Article
Understanding DB2 Universal Database character conversion
Learn how to set up automated character conversions when a conversion configuration is requiredArchive date: 2023-02-06
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.In today's world, many database applications work with multiple database components on multiple platforms. A database application could be running on a Windows® system, but interact with a DB2 UDB for z/OS® database through a DB2 Connect™ server running on AIX®. The information that flows between these various servers may go through several character conversions, and in most cases these conversions are transparent to the user.
There are occasions, however, when some configuration is required. In such cases, it is useful to understand how these conversions work, and which component handles them. For instance, consider these situations:
- "I stored an exclamation mark ( ! ) in a column of one of my DB2 UDB for OS/390 tables from SPUFI. When I retrieve the same column from the DB2 UDB for Linux™, UNIX® and Windows command line processor (CLP), the exclamation mark gets converted to a square bracket ( ] )."
- "I have Spanish information in my DB2 UDB for Linux, UNIX, and Windows database. My Java™ application retrieves the Spanish data (accents), but they are all corrupted, even though I can see the contents are correct with the CLP."
These are some examples of the questions and issues that come from DB2 UDB customers. This article addresses all of these and similar issues by describing the DB2 UDB character conversion process.
The article focuses on the following products and versions: DB2 UDB for Linux, UNIX, and Windows Version 8.2, DB2 UDB for iSeries™ 5.3 and DB2 UDB for z/OS Version 8. The information may be applicable to prior versions of these products.
Terminology
In order to understand how the character conversion process works, you need to understand some key concepts. Figures 1, 2, and 3 provide an overview of some of these concepts.
Figure 1. Character conversion key concepts -- The ASCII encoding scheme
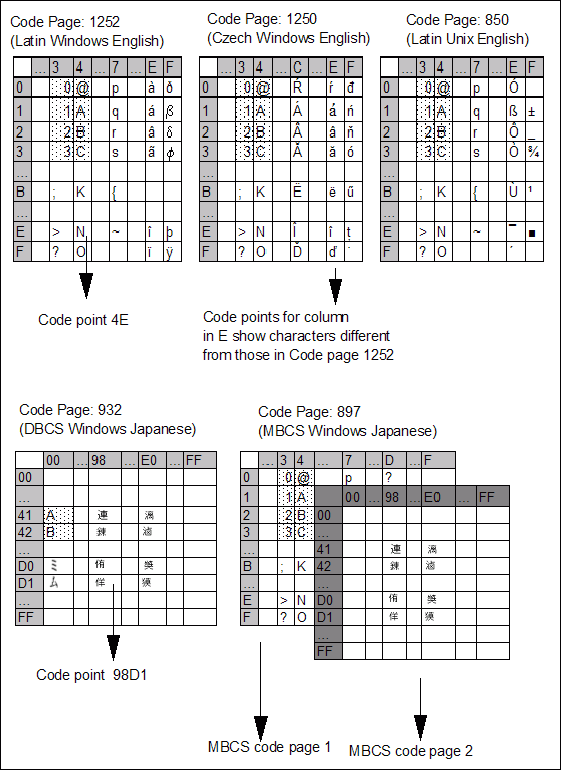
Figure 2. Character conversion key concepts -- The EBCDIC encoding scheme
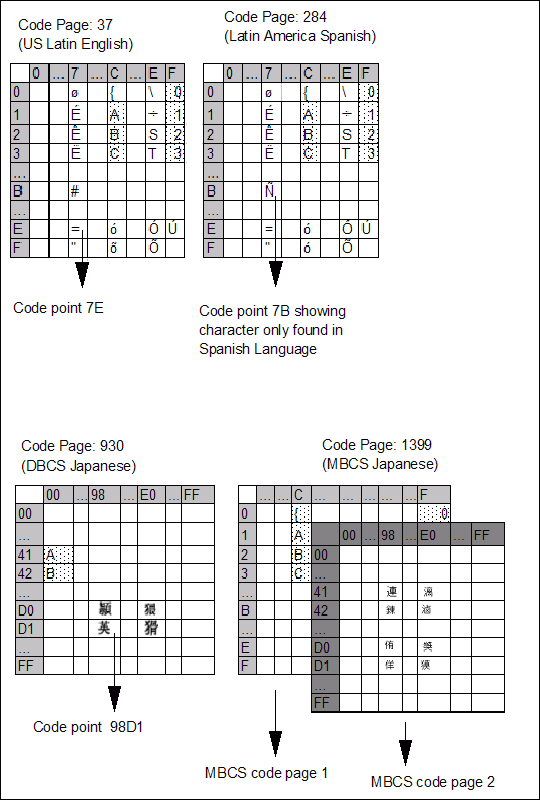
Figure 3. Character conversion key concepts -- The Unicode encoding scheme
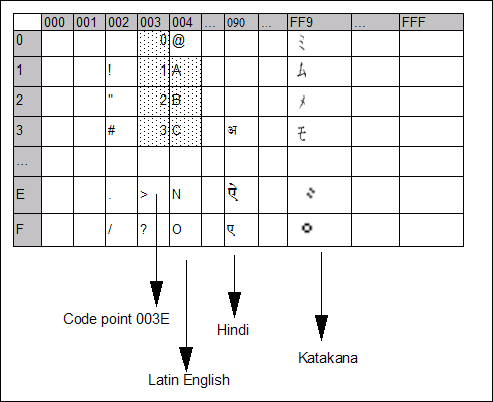
In the figures, the solid shaded borders in each code page indicate hexadecimal numbers.
