Article
Building out the edge in the application layer and device layer
Deploying key application components to the edgeThe first article in this edge computing series described a high-level edge computing architecture that identified the key layers of the edge including the device layer, application layer, network layer, and the cloud edge layer. In this article, we dive deeper into the application and device layers, and describe the tools you need to implement these layers.
As mentioned in the first article, the cloud edge is the source for workloads for the different edge layers, provides the management layer across the different edge layers, and hosts the applications that need to handle the processing that is just not possible at the other edge nodes due to limitations at these nodes.
The device layer consists of small devices running on the edge. The application layer runs on the local edge and has greater compute power than the device layer. Let’s dive into the details of each of these two layers and the respective components in the layers.
Edge computing use case: Workplace safety on a factory floor
In this article, we will describe how we implemented a workplace safety use case involving the application and device layer of the edge computing architecture.
In a particular factory, when employees enter a designated area, they must be wearing a proper Personal Protective Equipment (PPE) such as a hard hat. A solution is needed to monitor the designated area and issue an alert only when an employee has been detected, entering the area without wearing a hard-hat. Otherwise, no alert is issued. To reduce load on the network, the video starts streaming when a person is detected.
To implement the architecture, the following needs to happen:
Deep learning models need to be trained to identify a person wearing a hard hat. This is accomplished using IBM’s Maximo Visual Inspection (MVI).
The models need to be containerized and deployed to the edge cluster. This is accomplished using IBM Edge Application Manager (IEAM).
A Model needs to be deployed to the smart camera to identify a human which will trigger the video stream. This deployment of model to the smart camera is done using IEAM.
The model that is deployed on the edge device can be updated without updating the application or edge service that is deployed to the edge device using the Model Management System (MMS) of IEAM.
Here's an architecture diagram showing these components:
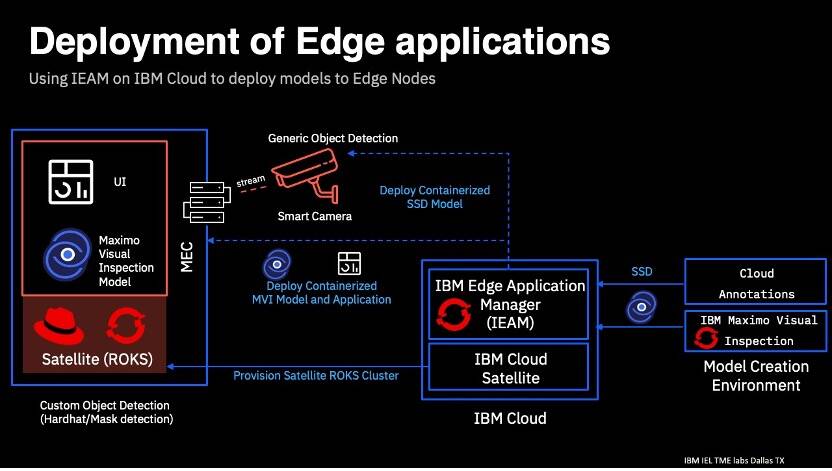
Implementing the application layer
The application layer enables you to run applications on the edge. The complexity of the applications that can be run depends on the footprint of the edge server. The edge server, also known as Multi-Access Edge Compute (MEC) server, can be an X86 server or an IBM Power System server that is often run-on premise in an environment such as a retail store, cellular tower, or other location outside of the core network or data center of the enterprise. The sizing of the servers is dependent on the workload that will be run.
Information from the device layer is sent to the application layer for further processing. Some of this information can then be sent to the cloud or other location.
The application layer is likely built on a containers-based infrastructure where common software services and middleware can run. For example, the application layer could be built on Red Hat OpenShift and have one or more IBM Cloud Paks installed on it where deployed containers run.
We will now look at how products such as IBM Maximo Visual Inspection and IBM Edge Application Manager that can be used to create a full end to end solution.
Creating a model using IBM Maximo Visual Inspection
IBM Maximo Visual Inspection is a video and image analysis platform that makes it easy for subject matter experts to train and deploy image classification and object detection models. We will see how to build a hardhat detection model using Maximo Visual Inspection.
- Create a set of videos with individuals wearing hardhat. Make sure to include varied scenarios with different lighting conditions.
- Log on to Maximo Visual Inspection, and click on Data Sets in the top left corner to create a dataset.
- Click on Create a new data set and provide a name like
hardhat datasetfor the data set. - Import the images or videos that you created in step 1.
