/promises.js:88:38,0x1cdb2694aec8,~
tick,0x7fff7ced6a1e,273422,0,0x0,6
delete,MemoryChunk,0x1cdb6be80000
delete,MemoryChunk,0x1cdbc2a00000
delete,MemoryChunk,0x1cdb2b600000
delete,MemoryChunk,0x1cdb0a780000
delete,MemoryChunk,0x1cdba3200000
delete,MemoryChunk,0x1cdb51c00000
delete,MemoryChunk,0x1cdb40f00000
delete,MemoryChunk,0x1cdbfff80000
delete,MemoryChunk,0x1cdbb7880000
delete,MemoryChunk,0x1cdb00e00000
delete,MemoryChunk,0x1cdb9dc00000
delete,MemoryChunk,0x1cdb32b00000
delete,MemoryChunk,0x1cdb26900000
delete,MemoryChunk,0x1cdb86b00000
delete,MemoryChunk,0x1cdb2ff00000
delete,MemoryChunk,0xfc7d5d00000
delete,MemoryChunk,0xfc7d5d80000
delete,MemoryChunk,0x1cdb9fe00000
delete,MemoryChunk,0x1cdbc8300000
delete,LargeObjectChunk,0x1cdb16400000
delete,MemoryChunk,0x1cdb16400000
profiler,end
Yikes! That's not very helpful. Fortunately, passing the --prof-process argument to Node creates analyzed output:
node --prof-process example3.log > example3.log.txt
The previous command invokes the profile analyzer, passes the example3.log profiler info, and then formats it for us. The output looks like this:
Statistical profiling result from v8.log, (215 ticks, 1 unaccounted, 0 excluded).
[Shared libraries]:
ticks total nonlib name
4 1.9% /usr/lib/system/libsystem_pthread.dylib
2 0.9% /usr/lib/system/libsystem_malloc.dylib
[JavaScript]:
ticks total nonlib name
1 0.5% 0.5% Script: ~<anonymous> console.js:1:11
[C++]:
ticks total nonlib name
118 54.9% 56.5% T node::crypto::PBKDF2(v8::FunctionCallbackInfo<v8::Value> const&)
24 11.2% 11.5% T node::contextify::ContextifyScript::New(v8::FunctionCallbackInfo<v8::Value> const&)
16 7.4% 7.7% T ___guarded_open_dprotected_np
5 2.3% 2.4% t node::Buffer::(anonymous namespace)::CreateFromString(v8::FunctionCallbackInfo<v8::Value> const&)
.
.
Tip: To run the profiler and process the output in a single command, do this:
`node --prof --no-logfile-per-isolate --log --logfile=example3.log example3 && node --prof-process example3.log | less && rm example3.log`
This lets you view the analyzed profile and then remove the original example3.log profiler output file, leaving your source directory less cluttered.
A tick is a single sampling interval, which by default is 1000 microseconds (1 millisecond). Notice that V8 took 215 samples, which would indicate that V8 ran JavaScript code for at least 215ticks (ms).
There are sections showing us the amount of time (expressed in ticks) spent in shared libraries, JavaScript code, and C++ code. The number of ticks in each table tells us how many sampling intervals were spent in the code listed under name. The results are sorted in order of where the profile spent the most time to where they spent the least amount of time.
Right away, you can see that 118 ticks (or 54.9% of total) were spent in a Node core library called crypto::PBKDF2, which is the library that handles password-based key derivation (remember that from Listing 1, line 5?).
Next, just over 1/10th of the total time was spent turning our JavaScript into runnable code (called "contexifying" in V8 terms).
If you scroll down in the v8.log.txt file, you see another section with a summary, followed by a "Bottom-up" profile:
[Summary]:
ticks total nonlib name
1 0.5% 0.5% JavaScript
207 96.3% 99.0% C++
3 1.4% 1.4% GC
6 2.8% Shared libraries
1 0.5% Unaccounted
[C++ entry points]:
ticks cpp total name
164 86.8% 76.3% T v8::internal::Builtin_HandleApiCall(int, v8::internal::Object**, v8::internal::Isolate*)
13 6.9% 6.0% T v8::internal::Runtime_CompileLazy(int, v8::internal::Object**, v8::internal::Isolate*)
.
.
1 0.5% 0.5% T v8::internal::Runtime_KeyedLoadIC_Miss(int, v8::internal::Object**, v8::internal::Isolate*)
[Bottom up (heavy) profile]:
Note: percentage shows a share of a particular caller in the total
amount of its parent calls.