A code page can be defined as a table with a mapping of alphanumeric code and its binary representation. Figure 1 shows several code pages for different languages and platforms. In the figure, for code page 1252, the letter 'K' can be represented as a binary '01001011' (or '4B' in hex notation). This same character may be represented with a different binary representation in another code page.
A code point is the location of a character within the code page. In Figure 1, the code point '4B' corresponds to character 'K' in code page 1252.
A character set is a defined set of characters. For example, a character set can consist of the uppercase letters A through Z, the lowercase letters a through z, and the digits 0 through 9. This character set can be repeated in several code pages. For example, in Figure 1 and Figure 2, the cells with dotted background in the different code pages represent the same character set.
Code pages can be classified as follows:
- A single-byte code page (sometimes referred to as a single-byte character set or SBCS) is a code page that can potentially hold 256 (28) code points in maximum. The actual number of code points in a SBCS might be less. For example, for territory identifier US, codeset ISO 8859-1, locale en_US on AIX is SBCS code page 819.
- A double-byte code page (sometimes referred to as a double-byte character set or DBCS) is a code page that can potentially hold 65536 (216) code points in maximum. The actual number of code points in a DBCS might be less. For example, for territory identifier JP, codeset IBM-932, locale Ja_JP on AIX is DBCS code page 932.
- A composite or mixed code page contains more than one code page. For example, an Extended UNIX Code (EUC) code page can contain up to four different code pages, where the first code page is always single-byte. For example, IBM-eucJP for Japanese (code page 954) refers to the encoding of the Japanese Industrial Standard characters according to the EUC encoding rules.
In the mainframe (z/OS, OS/390®) and iSeries (i5/OS™, OS/400®) world, the term Coded Character Set Identifier (CCSID) is used instead of code page. A CCSID is a 16-bit unsigned integer that uniquely identifies a particular code page. For example, the US-English code page is denoted by a CCSID of 37 on the mainframe. The German code page is CCSID 273. Some of these code pages include code points for specific characters in their language; some have the same characters but are represented by different code points in different CCSIDs. The CCSID is based on the Character Data Representation Architecture (CDRA), an IBM architecture that defines a set of identifiers, resources, services, and conventions to achieve a consistent representation, processing, and interchange of graphic character data in heterogeneous environments. OS/400 fully supports CDRA. OS/390 supports some of the elements of CDRA.
An encoding scheme is a collection of the code pages for various languages used on a particular computing platform. Common encoding schemes are:
- American Standard Code for Information Interchange (ASCII) ,which is used on Intel-based platforms (like Windows), and UNIX-based platforms, such as AIX. Figure 1 showed a simplified representation of the ASCII encoding scheme.
- Extended Binary Coded Decimal Information Code (EBCDIC), which is an encoding scheme designed by IBM. It is typically used on z/OS and iSeries. Figure 2 showed a simplified representation of the EBCDIC encoding scheme.
- Unicode character encoding standard is a fixed-length character that provides a unique code point for every character in the world regardless of the platform, program, or the language. It contains close to 100,000 characters and is growing. The Unicode standard has been adopted by such industry leaders as IBM, Microsoft, and many others. Unicode is required by modern standards such as XML, Java, LDAP, CORBA 3.0, and others, and is the official way to implement ISO/IEC 10646. Figure 3 shows a simplified representation of the Unicode encoding scheme.
The DB2 UDB character conversion process
From the previous discussion, it should be clear that the concept of "code page" is crucial to understanding character conversions. A code page can be defined at different levels:
- At the operating system where the application runs
- At the application level using specific statements depending on the programming language
- At the operating system where the database runs
- At the database level
Defining the code page at the operating system where the application runs
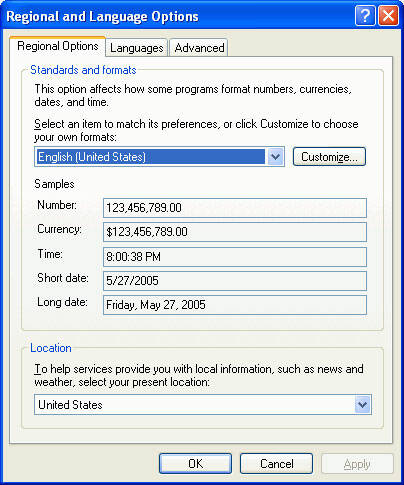
On Windows, the code page is derived from the ANSI code page setting in the Windows registry. You can review your settings from the Regional Settings control panel. Figure 4 shows the regional settings on a Windows XP machine.
