Tutorial
PostgreSQL: Experiences and tuning recommendations on Linux on IBM Z
Optimize an open source PostgreSQL database when implementing it on the mainframeThis guide shows how you can optimize an open source PostgreSQL database when implementing on Linux on IBM Z. Based on our experiences and performance measurements, you will learn step by step which configuration options and parameters can help improve your PostgreSQL installation on Linux on IBM Z in terms of:
- throughput
- response time
- general aspects
Target audience and required skills
This performance tuning guide is written for Linux system programmers and database administrators who wish to tune their PostgreSQL database servers running on an IBM Z or IBM LinuxONE system without spending hours researching Linux kernel parameters, PostgreSQL configuration settings, Logical Volume Manager (LVM) options, and other relevant configuration parameters.
The configuration settings presented here are optimized for transactional workloads such as online banking systems, airline ticketing systems, online shopping systems, and any other workload that requires high-volume transactional database processing. Other database access patterns, such as analytical workloads, might require other parameters and settings.
In order to understand and benefit from this guide, you need to have basic Linux system programming skills. Also, basic PostgreSQL database administration skills are helpful, but not required.
Tuning results overview
The chart in Figure 1 shows the overall tuning results that the Linux on IBM Z Performance Team achieved in our test environment. The 100% bar on the left-hand side represents the throughput at the beginning of our research, and each tuning step that was taken is illustrated by another bar, going from left to right in the chart.
Figure 1. PostgreSQL tuning results
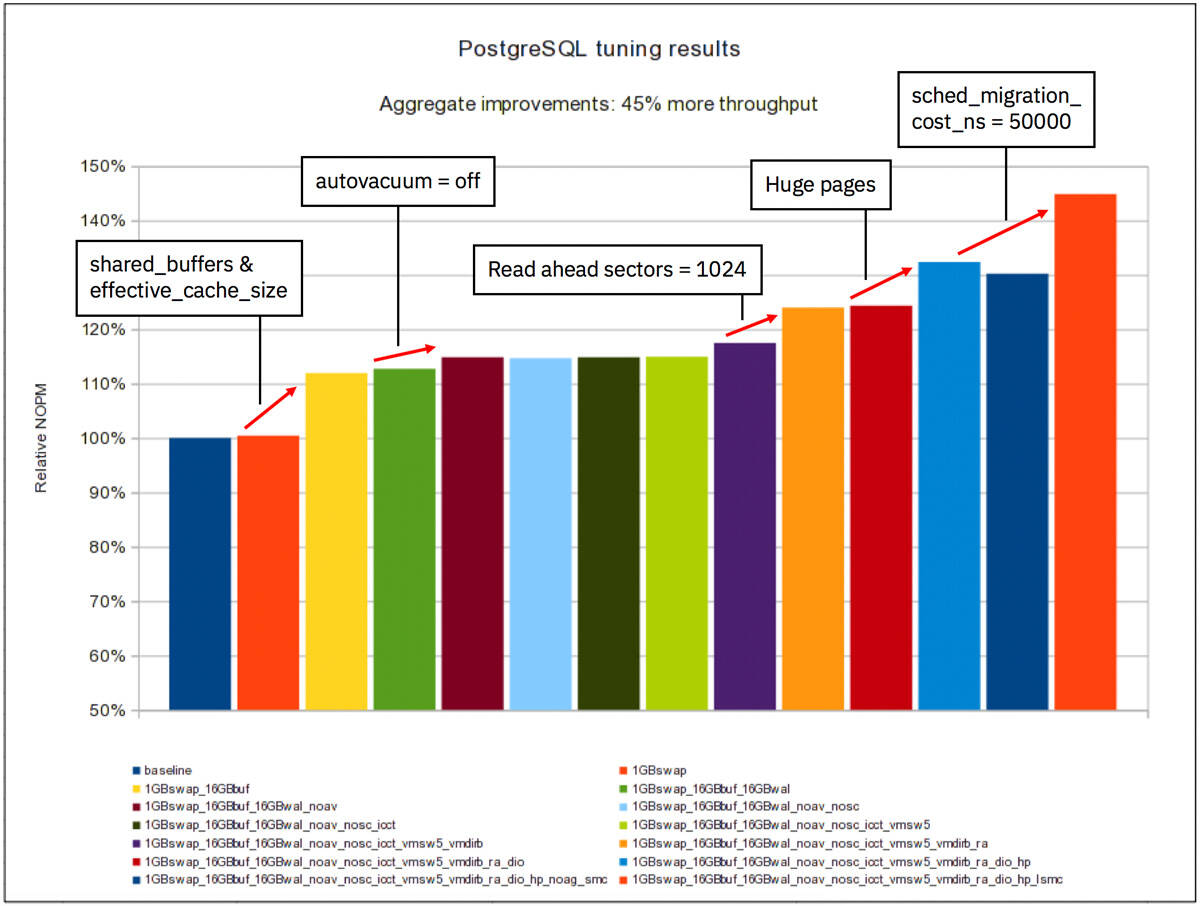
In the end, we achieved 45% higher throughput compared to our initial measurements, which is significant when you take into account that we did not tune the test database itself at all.