Callers occupying less than 1.0% are not shown.
ticks parent name
118 54.9% T node::crypto::PBKDF2(v8::FunctionCallbackInfo<v8::Value> const&)
118 100.0% T v8::internal::Builtin_HandleApiCall(int, v8::internal::Object**, v8::internal::Isolate*)
118 100.0% LazyCompile: ~_pbkdf2 internal/crypto/pbkdf2.js:37:17
118 100.0% LazyCompile: ~pbkdf2Sync internal/crypto/pbkdf2.js:33:20
118 100.0% LazyCompile: ~processFileSync /Users/sperry/home/development/projects/IBM-Code/Node.js/Course/Unit-4/file-processor.js:89:25
118 100.0% Script: ~mainline /Users/sperry/home/development/projects/IBM-Code/Node.js/Course/Unit-4/example3.js:31:19
24 11.2% T node::contextify::ContextifyScript::New(v8::FunctionCallbackInfo<v8::Value> const&)
24 100.0% T v8::internal::Builtin_HandleApiCall(int, v8::internal::Object**, v8::internal::Isolate*)
22 91.7% LazyCompile: ~NativeModule.compile internal/bootstrap/loaders.js:220:44
.
.
The information is pretty intuitive, though you might have to stare at it for awhile before it makes sense. One thing I want to mention, the Bottom-up profile is formatted to be indented like a call stack, so you can see the order the functions were called (each nested call results in further indention under the name column).
Put it into practice
Exercise: Run the profiler on the example4.js code. Hint: make sure to redirect the output of node --prof-process to a different logfile than you did for example3. I suggest example4.log.txt.
Once you've completed the exercise, let's compare the results of exercise3 and exercise4 and see if anything jumps out at us to explain why synchronous is still faster than asynchronous.
Now that you've run the profiler and analyzer on both files, load them into an editor (I'm going to use VSCode because it has a nice built-in split screen editor). Here's what I see when I look at both files:
Figure 1. Comparison: synchronous vs asynchronous
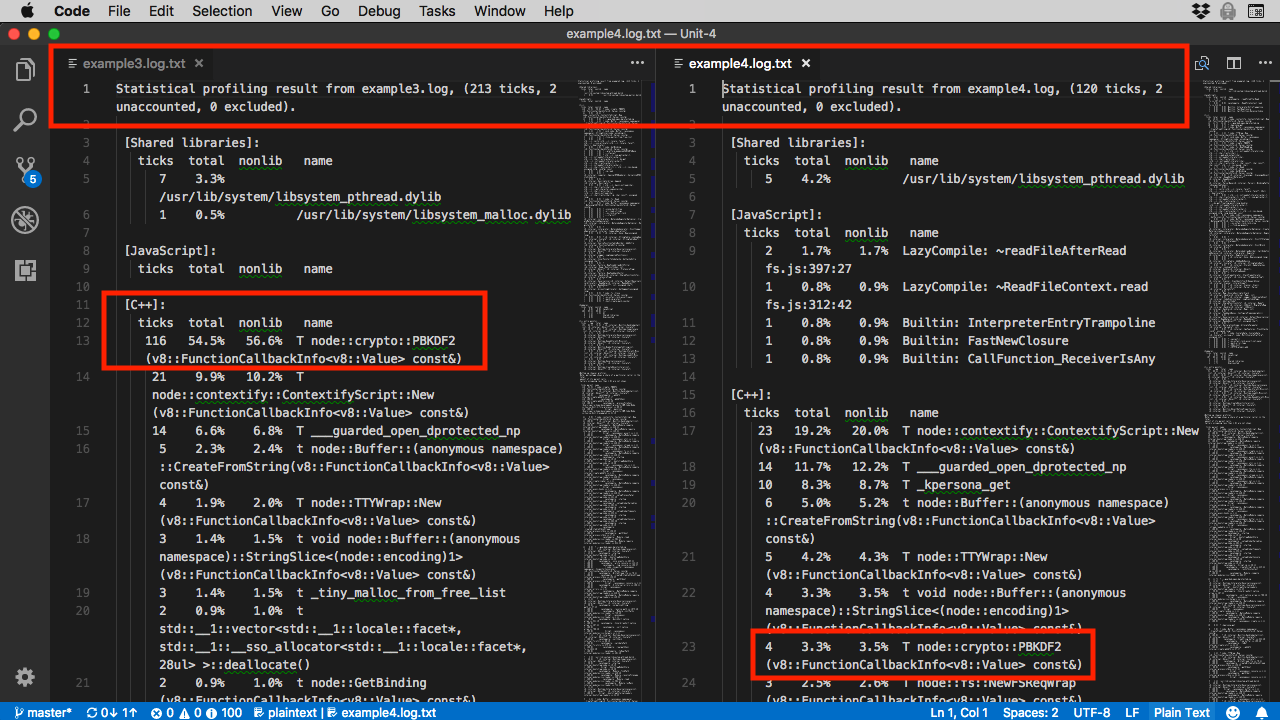
I highlighted two things that might be confusing:
- Recall the runtimes: synchronous code (
example3.js) : 165ms, versus asynchronous (example4.js) : 180ms. Yet the number of ticks is almost 100 less for the asynchronous code. - Time spent doing encryption: synchronous is roughly 55% of total, but asynchronous is about 4%.