Figure 4. Regional settings on a Windows XP machine
In a UNIX-based environment, the code page is derived from the locale setting. The command locale can be used to determine this value, as shown in Figure 5. The command localedef can compile a new locale file, and the LANG variable in /etc/environment can be updated with the new locale.
Figure 5. Regional settings on a UNIX machine using locale
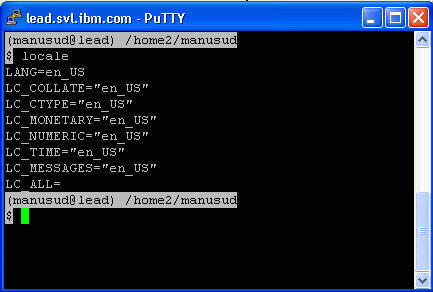
For the iSeries and z/OS, contact your system administrator.
Defining the code page at the application level
This article does not discuss application code page settings in detail, as the focus is mainly on the database side. However, it does mention some concepts that may be useful.
By default, an application code page is derived from the operating system where it is running. For embedded SQL programs, the application code page is determined at precompile/bind time and at execution time. At precompile and bind time, the code page derived at the database connection is used for precompiled statements, and any character data returned in the SQLCA. At execution time, the user application code page is established when a database connection is made, and it is in effect for the duration of the connection. All data, including dynamic SQL statements, user input data, user output data, and character fields in the SQLCA, is interpreted based on this code page. Therefore, if your program contains constant character strings, you should precompile, bind, compile, and execute the application using the same code page.
For a Unicode database, you should use host variables instead of using string constants. The reason for this recommendation is that data conversions by the server can occur in both the bind and the execution phases; this could be a concern if constant character strings are used within the program. These embedded strings are converted at bind time based on the code page which is in effect during the bind phase. Seven-bit ASCII characters are common to all the code pages supported by DB2 Universal Database and will not cause a problem. For non-ASCII characters, users should ensure that the same conversion tables are used by binding and executing with the same active code page.
For ODBC or CLI applications, you may be able to use different keywords in the odbc.ini file or the db2cli.ini file to adjust the application code page. For example, a Windows ODBC application can use the keyword TRANSLATEDLL to indicate the location of DB2TRANS.DLL, which contains codepage mapping tables, and the keyword TRANSLATEOPTION, which defines the codepage number of the database. The DISABLEUNICODE keyword can be used to explicitly enable or disable Unicode. By default, this keyword is not set, which means that the DB2 CLI application will connect using Unicode if the target database supports Unicode. If it doesn't, the DB2 CLI application will connect using the application code page. When you explicitly set DISABLEUNICODE=0, the DB2 CLI application will always connect in Unicode whether or not the target database supports Unicode. When DISABLEUNICODE=1, the DB2 CLI application always connects in the application code page, whether or not the target database supports Unicode.
Java applications using the Java Universal Type 4 driver don't need a DB2 UDB client installed at the client machine. The universal JDBC driver client sends data to the database server as Unicode, and the database server converts the data from Unicode to the supported code page. The character data that is sent from the database server to the client is converted using Java's built-in character converters, such as the sun.io.* conversion routines. The conversions that the DB2 Universal JDBC Driver supports are limited to those that are supported by the underlying Java Runtime Environment (JRE) implementation. For CLI and legacy JDBC drivers, code page conversion tables are used.
Application programs running on z/OS use the application encoding CCSID values specified on the DB2 UDB for z/OS installation panels. In addition, the application encoding bind option can also define the CCSID for the host variables in the program. For dynamic SQL applications, use the APPLICATION ENCODING special register to override the CCSID. It is also possible to specify the CCSID at an even more granular level by using the CCSID clause in the DECLARE VARIABLE statement. (For example: EXEC SQL DECLARE :TEST VARIABLE CCSID UNICODE;)
Defining the code page at the operating system where the database runs
The discussion in this section is exactly the same as explained above.
Defining the code page at the database level
The code page is defined differently depending on the DB2 UDB platform.
On DB2 UDB for Linux, UNIX, and Windows
A database can have only one code page, and it is set when you first create a database with the CREATE DATABASE command using the CODESET and TERRORITY clauses. For example, the following command creates the database "spaindb" with code set 1252 and territory ID 34 which determine the code pages for Spanish on the Windows platform.
CREATE DATABASE spaindb USING CODESET 1252 TERRITORY es
After the database is created, you can review the code page settings by issuing the command get db cfg for spaindb as shown in Figure 6.
