Article
Introduction to Kubernetes Operators
What they are, what they do, and how they can make your life easierManaging Kuberentes resources is complex. Kubernetes Operators are a way to simplify the process by automating deployment and lifecycle management tasks of software assets.
This article discusses what Kubernetes Operators are, what they do, and key features including the Operator SDK, Operator capability levels, and Operator Hub. You will learn all of the basic knowledge you need to develop an operator that's implemented using Golang.
Prerequisites
This article assumes you want to learn basic concepts about Kubernetes Operators and the steps needed to develop a Golang-based operator to manage Kubernetes resources. So you will need:
- A basic understanding of Kubernetes concepts and how to install a workload
- Little to no knowledge about Kubernetes Operators concepts
- Little to no experience developing operators
Estimated time
This article should take roughly 15-30 minutes to complete.
What are Kubernetes Operators?
Operators are extensions to Kubernetes that use custom resources to manage Kubernetes applications and their components. Operators automate software configuration and maintenance activities that are typically performed by human operators.
While Kubernetes is great at managing stateless applications, operators are useful when you need more complex configuration details for a stateful application such as a database. An operator can also automate other more complex lifecycle management tasks such as version upgrades, failure recovery, and scaling.
Why does Kubernetes need operators?
Kubernetes needs operators to automate tasks that are normally performed manually by IT operations personnel. A stateful workload is more difficult to manage than a stateless workload. The state in a workload changes how a workload:
- Is installed
- Upgrades to a new version
- Recovers from failures
- Needs to be monitored
- Scales out and back in again
The operator takes care of everything that's needed to make sure the service keeps running successfully. An operator makes its service more self-managing, enabling an application team to spend less effort managing the service so that it can spend more effort using the service.
Operator components
Operators extend the Kubernetes control plane with specialized functionality to manage a workload on behalf of a Kubernetes administrator. An operator includes these components:
- A custom resource definition (CRD) defines a schema of settings available for configuring the workload.
- A custom resource (CR) is the Kubernetes API extension created by a CRD. A custom resource instance sets specific values for the settings defined by the CRD to describe the configuration of a workload.
- A controller is customized for the workload and configures the current state of the workload to match the desired state that's represented by the values in the CR.
Operators have the following features:
- The user provides configuration settings within a CR, and then the operator translates the configuration into low-level actions using the operator's custom controller logic to implement the translation.
- An operator introduces new object types through its custom resource definition. These objects can be handled by the Kubernetes API just like native Kubernetes objects, including interaction via Kubernetes client tools and inclusion in role-based access control policies (RBAC).
The Red Hat article What is a Kubernetes operator? provides more details about operators.
What do operators do?
In Kubernetes, controllers in the control plane run in a control loop that repeatedly compares the desired state of the cluster to its current state. If the states don't match, then the controller takes action to adjust the current state to more closely match the desired state.
Similarly, the controller in an operator watches a specific CR type and takes application-specific actions to make the workload's current state match the desired state as expressed in the CR.