- To create an object detection model, click Objects in the menu on the left, and click Add Objects to create objects. Create an object called
hardhat. If you have different colored hats that you want to recognize, you can create an object for each likeYellow HardhatandBlue Hardhat. Click the Label Objects button. For videos in your data set, you can use the Auto Capture button to capture frames at desired time intervals. For each frame, click Box, and choose the hardhat object that you just created, and draw a box around the hardhat. Repeat this step for all frames.

In general, the larger the data set, the better the accuracy of the model will be. If you do not have a lot of data, you can use the Augment Data button to create additional images using filters such as flip, blur, rotate, and so on.
- Once you are done labeling the images, click Train Model, and select the type of training as Object detection. You can choose from a number of options to optimize your model training and click the Train button. The training time depends on the size of data, type of model, and additional options selected.
- Once the model is trained, click the Deploy button. You can name your deployed model and choose to export it. Then, download the exported model as a zip file.
- The deployed hardhat model now appears in the Deployed Models tab where you can test the model either using the API endpoint displayed or by clicking the Open button and uploading a video to test if the hardhats are being detected.
Containerizing the model using the Maximo Visual Inspection Edge server
IBM Maximo Visual Inspection edge server is a server that lets you quickly and easily deploy multiple trained models. We will use the edge server to create a Docker image of the hardhat model. This allows you to make the hardhat model available to others, such as customers or collaborators, and also give them the ability to run the model on other systems.
To install the inference server on a machine, download the latest Maximo Visual Inspection Inference software. Navigate to IVI inference folder to install inference server. See the installation documentation for detailed instructions.
sudo docker run --rm -v /apps/vision-edge:/opt/ibm/vision-edge -e hostname=$(hostname -f) --privileged -u root cp.icr.io/cp/visualinspection/vision-edge-inception:8.5.0Start the application by running the following command:
sudo apps/vision-edge/startedge.shUse the
deploy_zip_model.shscript to deploy a model exported from Maximo Visual Inspection on this system./opt/ibm/vision-inference/bin/deploy_zip_model.sh --model model_name --port port_number --gpu GPU_number location_of_exported_IVI_modelFor example:
/opt/ibm/vision-inference/bin/deploy_zip_model.sh--model Hardhatmodel --port 6002 --gpu 0 /root/Hardhatmodel.zipThis command creates a Docker container.
Using the Docker container, create a Docker image. To do so, first obtain the container’s ID and then commit the Docker image:
docker ps | grep model_nameCopy the container ID from the output, and specify it on this command:
docker commit <container-id> docker_image_name:tagFor example, for our
hardhatmodel, the Docker commit command might look like this:docker commit <container-id> hardhatmodel:v1Save the Docker image you created in the above step and zip it to create a
.tgzfile using the following command:docker save docker_image_name:tag | gzip > file_name.tgzFor example:
docker save hardhatmodel:v1 | gzip > Hardhatmodel.tgzYou can now move this .tgz file to the MEC cluster and run a
docker loadcommand to load the Docker image onto that edge cluster.docker load < hardhatmodel.tgz
Implementing the edge clusters
The edge cluster capability of IBM Edge Application Manager (IEAM) helps you manage and deploy workloads from a management hub cluster to remote instances of Red Hat OpenShift Container Platform or other Kubernetes-based clusters. Edge clusters are IEAM edge nodes that are Kubernetes clusters. IEAM deploys edge services to an edge cluster, via a Kubernetes operator, enabling the same autonomous deployment mechanisms used with edge devices.
The hardhat model that you created in the previous section will be deployed to the edge cluster using IEAM. This model requires a GPU for optimal performance. The below instructions provide the steps to install a GPU operator that enables us to use a GPU on an edge cluster.
Set up a GPU operator
To set up GPU support within a Red Hat OpenShift cluster, it is best to install and use the GPU Operator. The MVI models will run only on a few supported GPUs, such as Tesla T4, Tesla P100, and Tesla V100.
You need to complete the following steps before you follow the steps in the NVIDIA documentation.
Review the platforms supported and install the appropriate Red Hat OpenShift version that matches the environment setup.
Follow these steps to install the NVIDIA GPU Operator. First, install the Node Feature Discovery (NFD) operator. Then, install the NVIDIA GPU operator.
Optionally, you might have to enable the cluster-wide entitlement on the OpenShift cluster. Use this NVIDIA doc to set up the entitlement on the cluster. This troubleshooting page will provide solutions to the common issues faced while installing GPU Operator.
