Article
Introduction to computer vision
Learn the basics of computer vision with deep learningOverview
Cameras are everywhere. Videos and images have become one of the most interesting data sets for artificial intelligence. In particular, deep learning is being used to create models for computer vision, and you can train these models to let your applications recognize what an image (or video) represents.
Learning objectives
The article covers computer vision basics and explains how you might use computer vision in your apps. You'll learn about:
- Image classification
- Object detection
- Object tracking in videos
- Creating custom models
- Using your model
- Example use cases
Definition of common terms
| Term | Definition |
|---|---|
| Data set | In our case, a data set is a collection of images and videos. An example of a data set would be images of cars. |
| Model | A model is a set of tuned algorithms that produces a predicted output. Models are trained based on the input that is provided by a data set to classify images or video frames, or find objects in images or video frames. |
| Category | A category is used to classify an image. The image can belong to only a single category. An example of a category for a data set that contains cars would be car manufacturers (for example, Toyota, Honda, Chevy, or Ford). |
| Object | An object is used to identify specific items in an image or specific frames in a video. You can label multiple objects in an image or a frame in a video. An example of objects in an image of cars might be wheels, headlights, or windshields. |
Computer vision basics
To begin understanding computer vision, you might start with image classification and then take on object detection. In both cases, you have endless possibilities for how you can apply these features in your apps using your own custom models. Some advanced applications, such as detecting actions or tracking objects in a video, build on these basics.
Image classification
For image classification, you want to build a solution that can examine an image and properly classify it according to your model. A model can be as simple as the famous hotdog/not-hotdog model, which is a binary model where you want to know only whether you have an image of a hotdog. You might think the application of this model is limited (and it is), but if you consider all of the if/else decisions that applications might make based on simple binary models, you'll find many use cases for application-specific binary models. Even something as sophisticated as a medical test often comes down to a simple positive/negative answer, which can be accomplished with image classification.
The following demo shows what you can do with a video and a simple model. Notice that instead of images, this was built using a video, which is just a sequence of images (frames). The current frame is either recognized as a hotdog or not.