At first glance, these results might be mystifying.
How can the asynchronous code result in over 90 fewer samples of the V8 profiler yet run about 15ms slower, because the corresponding example4 code ran about 15ms slower. You might think the slower a program's response time, the more opportunity the V8 profiler would have to take samples, right?
How can you perform the same encryption, yet the asynchronous code uses so much less of the V8 thread? (Check the results, and you'll see the derived keys computed by both examples are identical.)
The answer is simple and lies at the heart of why Node.js is so powerful. Most of the asynchronous code is not running on the V8 thread. It's running in the event loop (well, technically, it's running in the worker pool, which is part of libuv)!
There's no magic involved. The code has to run somewhere! It's just not running on the V8 thread. So why is async slower? The difference in runtime is probably just related to libuv overhead.
So, if that's the case, and the asynchronous code's encryption processing is not occurring in V8 but in the thread pool, then a load testing tool would demonstrate that, and the asynchronous code would run circles (from a response time standpoint) around the synchronous code.
To see that demonstration, we need to make the code suitable for running in an environment where we can load test it (say, wrap it in a simple HTTP server). Act 3 shows this load testing scenario.
Synchronous vs asynchronous - Act 3
Earlier in this tutorial, I noted that asynchronous programming isn't about pure speed, it's about scalability. We are about to put that to the test.
In the final act of our synchronous versus asynchronous showdown, we are going to put the file-processor under a load. Why? To see how the examples perform when stress-tested against many requests coming in at once. After all, that's what Node.js is: a server-side, high network-throughput JavaScript runtime.
In a single request, head-to-head comparison, synchronous wins with pure speed. However, when we run the asynchronous code against lots of simultaneous requests, its scalability should shine through.
To deploy the code for Examples 3 and 4 in a way where we can load test it, we have to wrap it in an HTTP server and strain it using a load test tool.
Node's http module
Before you can dive into the load testing, you need to understand Node's http module.
I've written an HTTP server that uses the Node built-in http module, and provides 2 valid request URLs that we'll put under load:
/processFileSync- runsfile-processor.processFileSync()inside the HTTP server./processFile- runsfile-processor.processFile()inside the HTTP server.
The code is in the GitHub repo directory in a file called example5.js. I show the code in its entirety below (the fact that I can do that is a testament to the Node API's elegant simplicity):
01 'use strict'
02 const PORT = 8080;
03 const DATA_DIR = '../data';
04 const FILE_NAME = "1mWords.txt";
05 const http = require('http');
06 const logger = require('./simple-logger');
07 const fileProcessor = require('./file-processor');
08 const server = http.createServer((request, response) => {
09 const { method, url } = request;
10 if (method === 'POST') {
11 request.on('error', (err) => {
12 logger.error('ERROR processing request: ' + err.message);
13 });
14 if (url === '/processFile') {
15 fileProcessor.processFile(DATA_DIR + '/' + FILE_NAME, (err, derivedKeyAsString) => {
16 if (err) {
17 logger.error('Something has gone horribly wrong: ' + err.message);
18 } else {
19 writeServerResponse(response, 'File contents:\n' + derivedKeyAsString, 200);
20 }
21 });
22 } else if (url == '/processFileSync') {
23 let derivedKeyAsString = fileProcessor.processFileSync(DATA_DIR + '/' + FILE_NAME);
24 writeServerResponse(response, 'File contents:\n' + derivedKeyAsString, 200);
25 } else {
26 writeServerResponse(response, 'The requested URL \'' + url + '\' is not recognized.\nOnly one of these URLS:\n\t/processFile\n\t/processFileSync.\nPlease try your request again.\n', 404);
27 }
28 } else {
29 writeServerResponse(response, 'Only POST method is allowed and either one of these URLS:\n\t/processFile\n\t/processFileSync.\nPlease try your request again.\n', 400);
30 }
31 response.on('error', (err) => {
32 logger.error('ERROR on response: ' + err.message);
33 });
34 }).listen(PORT);
35
36 var writeServerResponse = function(response, responseMessage, statusCode) {
37 logger.debug(responseMessage);
38 response.statusCode = statusCode;
39 response.write(responseMessage);
40 response.end();
41 }
I'll skip a detailed explanation of example5.js but want to point out 3 things:
Line 22: The
processFileSync()function offile-processormodule is invoked when youPOSTto thehttp://localhost:8080/processFileSync.Line 14: The
processFile()function of thefile-processormodule is invoked when youPOSTto thehttp://localhost:8080/processFile.Lines 28-30: Only the
POSTmethod and the two URLs I showed you earlier are supported. Any other messages are rejected with an HTTP 400 error message.