Figure 6. Reviewing the code page of your DB2 UDB for Linux, UNIX, and Windows database
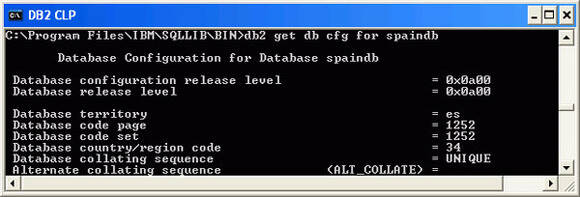
Table 1 provides descriptions of each of the fields shown in Figure 6.
Table 1. Code page database configuration parameters description
| Database territory | Determines the territory identifier for a country. |
| Database code page | Indicates the code page used to create the database. |
| Database country/region code | Indicates the territory code used to create the database. |
| Database collating sequence | Indicates the method to use to sort character data. |
| Alternate collating sequence | Specifies the collating sequence that is to be used for Unicode tables in a non-Unicode database. Until this parameter is set, Unicode tables and routines cannot be created in a non-Unicode database. |
Collating sequences are discussed in more detail in the section Other considerations. If you create the database using the default values, the code page that is used is taken from the operating system's information. Once a database is created with a given code page, you cannot change it unless you export the data, drop the database, recreate the database with the correct code page, and import the data.
On DB2 UDB for iSeries
On DB2 UDB for iSeries, a code page can be specified per physical file or table within a database. Therefore, an iSeries database can hold multiple code pages, even ASCII code pages, depending on the specific code page.
To specify the code page to use for a physical file or table, use either of these two approaches:
- Create a physical file and use the CCSID clause. For example, the following command creates a one-member file with CCSID 62251 using Data Description Source (DDS) and places it in a library called DSTPRODLB. This assumes the DDS source exists and has been correctly defined. Note that the CCSID value is only valid for source physical files FILETYPE(SRC). iSeries tables are stored in data physical files FILETYPE(DATA), so you must use DDS and specify the CCSID that way.
CRTPF FILE(DSTPRODLB/ORDHDRP) TEXT('Order header physical file') CCSID(62251) - Use the SQL
CREATE TABLESQL statement with the CCSID clause. For example, the following SQL statement creates the table DEPARTMENT with CCSID 37 specified for two columns:CREATE TABLE DEPARTMENT (DEPTNO CHAR(3) CCSID 37 NOT NULL, DEPTNAME VARCHAR(36) CCSID 37 NOT NULL, PRENDATE DATE DEFAULT NULL)
To review the current value of the code page, at the job level, you can issue the following from an OS/400 command line: DSPJOB OPTION(*DFNA)
If you scroll down to the third page, you will be able to see the code page settings, for example: Language identifier . . . . . . . . . . . . . . . : ENU Country or region identifier . . . . . . . . . . : CA Coded character set identifier . . . . . . . . . : 37 Default coded character set identifier . . . . . : 37
If the CCSID is not specified, the code page that is used is the one specified in any of these three layers:
- Distributed Data Management (DDM)
- Job (that is, at the OS level)
- User profile (that is, at the System level)
The client will send its code page in the DDM request (DDM Layer). At the OS400 level, the CCSID is determined following this priority:
- Use the CCSID in the field definition.
- If there is no CCISD in the field definition, the file-level CCSID is used.
- If there is no file-level CCSID specified, the CCSID of the current job is used.
The CCSID of the job is determined as follows:
- Check the user profile and get the CCSID from there.
- If the user profile does not specify a CCSID, the value is determined from the system value QCCSID.
On DB2 UDB for z/OS
On DB2 UDB for z/OS, the CCSID (code page) needs to be specified when you install the DB2 UDB for z/OS subsystem on panel DSNTIPF. This is shown in Listing 1.
Listing 1. Listing 1. Application programming defaults panel: DSNTIPF
DSNTIPF INSTALL DB2 ‑ APPLICATION PROGRAMMING DEFAULTS PANEL 1
===> _
Enter data below:
1 LANGUAGE DEFAULT ===> IBMCOB ASM,C,CPP,IBMCOB,FORTRAN,PLI
2 DECIMAL POINT IS ===> . . or ,
3 STRING DELIMITER ===> DEFAULT DEFAULT, " or ' (COBOL or COB2 only)
4 SQL STRING DELIMITER ===> DEFAULT DEFAULT, " or '
5 DIST SQL STR DELIMTR ===> ' ' or "
6 MIXED DATA ===> NO NO or YES for mixed DBCS data
7 EBCDIC CCSID ===> CCSID of SBCS or mixed data. 1‑65533.
8 ASCII CCSID ===> CCSID of SBCS or mixed data. 1‑65533.
9 UNICODE CCSID ===> 1208 CCSID of UNICODE UTF‑8 data.
10 DEF ENCODING SCHEME ===> EBCDIC EBCDIC, ASCII, or UNICODE
11 APPLICATION ENCODING ===> EBCDIC EBCDIC, ASCII, UNICODE, cssid (1‑65533)
12 LOCALE LC_CTYPE ===>
PRESS: ENTER to continue RETURN to exit HELP for more informationTable 2 provides descriptions of each of the relevant fields shown in Listing 1.