Typically, the most significant improvements in database tuning can be achieved by applying changes at the SQL level -- for example, by creating or changing indexes or adapting SQL queries. We didn't apply any of these changes in our study. We only concentrated on configuration changes in the underlying environment: operating system (Linux) and middleware (PostgreSQL).
Observations and tuning recommendations on IBM Z and LinuxONE
Disclaimers
Note: The following is important -- please read it carefully.
The performance test results shown in the following charts were obtained in a controlled lab environment natively in an IBM Z logical partition (LPAR). The measured differences in throughput might not be observed in real-life scenarios and environments other than native LPAR.
All of the test runs were performed with Ubuntu 16.04.2, PostgreSQL 9.5.7, and HammerDB 2.23. Other product versions might produce different performance results.
All of the tests were specifically executed for PostgreSQL. The impact of the recommendations in this chart deck on other database management systems might be totally different, including adverse performance effects.
All of the tests were specifically executed for a heavy online transaction processing (OLTP) workload. The impact of the recommendations in this chart deck on other types of workloads -- online analytical processing (OLAP), for example -- might be totally different, including adverse performance effects.
Throughput
In Figure 1 above, you can see the PostgreSQL throughput of our test environment and how the initial baseline value could be improved by taking certain tuning actions.
In order to optimize the throughput of your PostgreSQL database on Linux on IBM Z, consider the following recommendations.
Throughput recommendation #1: Increase the size of the PostgreSQL shared buffers to 1/4 of the total amount of physical memory and the size of the effective cache to 3/4. (Read the recommendation from the official PostgreSQL tuning wiki.)
This turned out to be one of the major tuning knobs, yielding almost 12% more throughput (see the tuning results chart).
Important: Do not increase the size of the PostgreSQL shared buffers too much (for example, to 1/2 of the total amount of physical memory). Otherwise, you will see activity from the Linux out-of-memory (OOM) killer.
Lowering the size of the shared buffers to 1/8 did not lead to performance degradation for the HammerDB TPC-CTM workload. (Note: This might not hold true for other database workloads.)
Why is the impact of the larger shared buffers so marginal? Probably because PostgreSQL relies heavily on the effectiveness of the Linux page cache. This is mentioned several times in the PostgreSQL documentation.
The effective cache size setting is not an actual memory allocation, but only "an estimate of how much memory is available for disk caching by the operating system and within the database itself" (according to the tuning wiki). This is used by the PostgreSQL query planner.
Throughput recommendation #2: For mostly read-only workloads, consider turning off the autovacuum daemon in PostgreSQL.
In general, it is a good idea to keep the autovacuum daemon turned on (it is turned on by default).
The autovacuum daemon does some very useful things, including:
- Recovers or reuses disk space that's occupied by updated or deleted rows
- Updates data statistics that are used by the PostgreSQL query planner
This process can cost you some CPU cycles. Turning the autovacuum off for the HammerDB TPC-C workload resulted in almost 2% more throughput (see the tuning results chart).
For write-heavy production workloads -- those with lots of INSERT, UPDATE, and DELETE statements -- the clear recommendation is to keep the autovacuum daemon turned on; otherwise, a lot of disk space could be wasted, and/or the database statistics could be bad or skewed. The only exception to this rule might be situations where the inserted and/or updated data does not change the statistics information significantly -- but this can be very hard to figure out.
For mostly read-only database workloads, the statistics information does not change significantly over time, so you could try running PostgreSQL with the autovacuum daemon turned off. Nevertheless, a manual VACUUM operation should be scheduled (via a cron job, for example) at times when the load on the system is low.
Throughput recommendation #3: Turn on read ahead for the logical volume that contains the database data files.
Why is this setting noteworthy? Because up to now, the clear recommendation for databases was to turn read ahead off at the Logical Volume (LV) / block device level. For example, DB2 performs better if read ahead is turned off at the LV / block device level.
Turning read ahead on resulted in almost 6% more throughput (see the tuning results chart). Again, the reason for this is probably the fact that PostgreSQL relies heavily on the effectiveness of the Linux page cache. Other databases decide for themselves which pages should be read ahead, and do not rely on the read-ahead functionality of the operating system.
