Tutorial
Build a Tekton Pipeline to deploy a mobile app back end to OpenShift 4
Create an automated Tekton Pipeline to deploy several microservices used to handle data access tasksArchive date: 2023-11-10
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Now that OpenShift 4.3 is available on IBM Cloud, there's a lot of chatter regarding exciting new capabilities. One of the flashier components that I'm most excited about is the ability to view Tekton Pipeline resources from the OpenShift web console.
While the Tekton Dashboard is still a great way to view what's going on with your Tekton resources, this new functionality, part of OpenShift 4, makes it available in the user interface (UI), which you can see in the following screen capture.
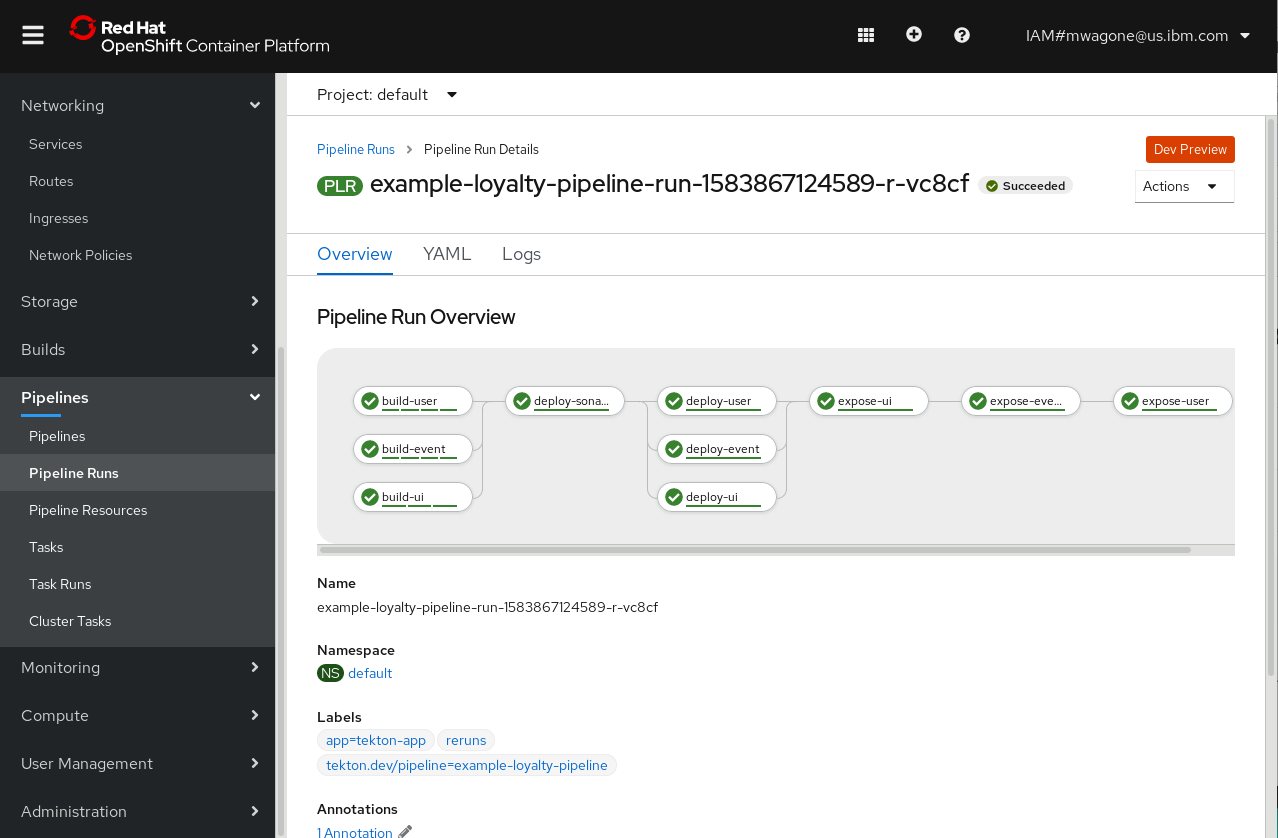
To demonstrate some of the capabilities of Tekton on OpenShift, this tutorial deploys an instance of Example Bank, an example customer credit card application.