Binary image classification example app
Many image classification use cases are not binary. For these use cases, you train a model to recognize multiple categories. In addition to returning the chosen category, a confidence percentage is returned. This confidence percentage is used to select the most likely category, but you can also use a threshold to throw out even the most likely category when the confidence is too low to be trusted. The following example Swift app runs on an iPhone and classifies a picture of a seagull as genus larus with 100% confidence.
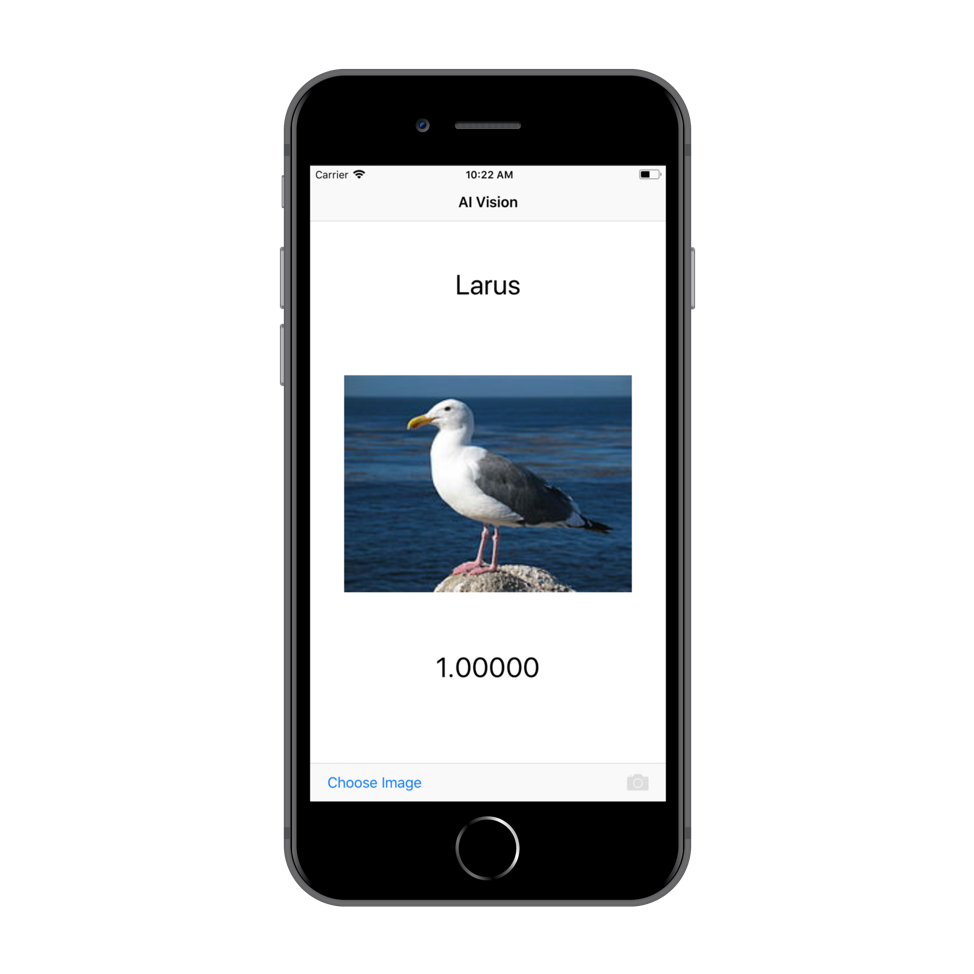
Multiclass classification example app
Object detection
Object detection is similar to image classification, except with object detection the image can contain many objects, which are located and classified. For example, you can train a model to not only classify images of Coca-Cola, but also to locate each bottle within the image.
In the following image, you see that three different categories of Coca-Cola products were recognized. In addition to returning the labels and confidence, it provides coordinates that let the app draw bounding boxes around each identified object.
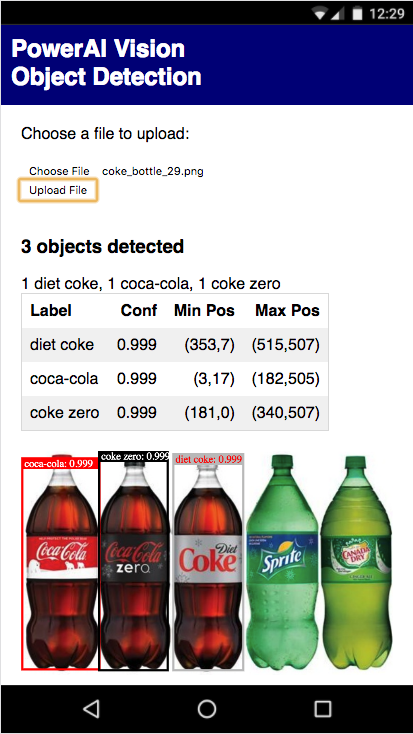
Object detection example app
Object detection is used in a wide variety of use cases where the interesting thing is not a single classification that describes the entire image, but instead can be many objects of different categories in the image. Giving an application the ability to identify, locate, and count the objects increases the possible applications of this type of computer vision.
Object tracking in videos
When using object detection in videos, you often want to track objects from one frame to the next. The initial object detection can be done by extracting a frame from the video and detecting objects in the frame. In addition to counting objects and locating each object, tracking the objects as they move from frame to frame adds another dimension to what you can do.
The following example shows how object detection was used along with object tracking to annotate a video and count cars.

Object detection and tracking example app
Creating custom models
Now that I've discussed the basics of image classification and object detection (and tracking), let's discuss how to use deep learning to create these apps as well as apps for your own use cases. In practice, this is much easier than it sounds.
A lot of work has been done to use deep learning and convolutional neural networks to recognize objects in images. Existing models already understand how to recognize edges, shapes, patterns, and so on. We use what is called transfer learning to leverage the existing models and retrain them with our own data sets.
