Article
Explore checkpoint and restart functionality in DataStage
Restart from last known successful flow checkpointDataStage ETL executions are known for their high-performant, pipeline-parallel partitioning. While DataStage has had the ability for quite some time to enable an orchestration flow (traditionally called a DataStage sequence) to restart from the last failed activity, DataStage parallel flows would have to be restarted manually and from the beginning of the flow. Checkpoint/Restart functionality is now available for DataStage parallel flows, allowing you to benefit from the ability for DataStage flow executions to not only automatically restart but also restart from the last known successful checkpoint in the flow. This feature was implemented using environment variables within DataStage to make enabling this feature simple and possible to apply without any code changes.
As mentioned, DataStage flows are known for their performance. Inserting a checkpoint into the flow could introduce a delay to the pipeline parallelism that DataStage constructs. Checkpointing was implemented to avoid introducing unnecessary bottlenecks in the flow design to maintain strong performance while adding resiliency. DataStage accomplishes this by only inserting checkpoints into natural blocking places in the ETL stream. Sort operations in DataStage are naturally blocking due to the need to have all of the data to sort the data. This allows DataStage to have an efficient place in the ETL stream to checkpoint the state of the flow. Once the checkpoint is marked complete, subsequent executions can restart from this checkpoint, instead of the beginning of the flow.
Checkpoint/Restart was originally developed for DataStage flows running on Apache Hadoop (BigIntegrate/BigQuality). DataStage is able to utilize the power of Hadoop clusters by running as a YARN application and distributing workload across data nodes in the Hadoop cluster. Hadoop was originally known for building clusters out of low-cost commodity hardware, which meant applications needed to be resilient in order to handle nodes going offline. Focusing on the current trend of the software market toward containerization and cloud-native principals, the same desire for resiliency exists. Instead of using HDFS in BigIntegrate/BigQuality for the resource disk to persist checkpoints, DataStage can also persist checkpoints to another form of common storage, such as an S3 endpoint, block, or object storage. Checkpoints do require additional disk space from typical DataStage executions. Checkpoints by their nature are persisting the entire data set of an ETL flow in stream to disk, which can result in significant storage allocations given the data volume the flow will process.
Checkpoint operator
The Checkpoint operator is an operator that contains the capability in the DataStage parallel engine to manage and persist the data stream of the DataStage flow. At this time, the checkpoint operator is only available as a framework-inserted operator, meaning that while designing a DataStage flow, you cannot select where checkpoints are performed as there is no dedicated stage that represents the checkpoint operator on the canvas. Checkpoints will be inserted automatically into the generated flow code by the DataStage parallel engine at the time of compilation. Checkpoints will most commonly be inserted ahead of sort operations by the framework, but could also be inserted ahead of target stages or connectors, depending on the type of checkpoint chosen. There are two main types of checkpoints:
- Intermediate checkpoints
- Target-blocking checkpoints
Intermediate checkpoints are inserted before sort operations due to the naturally blocking condition that sort operations enforce. This allows for checkpoints to be inserted into the flow at various intermediate places through the design. Only the last successful checkpoint is persisted. If a subsequent checkpoint downstream completes successfully, the upstream checkpoint is purged from disk and the flow continues. This functionality can be enabled by setting the environment variable APT_CHECKPOINT_ENABLED to sortonly.
By default, flows that fail are not automatically restarted after they have begun writing, inserting, or updating data to a target stage. This is by design to prevent any partial insertion of data that may leave the target in an unknown or corrupt state if the flow restarts. In this target blocking checkpoint, the checkpoint will buffer all data it reads until it gets to the final record in its assigned partition. At this point, the checkpoint is marked as complete and data begins to stream to the target stage or connector. If the DataStage execution fails prior to this target-blocking checkpoint, the flow will be able to automatically restart. Once this target-blocking checkpoint is complete, any failure after this point in the flow will require a manual restart due to the DataStage parallel engine's inability to be sure of any impact to the data integrity of the target stage or connector. While this necessitates a manual restart, you can manually restart the DataStage flow from a persisted checkpoint, discussed below. This target-blocking checkpoint can be excluded in situations where the target stage or connector is replacing the entire contents of a table or file as an example. This functionality can be enabled by setting the environment variable APT_CHECKPOINT_ENABLED to targetonly.