The examples in this tutorial use Red Hat® OpenShift® on IBM Cloud™.
Prerequisites
To complete this Tekton and OpenShift tutorial, you need the following environment:
A Red Hat OpenShift on IBM Cloud cluster already provisioned to enable you to set up a pipeline.
If you need to create one, you can use the IBM Cloud web console or the
ibmcloudCLI. When using the latter, this tutorial may come in handy.NOTE: This tutorial is not compatible with Cloud Pak for Applications. You will need an empty cluster.
A few CLIs, including
kubectlandoc, which can be found in these docs.There are a few steps from the main code pattern that need to be implemented before starting the tutorial. Complete the Prerequisites and Deployment sections to set up an App ID instance, a PostgreSQL database, and the integral kubernetes secrets in an
example-bankproject.
Estimated time
After the prerequisites are met, this tutorial takes approximately 30 minutes to complete, including the time required for the pipeline to run.
Understand the Example Bank app
Example Bank is an example app set up to show how you can reward users of your application. It grew out of a project implemented at several conferences (Ah, remember those days?) to register attendees and distribute swag.
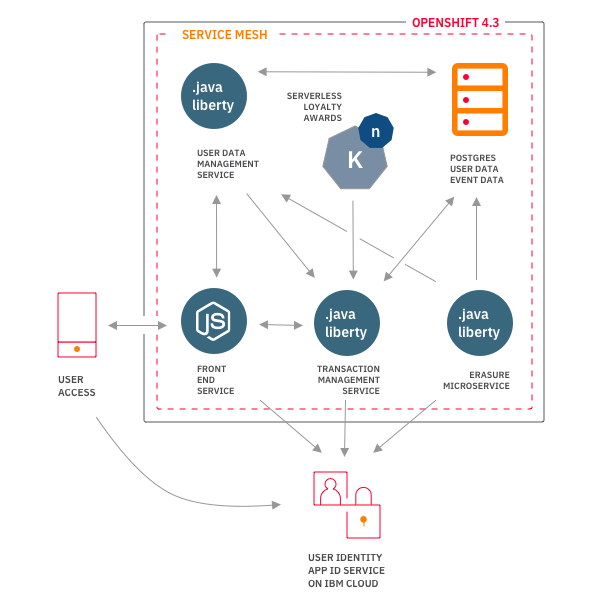
The back end of Example Bank is what this tutorial deploys through a pipeline. It consists of several microservices, including two Java services to keep track of events and users respectively, a nightly service to delete user data, a Node.js front end, and a PostgresSQL instance to keep track of it all.
Steps for setting up a pipeline
To get started, you first need to install Tekton Pipelines itself. Then you can apply all the resources you need to run the pipeline specific to this exercise.
1. Target your cluster
Log in to your IBM Cloud account and navigate to the overview page for your OpenShift cluster. Click on the OpenShift web console button in the upper right corner. On web console, click the menu in the upper right corner (the label contains your email address), and select Copy Login Command. Paste the command into your local console window. It should resemble the following example:
oc login https://c100-e.us-east.containers.cloud.ibm.com:XXXXX --token=XXXXXXXXXXXXXXXXXXXXXXXXXX
2. Install Tekton
Next up, Tekton installation. From the navigation menu on the left of your OpenShift web console, select Operators --> Operators Hub and then search for the OpenShift Pipelines Operator. Click on the tile and then the subsequent Install button. Keep the default settings on the Create Operator Subscription page and click Subscribe.
3. Create a new project
Back in your local console, let us separate the tools from the application by creating a new project:
oc new-project bank-infra
4. Create a service account
To make sure the pipeline has the appropriate permissions to store images in the local OpenShift registry, you need to create a service account. For this tutorial, call it "pipeline".
oc create serviceaccount pipeline
oc adm policy add-scc-to-user privileged -z pipeline
oc adm policy add-role-to-user edit -z pipeline
oc policy add-role-to-user edit system:serviceaccount:bank-infra:pipeline -n example-bank
That last command grants your service account access to the example-bank project. You should have created it as part of the prerequisites.