Providing examples
For the example bird classifier, all we need is a good set of example images of birds of each type that we want to recognize. Using transfer learning and this new data set with known expected results, we can create a new model for bird image classification.
If you are using Maximo Visual Inspection, the user interface lets you upload and classify your images and then train a model with a push of a button. It's that easy. Various other frameworks let you do the same thing with a little bit of code. It is not hard to copy their example code, swap in your own data set, and map your images to custom categories, but having an easy-to-use UI is a good way to get started.
Object detection is similar to image classification, but the objects also need to be located in the data set that you use for training. To create an object detection model, you must provide images and the location (for example, coordinates) of each object in each image.
Again, Maximo Visual Inspection provides a UI to make that easy. With whatever framework you use, you need a way to upload images and provide a label and coordinates for each object in the image. Labeling for object detection is typically more time consuming than for image classification. Also, the compute time needed for training an object detection model is often significantly longer. Using GPUs and the latest algorithms helps to shorten the training time (which then allows for bigger, better data sets being used to create more accurate models).
The following image shows what labeling for object detection might look like. In this example from Maximo Visual Inspection, the data set is created by extracting frames from a video. Then, cars in a selection of frames are manually labeled by dragging a box around each car. After some manual labeling, auto-labeling and data augmentation are used to multiply your manual efforts.
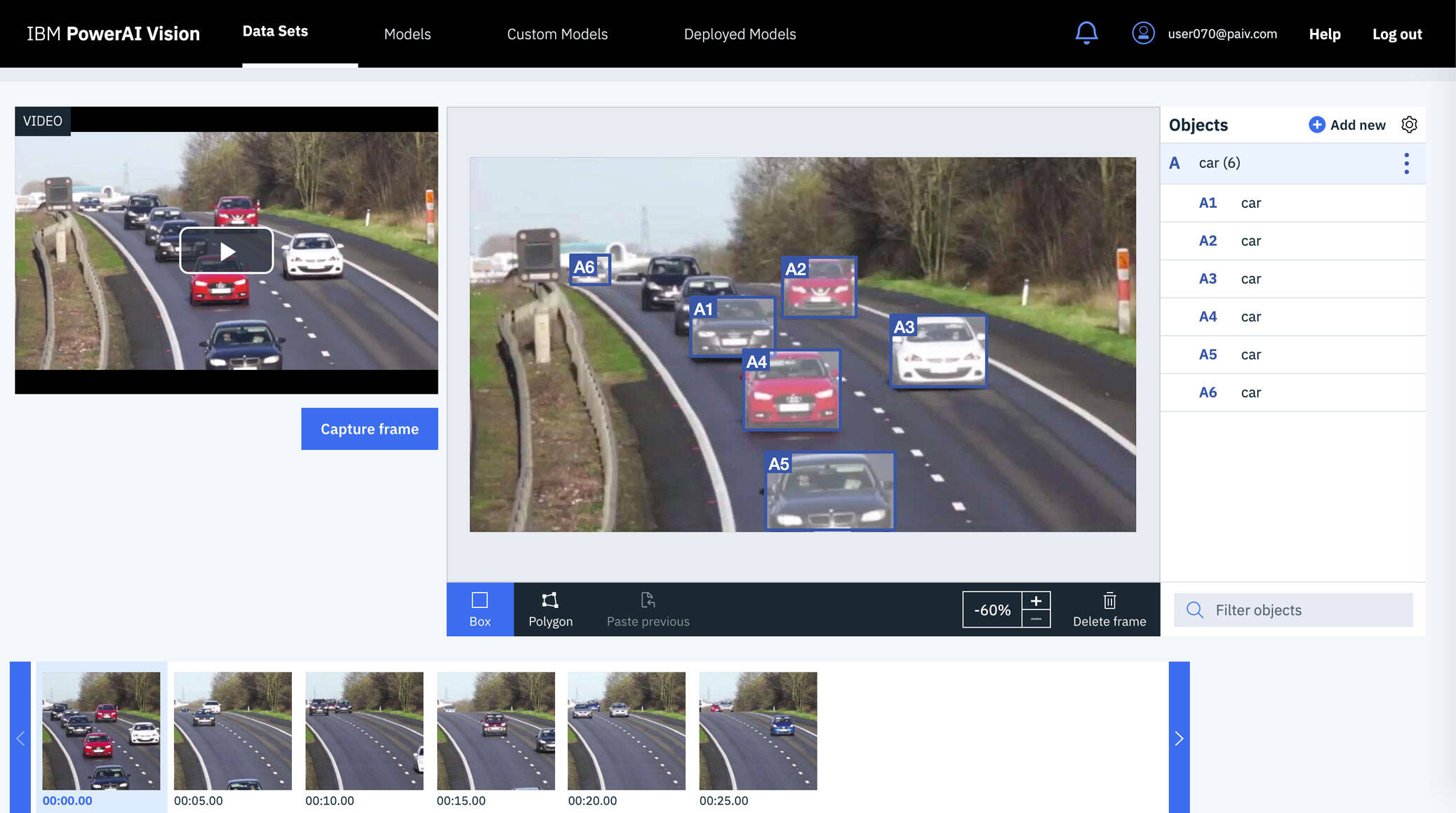
Manual labeling
Behind the scenes, Maximo Visual Inspection is built on open source technology. Whether you want to take advantage of the easy-to-use UI or prefer to write some code and work more directly with the open source APIs, you can run on Power Systems with GPUs to improve your training time and create better models faster.
Training, validation, and testing
Training a model is essentially the process of iterating over example images and adjusting weights to improve the accuracy of a prediction algorithm. I won't get into the details of deep learning and convolutional neural nets here, but you can use deep learning through transfer learning without worrying too much about the internal algorithms. However, there are a few things that you should understand to create and maintain an accurate model.