Both intermediate and target-blocking checkpoints can be inserted by setting the environment variable APT_CHECKPOINT_ENABLED to 1. This is the most common setting for checkpointing.
In some cases, it may be desired to manually restart a DataStage flow from a persisted checkpoint. This can help address situations in which a DataStage execution cannot be automatically restarted. To do this, the checkpoint must be persisted past the lifecycle of the execution invocation. The variable APT_CHECKPOINT_PERSISTENT can be set to a fully qualified path name, including the checkpoint filename that will be persisted after the execution fails. The same variable can be set when manually restarting a DataStage execution, providing the location of the persisted checkpoint and the execution will use this checkpoint and attempt to re-run the flow.
Whether checkpoints are persisted past the execution lifecycle or leverage within an execution, by default, checkpoints will be written to disk in a compressed format using LZ4 compression. This helps drastically reduce the storage requirements for large datasets. Checkpoint data is split into individual files based on the defined memory block size; by default, this is 64MB, but is configurable by setting APT_CHECKPOINT_BLOCK_SIZE to an integer value in MB.
Restart functionality
The restart functionality in DataStage is triggered when a DataStage execution fails for any reason. Restart functionality can be used stand-alone or in coordination with checkpoints, meaning that in order to enable restart functionality, it is not required to enable checkpointing. If checkpointing is not enabled, the DataStage execution will simply restart from the beginning of the flow. Restart functionality is an opt-in feature that can be enabled by setting the environment variable APT_CHECKPOINT_RESTART to an integer value that defines the number of times DataStage will attempt an automatic restart. The DataStage execution log will note the failure and the restart attempt(s). If the subsequent execution was successful, the final status of the execution will be successful/completed.
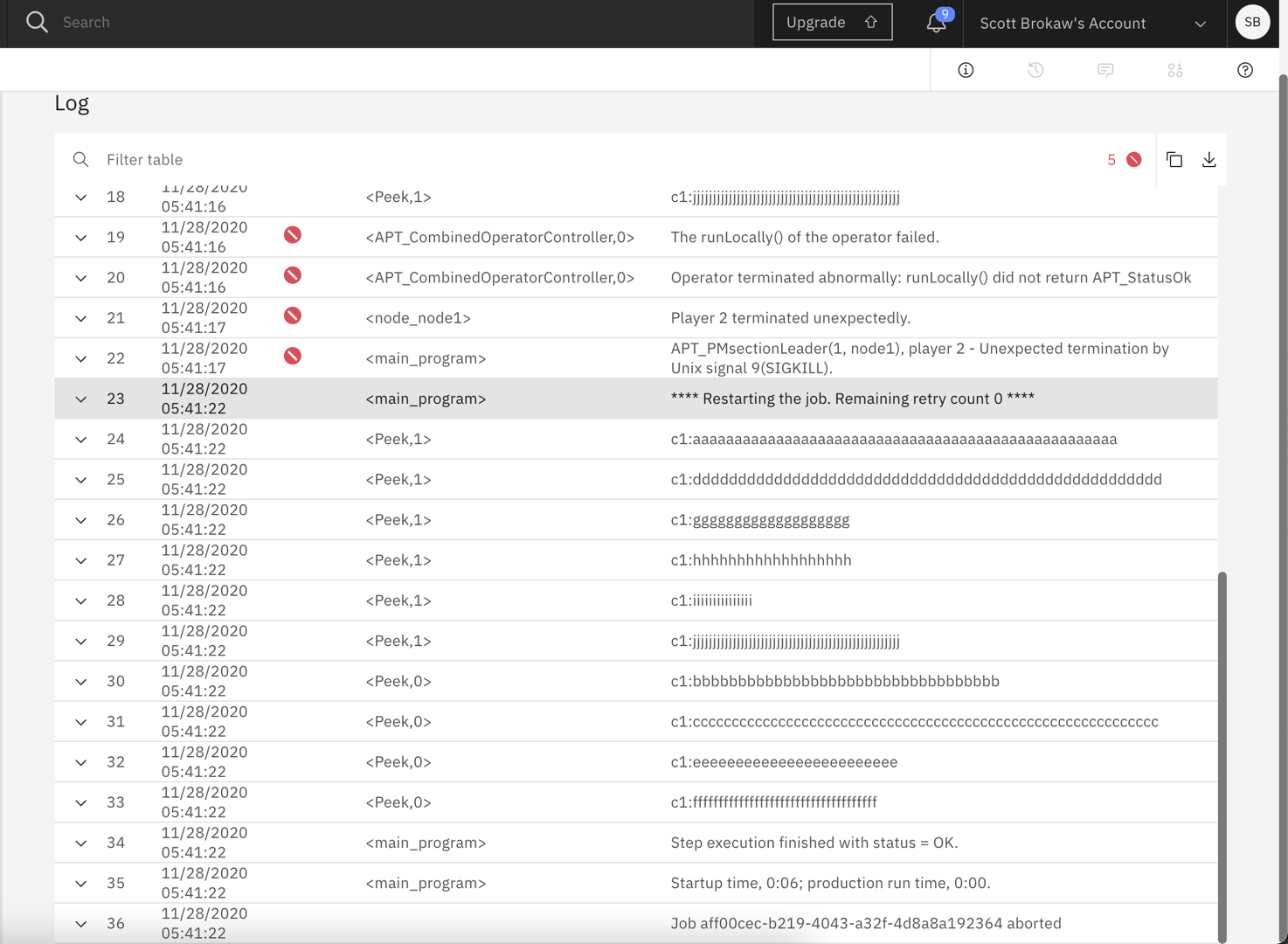
By default, restart of the execution will happen immediately after a failure condition is detected. It can be desirable to ask the DataStage engine to delay restart for a period of time between invocations. To trigger a delay, the environment variable APT_CHECKPOINT_RESTART_DELAY can be set to a valid integer seconds value to delay the restart of the execution after a failure.