Register the edge node
Once the GPU operator is installed, the next step is to install and register this edge cluster and an edge device (Mac/TX2) to the IEAM Hub. Registering the edge nodes enables us to deploy workloads like the above hardhat model as edge services on the edge cluster. Use the IEAM documentation to install the edge agent on edge nodes and register it with IEAM hub.
Use a helm chart and helm operator service to deploy a service on the edge cluster
Once you register the OpenShift cluster, you can now create services that can be deployed on the edge cluster. In this scenario, we will use a helm chart and helm operator service for our hardhat MVI model to deploy it on the OpenShift cluster. Using the Docker image that we created earlier for MVI model, we will create a helm chart that can be used to create a helm operator service.
Create a helm chart
Verify helm is installed with:
helm versionFor example: `Client: &version.Version{SemVer:"v2.12.3", GitCommit:"eecf22f77df5f65c823aacd2dbd30ae6c65f186e", GitTreeState:"clean"}``
Create Helm Chart Repository:
helm create mvi-edge-model (mvi-edge-model should be small case letters)Update Chart.yaml if needed:
vi mvi-edge-model/Chart.yamlUpdate the
values.yamlto include your deployment image, tag and ports for your service.vi mvi-edge-model/values.yamlEnsure that the repository, tag and service ports match your application's docker image properties.
For example:
mvi-edge-model: enabled: yes service: type: clusterIP inferencePort: 5001 image: registry: <OCP-private-registry> repository: default/hardhatx86aug9 tag: v1 pullPolicy: IfNotPresentModify the
deployment.yamland checkservice.yamlfiles in the templates folder according to your application as needed. Ensure that the port number indeployment.yamlmatches the above port number ofvalues.yaml.Test if the helm chart is valid:
helm template mvi-edge-modelIf the chart is valid without any errors, this command will show you the deployment and service yaml files. It will return errors if there is an error in the helm chart.
Create and publish a helm operator service
Use the following steps to create a helm operator servicce on top of the helm chart you just created. These instructions assume that operator-sdk is installed on a Mac or a device. You can download and install version 0.17.0 of the operator-sdk from the operator framework github.
Create a helm operator with the
operator-sdkusing the helm chart created above:operator-sdk new mvi-edge-operator --type=helm --api-version=mvi-edge.com/v1 --kind=Service --helm-chart=~/mvi-edge-modelYou should see similar results to:
INFO[0000] Creating new Helm operator 'mvi-edge-operator'. INFO[0000] Created helm-charts/mvi-edge-model INFO[0000] Generating RBAC rules WARN[0000] Using default RBAC rules: failed to generate RBAC rules: failed to get server resources: Get https://kubernetes.docker.internal:6443/api?timeout=32s: EOF INFO[0000] Created build/Dockerfile INFO[0000] Created watches.yaml INFO[0000] Created deploy/service_account.yaml INFO[0000] Created deploy/role.yaml INFO[0000] Created deploy/role_binding.yaml INFO[0000] Created deploy/operator.yaml INFO[0000] Created deploy/crds/edge-detector.com_v1_service_cr.yaml INFO[0000] Generated CustomResourceDefinition manifests. INFO[0000] Project creation complete.Next, create the operator with:
cd mvi-edge-operator operator-sdk build docker.io/ibmgsc/mvi-edge-operator_amd64:1.0.0Your
$DOCKER_IMAGE_BASE(which isibmgscin this case) will be different.You should see results similar to these results:
INFO[0000] Building OCI image docker.io/ibmgsc/mvi-edge-operator_amd64:1.0.0 Sending build context to Docker daemon 31.23kB Step 1/3 : FROM quay.io/operator-framework/helm-operator:v0.17.0 ---> ce3d68592219 Step 2/3 : COPY watches.yaml ${HOME}/watches.yaml ---> 6de4f6f579f4 Step 3/3 : COPY helm-charts/ ${HOME}/helm-charts/ ---> 2cbad6fbf986 Successfully built 2cbad6fbf986 Successfully tagged ibmgsc/mvi-edge-operator_amd64:1.0.0 INFO[0002] Operator build complete.Publish the image to the repository with:
docker push docker.io/ibmgsc/mvi-edge-operator_amd64:1.0.0Again, your
$DOCKER_IMAGE_BASE(which isibmgscin this case) will be different.Update your image name in
operator.yamlwith the above Docker image. Edit theREPLACE_IMAGE_NAMEwithdocker.io/ibmgsc/mvi-edge-operator_amd64:1.0.0from above.vi deploy/operator.yaml# Replace this with the built image nameimage: docker.io/ibmgsc/mvi-edge-operator_amd64:1.0.0(Optional) To Create and test if the files are working on the cluster where you want to deploy this model:
kubectl create -f deploy/service_account.yaml -n openhorizon-agent kubectl create -f deploy/role.yaml -n openhorizon-agent kubectl create -f deploy/role_binding.yaml -n openhorizon-agent kubectl create -f deploy/operator.yaml -n openhorizon-agent kubectl create -f deploy/crds/mvi-edge.com_appservices_crd.yaml -n openhorizon-agent kubectl create -f deploy/crds/mvi-edge.com_v1_appservice_cr.yaml -n openhorizon-agent And then kubectl delete commands should also be executed kubectl delete -f deploy/crds/mvi-edge.com_v1_service_cr.yaml kubectl delete -f deploy/crds/mvi-edge.com_services_crd.yaml kubectl delete -f deploy/operator.yaml -n openhorizon-agent kubectl delete -f deploy/role_binding.yaml -n openhorizon-agent kubectl delete -f deploy/role.yaml -n openhorizon-agent kubectl delete -f deploy/service_account.yaml -n openhorizon-agentIf the
kubectl delete -f deploy/crds/mvi-edge.com_services_crd.yamlcommand hangs, press Command+C or Ctrl+C and run the below command to patch and delete the respective crd:oc patch crd/services.mvi-edge.com -p ‘{“metadata”:{“finalizers”:[]}}’ --type=mergeCreate a tar file for operator files:
cd deploy/ tar -zvcf mvi-edge-operator.tar.gz .Make sure that you complete the steps to register your Mac as an edge device to the IEAM hub before proceeding to publishing the edge cluster service. Refer to the IEAM documentation for more details on installing and registering the horizon edge agent on a Mac (edge device).
Create a horizon service:
hzn dev service new -V 1.0.0 -s mvi-edge -c clusterUpdate service definition file. Edit
OperatorYamlArchiveand add the path for theoperator.tar.gzfile from the above step.vi horizon/service.definition.json "clusterDeployment": { "operatorYamlArchive": "~/edge-cluster-example/mvi-edge-operator/deploy/mvi-edge-operator.tar.gz" }Set environment variables. These commands will set up the necessary environment variables to be able to publish this service to IEAM.
eval $(hzn util configconv -f horizon/hzn.json) export ARCH=$(hzn architecture) echo $ARCHPublish the service to IEAM. This command will push the MVI Edge service compatible for clusters to IEAM. Using which patterns or policies can be built to deploy to multiple clusters linked to this specific IEAM Hub.
hzn exchange service publish -f horizon/service.definition.json
Create a node policy on the edge cluster
After you publish the edge service, you can deploy this service to the edge cluster by creating a deployment policy. IEAM uses autonomous management to decide which nodes to deploy the policy. Every edge node has a set of node properties defined. When the node policy on the edge node matches the constraints defined in the deployment policy. You should have already completed the steps to install the GPU operator and register your edge cluster to IEAM hub before completing these steps.
Get the node policy json file and update according to your deployment policy:
wget https://raw.githubusercontent.com/open-horizon/examples/master/edge/services/helloworld/policy/node.policy.jsonEdit the above
node.policy.jsonto set and change it according to your use case.For example:
{ "properties": [ { "name": "edgenode", "value": "cluster" }, { "name": "property1", "value": "value1" } ], "constraints": [ ] }Register your node policy with this policy:
hzn register -u $HZN_EXCHANGE_USER_AUTH cat node.policy.json | hzn policy update -f-After the above registration is complete, run the
hzn policy listto get the node policy properties created on the device.
Deploy the MVI model using the deployment policy
Get the deployment policy files to deploy your new service to your edge node. Change the properties and service values accordingly in the deployment policy json.
wget https://raw.githubusercontent.com/open-horizon/examples/master/edge/services/helloworld/policy/deployment.policy.jsonPublish and view your deployment policy in the Horizon Exchange.
hzn exchange deployment addpolicy -f deployment.policy.json ${HZN_ORG_ID}/policy-${SERVICE_NAME}_${SERVICE_VERSION} hzn exchange deployment listpolicy ${HZN_ORG_ID}/policy-${SERVICE_NAME}_${SERVICE_VERSION}Once the node policy on the cluster matches the constraints of the deployment policy, the edge cluster will make an agreement with one of the Horizon agreement bots (this typically takes about 15 seconds). Repeatedly query the agreements of this device until the "agreement_finalized_time" and "agreement_execution_start_time" fields are filled in.
hzn agreement listCheck that the containers are in
runningstate by issuing theoc get podscommand after the “agreement_execution_start_time” is filled in.