The data set is split to separate training from validation. This can be done automatically (for example, when using Maximo Visual Inspection). The reason to keep this in mind is that training can lead to overfit. As the iterations improve accuracy over the training data, eventually, the model can become "too accurate." It will recognize the images that it used for training with near 100% accuracy, but it won't be good at recognizing things in new images. This is called overfitting. Because you want a model that is more robust than that, the validation set is used to validate the training and avoid overfitting.
After running the training and validation over a specified number of intervals (perhaps canceling early if the accuracy isn't improving), you'll get a model. Generally, you also get a report of the accuracy of the model. Keep in mind that this accuracy is only regarding the provided data.
Even though some validation is part of the training, it is always a good idea (and often very satisfying) to take some additional test data and see how well your model works with images that were not part of the training (or validation) data set. Often, you find that you need to continuously evaluate your model with new data and retrain the model with an improved data set as needed.
Using your model
The previous examples showed various applications that all demonstrate taking an input image and using a custom model to produce a result (image classification or object detection). Inference is the term used when you take the input and infer its category or its objects. This is accomplished using the model. The training took a long time, but after the training is complete the model is optimized and ready to be used for inference. The details vary by framework, language, and platform, but the model is deployed (or loaded), and an API is made available for the application code to call. With the API, the app code can take an image, get inference results, and then choose how to display the results.
Example use cases
I've shown a few examples -- and I already mentioned that the possibilities are endless -- but it's worth listing some example use cases to get you thinking about how you might apply computer vision.
- Automotive: Monitor busy intersections for near-miss incidents
- Consumer goods: Monitor product quality or quantity on shelves
- Healthcare: Detection of melanoma in dermoscopic images
- Manufacturing: Counting and classifying items on a conveyer belt
- Media: Analyze effectiveness of advertising placement
- Energy: Remote inspection of infrastructure using drones
Summary
This article provided a basic overview of computer vision. You can find out more about using IBM Maximo Visual Inspection for no-code computer vision for inspection automation.