Throughput recommendation #4: Turn on huge pages.
In this context, huge pages means persistent huge pages that are configured via a setting in /etc/sysctl.conf: vm.nr_hugepages=17408 (17 GB). Don't forget to turn off transparent huge pages.
Turning huge pages on resulted in about 7% more throughput in our tested workload (see the tuning results chart).
Why 17 GB? Shared buffers consume 16GB, plus some extra memory required by PostgreSQL for other purposes, and some extra "headroom" for safety reasons.
If you want to know exactly how much memory PostgreSQL uses, look at the /proc/[PID]/task/[TID]/status file and search for the "VmPeak" entry.
Throughput recommendation #5: For a smaller number of IFLs and many parallel users, consider lowering the kernel scheduler's migration cost.
Test runs with the Intel x86 related parameters led us to perform some experiments with smaller migrations costs for the kernel scheduler. kernel.sched_migration_cost_ns= sets the number of nanoseconds that the kernel will wait before considering moving a thread to another CPU.
The higher this migration cost is, the longer the scheduler will wait before considering moving a thread to another CPU. This makes a lot of sense for large Linux images and/or scattered Linux images that span multiple PU chips and/or multiple nodes, or even multiple drawers in the z13 topology.
However, our test runs were based on a 4 IFL configuration and therefore all CPUs did actually fit on the same PU chip. This was verified with lscpu --extended.
Some important details to keep in mind
- All cores on the same PU chip share the same L3 cache (and L4 cache, of course).
- PostgreSQL spawns a new process for each virtual user; this means we had lots of Linux processes.
- Although the system was heavily loaded, there was still quite a bit of idle time.
In addition, lowering the scheduler's migration cost by one order of magnitude increases the throughput by almost 9%. Add the following to /etc/sysctl.conf:
kernel.sched_migration_cost_ns=50000`
This means that in our particular configuration, it is not beneficial for performance to try to let the individual PostgreSQL processes run as long as possible on the same CPU/core. Even if they are dispatched on another core, they are still on the same PU chip -- meaning either the L3 cache still contains a good amount of relevant information for the process or the L3 cache is totally flooded anyway.
If the amount of user time increases significantly, that's a clear indication that the Linux image is performing more useful work with this setting applied. This can be verified with top and/or sar data
Important: Don't simply apply this setting without testing for large Linux images and/or Linux images that have their CPUs scattered all over the z13 topology and/or environments where you only have a very small number of parallel users. You can verify the current topology with lscpu --extended. In this context, a small number of users means #users = #cores.
Response time
The graphs in Figures 2 and 3 illustrate throughput before and after the configuration changes.
Figure 2. Throughput graph before configuration changes
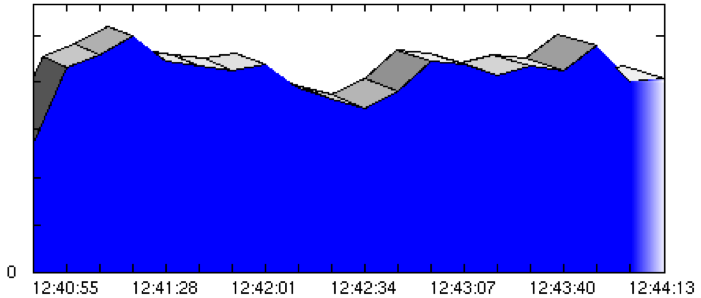
Note: Of course, response time is not equal to throughput. However, from the throughput graph, one can conclude that the response times must have been very shaky because the amount of virtual users didn't change after the ramp-up phase.
Figure 3. Throughput graph after configuration changes
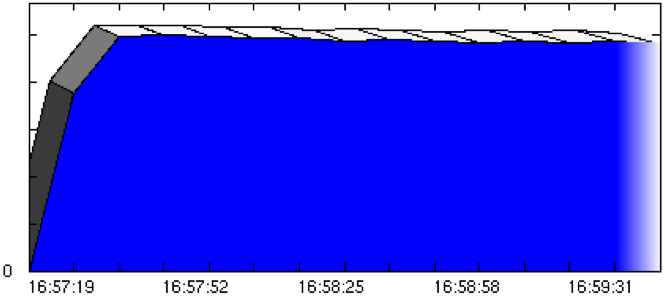
Note: A stable overall throughput graph is not an absolute guarantee that the response times of the individual virtual users were 100% consistent during the entire test run. It is, however, a very strong indicator.