Implementing the device layer
The edge device layer will contain devices that have compute and storage power and can run containers. These devices can run relatively simple applications to gather information, run analytics, apply AI rules, and even store some data locally to support operations at the edge. The devices could handle analysis and real-time inferencing without involvement of the edge server or the enterprise region.
Devices can be small. Examples include smart thermostats, smart doorbells, home cameras or cameras on automobiles, and augmented reality or virtual reality glasses. Devices can also be large, such as industrial robots, automobiles, smart buildings, and oil platforms. Edge computing analyzes the data at the device source.
The primary product for the device layer is IBM Edge Application Manager. IBM Edge Application Manager provides a new architecture for edge node management. With IBM Edge Application Manager, you can quickly, autonomously, and securely deploy and manage enterprise application workloads at the edge and at massive scale.
On the device layer, any tools or components must be able to manage workloads placed across clusters and the device edge. While many edge devices are capable of running sophisticated workloads such as machine learning, video analytics and IoT services, if the workload is too large for the device layer, the workload should be placed at the application layer. The use of open-source components is key at the device layer, because the portability of our edge solution is key across private, public, and edge clouds.
In our use case, we are using Jetson TX2 as the smart camera. To implement the use case, this edge device needs to be registered to IBM Edge Application Manager.
In this section, we will go through steps involved in installing the Open Horizon agent on our device and registering the device to IBM Edge Application Manager Exchange so that we can deploy models on the device. Once our TX2 device is registered to IBM Edge Application Manager, the object detection model can be deployed which can then help identify human beings in the danger zone and start the stream to the MEC server.
Register the edge device
The next step is to install edge agent and register edge device (Mac/TX2) to the IEAM Hub. Registering the edge nodes enables us to deploy workloads like object detection models on the edge device. Use the IEAM documentation to install the edge agent on edge nodes and register it with IEAM hub.
Configure and register your edge device to the IEAM hub using the IEAM documentation.
Create a node policy on the edge device
We can deploy edge services to the edge node by creating a deployment policy on the IEAM hub. The edge services added to the deployment policy will be deployed to the edge node when there is a match between constraints of the deployment policy and node properties of the device. We’ll see how to create a deployment policy with constraints in the next step, in this step we’ll see how to create a node policy on the edge device for IEAM to be able to autonomously manage these nodes.
Get the node policy json file and update according to your deployment policy:
wget https://raw.githubusercontent.com/open-horizon/examples/master/edge/services/helloworld/policy/node.policy.jsonEdit the above
node.policy.jsonto set and change it according to your use case. For example:{ "properties": [ { "name": "edgenode", "value": "devicex" }, { "name": "device", "value": "mac" } ], "constraints": [ ] }Register your node policy with this policy:
hzn register -u $HZN_EXCHANGE_USER_AUTH --policy node.policy.jsonAfter the above registration is complete, run the
hzn policy listto get the node policy properties created on the device.
Create deployment policies on the IEAM hub
When the edge node is registered with IBM Edge Application Manager hub, we use node properties to identify this node in the fleet of edge nodes. The deployment policies use node constraints to determine where the service in these policies needs to be deployed. The node properties on the edge nodes should match the constraints defined in the policies for the service to be deployed on a specific edge node.
Get the deployment policy files to deploy your new service to your edge node. Change the properties and service values accordingly in the deployment policy json.
wget https://raw.githubusercontent.com/open-horizon/examples/master/edge/services/helloworld/policy/deployment.policy.jsonPublish and view your deployment policy in the Horizon Exchange.
hzn exchange deployment addpolicy -f deployment.policy.json ${HZN_ORG_ID}/policy-${SERVICE_NAME}_${SERVICE_VERSION} hzn exchange deployment listpolicy ${HZN_ORG_ID}/policy-${SERVICE_NAME}_${SERVICE_VERSION}Once the node policy on the cluster matches the constraints of the deployment policy, the edge cluster will make an agreement with one of the Horizon agreement bots (this typically takes about 15 seconds). Repeatedly query the agreements of this device until the “agreement_finalized_time” and “agreement_execution_start_time” fields are filled in.
hzn agreement list
The agreement triggers the horizon agent to download the necessary docker images to the edge device. Once the necessary docker images are pulled and horizon agent runs the docker images on the node and this can be confirmed by running “docker ps” command on the system to confirm that the docker image is running.
