Article
An introduction to event sourcing
Learn a common pattern for building an event-driven solutionIn most industries, businesses have to react in real time to actions taken by their customers and events affecting their environments. For that reason, it’s often valuable to design processes and applications that mimic the real world and are event-driven.
The Event-driven architecture model shows how to build and extend event-driven solutions on cloud-native architectures.
This article takes a closer look at one of the most common patterns used when building an event-driven solution and gives an overview of using event sourcing.
Prerequisites
This article assumes that you have some familiarity with cloud terminology and Apache Kafka.
Estimated time
Take 5-10 minutes to read this article and consider some of the tools we used, and invest more time if you want to try to work with event-driven architecture yourself.
What is event sourcing?
Event sourcing is an approach for maintaining the state of business entities by recording each change of state as an event.
Whether a customer buys an item in a shop, or updates a profile online, both actions can be seen as an event. In its most basic form, an event captures a fact. It means that something has happened.
In event sourcing, every time something interesting happens, it is captured and stored as an event. Instead of directly updating the state of the affected entities, the sequence of state changes is saved. The following sequence diagram shows the sequence of events for three different customers.
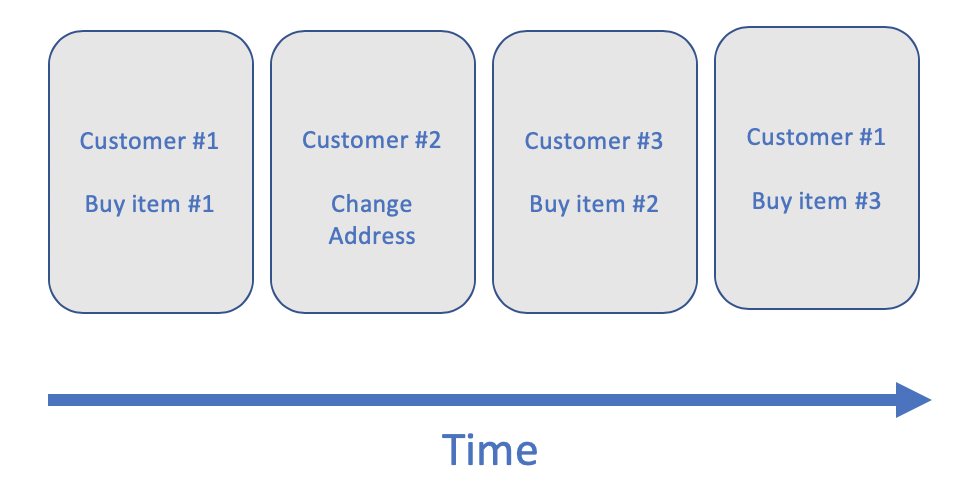
The event store must provide a few features to make this approach viable:
- Ordering: New events must be added at the end of the sequence.
- Immutability: Previous events cannot be updated. If an operation must be undone, a new event should be created to revert the previous event.
- Message broker: Applications must be able to subscribe to events.
The goal is to use the event store as the source of truth and allow reprocessing the events to fully rebuild all other states.
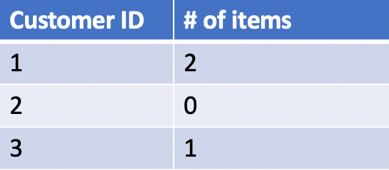
For example, if you take the short sequence of events shown above, a microservice that stores the number of items bought by the customer is able to compute the following customer IDs and number of items:
Why use event sourcing?
Event sourcing brings some interesting benefits. The first advantage is atomicity, because writing the event is a single operation. Applications can easily ensure the event is correctly recorded. Then each consuming service can handle updating its own state in response to the event. This approach avoids the need to deal with distributed transactions between a database and a message broker.
Using an event store also decouples the different microservices. When emitting an event, an application does not need to know about other applications interested in the event. This approach greatly improves performance and allows the pattern to scale really well.
Finally, event sourcing gives you the ability to use the sequence of events that led to the current state. Whether it is for audit, replayability, or to perform machine learning on past data, the full sequence of events provides more insight than only retaining the current state.
Apache Kafka as the event store
Apache Kafka’s rise in popularity is at least partly due to its capabilities in event-driven environments. It is extremely well suited for event sourcing because it provides all the required properties, including the ability to scale:
- Kafka Streams is a stream processing library that allows you to quickly write complex processing logic. It supports all sorts of operations like joining, aggregating, counting, filtering and allows to focus on business logic.
- Messaging System is a performant and easy-to-use API provided by Kafka to emit and consume events. In addition, consumer groups enable to scale processing microservices when needed.
- Log Compaction is a capability with Kafka that you can use to build snapshots of streams of events and save time when starting an application. When a topic is compacted, Kafka only keeps the last value associated with each key. This value can be used to build snapshots of the streams of events, so microservices don’t need to reprocess all events when you start up.
Considerations when event sourcing
You need to take into account a few factors when implementing a solution based on event sourcing.
Because all things evolve, it is very likely the schemas of events change, or new events are added over time. If built without care, you quickly find a situation where every single event update requires updating all consuming applications.
In addition, the initial cost can be high. Each microservice needs some scaffolding to process the stream of events and to update its store. In addition, it’s relatively common to have logic that joins multiple types of events to enrich data. Without a framework or a library, this situation can lead to significant code duplication and some inconsistencies that are hard to debug.
Finally, in practice, you don’t want microservices to reprocess all the events since the beginning of time when you start up an application. It’s important to build regular snapshots that can be used to restart very quickly. As previously mentioned, Apache Kafka helps building snapshots. Otherwise, a database can be used.
Summary
Now you understand one of the most common patterns for building an event-driven solution, and you have some basic tips to use event sourcing.
To try out event sourcing, check out Event Streams, a managed Kafka-as-a-service platform on IBM Cloud.