I want to introduce you to two load testing tools that you should be familiar with:
- Apache Bench
- loadtest
Apache Bench
Apache Bench is an HTTP load testing tool. The ab documentation page gives an apt description:
"ab is a tool for benchmarking your Apache Hypertext Transfer Protocol (HTTP) server. It is designed to give you an impression of how your current Apache installation performs. This especially shows you how many requests per second your Apache installation is capable of serving."
The cool thing is, while ab was designed to load test Apache web server, it works with any HTTP server. This is good for us.
MacOS
Apache web server (which includes Apache Bench) should already be installed on your Mac.
Other platforms
If you are running on Windows, Linux, or another platform and need to install Apache web server, check out Apache HTTP Server Version 2.4 Installation Instructions.
Verify installation
Use ab -V to verify that ab is installed.
You'll see output like this:
$ ab -V
This is ApacheBench, Version 2.3 <$Revision: 1826891 __CODE_BLOCK_33__gt;
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, https://www.apache.org/
$
loadtest
loadtest is a popular load test tool that installs as a package through npm.
It uses the same basic runtime options as ab and this is by design (see loadtest basic usage), so if you're familiar with using ab you should feel right at home with loadtest.
Install loadtest globally (so it's on your PATH) with this command: npm install -g loadtest
To verify that loadtest is installed use loadtest -V.
You'll see output like this:
$ loadtest -V
Loadtest version: 3.0.3
$
Let's load test
To begin the load test, run
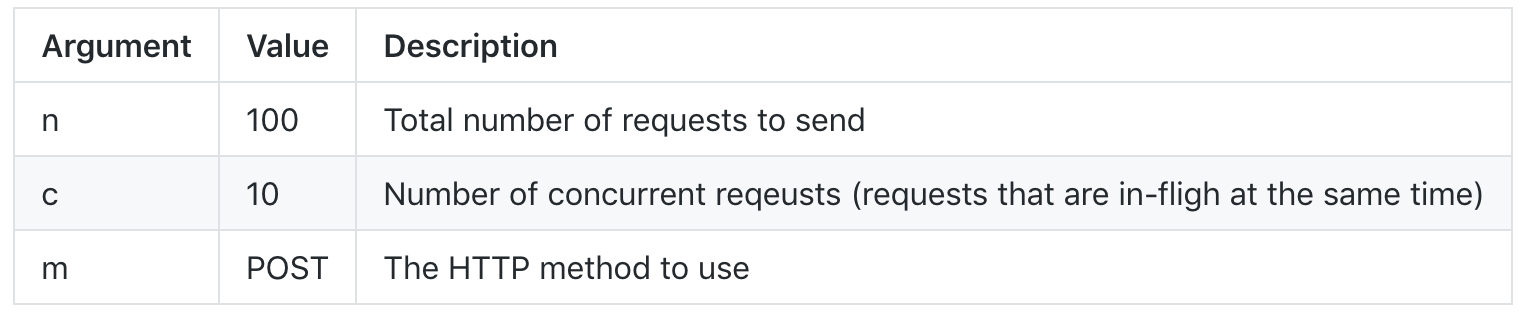
example5.js:node example5Now, use the load test tool of your choice (the arguments I recommend you provide are identical no matter which tool you use):
The final argument is the URL:
* `http://localhost:8080/processFileSync`: Execute synchronous code * `http://localhost:8080/processFile`: Execute asynchronous codeKick off the first test - Synchronous:
ab -n 100 -c 10 -m POST http://localhost:8080/processFileSyncYou should see output like this:
$ ab -n 100 -c 10 -m POST http://localhost:8080/processFileSync This is ApacheBench, Version 2.3 <$Revision: 1826891 __CODE_BLOCK_37__gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, https://www.apache.org/ Benchmarking localhost (be patient).....done Server Software: Server Hostname: localhost Server Port: 8080 Document Path: /processFileSync Document Length: 79 bytes Concurrency Level: 10 Time taken for tests: 15.600 seconds Complete requests: 100 Failed requests: 0 Total transferred: 