Article
Profile-guided optimization (PGO) using GCC on IBM AIX
Applying PGO to Facebook zstdArchive date: 2025-02-19
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Learning objectives
In this article, you can learn how profile guided optimization works, and how it can be used with GCC to acclerate any application. You can also learn how to apply profile-guided optimization (PGO) to Facebook Zstandard compression library (zstd).
Profile-guided optimization
Compilers do performance optimizations by using known heuristics, making most probable guesses about code execution. For example, a compiler may decide the branch to take based on where is it located in a loop, and it may choose to inline a function based on its size. To extract good performance out of a program, it is important for the programmer to have intrinsic knowledge of the compiler and system design so that the programmer can provide hints or annotations to the compiler. Unfortunately, this is not always possible. Another performace optimization technique that offers a better advantage is profile-guided optimization (PGO).
PGO is a method used by compilers to produce optimal code by using application runtime data. Because this data comes directly from the application, the compiler can make much more accurate guesses.
How does it work, phases?
1. Instrumentation
The first phase is the instrumented compilation. Instrumented compilation typically produces an executable program that contains probes in each of the basic blocks of the program. Each probe counts the number of times a basic block runs. If the block is a branch, the probe records the direction taken by that branch.
gcc -fprofile-generate=<profile_dir> progname.c
2. Profiled execution
The second phase is the profiled execution. When run, the instrumented program generates a data file that contains the execution counts for the specific run of the program.
3. Optimization
Information from the profiled execution of the program is fed back to the compiler. This data is used to make a better estimate of the program’s control flow. The compiler uses this information to produce an executable file, relying on this data rather than the static heuristics.
gcc -fprofile-use=<profile_dir> progname.c
A key factor in deciding whether you want to use PGO lies in knowing sections of your code that are the most heavily used. If the data set provided to your program is very consistent and it elicits a similar behavior on every execution, then PGO can probably help to optimize your program execution. However, different data sets can elicit different algorithms to be called. This can cause the behavior of your program to vary from one execution to the next.
What optimizations are performed?
A compiler performs various optimizations based on a profile. Some of the most common and effective techniques are explained in this section.
Function inlining
Function inlining is a technique where we inline high frequency functions into one of the calling functions to reduce function call overheads. Normally, a compiler makes these decisions based on the code block size etc. Inlining decisions are most effective when the compiler has a vague idea of the call pattern. Let us look at an example.
The following diagram has parts of a program’s flow graph. Circles represent functions and the edges represent frequency of the call. When a compiler has no heuristic data, it may or may not choose inlining at all. The story is different when we have runtime heuristics available.
Figure 1. A typical program flow graph where edges represent frequency of calls
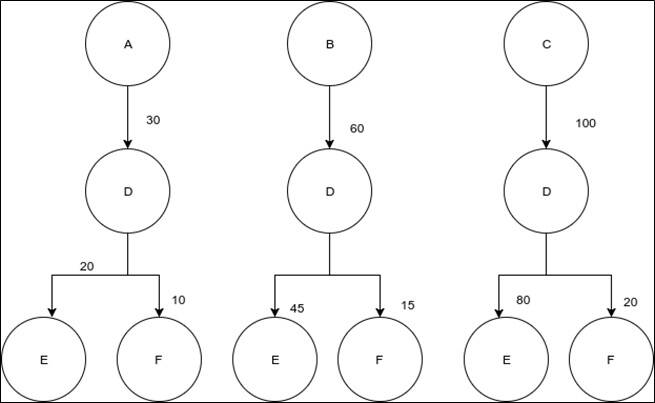
In Figure 1, it is not difficult to observe that function D get called several times. Clearly we will make the most by inlining D into C and E into D. It is an easy decision when we have function call heuristics available.
Block ordering
A code block is a sequence of consecutive instructions where execution begins at the top and ends at the bottom. A typical program consists of code blocks and branches. Although the easiest approach to code generation is to organize code blocks in the same sequence as specified by the programmer, it is not the most performance effective approach. Let us look at an example to see why.