Reading the score
The DataStage parallel engine score report documents the execution pattern a DataStage flow will contain. The score will include optimizations and additional framework-inserted operations to take the graphically designed DataStage flow and convert into an execution pattern. Given that checkpoints are framework-inserted, the score report is a useful way to understand more about their use and execution.
Use the following DataStage flow as an example.

An extract of the generated Score report for this flow is as follows.
...
...
It has 5 operators:
op0[1p] {(sequential Row_Generator)
on nodes (
node1[op0,p0]
)}
op1[1p] {(parallel checkpoint(0))
on nodes (
node2[op1,p0]
)}
op2[2p] {(parallel Sort)
on nodes (
node1[op2,p0]
node2[op2,p1]
)}
op3[2p] {(parallel Abort)
on nodes (
node1[op3,p0]
node2[op3,p1]
)}
op4[2p] {(parallel Peek)
on nodes (
node1[op4,p0]
node2[op4,p1]
)}
It runs 8 processes on 2 nodes.
In this example, you can see the checkpoint operator inserted by the DataStage framework ahead of the sort operator.
Estimating checkpoints
As checkpoint files are written to disk -- and can be fairly large depending on the amount of data the DataStage execution is processing -- there is a mechanism to estimate the amount of disk space each checkpoint would require on disk before fully enabling checkpointing in the flow. To enable this estimate, the environment variable APT_CHECKPOINT_ESTIMATE can be defined, along with defining the type of checkpoints used via defining APT_CHECKPOINT_ENABLED. The combination of these two variables will result in an estimate of the disk space required per checkpoint to be written to the execution log.
Troubleshooting
For troubleshooting, the checkpoint operator, if the environment variable APT_DEBUG_CHECKPOINT is defined, verbose logging messages will be written to the execution log for review and analysis.
Summary
We have expleined how to use the new checkpoint/restart functionality for DataStage parallel flows, allowing you to restart from the last known successful checkpoint in the flow. This feature was implemented using environment variables within DataStage to make enabling this feature simple and possible to apply without any code changes. To learn more about DataStage, check out Getting started: Using the new IBM DataStage SaaS beta.