Article
An introduction to the DataOps discipline
End-to-end data management and the elimination of data silosDataOps is a collaborative data management discipline that focuses on end-to-end data management and the elimination of data silos. There are many DataOps definitions provided by the various thought leaders in this space, such as IBM, Gartner, Eckerson Group, Forbes, and DataKitchen, all of which essentially define it as "the orchestration of people, processes, and technology to accelerate the quick delivery of high-quality data to data users." Built on software development frameworks such as Agile, DevOps, and Statistical Process Control, DataOps offers the following benefits:
- Decreases the cycle time in deploying analytical solutions
- Lowers data defects
- Reduces the time required to resolve data defects
- Minimizes data silos
DataOps dimensions
There are three dimensions across which DataOps is executed: people, processes, and technology. It requires the organization of a team to promote collaboration and drive culture change, to identify and develop processes that transform existing data pipelines into DataOps pipelines, and absorb its value and identifying advantageous technical product features in a DataOps technology.
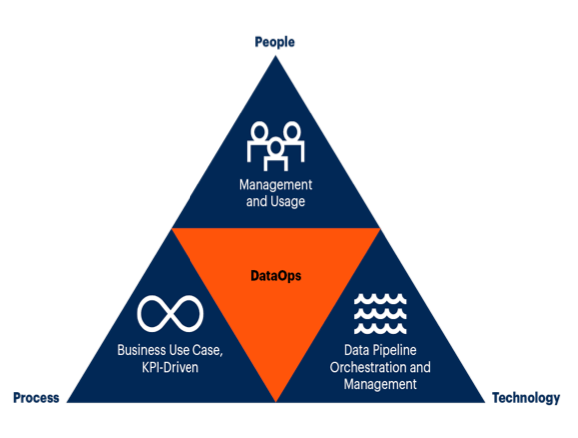
The DataOps team
DataOps supports a highly productive and tightly collaborative team that uses automation technology to help deliver efficiency gains. It comprises DataOps managers, such as data engineers, information architects, and DataOps engineers who are responsible for leading the delivery, management, and support of high-quality, mission-ready data at scale.
- Data engineers are responsible for data curation, data cleansing, and data availability.
- Information architects are responsible for conceptualizing the data framework. They work with the relevant stakeholders within the enterprise to understand the business challenges and translate them into requirements and solutions.
- DataOps engineers are responsible for the frequent and timely releases of data pipelines and data products into production. Their responsibilities include end-to-end management and automation of the provision of environments, the data on the data platforms, deployment, testing, release, security, and monitoring processes.
In addition to the DataOps managers, the DataOps team also consists of DataOps consumers, such as data scientists and data analysts, who ultimately turn the data into business value.
- Data scientists conduct research and iteratively perform experiments to create algorithms and machine learning models that address questions or solve problems.
- Data analysts perform analytics to summarize and synthesize massive amounts of data in the data warehouses created by data engineers. They can also create visual representations of data to better communicate information that can be used to gain insights into the data.
The DataOps process
DataOps enables you to engineer data by creating continuous end-to-end data flows using automated processes, quality control, and self-service tools. The right capabilities in technologies and tools can help you discover and deliver data in a matter of days or hours as opposed to weeks or months.