Table 2. Code page parameters descriptions
| MIXED DATA | Indicates whether the EBCDIC CCSID and ASCII CCSID fields contain mixed data or not. |
| EBCDIC CCSID | Indicates the default CCSID for EBCDIC encoded data. |
| ASCII CCSID | Indicates the default CCSID for ASCII-encoded character data. |
| UNICODE CCSID | Indicates the default CCSID for Unicode. DB2 UDB for z/OS currently only supports CCSID 1208 for Unicode. |
| DEF ENCODING SCHEME | Indicates the default format in which to store data in DB2. |
| APPLICATION ENCODING | Indicates the system default application encoding scheme that affects how DB2 UDB for z/OS interprets data coming into DB2. |
| LOCALE LC_CTYPE | Specifies the system LOCALE_LC_CTYPE. A locale is the part of your system environment that depends on language and cultural conventions. An LC_TYPE is a subset of a locale that applies to character functions. For example, specify En_US for English in the United States or Fr_CA for French in Canada. |
If the language only uses a single-byte CCSID, the mixed and double-byte CCSIDs in the CCSID set default to the reserved CCSID 65534. Due to the complexity and high number of the characters of some languages such as Chinese and Japanese, these character sets use double-byte and mixed character sets. All the single-byte and mixed CCSIDs are stored in the macro called DSNHDECP in the DB2 UDB for z/OS subsystem parameter job. In addition, the DB2 UDB for z/OS catalog table SYSIBM.SYSSTRINGS has to point to a conversion table for all required code page conversions.
DB2 UDB for z/OS uses the ASCII CCSID value to perform conversion of character data that is received from ASCII external sources, including other databases. You must specify a value for the ASCII CCSID field, even if you do not have or plan to create ASCII-encoded objects.
To store data in ASCII format in a table, you can use the CREATE statement with the CCSID ASCII clause at the table, table space, or database level. For example, at the table level use the CREATE TABLE statement as follows: CREATE TABLE T1 (C1 int CCSID ASCII, C2 char(10) CCSID ASCII)
The CCSID ASCII value from the above CREATE TABLE statement is taken from panel DSNTIPF.
The following statements use the default encoding scheme specified in panel DSNTIPF:
- CREATE DATABASE
- CREATE DISTINCT TYPE
- CREATE FUNCTION
- CREATE GLOBAL TEMPORARY TABLE
- DECLARE GLOBAL TEMPORARY TABLE
- CREATE TABLESPACE (in DSNDB04 database)
If the CCSID values of the DSNTIPF panel fields are not correct, character conversion produces incorrect results. The correct CCSID identifies the coded character set that is supported by your site's I/O devices, local applications such as IMS and QMF, and remote applications such as CICS Transaction Server.
Never change the CCSIDs of an existing DB2 UDB for z/OS system without specific guidance from IBM DB2 UDB Technical Support; otherwise you may corrupt your data!
Character conversion scenarios
The previous sections showed how the code page value can be determined and changed for an application or database in different platforms. This section describes the character conversion process using two generic scenarios. (It assumes the code page value for the application and the database have already been established). The fundamental rule of the conversion process is that the receiving system will always perform the code page conversion.
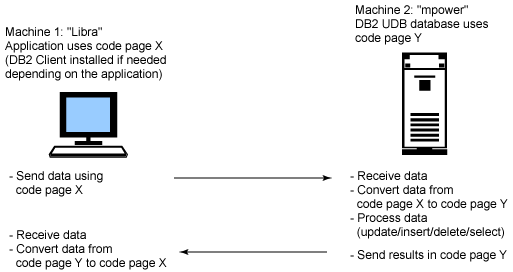
Scenario 1: Client to DB2 UDB server conversion
This generic scenario shown in Figure 7 represents such cases as:
- Application running on Linux, UNIX, or Windows client to DB2 UDB for Linux, UNIX, and Windows Server
- Application running on iSeries client to DB2 UDB for Linux, UNIX, and Windows server
- Application running on iSeries client to DB2 UDB for iSeries server
- Application running on iSeries client to DB2 UDB for z/OS server
- Application running on z/OS client to DB2 UDB for Linux, UNIX, and Windows server
- Application running on z/OS client to DB2 UDB for iSeries server
Application running on z/OS client to DB2 UDB for z/OS server
Figure 7. Client to DB2 UDB server conversion
Scenario 2: Client to DB2 Connect Gateway to DB2 UDB server conversion
This generic scenario, shown in Figure 8, represents such cases as:
- Application running on Linux, UNIX, or Windows client to DB2 UDB for iSeries
Application running on Linux, UNIX, or Windows client to DB2 UDB for z/OS
Figure 8. Client to DB2 Connect Gateway to DB2 UDB server conversion
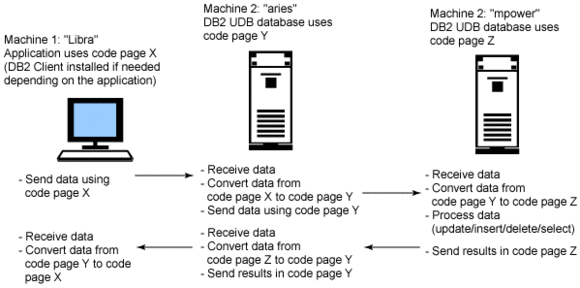
In Figures 7 and 8, when the operating system where the application runs is Linux, UNIX, or Windows, a DB2 UDB for Linux, UNIX, and Windows client may need to be installed. If the application is written in Java using the JDBC Type 4 driver, a DB2 UDB for Linux, UNIX, and Windows client is not required.