Response time recommendation #1: Adjust the kernel's settings regarding the writeback of dirty pages.
The default values of these settings are very high:
vm.dirty_background_ratio=10(10% of 64GB = 6.4 GB)vm.dirty_ratio=20(20% of 64GB = 12.8 GB)
Our recommendation is to lower those 2 values in /etc/sysctl.conf:
vm.dirty_background_bytes=67108864(64 MB)vm.dirty_bytes=536870912(512 MB)
This recommendation not only helps improve overall throughput by around 2%, but it also helps greatly to avoid burst situations in the disk I/O subsystem. Without adjusting these settings, you will see spikes in the number of pages/kilobytes written to disk per second.
Applying the values mentioned above leads to more consistent response times for end users, since I/O bursts are smoothed out. Throughput is not the only important metric when it comes to performance.
All of this has an important side-effect: These settings speed up the restore of a 256 GB database snapshot from about 20 minutes to about 13 minutes, which is great for recovery situations.
Exactly how much you lower these values is not particularly important, but it is important to lower them significantly compared to the defaults. For example, experiments with 32 MB, 64 MB, and 128 MB for vm.dirty_background_bytes did not lead to significant changes for the duration of the database restore, but 512 MB turned out to increase the duration again. 64 MB seems to be a reasonable value for vm.dirty_background_bytes, and is also recommended in other PostgreSQL-related publications.
Response time recommendation #2: Consider applying a number of PostgreSQL settings that smooth out end user response times.
There are a number of PostgreSQL settings that do not actually increase throughput, but help to smooth out end user response times. Remember, throughput is not the only important metric when it comes to performance!
Note: To make changes to any of these settings you need to edit /etc/postgresql/9.5/main/postgresql.conf.
Parameter #1:
checkpoint_completion_target- The default value for this parameter is 0.5.
- The value recommended by many PostgreSQL-related internet sources is 0.9.
- Pro: Reduces the I/O load from checkpoints by spreading the checkpoint out over a longer period of time.
- Con: Prolonging checkpoints affects recovery time in case of a failure.
Parameter #2:
max_wal_size- The default value for this parameter is 1 GB.
- The value recommended by many PostgreSQL-related internet sources is 16 GB.
- Pro: Checkpoints occur less frequently (check
/var/log/postgresql/postgresql-9.5-main.log) because more Write Ahead Log (WAL) can be written per checkpoint. - Con: Less frequent checkpoints affect recovery time in case of a failure.
Parameter #3:
wal_buffers- The default value for this parameter is -1.
- The value recommended by many PostgreSQL-related internet sources is 16 MB.
- Pro: Fewer physical writes to the disks due to increased buffering of WAL data.
- Con: Higher number of lost transactions in case of a failure.
Parameter #4:
synchronous_commit- The default value for this parameter is on.
- The value recommended by many PostgreSQL-related internet sources is off.
- Pro: Slightly improves response times, since success is reported to the client before the transaction is guaranteed to be written to disk.
- Con: Can lead to loss of transactions.
- We do not recommend turning
synchronous_commitoff, since it did not increase performance in our test cases, and there is a risk of loss of end-user transactions.
General recommendations
General recommendation #1: Add some swap space.
In general, it is advisable to have at least a small amount of swap space available, in order to be prepared when there are spikes in memory consumption. Otherwise, you will see activity from the Linux OOM killer. In our series of test runs, there were combinations of parameters/settings where turning swap space on increased throughput, and there were combinations of parameters/settings where having swap space turned on or off did not make any difference in database throughput. However, turning swap space on did not hurt performance. Even if it doesn't have a positive impact on performance, having swap space turned on has more benefits than disadvantages.
General recommendation #2: Use Direct I/O for the transaction logs.
Using Direct I/O for your database workloads can greatly improve the overall reliability of your database workload's operations. By using Direct I/O, the database bypasses the Linux page cache and writes directly to the disks, thus avoiding loss of transactions in case of a failure.
So how much of an impact does the usage of Direct I/O have on performance? In our test cases, the impact was significantly less than one percent. In benchmarking, this is generally considered white noise.
General recommendation #3: Be careful with tips for Intel x86 Linux and/or different kernel versions.
For example, on the PostgreSQL performance mailing list, there is a popular post entitled Two Necessary Kernel Tweaks for Linux Systems where users reported throughput increases of up to 30% with the mentioned settings. However, those tips were for Linux on Intel x86 and very probably for a kernel version different from the one used in our test runs. In our environment, the specified settings decreased the throughput by about 2%. These settings were related to the Linux scheduler: kernel.sched_migration_cost and kernel.sched_autogroup_enabled. Therefore, be careful with tips for Intel x86 and / or different kernel versions as they could have opposite effects when applied to your environment.