15400 bytes HTML transferred: 7900 bytes Requests per second: 6.41 [#/sec] (mean) Time per request: 1560.037 [ms] (mean) Time per request: 156.004 [ms] (mean, across all concurrent requests) Transfer rate: 0.96 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.1 0 1 Processing: 157 1491 298.9 1562 1726 Waiting: 152 1234 303.4 1252 1573 Total: 157 1491 298.8 1563 1726 Percentage of the requests served within a certain time (ms) 50% 1563 66% 1573 75% 1704 80% 1708 90% 1721 95% 1725 98% 1726 99% 1726 100% 1726 (longest request) $Apache Bench sent 100 total requests, making sure that there were 10 concurrent requests at all times until the test was complete. The total time was 15.6 seconds for all 100 tests.
Now let's run it using the asynchronous code.
ab -n 100 -c 10 -m POST http://localhost:8080/processFileAnd the output (moment of truth!):
$ ab -n 100 -c 10 -m POST http://localhost:8080/processFile This is ApacheBench, Version 2.3 <$Revision: 1826891 __CODE_BLOCK_39__gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, https://www.apache.org/ Benchmarking localhost (be patient).....done Server Software: Server Hostname: localhost Server Port: 8080 Document Path: /processFile Document Length: 79 bytes Concurrency Level: 10 Time taken for tests: 5.123 seconds Complete requests: 100 Failed requests: 0 Total transferred: 15400 bytes HTML transferred: 7900 bytes Requests per second: 19.52 [#/sec] (mean) Time per request: 512.334 [ms] (mean) Time per request: 51.233 [ms] (mean, across all concurrent requests) Transfer rate: 2.94 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.0 0 0 Processing: 173 474 67.4 471 635 Waiting: 173 472 67.0 471 634 Total: 174 474 67.3 472 635 Percentage of the requests served within a certain time (ms) 50% 472 66% 514 75% 524 80% 529 90% 536 95% 544 98% 634 99% 635 100% 635 (longest request) $
Wow! It appears that there's something to this whole asynchronous code thing after all. Turns out, when you're running a single Node program like node example3 versus node example4 that synchronous wins on pure speed. But under load, scalability is king, and nothing beats asynchronous code.
I encourage you to play around with Example 5, including the settings to the load test tool, and convince yourself that when it comes to putting a load on code that can run asynchronously, it really is more scalable than its synchronous counterpart.
One more load test
Remember Examples 1 and 2? What would happen if we pit them against each other? I've provided an example HTTP server for this scenario as well. Check out example6.js and run it the same way you did example5.js in the previous section.