In both generic scenarios, no code page conversion will happen if the code pages are the same for all the systems. This is unlikely to happen when you are dealing with Linux, UNIX, or Windows applications (which use ASCII encoding scheme) that access DB2 UDB for iSeries or z/OS data (which use EBCDIC encoding scheme), unless Unicode is used for all of these systems.
Character conversion example
The following example illustrates the character conversion process. Let's say you have the following configuration:
- An ODBC application is running on a Windows machine, and by default the application is using the operating system's code page, which for this example is 1252 (Windows, English).
- The AIX server where DB2 Connect runs is set to use Unicode.
- The iSeries server uses code page 66535 and has a database with table DEPARTMENT defined as:
CREATE TABLE DEPARTMENT (DEPTNO CHAR(3) NOT NULL, DEPTNAME VARCHAR(36) CCSID 37 NOT NULL, PRENDATE DATE DEFAULT NULL)
The column DEPTNO and PRENDATE will use the iSeries code page of 66535 as the default.
When the Windows application sends a request such as: SELECT DEPTNO FROM DEPARTMENT
The following conversion occurs:
- The Windows application sends a request to the DB2 Connect server with code page 1252.
- The DB2 Connect server converts it to code page 1208 (Unicode), then it sends it to the iSeries Server.
- The iSeries server converts it to the CCSID 66535 and accesses the data in the DEPARTMENT table.
- Since the data obtained from the table is in CCSID 66535, it will be sent to the requester (in this case the DB2 Connect server) in that code page.
- The DB2 Connect server converts the data to code page 1208, then it sends it to the Windows application.
- The Windows operating system converts code page 1208 back to 1252.
Other considerations
Enforced subset conversion
During code page conversion, a character in the source code page X might not exist in the target code page Y. For example, let's say a multinational company stores information in both Japanese and German languages. A corresponding Japanese application inserts data into this DB2 UDB database which has been created using the German code page. In such cases, many characters will not have a code point in the CCSID used by DB2. In such cases, one way to get past this problem is to convert the character by mapping only those characters from the source CCSID to those that have a corresponding character in the target CCSID. Those characters that do not map will be substituted by a reserved code point. (Every code page has reserved at least one code point for substitution.) Those characters that cannot be mapped to the target code page are lost forever. This approach is called enforced subset conversion.
Roundtrip conversion
Another conversion approach is called the round-trip conversion. A round-trip conversion between two CCSIDs ensures that all characters making the "round trip" arrive as they were originally, even if the receiving CCSID does not support a given character. Round-trip conversions ensure that code points that are converted from CCSID X to CCSID Y, and back to CCSID X are preserved, even if CCSID Y is not capable of representing these code points. This is implemented by using conversion tables.
Using other DB2 UDB for Linux, UNIX, and Windows conversion code page tables
When you want to use a different version of the conversion tables, such as the Microsoft version, you must manually replace the default conversion table (.cnv) files, which reside in the .../sqllib/conv directory in the UNIX and Linux platforms or ...\sqllib\conv on Windows. These tables are the external code page conversion tables used to translate values between various code pages. Before replacing the existing code page conversion table files in the sqllib/conv directory, you should back up the files.
DB2 UDB Unicode support
On all platforms, DB2 UDB supports the International Standards Organization (ISO)/International Electrotechnical Commission (IEC) standard 10646 (ISO/IEC standard 10646) Universal 2-Octect Coded Character Set (UCS-2). UCS-2 is implemented with Unicode Transformation Format, 8 bit encoding form (UTF-8). UTF-8 is designed for ease of use with existing ASCII-based systems. The code page/CCSID value for data in UTF-8 format is 1208. The CCSID value for UCS-2 is 1200. UTF-8 was chosen as the default format for character data columns, with UTF-16 for graphic data columns.