Consider the following code.
func_a()
{
........
........
if (condition = TRUE)
{
call_func_b()
} else {
call_func_c()
}
}
func_b()
{
func_d()
}
func_c()
{
func_d()
}
Without any knowledge about the condition, the compiler generates the following blocks of code.
Figure 2. Default layout
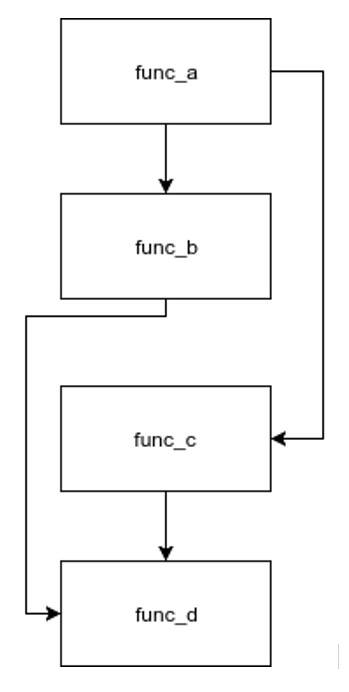
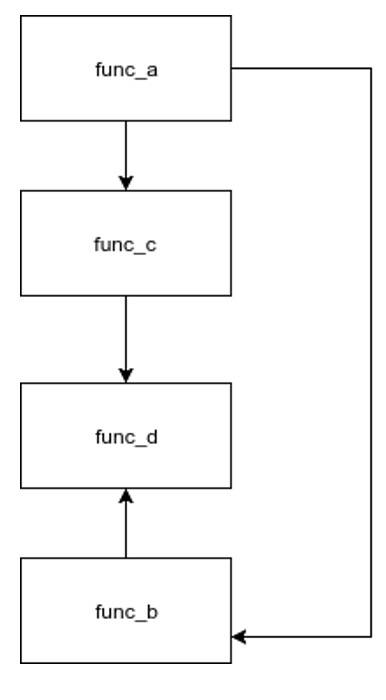
A compiler’s aim is to achieve call locality or to perform minimum amount of memory operations. Functions which are tightly bound should be collocated to minimize instruction cache fetches. In the given example, if the profile suggests that the condition is FALSE, most of the time, it would make sense to keep func_c closer to func_a. Similarly func_d will be placed close to func_b.
Figure 3. Optimized layout
Register allocation
Although not important for reduced instruction set computing (RISC) architectures than their complex instruction set computing (CISC) counterparts, optimal use of available regsiters makes a lot of difference in application performance. With a sample heuristics available, the compiler can easily find the hot and very frequently used variables. This prevents unnesseary cache (perhaps memory) access, speeding up the application.
Typically, the register allocator uses a static heuristic, preferring to keep variables used in loops in registers, for example. This results in register allocation that is locally optimized within the loop, but it may not produce the best total performance. With profile information, this decision is made based on the actual usage.
There are other performance enhancement techniques that gain immensely with a profile. They include optimizing virtual calls, dead code seperation, and so on.
Using GCC PGO to accelerate zstd on AIX
The effect of PGO can be most easily observed in processor-intensive applications. We chose Facebook zstd compression/decompression library to demonstratre the benefits of PGO. This experiment requires an IBM® AIX® logical partition (LAPR) with GCC 7.0 or a later version installed.
Configuring IBM AIX and GCC
A GCC compiler suite can be installed on AIX from various sources, however it is easiest to do so using YUM. Refer to the YUM on AIX guide.
Obtaining sources
Clone the zstd library from GitHub or download a compressed version using the following command to get the latest source.
git clone https://github.com/facebook/zstd.git
Benchmarking using zstd library
The zstd library also has a benchmark program in its source which performs compression and decompression on memory files. Because we do not have to deal with the files present on disk, factors such as I/O devices do not affect our results. The source for this benchmark program is available in tests/fullbench.c. Following steps can be performed to obtain the benchmark.