First, start the HTTP server (make sure to shut down
example5.jsfirst if it's still running, because the HTTP server for both of these examples uses port 8080):node example6Now, start
aborloadtestto run a load test using these settings: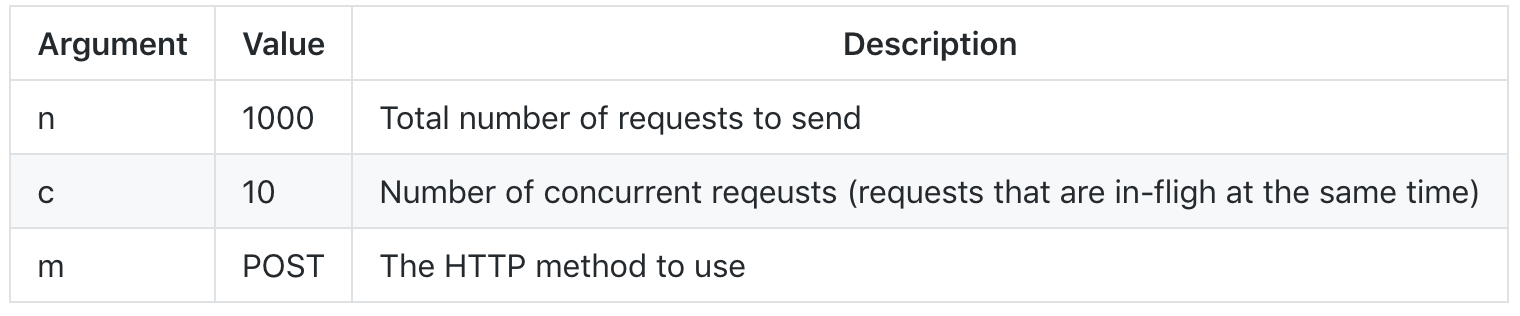
The final argument is the URL:
http://localhost:8080/sync: Eexecute synchronous codehttp://localhost:8080/async: Execute asynchronous code
Kick off the first test - pure synchronous:
ab -n 1000 -c 10 -m POST http://localhost:8080/syncYou should see output like this (I've skipped a bunch of the prologue output to save space):
$ ab -n 1000 -c 10 -m POST http://localhost:8080/sync . . . Percentage of the requests served within a certain time (ms) 50% 20 66% 20 75% 20 80% 21 90% 22 95% 22 98% 24 99% 24 100% 27 (longest request) $Okay, cool, the requests took between 20 and 27 ms.
Now kick off the pure asynchronous test:
ab -n 1000 -c 10 -m POST http://localhost:8080/async$ ab -n 1000 -c 10 -m POST http://localhost:8080/async . . . Percentage of the requests served within a certain time (ms) 50% 26 66% 27 75% 27 80% 27 90% 28 95% 28 98% 29 99% 30 100% 30 (longest request) $
You might be wondering why in the world the asynchronous test was slower?! How can that be? I forgot to tell you, I cheated. I made the asynchronous wait 10 times longer than the synchronous code before waking up. Check out example6.js near the top, where I've defined constants to set the sleep time (async) and cpu burn time (sync) values. Notice they're the same:
.
.
const MS_TO_SLEEP = 20; // For async
const MS_TO_BURN = 2; // For sync
.
example6.js - constants to define sleep (async) and cpu burn (sync) times.
nodemon
Another core Node tool you need to know about is nodemon.
nodemon detects changes to your project's source files and restarts Node.js if it detects any, speeding up the code-test-repeat development cycle.
From your terminal window or command prompt, kill the Node process running
example6, then installnodemonthe same way you didloadtest. That is, install it globally:npm install -g nodemonOnce it's finished, verify the installation:
$ nodemon -v 1.17.5Now, you use it the same way you use Node:
nodemon example6You'll see output like this:
$ nodemon example6 [nodemon] 1.17.5 [nodemon] to restart at any time, enter `rs` [nodemon] watching: *.* [nodemon] starting `node example6.js`Change the
MS_TO_SLEEPandMS_TO_BURNconstants inexample6.jsto be the same (I suggest20), and saveexample6.js.nodemonwill detect the change and automatically restart Node:$ nodemon example6 [nodemon] 1.17.5 [nodemon] to restart at any time, enter `rs` [nodemon] watching: *.* [nodemon] starting `node example6.js` [nodemon] restarting due to changes... [nodemon] starting `node example6.js`(Notice the two lines at the bottom appear once you save
example6.js).Now, run your tests again. I've summarized my results in the following table:
| Document | Requests per second | Time per request |
|---|---|---|
| /sync | 49.91 | 200.354 |
| /async | 388.57 | 25.735 |
Not even close.
Now that you have nodemon running, play around with the wait times for yourself until you're convinced: asynchronous code is the way to go. Or, to put it another way: run as little code on the V8 thread as possible. Each time you make a code change, nodemon will restart Node automatically.
The pyramid of doom
We've seen how asynchronous code beats synchronous code under load. That's great and all, but asynchronous code has a "dark side": code complexity.
When more than two processes occur serially (that is, they must be done one after the other), this can result in the Pyramid of Doom.