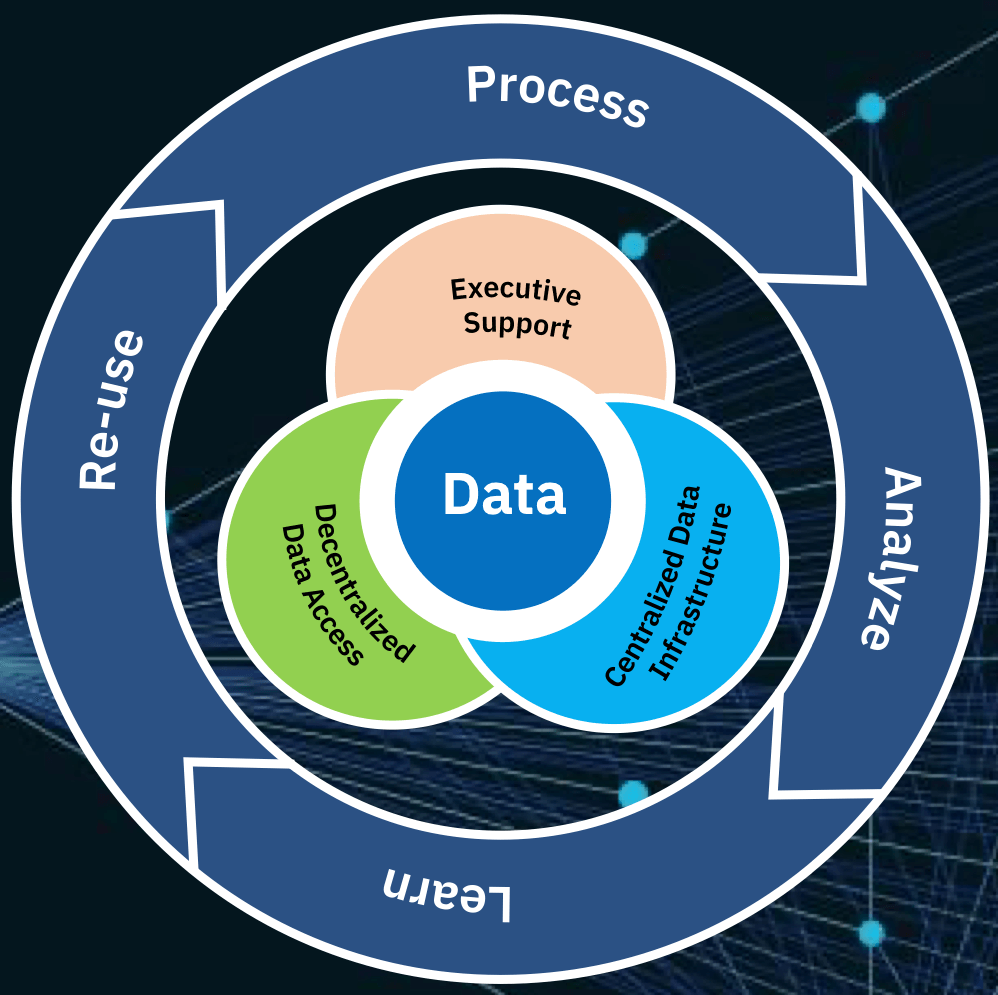
The DataOps process comprises the following steps:
- Step 0. Pre-Collect Planning for your project by gathering customer requirements, defining the business objectives, use cases, and KPIs.
- Step 1. Collect Identifying your existing information architecture (what you are working with in terms of the applications being used, the data storage, the scope of the data) and defining what your information architecture should be (what your data solution should look like, if you need additional data storage, new or updated processes, dependencies, and additional environments).
- Step 2. Organize Organizing your data by performing data quality analysis, ensuring data lineage is maintained since the beginning and using data cleaning to fix problems with the data.
- Step 3. Analyze Enriching your data using feature engineering, cataloging the useful features as well as models created using the data, and ensuring the models and data are versioned in order to easily track experiments and to make comparisons easier.
- Step 4. Infuse Infusing the data models into applications using reproducible, automated deployments.
- Step 5. Monitor Quality Control Automated end-to-end monitoring of data pipelines in order to ensure that problems are identified earlier in the pipeline when they are easier as well as cheaper to fix.
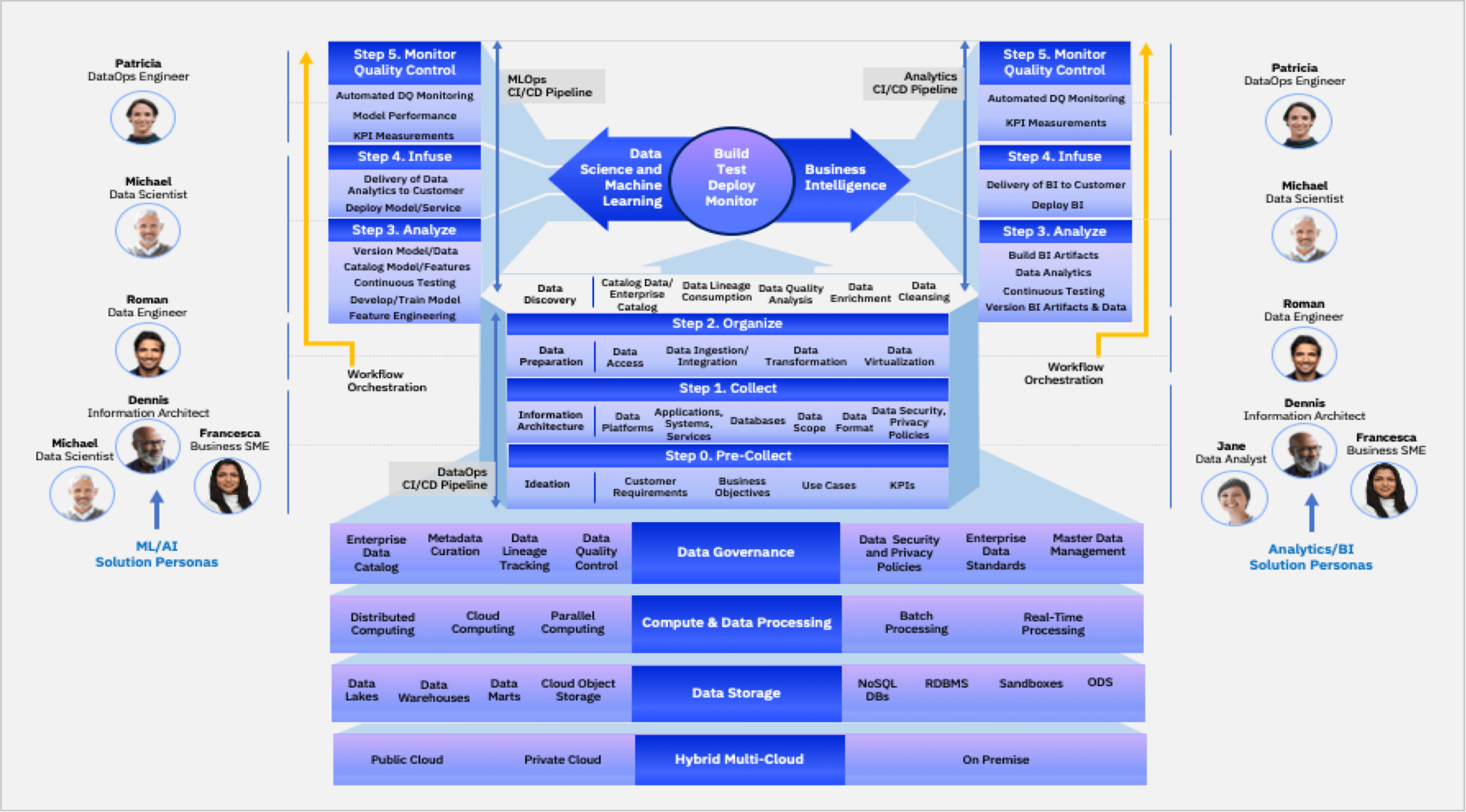
Organizing data as part of the implementation of DataOps using IBM Cloud Pak for Data
In the Create a strong data foundation for your AI learning path, you concentrate on the data governance and data virtualization portion within Step 2 (Organize) of the DataOps process. This case study makes use of synthetic patient healthcare data created by using Synthea and creates a technology pipeline that organizes and manages healthcare data in an enterprise setting. The following products are employed in this case study:
- IBM Cloud Pak for Data
- IBM Watson Knowledge Catalog
- IBM Data Virtualization
- Red Hat OpenShift
- Db2 on IBM Cloud
The pipeline consists of the following steps:
- Set up IBM Cloud Pak for Data on Red Hat OpenShift
- Set up governance artifacts for the data
- Discover the data in the data sources
- Analyze the quality of the data
- Secure the data
- Integrate the data
NOTE: The Organize step of the DataOps process also includes data preparation aspects. However, the data preparation steps are not included in this series and it is assumed that the data is already cleaned and ready to be governed and integrated.
Set up IBM Cloud Pak for Data on Red Hat OpenShift
There are a number of services available on IBM Cloud Pak for Data that can be used to govern, analyze, and protect your data. IBM Cloud Pak for Data runs on a Red Hat OpenShift Kubernetes Container.
IBM Cloud Pak for Data can be installed through a tile in the IBM Cloud catalog.
Set up governance artifacts for the data
The success of DataOps begins with data governance. A solid data governance foundation created using an enterprise data catalog that defines the business data definitions, data location across data environments, data formats, and data lineage makes it easier to discover and use the data. Additionally, healthcare data involves huge amounts of information that needs to be protected as per HIPAA laws. IBM Cloud Pak for Data offers the IBM Watson Knowledge Catalog service, which provides a number of features to incorporate such policy, security, and compliance features and to govern your data.