General recommendation #4: Separate the database data files from the database transaction log files.
This is a general recommendation for database workloads, and not specific to PostgreSQL. It holds true for all relational databases. Performance gain in the sandbox environment was about 10% more throughput. This is because:
- The I/O behavior of the data files (random r/w) was separated from the I/O behavior of the transaction log files (sequential writes).
- There was better overall usage of the storage server infrastructure due to more disks (one disk for both data and logs vs. one disk for data and one disk for logs).
Performance gain in the large environment was close to 0%. One possible reason for this is that we used many different logical unit numbers (LUNs) for our LVMs, and each LUN by itself is spread across many physical disks by means of DS8K storage pool striping.
Nevertheless, the recommendation is to separate the data files from the transaction log files due to the unpredictable nature of your to-be-deployed database workload (random reads vs. sequential reads, large hit ratio vs. small hit ratio, etc.). Plus, separating the data files from the transaction log files does not hurt performance.
Important: Make sure that the disks for the log files are physically different from the disks for the data files; otherwise, you will not see any benefit at all. In terms of DS8K, if you cannot guarantee physically different disks, you can at least use disks from different storage servers and different extent pools.
This is easy to implement in PostgreSQL: Just create a symbolic link from the original transaction log file location to the new location. (To learn more, read How To Move a PostgreSQL Data Directory to a New Location on Ubuntu 16.04.)
Test environment used for performance measurement and tuning approach
For the PostgreSQL installation, we used an IBM Z (z13) system with an attached DS8000 storage server. A load generator running on an Intel x86 server was connected to the IBM Z system via a switch.
Figure 4. High-level environment setup

We followed these steps to set up the test environment:
Installed a sandbox environment in order to get familiar with Ubuntu, PostgreSQL, and HammerDB. The goal was to have an environment that was as simple as possible, and to start with an out-of-the-box configuration.
Populated a small TPC-C test database with HammerDB built-in functionality. For this, the most important configuration parameter was the number of so-called warehouses.
Put the System Under Test (SUT) under light load (a small number of virtual users) just to see how it behaved at run-time. Generally speaking, at a first glance, PostgreSQL behaved like any other modern database: It is both CPU and I/O intensive.
Applied numerous tuning parameters at all levels (OS, I/O, database) in small test runs, just to see if they had any effect. The goal here was to determine if the parameters should be evaluated in large test runs.
Selected parameters based on internet research (PostgreSQL documentation, wikis, blog entries, etc.), as well as by analyzing the run-time behavior of PostgreSQL and choosing appropriate well-known kernel parameters, LVM settings, etc.
After gaining experience with the sandbox environment, set up a large test environment in its own LPAR. A larger environment means more memory (64 GB) and more disk space (256 GB database size).
Applied additional tuning parameters, where the expectation was that they will show some effects in the large test environment (see the "Observations and tuning recommendations" section above for more details).
Implemented automated test scripts based on an internal test framework and homegrown shell scripts in order to do identical benchmark runs. The results are stored in a database along with sadc/sar data, etc.
Finally, ran so-called night runs with exclusive use of the IBM Z host (IBM z13) and storage server (DS8000). The goal here was to generate reproducible benchmark results.
The goal of the tuning experiments was to gain a pragmatic set of parameters/switches that led to measurable performance improvements. The goal was not to execute performance test runs for the sake of scientific curiosity. In addition, the goal was not to performance-tune the HammerDB built-in TPC-C workload, but to give recommendations that would probably hold true for all transaction-oriented workloads. So we did not do any tuning of TPC-C related SQL statements, indexes, tablespace design, etc.
Outlook: We plan to perform additional tests with PostgreSQL and with other databases to optimize on Linux on IBM Z/IBM LinuxONE, including inside a Docker container and inside an IBM Secure Service Container (SSC).
Summary
In this tutorial, you learned that PostgreSQL is a pretty mature open source database. In all of our test runs, we did not experience a single failure, crash, or anything similar. You also saw how PostgreSQL is well suited to being run on Linux on IBM Z, either in a virtual machine or natively in an LPAR. You can greatly improve the performance of your PostgreSQL database on Linux on IBM Z by following the recommendations in this tutorial (such as shared buffers, read ahead, huge pages, and scheduler settings). And there are some additional recommendations that you should also follow, even if they don't have a direct impact on performance (such as swap space, usage of Direct I/O, and writeback of dirty pages).
To expand your PostgreSQL tuning skills, a great source of information is the PostgreSQL tuning wiki.