I present for your inspection Listing 7 (from file-processor.js):
Listing 7. A version of the processFile() method that acts like a real-world application, which results in a messy pyramid of code
01 function processFilePyramid(fileName, resultsCallback) {
02 fs.readFile(fileName, 'utf8', function(err, fileContents) {
03 if (err) throw err;
04 crypto.pbkdf2(fileContents, SALT, NUMBER_OF_ITERATIONS, KEY_LENGTH, DIGEST, (err, derivedKey) => {
05 if (err) throw err;
06 let derivedKeyAsString = derivedKey.toString('hex');
07 let outputFileName = fileName + '.sha512';
08 fs.writeFile(outputFileName, derivedKeyAsString, 'utf8', (err) => {
09 if (err) {
10 logger.error('fe.writeFile(): Something went horribly wrong: ' + err.message);
11 }
12 resultsCallback(err, outputFileName);
13 });
14 });
15 }); // Bottom of the pyramid (sigh)
16 }
The pyramid:
- Line 2: Read a file asynchronously, and when the I/O is done:
- Line 4: Encrypt the file's contents, and when that is done:
- Line 8: Write the derived key to a file, and when that is done:
- Line 12: Invoke a callback with the results
- Line 13: End Write block
- Line 8: Write the derived key to a file, and when that is done:
- Line 14: End Encrypt block
- Line 4: Encrypt the file's contents, and when that is done:
- Line 15: End Read block
Now, each of these steps is dependent on the one before it, so they cannot be done in parallel. The result is this sort of highly indented, triangular shape.
How do you avoid this? After all, the business logic determines the order of the steps. Answer: JavaScript promises.
Now let's look at a rewritten version of processFilePyramid() that uses promises:
Listing 8. Using JavaScript Promise to rewrite processFilePyramid()
function processFilePromise(fileName) {
const startTime = process.hrtime();
return new Promise((resolve, reject) => {
fs.readFile(fileName, 'utf8', function(err, fileContents) {
if (err) {
reject(err);
} else {
resolve(fileContents);
}
});
}).then(fileContents => {
return new Promise((resolve, reject) => {
crypto.pbkdf2(fileContents, SALT, NUMBER_OF_ITERATIONS, KEY_LENGTH, DIGEST, (err, derivedKey) => {
if (err) {
reject(err);
} else {
resolve(derivedKey.toString('hex'));
}
});
});
}).then(derivedKeyAsString => {
return new Promise((resolve, reject) => {
let outputFileName = fileName + '.sha512';
fs.writeFile(outputFileName, derivedKeyAsString, 'utf8', (err) => {
if (err) {
reject(err);
} else {
resolve(outputFileName);
}
});
});
});
}
There are more lines of code, but the code is arguably cleaner.
The concepts and motivations behind promises are beyond the scope of this tutorial. I just wanted to introduce you to them and make you aware that using them can make the serial nature of the processing steps in your code more visually obvious.
I have provided example wrappers so that you can run the code in Listings 7 and 8 if you want to.
- Listing 7: Run
example7.js - Listing 8: Run
example8.js
One last thing before I wrap up this section: You might look at the code in file-processor.processFilePromise() and think that there are a whole lot of promises being created here. Why would we need more than one (top-level) promise?
After all, the use of then() should force the code to execute serially, right?
Well, yes, then() does execute serially, but unfortunately, because the underlying code is a chain of asynchronous logic that must execute serially (see the "The Pyramid" illustration at the beginning of this section), the results of the previous asynchronous call aren't ready when then() is executed, resulting in undefined variables.
Because of that, we absolutely do not want the promise bound to its resolution callback before the results are ready, so within each block of asynchronous code we must create a new Promise to force the binding to occur to the next then() in the chain only after we have called resolve() with the results value.
To illustrate this, I put together a processFileBrokenPromise() function in file-processor and have wrapped it with example9.js so you can run it. Go ahead, play around with it until you have a good mental model of how asynchronous code really works with promises.
Learn more about promises
I could do a whole tutorial on Promises alone, but unfortunately there isn't space here to do that. However, I've included some links to resources below that you can use to learn more about Promises, including why and how to use them.
Conclusion
In this tutorial, you learned about:
- The difference between synchronous and asynchronous models for handling requests with an intuitive example - the bank versus the coffee shop.
- Synchronous versus Asynchronous JavaScript coding styles
- Node's Module system, what it is, and how to use it
You also saw a head-to-head comparison of code using the synchronous and asynchronous Node APIs:
- From a pure speed standpoint, synchronous code wins every time
- When under load, asynchronous code scales much better than synchronous code
Along the way, you became familiar with some new tools:
- Apache Bench
- loadtest
- nodemon
And finally, I showed you how Promises can help make the code a large group of serial asynchronous operations more visually appealing and cleaner.