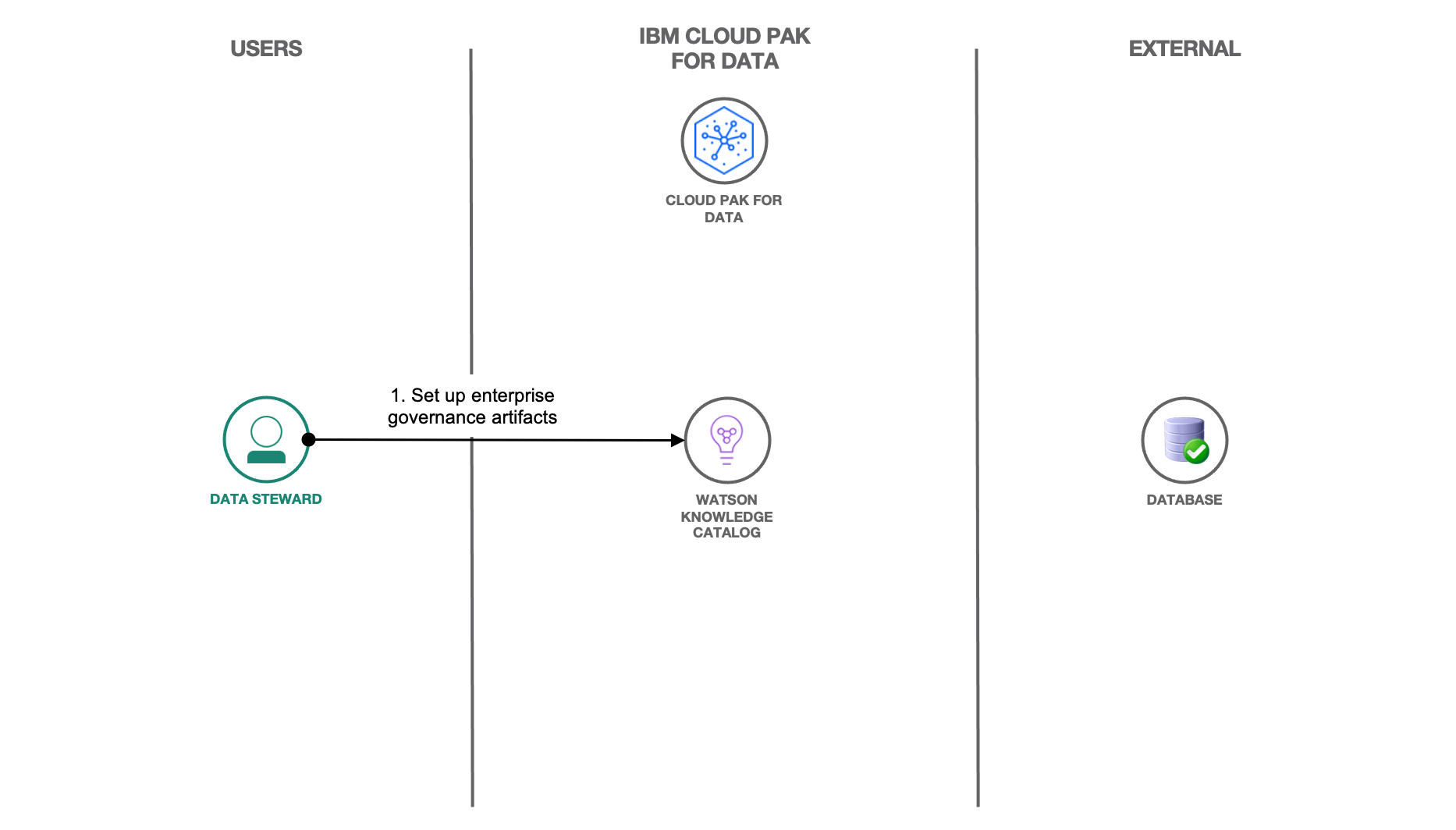
A data steward or administrator can use the IBM Watson Knowledge Catalog to build a governance catalog consisting of terms, policies, and rules that can help govern and secure the data. You can use the Incorporate enterprise governance in your data tutorial within the learning path to learn about the various governance artifact types that are available in IBM Cloud Pak for Data and to set up the governance artifacts that are needed for the Healthcare data.
Discover the data in the data sources
The data in an organization can be spread across multiple data sources and across multiple tables within these data sources. Assigning the governance artifacts to the data can make the data easily identifiable and make related data easily accessible.