We have deployed the object detection model on the devices and now the devices are ready to deploy any further models. With the object detection model deployed on the MAC/TX2, whenever the camera detects a person, we can start video streaming to the MEC server.
Updating the AI model by using MMS
The IEAM model management system (MMS) eases the burden of Artificial Intelligence (AI) model management for cognitive services that run on edge nodes. MMS enables edge nodes to easily send and receive models and metadata to and from the cloud. MMS enables us to update AI Models within an application without re-deploying the entire edge service.
In the above steps, we have deployed an application that does object detection to the edge device using deployment policies. This object detection model is trained to detect person in the frame. With MMS, we can easily update the model to detect hardhat instead of person without re-deploying the earlier edge application but only update the model that the application uses.
The following figure shows our object detection model detecting a person before we deploy a MMS model update.

To use the IEAM MMS to manage updates to our MVI model, follow these steps:
Create the MMS Object.
MMS Objects are the machine learning model files and other types of data files that are published for distribution across edge nodes. The MMS object requires a metadata file along with the data model file for publishing and distribution. The metadata file is a json file that configures a set of attributes for the data model.
Copy the template to a file named my_metadata.json:
hzn mms object new >> my_metadata.jsonUpdate the metadata file.
In the below sample example, we have edge nodes registered with policy that deploys
objectdetectmmsservice.objectdetectmmsis one of the services running on the nodes which does person detection, and we want to update your model to detect hardhat instead of person. We can update or change the model file by publishing a differentmodel.zipto theobjectdetectmmsservice for the model to start detecting hardhat. If the target edge nodes are registered with policies, usedestinationOrgIDanddestinationPolicyto update the metadata file. Service details should be provided accurately to ensure that the new model being published will be utilized by the intended service.An example of metadata file would be:
{ "objectID": "model.zip", "objectType": "model", "destinationOrgID": "$HZN_ORG_ID", "destinationPolicy": { "properties": [], "constraints": [], "services": [ { "orgID": "$SERVICE_ORG_ID", "arch": "$ARCH", "serviceName": "objectdetectmms", "version": "$VERSION" } ] }, "version": "1.0.0", "description": "update/change the existing model to hardhat detection" }Publish the MMS object.
We will need the metadata file as well as model file (
model.zip) to publish this MMS object. Model file is the model data file that’s used in the application to do the detection.hzn mms object publish -m my_metadata.json -f model.zipThe above command publishes the model and metadata file to the Cloud Sync Service, which is deployed in the IEAM hub and will deliver the models and metadata to the edge nodes.
Check the status of MMS object.
Once the MMS object is published, all the nodes running this service deployed using policies will get the model update. Edge Sync Service (ESS) running on the edge node will continually poll the CSS for object updates and stores any objects that are delivered to the edge node.
hzn mms object list --objectType=model --objectId=my_model -dThe above command will display the object status and destinations along with the MMS object. From the sample output below for the above command, the status displays which nodes is the model update delivered to.
[ { "objectID": "model.zip", "objectType": "model", "destinations": [ { "destinationType": "openhorizon.edgenode", "destinationID": "sai-mac", "status": "delivered", "message": "" } ], "objectStatus": "ready" } ]
After the model update is received and processed by the edge node, we can see the application detecting hardhat instead of person (see the following figure).

Summary and next steps
We covered two key components of the edge: the application layer and the device layer. Connectivity to the edge is a key component required to successfully implement the edge. In many cases, the edge will be implemented where connectivity is not available or is not sufficient to meet the low latency requirements for the edge nodes. In such cases, the key network components have to be deployed on the edge.
To implement this edge computing architecture, these are the steps that you followed:
- Create MVI model and containerize it.
- Install GPU operator on the edge cluster.
- Register edge device and edge cluster as edge nodes to IEAM Hub.
- Create helm chart and helm operator service on edge device for the MVI model.
- Publish the helm operator service to IEAM Hub
- Create node policy and deploy the edge operator service to the cluster.
- Deploy the object detection pattern to the edge device.
Our next article in this edge computing series dives deeper into the network edge and the tooling that is needed to implement it. This article discusses how the different layers come together using a use case that requires all three layers: application, device, and network.