In the next tutorial, we'll go deeper into the Event Loop, which you really need to understand to be the best Node developer you can be.
Video

Test your understanding
True or false
A callback function is executed following a blocking I/O operation and is part of the synchronous coding style.
The Node.js module system is used to extend Node's functionality and works with built-in modules, and custom modules you write.
nodemon is a load testing tool used to test Node application scalability.
Choose the best answer
The Asynchronous coding style:
A. Uses specially formatted comments to tell the V8 optimizer to run the specified code on a background thread.
B. Is best suited for short-lived tasks that do not use much CPU.
C. Uses callback functions that are executed following the completion of non-blocking operations such as I/O.
D. There is no such thing as Asynchronous coding style.
Blocking I/O:
A. Refers to a style of I/O where the operation blocks the request thread until the operation is complete.
B. Uses callback functions that are executed following the completion of non-blocking operations such as I/O.
C. Performs I/O operation in specially formulated blocks (known as "chunks") in order to optimize throughput.
D. None of the above.
If your application code is using a Node API call to perform a non-blocking operation, only a small percentage of that call shows up in the V8 profile. Where is the code running?
A. The code is actually running in a separate thread in libuv's worker pool.
B. The code is running on the V8 thread, there is less of a profile footprint because asynchronous code is simply faster than synchronous code.
C. The code is running in a special thread pool managed by V8.
D. Node core libraries, like those for encryption, are optimized for asynchronous code, so the V8 profile footprint for those is smaller.
Fill in the blank
When reading analyzed output from the V8 profiler, a single sample interval is referred to as a _, and is typically __ milliseconds in duration.
When writing a Promise, you call the __ method when the Promise is fulfilled.
When a promise has been fulfilled, you call the _ method to process the results.
Programming exercises
Write a JavaScript program to:
- Read a file called
foo.txt(assume the file is UTF-8 encoded). - Write its contents to a new file called
newfoo.txt. - Wrap all mainline logic in an IIFE called
mainline(). - Write a message to the console if the write I/O operation is successful.
- Read a file called
Write a module called
echowith a single method calledecho()that takes a single parameter, and writesecho+ the parameter to the console. Write another module calledecho-requesterthat usesechoand passes it a text parameter of your choice. Assume thatecho.jsandecho-requester.jsreside in the same directory.
Quiz answers
Answers for true or false questions
False. A callback function is used as part of asynchronous coding style.
True. In addition, Node's module system works with third party modules that extend Node's functionality that are available in module registries such as npmjs.com.
False. nodemon is a utility that monitors your project's source files for changes and restarts Node if it detects any. It is used to to speed up development cycle.
Answers for multiple choice questions
C. Asynchronous coding style uses callbacks to process the results of the asynchronous call.
A. Blocking I/O blocks the current operation (preventing it from running) until the operation is complete.
A. The code is running in libuv's worker pool (a.k.a., the thread pool). Since V8 cannot profile libuv, only the Node core code that hands the call off to libuv shows up in the V8 profile.
Answers for fill in the blank questions
When reading analyzed output from the V8 profiler, a single sample interval is referred to as a _ tick _, and is typically 1 _ milliseconds in duration.
When writing a Promise, you call the _ resolve() _ method when the Promise is fulfilled.
When a promise has been fulfilled, you call the _ then() __ method to process the results.
Answers to programming exercises
Write a JavaScript program to:
- Read a file called
foo.txt(assume the file is UTF-8 encoded) - Write its contents to a new file called
newfoo.txt - Wrap all mainline logic in an IIFE called
mainline() Write a message to the console if the write I/O operation is successful.
Answer:
const fs = require('fs'); (function mainline() { fs.readFile('foo.txt', 'utf8', (err, fileContents) => { if (err) throw err; fs.writeFile('newfoo.txt', fileContents, (err) => { if (err) throw err; console.log('Operation successful'); }) }) })();Write a module called
echowith a single method calledecho()that takes a single parameter, and writesecho+ the parameter to the console. Write another module calledecho-requesterthat usesechoand passes it a text parameter of your choice. Assume thatecho.jsandecho-requester.jsreside in the same directory.Answer:
echo.js:'use strict' function echo(textToEcho) { console.log('echo ' + textToEcho); } module.exports.echo = echo;
- Read a file called
echo-requester.js:
'use strict'
const echo = require('./echo');
echo.hello('echo echo echo');//echo echo echo echo