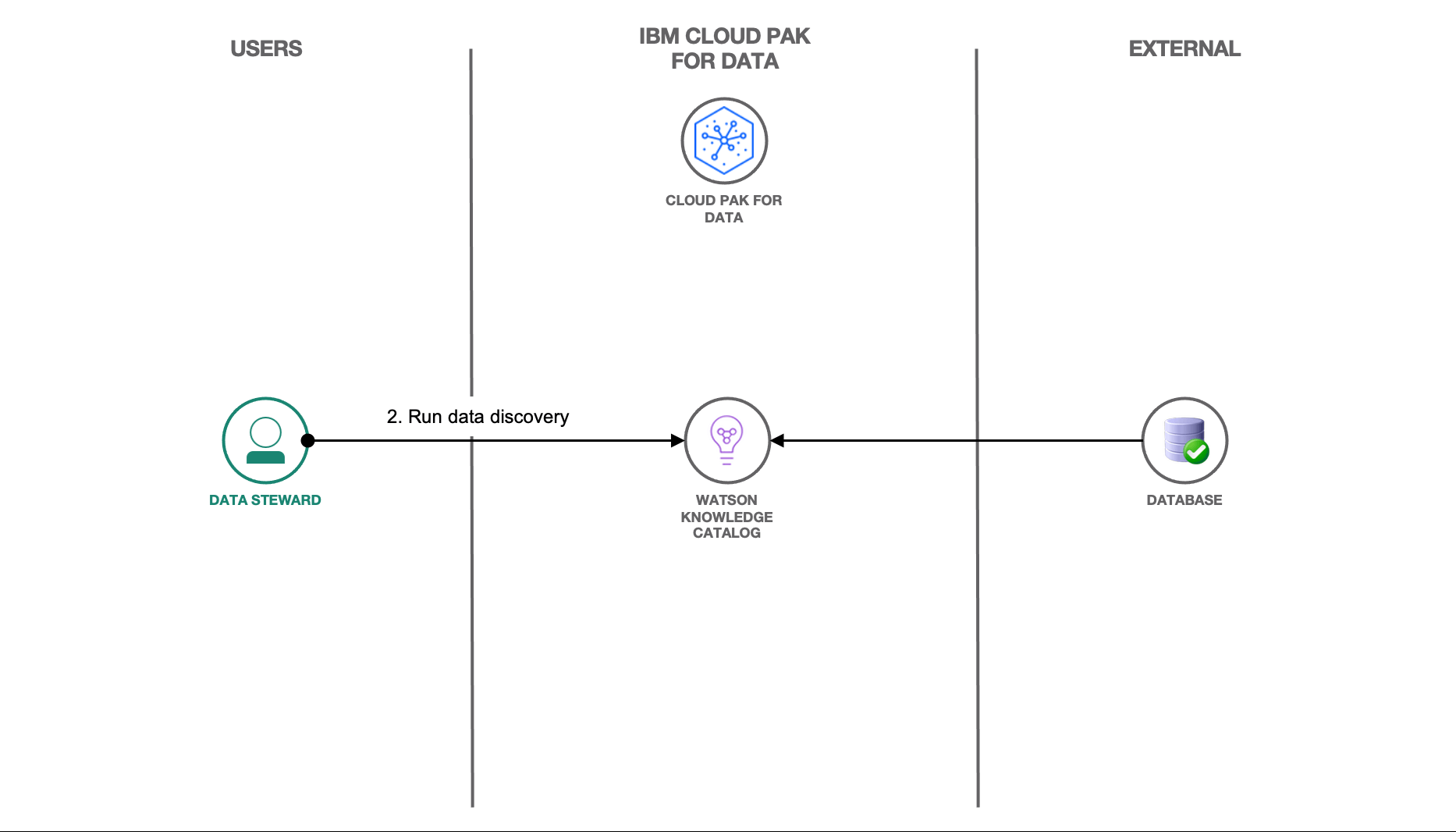
Once the governance artifacts have been defined, a data steward or administrator can easily locate, and identify the data in the data sources using the data discovery feature of IBM Watson Knowledge Catalog. Data discovery, in addition to discovering the data, also identifies governance artifacts for the data. You can use the Learn to discover data that resides in your data sources tutorial to see how Watson Knowledge Catalog on IBM Cloud Pak for Data can be used to discover the data from your data sources and how Watson Knowledge Catalog attempts to identify and assign the right governance artifacts to your data.
Analyze the quality of the data
Once the data assets are discovered and the governance terms are assigned by Watson Knowledge Catalog, it provides the ability to further drill down into the assignments and to update them, as required. In addition, Watson Knowledge Catalog can be used to incorporate additional rules that can help ensure that the data is of the utmost quality.