A DB2 UDB for Linux, UNIX, and Windows database created using default values will create tables in ASCII. To create a Unicode database, use the CREATE DATABASE with the CODESET and TERRITORY clauses as follows: CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
The tables in this Unicode database will default to code page 1208. You cannot define a table with an ASCII code page in a Unicode database. The opposite however, is possible; that is you can create a Unicode table in a non-Unicode database. This can be performed by invoking the CREATE TABLE statement using the CCSID UNICODE clause. For example: CREATE TABLE unitbl (col1 char(10), col3 int) CSSID UNICODE
For this to work, you first need to activate the database configuration parameter, alt_collate. Once set, this parameter cannot be changed or reset. UPDATE DB CFG FOR nonunidb USING ALT_COLLATE IDENTITY_16BIT
In DB2 UDB for iSeries, the CCSID clause can be used on individual columns. For example, the following SQL statement creates the table U_TABLE. U_TABLE contains one character column called EMPNO, and two Unicode graphic columns. NAME is a fixed-length Unicode graphic column and DESCRIPTION is a variable-length Unicode graphic column. The EMPNO field only contains numerics and Unicode support is not needed. The NAME and DESCRIPTION fields are both Unicode fields. Both of these fields may contain data from more than one EBCDIC code page.
CREATE TABLE U_TABLE (EMPNO CHAR(6) NOT NULL,
NAME GRAPHIC(30) CCSID 1200,
DESCRIPTION VARGRAPHIC(500) CCSID 1200)Similar to DB2 UDB for Linux, UNIX, and Windows, in DB2 UDB for z/OS you can store and retrieve Unicode data if you have used the CCSID UNICODE clause on the object definitions, such as the following:
CREATE TABLE DBTBDWR.WBMTEBCD
(CUSTNO CHAR(8),
CUSTBU CHAR(6),
CUSTEXT CHAR(3),
CNAME VARCHAR(80) FOR MIXED DATA)
IN TEST.CUSTTS
CCSID UNICODEDB2 UDB for z/OS performs character conversions using LE's (Language Environment's) ICONV, unless z/OS Unicode Conversion Services have been installed. To learn how to set up z/OS Unicode Conversion Services for DB2, review informational APARs II13048 and II13049. To review the conversions that have been installed, use the command /d uni, all from the console as shown in Figure 9.
Figure 9. Reviewing installed character conversions on z/OS
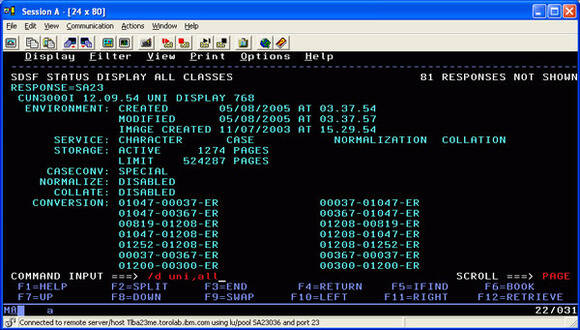
For example, Figure 9 shows that there is a conversion from 1252 to 1208, and from 1208 to 1252 (that is, from Windows English to Unicode and vice versa).
Using the Unicode encoding scheme between all systems avoids character conversion and improves performance.
Collating sequence
A collating sequence is an ordering for a set of characters that determines whether each character sorts higher, lower, or the same as another. The collating sequence maps the code point to the desired position of each character in a sorted sequence. For example, the collating sequence in ASCII is: space, numeric values, upper case characters, lower case characters. On the other hand, the collating sequence in EBCDIC is: space, lower case characters, upper case characters, and numeric values.
An application designed to work against an ASCII database may run into problems if used against an EBCDIC database, because of the difference in the collating sequence. You are allowed to create custom collating sequences. For more details, refer to the Application Development Guide: Programming Client Applications manual (see Related topics).
Special considerations for federated systems
Federated systems do not support certain data mappings. For example, DB2 UDB federated servers do not support mappings for the data type of LONG VARCHAR. As a result, the scenarios discussed may not work. Please review the Federated Systems Guide (see Related topics) for more details.
Moving data with different code pages
You cannot backup a database with a given code page, and restore it into another with a different code page. On DB2 UDB for Linux, UNIX, and Windows, you should use the export or db2move utility, create the new database with the new desired code page, and import or db2move the data back. When you use this method, DB2 UDB will perform the character conversion correctly.
Dealing with binary data
Columns defined with the BLOB data type, or using the FOR BIT DATA clause will be passed as binary from the source to the target, and the code page used is zero. This indicates that no code page conversion is to happen.
Character conversion problem determination and problem source identification
When you encounter problems with character conversions, first identify which code pages are being used by the application and the DB2 UDB database server involved.
Identifying code pages in the DB2 UDB environments
In addition to the methods discussed in previous sections for determining the code page value for the operating system or the DB2 UDB database server, the following methods will show you the code page at both the target and the source. The discussion in this section is geared towards DB2 UDB for Linux, UNIX, and Windows.
Using the CLP with the "-a" option to display the SQLCA information
When you use the "-a" option of the CLP to display the SQLCA information, the code pages of the source application (in this case the CLP), and the target database are shown. Figure 10 shows an example of connecting from the CLP on Windows to a database also on Windows.