5. Install tasks
Tekton Pipelines are essentially a chain of of individual tasks. This tutorial uses serveral tasks, but you can install them all at once by cloning the main code pattern repo and then targeting the pipelines/tasks folder:
git clone https://github.com/IBM/example-bank
cd example-bank/pipeline
oc apply -f tasks
6. Create the pipeline
The pipeline file (example-bank-pipeline.yaml) links together all the tasks of your pipeline, in this case consisting of: code scanning, building code into an image, and then deploying and exposing those images.
kubectl apply -f example-bank-pipeline.yaml
Steps for threat testing
Did I say code scanning? Let’s take this exercise in creating a pipeline a step further and introduce threat testing by including an application called SonarQube. SonarQube is open source software for inspecting a code base. It supports a plethora of languages. SonarQube can report on bugs and security vulnerabilities, as well as other helpful areas like code coverage and unit tests. This tutorial uses SonarQube to test code for vulnerabilities.
1. Deploy an instance of SonarQube
Another file in the repo describes all the settings needed for a deployment of SonarQube. A Deployment lists all the volumes and mount paths SonarQube requires. Additionally, a Service and Route allow the app to be publicly accessible. One file contains all this information:
oc apply -f sonarqube.yaml
2. Create a PVC
You also need a Persistent Volume Claim. It allows the tasks in the pipeline to have a common place to write information to share with one another:
oc apply -f bank-pvc.yaml
3. Run the pipeline
Finally, with your vulnerability scanner in place, you can run your loyalty pipeline using a PipelineRun file:
oc create -f bank-pipelinerun.yaml
Anytime you need to rescan and/or redeploy your code base, simply run that command.
Results
Now to enjoy the fruits of our labor! SonarQube has its own web interface. To get to it, navigate to the loyalty-infra project in the OpenShift web console. From the menu on the left, select Networking and then Routes:

Select the URL for SonarQube and check out the stats for your installation:
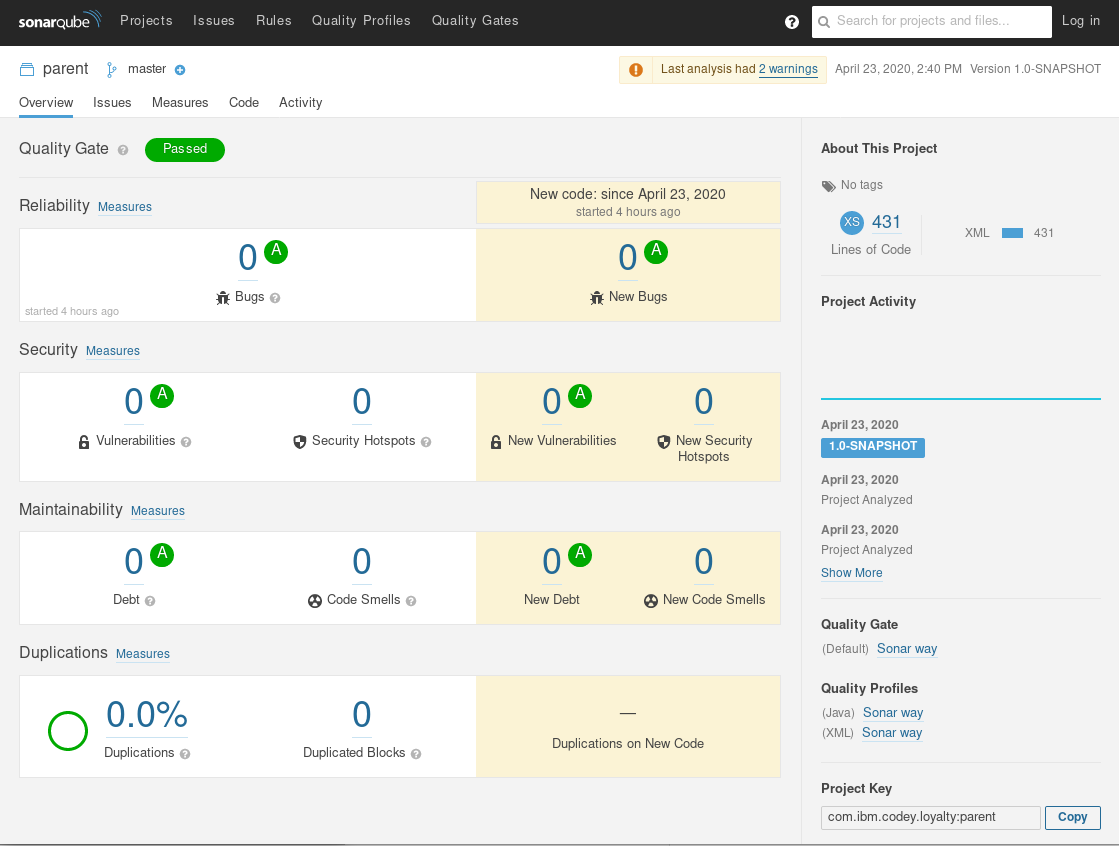
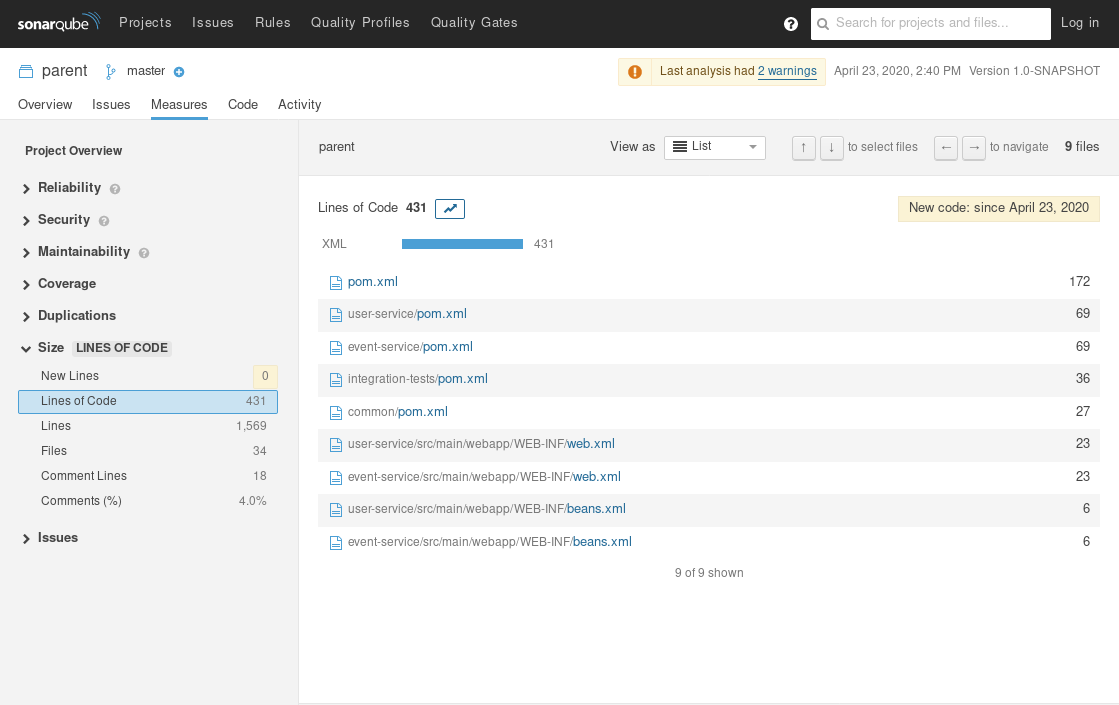
All green! Since there are no vulnerabilites here, you can click through to check out the stats for the lines of code:
Back on the Routes page, you can also find the URL for the user interface of your freshly installed Example Bank app. For the loyalty-mobile-simulator-service:

Summary
As you can see, Tekton Pipelines are powerful, allowing you to automate some significant workloads. Housed within the same cluster as your imaged code base, this cloud-native approach to continuous deployment can become seamless and hands-free. The new features in OpenShift 4.3 make it easier to see what's happening with your Tekton pipelines.
After practicing with this example, you can explore ideas for using pipelines in your own installations!