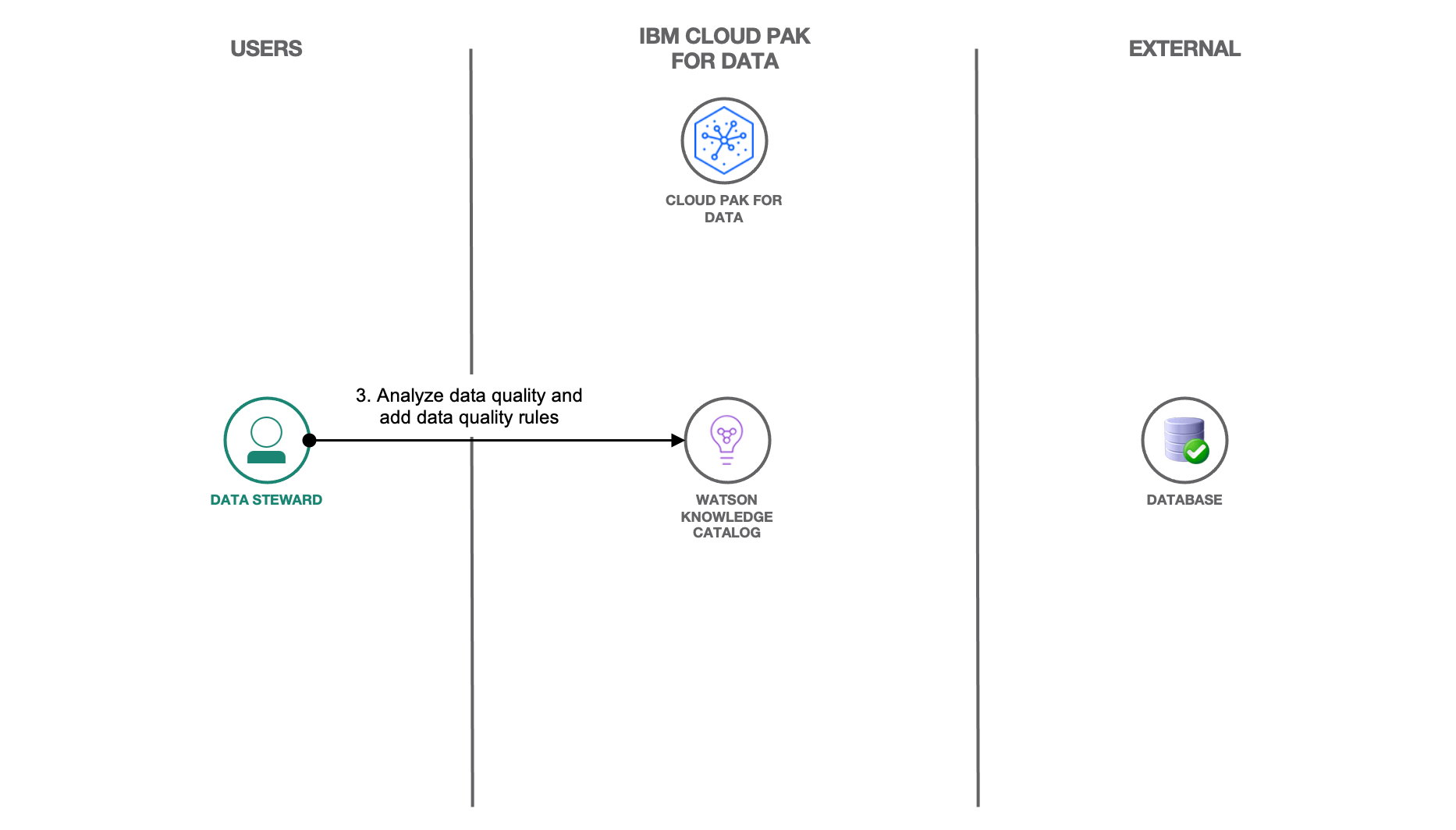
The data steward can use Watson Knowledge Catalog on IBM Cloud Pak for Data to perform data quality analysis of the discovered data. They can add additional data and quality rules that the discovered data should observe. The Analyze discovered data to gain insights on the quality of your data tutorial walks through the process of reviewing the assigned governance artifacts and incorporating data quality rules in the data.
Secure the data
In addition to data quality rules, data protection rules can also be incorporated into the governed data to ensure the security of the data and to ensure that individuals can view certain sensitive portions of the data only if they are allowed to do so.