Edit Makefile in the tests directory as follows.
zstdDIR = ../lib PRGDIR = ../programs PYTHON ?= python3 TESTARTEFACT := versionsTest CC = gcc DEBUGLEVEL ?= 1 DEBUGFLAGS = -g -DDEBUGLEVEL=$(DEBUGLEVEL) CPPFLAGS += -I$(zstdDIR) -I$(zstdDIR)/common -I$(zstdDIR)/compress \ -I$(zstdDIR)/dictBuilder -I$(zstdDIR)/deprecated -I$(PRGDIR) ifeq ($(OS),Windows_NT) # MinGW assumed CPPFLAGS += -D__USE_MINGW_ANSI_STDIO # compatibility with %zu formatting endif CFLAGS ?= -O3 CFLAGS += -Wall -Wextra -Wcast-qual -Wcast-align -Wshadow \ -Wstrict-aliasing=1 -Wswitch-enum -Wdeclaration-after-statement \ -Wstrict-prototypes -Wundef -Wformat-security \ -Wvla -Wformat=2 -Winit-self -Wfloat-equal -Wwrite-strings \ -Wredundant-decls -Wmissing-prototypes PGOFLAGS += CFLAGS += $(DEBUGFLAGS) $(MOREFLAGS) $(PGOFLAGS) FLAGS = $(CPPFLAGS) $(CFLAGS) $(LDFLAGS)Run the
gmakecommand to produce fullbench in tests directory.rm fullbench; gmake ; ./fullbench -b2Obtain initial results by running the following command.
# ./fullbench -b2 *** Zstandard speed analyzer 1.3.8 32-bits, by Yann Collet (Nov 26 2018) *** Sample 10MiB : 2#decompress : 1215.8 MB/s (10000000)Edit
PGOFLAGSas follows:PGOFLAGS = -fprofile-generate=/tmp/pgoRun the following command to generate profile data in /tmp/pgo.
rm fullbench; gmake ; ./fullbench -b2 *** Zstandard speed analyzer 1.3.8 32-bits, by Yann Collet (Nov 26 2018) *** Sample 10MiB : 2#decompress : 770.5 MB/s (10000000)It can be noted that this run is considerably slower. This is because of the probes we placed using the
fprofile-generatecommand. Let us look at the /tmp/pgo directory. It consists of *.gcda files. Each file here contains metadata about the hot code blocks obtained from our last test run.ls /tmp/pgo # ls /tmp/pgo benchfn.gcda fse_compress.gcda huf_compress.gcda xxhash.gcda zstd_decompress.gcda zstd_lazy.gcda datagen.gcda fse_decompress.gcda huf_decompress.gcda zstd_common.gcda zstd_decompress_block.gcda zstd_ldm.gcda entropy_common.gcda fullbench.gcda pool.gcda zstd_compress.gcda zstd_double_fast.gcda zstd_opt.gcda error_private.gcda hist.gcda util.gcda zstd_ddict.gcda zstd_fast.gcda zstdmt_compress.gcdaUse the profile data from previous step and perform the following tasks.
Edit PGOFLAGS as follows.
PGOFLAGS = -fprofile-use=/tmp/pgoRun the following command to use profile data in /tmp/pgo.
rm fullbench; gmake ; ./fullbench -b2 *** Zstandard speed analyzer 1.3.8 32-bits, by Yann Collet (Nov 26 2018) *** Sample 10MiB : 2#decompress : 1452.7 MB/s (10000000)
Conclusion
It should be noted that profile-based optimization is suited to those applications where a sample run mimics the general behaviour of the program. Also, it must be ensured that the data set used to produce profile information must closely resemble the data set in actual use. If the application behaves differently for different data sets, it is possible to observe a regression in performance. However, for large applications that are run frequently, it is observed that PGOs can prove to be a significant source of performance.