Figure 10. Displaying the SQLCA information to review code page values
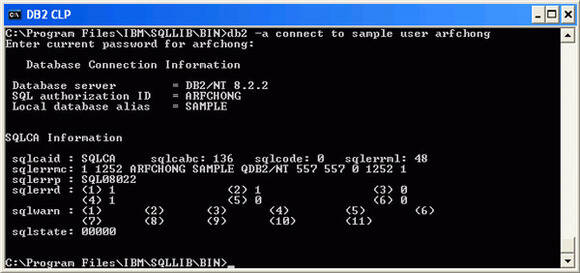
In Figure 10, note the line that reads: sqlerrmc: 1 1252 ARFCHONG SAMPLE QDB2/NT 557 557 0 1252 1
The first instance of "1252" indicates the code page used at the target, which is Windows US-English. The second instance indicates the code page used at the source, which is also Windows US-English.
Figure 11 shows another example, this time connecting from a Windows CLP (where DB2 Connect is installed) to a DB2 UDB for z/OS target database.
Figure 11. Displaying the SQLCA information to review code page values -- another example
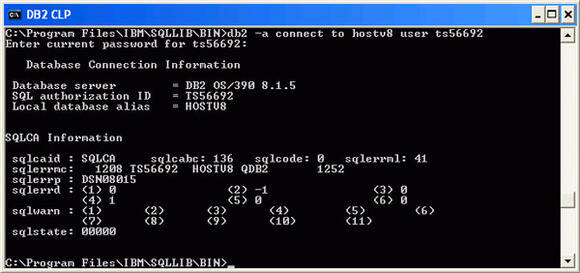
In Figure 11, note the line that reads: sqlerrmc: 1208 TS56692 HOSTV8 QDB2 1252
The 1208 indicates that the target DB2 UDB for z/OS subsystem is using Unicode.
The 1252 indicates that the source CLP application is using Windows US-English.
Using a CLI trace for CLI, ODBC or JDBC Type 2 applications
To identify the code page for a CLI and JDBC type 2 application, you can use the trace facilities offered by DB2 CLI on Linux, UNIX, and Windows. By default, this trace facility is disabled and uses no additional computing resources. When enabled, text log files are generated whenever an application accesses the CLI driver. You can turn on the CLI trace by adding the following DB2 CLI keywords in the db2cli.ini file as follows:
[COMMON]
trace=1
TraceFileName=\temp\clitrace.txt
TraceFlush=1where \temp\clitrace.txt is an arbitrary name used for the directory and trace file where the traces will be stored.
You can find the application and database code pages from the SQLConnect() or SQLDriverConnectW() calls in the trace output file. For example, the application and the database server are using the same code page (1252) in the following messages:
(Application Codepage=1252, Database Codepage=
1252, Char Send/Recv Codepage=1252, Graphic
Send/Recv Codepage=1200, Application Char
Codepage=1252, Application Graphic Codepage=1200Verifying that the conversion tables or definitions are available
In most cases, the conversion tables or definitions between the source and the target code page have not been defined. The conversion tables in DB2 UDB for Linux, UNIX, and Windows are stored under the sqllib/conv directory, and normally they handle most conversion scenarios.
On iSeries, the IBM-supplied tables can be found in the QUSRSYS library. You can also create your own conversion tables using the Create Table (CRTTBL) command. The Globalization topic in the iSeries Information Center includes a list of the convserion tables. (See Related topics.)
You can also run the following query to see a list of character set names: SELECT character_set_name from sysibm.syscharsets
On DB2 UDB for z/OS, as shown in Figure 9, you may need to issue the /d uni, all command to display the conversions that have been installed. If the output of this command does not list a conversion you need, say from 1252 to 1208, you should add a conversion entry to the Unicode Conversion Services (the sample JCL hlq.SCUNJCL(CUNJIUTL)), such as: CONVERSION 1252,1208,ER
You should also verify in the DB2 UDB for z/OS catalog table SYSIBM.SYSTRINGS that an entry for the given conversion is present. For example, to view the list of entries in this table, issue this query: SELECT inccsid, outccsid FROM sysibm.sysstrings
If these do not lead you to a solution, contact DB2 UDB Technical Support. You may be asked to collect a DB2 trace and to format it with the fmt -c option (formerly known as the DDCS trace). This trace will show what is being passed and received between the source and the target.
Summary
This article provided you with an overview of the character conversion process that occurs within and between DB2 UDB databases. It first explained key concepts such as code pages, code points, and encoding schemes, and indicated how to review their current value, and how to update the value. Next it provided generic scenarios to show the character conversion process. It explained some special considerations during conversions, and provided a two-step method to determine the cause of conversion problems.
Ideally, you should try to avoid character conversions to improve performance by using the same code pages between the source and the target of the conversion. But if your database scenario is complex and you cannot avoid character conversion, this knowledge will help you make the process as smooth as possible.