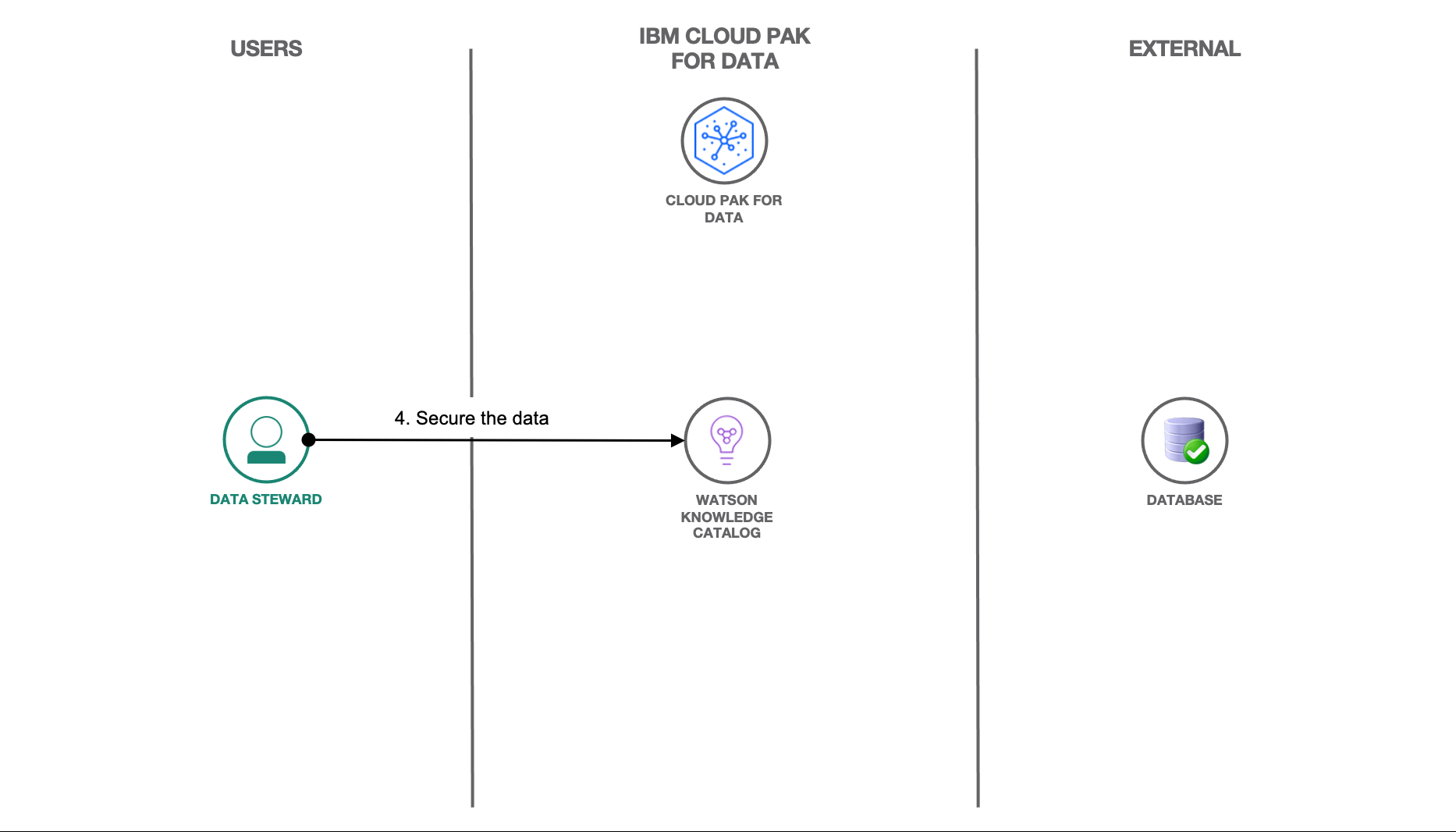
Using Watson Knowledge Catalog on IBM Cloud Pak for Data, the data steward can protect the data by incorporating data privacy. The Protect your data using data privacy features tutorial outlines how you can use the data privacy features of Watson Knowledge Catalog to protect any sensitive pieces of information within your governed data and ensure that data is only accessible by authorized users. Once the data is protected using the data protection rules, it can be published to a governed catalog.
Integrate the data
By now, the data is governed using the governance artifacts, its quality is ensured using data and quality rules, and it is protected using the data protection rules. Next, the data can be integrated using processes like data virtualization.
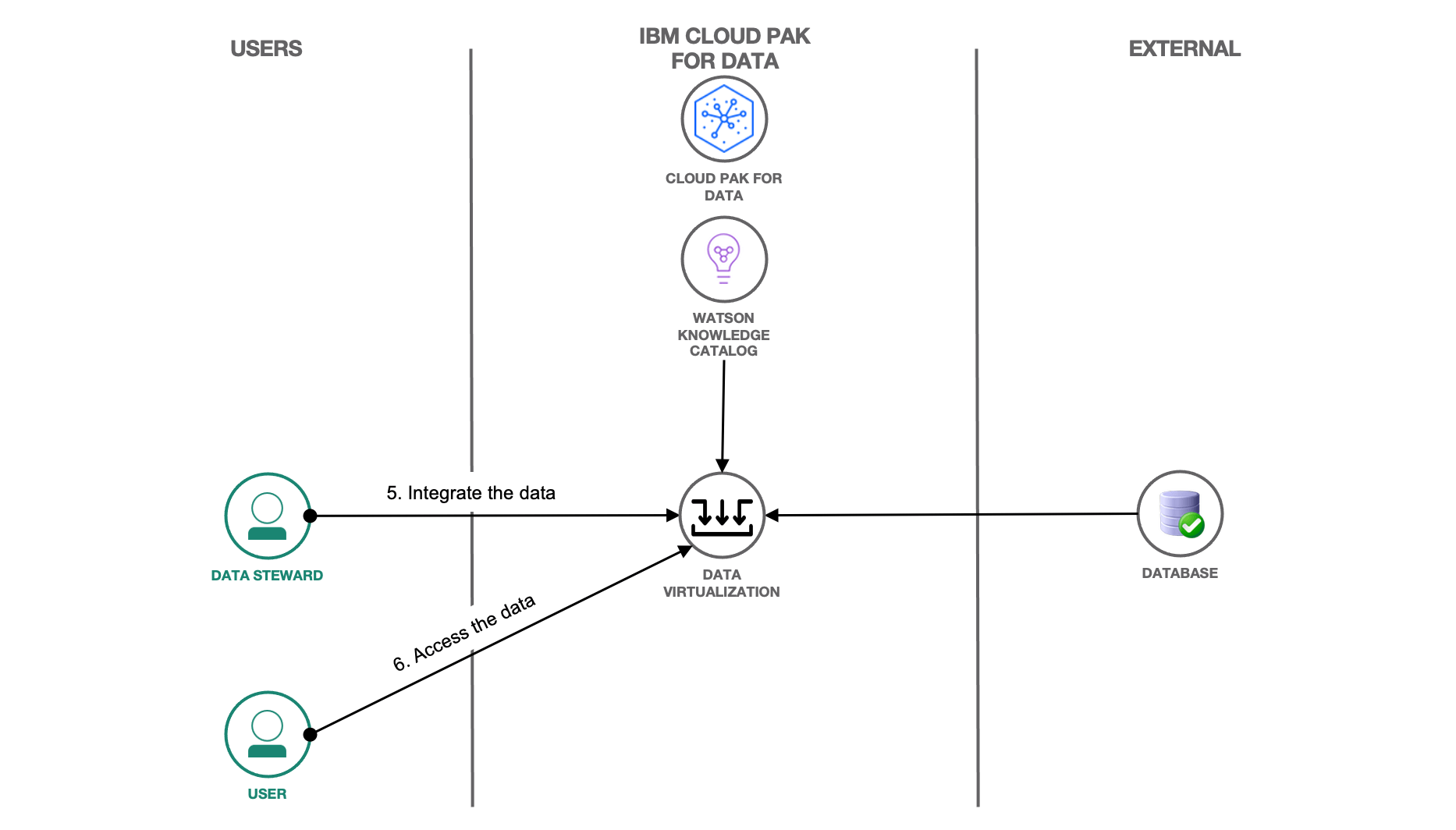
The data steward can virtualize the data and make it available for other users to use. The steps in Create a single customer view of your data with data virtualization tutorial can be followed to integrate the data while it resides in its original source location. This enables you to prepare the data by transforming, aggregating and cleansing it, without migrating it to a new target. The steps performed in the previous tutorials to incorporate governance and privacy features in the data assets will enable the virtualization of the data with business terms and ensure that the data privacy rules are followed even after virtualization.
Summary
DataOps is a framework that aims at resolving common data pain points in today's big data world where speed, quality, and reliability are key. It does this by speeding up the distribution of data for reporting and analytic output, while simultaneously reducing data defects and lowering costs.
The tutorials within the Create a strong data foundation for your AI learning path provides you with a practical understanding of the Organize step within the DataOps framework. Complete the learning path to learn how to use Watson Knowledge Catalog and Data Virtualization on IBM Cloud Pak for Data to govern, analyze, protect, and virtualize your data.