This diagram illustrates how the control plane runs the controllers in a loop, where some controllers are built into Kubernetes and some are part of operators:
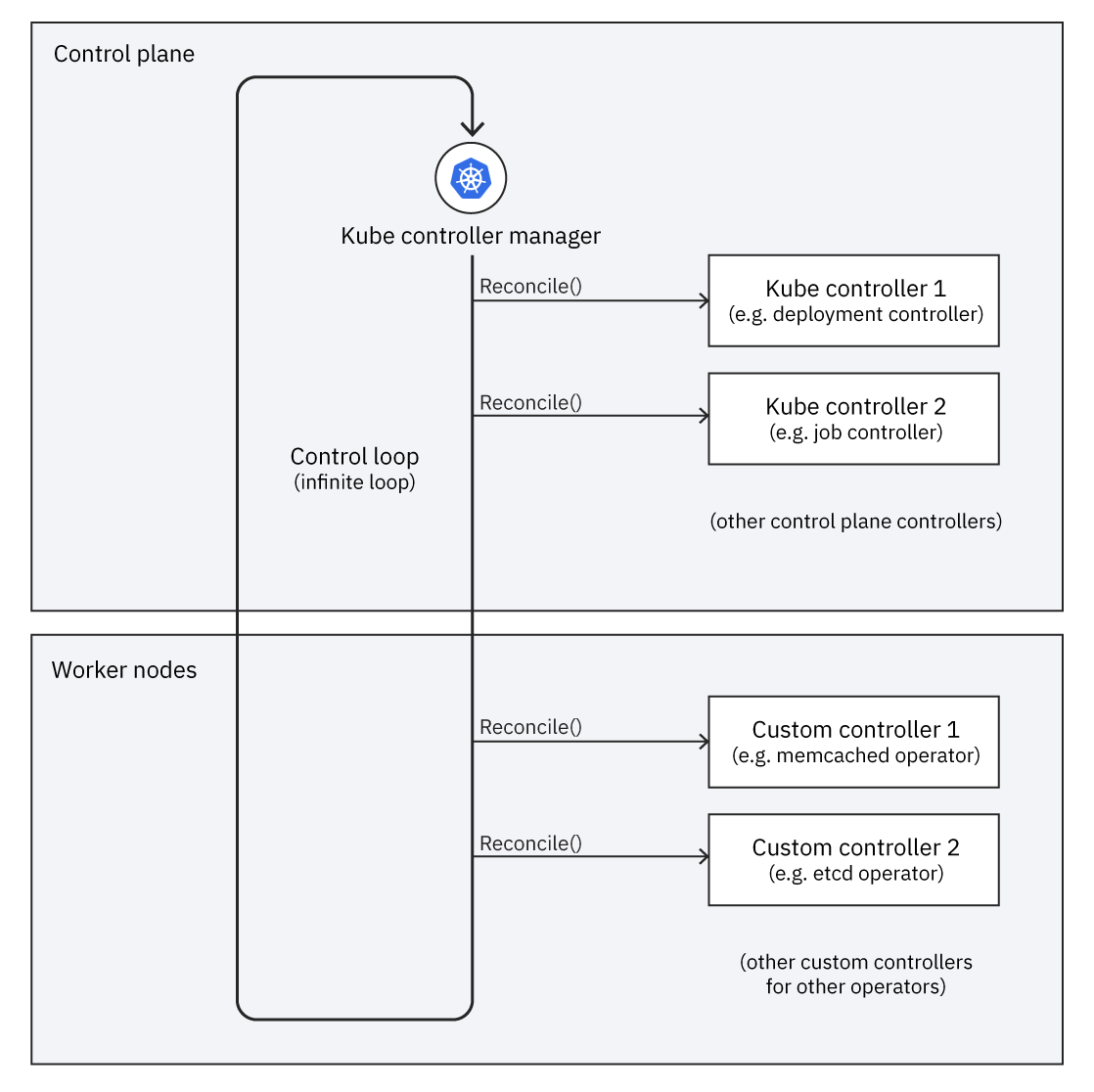
The controllers in the control plane are optimized for stateless workloads, and one set of controllers works for all stateless workloads because they're all very similar. The controller in an operator is customized for one particular stateful workload. Each stateful workload has its own operator with its own controller that knows how to manage this workload.
How do I use an operator?
To use an operator, you must first deploy the operator as a workload in your cluster. You can deploy it like any other workload, via the Kubernetes CLI or using a Helm chart. Additionally, you can make use of Operator Hub or deploy your operator through the Operator Lifecycle Manager.
Operator technologies
Operators are usually implemented in one of three main technologies: Go, Ansible, or Helm.
- Go: Code written in Go is powerful and can do almost anything Kubernetes can do. Kubernetes itself is implemented in Go, so operators implemented in Go are a good fit.
- Ansible: Ansible is a good choice for infrastructure teams that have already written Ansible modules. Ansible is declarative and human-readable, and can express almost as much functionality as Go.
- Helm: Helm operators are simpler to implement, but functionality is limited to Helm features.
This learning path uses Go to implement a Kubernetes operator, because 71% of operators from OperatorHub.io are written in Go. And because Kubernetes itself is written in Go, this makes it much easier to write the operator that interacts with the Kubernetes API.
You can read more about the pros and cons of each approach in Build Your Kubernetes Operator With the Right Tool. The Operator SDK supports all three technologies.
Operator SDK
The Operator SDK is a set of open source tools for building, testing, and packaging operators. The SDK CLI enables you to scaffold a project, and also provides commands to generate code. The SDK uses Make, a build automation tool that runs commands configured in a makefile to generate executable code and libraries from source code.
The SDK includes pre-built Make commands that you can use to develop your operator, such as:
make manifests-- generates YAML manifests based onkubebuildermarkersmake install-- compiles source code into executablesmake generate-- updates the generated code based on an operator's API schemamake docker-build-- builds the operator's Docker container imagemake docker-push-- pushes the Docker imagemake deploy-- deploys all of the operator's resources to the clustermake undeploy-- deletes all of the operator's deployed resources from the cluster
These commands in the SDK greatly simplify implementing an operator.
Operator Lifecycle Manager
The SDK also enables you to install the Operator Lifecycle Manager (OLM) using the operator-sdk olm install command. The OLM is a set of cluster resources that manage the lifecycle of an operator. Once it is installed, you can get the status of the OLM using operator-sdk olm status, which verifies whether the SDK can successfully communicate with the OLM components in the cluster.
Additional Operator SDK concepts
In addition to operator, custom resource, and custom resource definition, you need to understand what we mean by the Operator SDK operand and managed resources:
- Operand -- the managed workload provided by the operator as a service
- Managed resources -- the Kubernetes objects or off-cluster services that the operator uses to constitute an operand (also known as secondary resources)
Operator Capability Levels
Some operators are more sophisticated at managing their operand's lifecycle than others. The Operator Capability Levels model defines five levels of sophistication, as illustrated here:
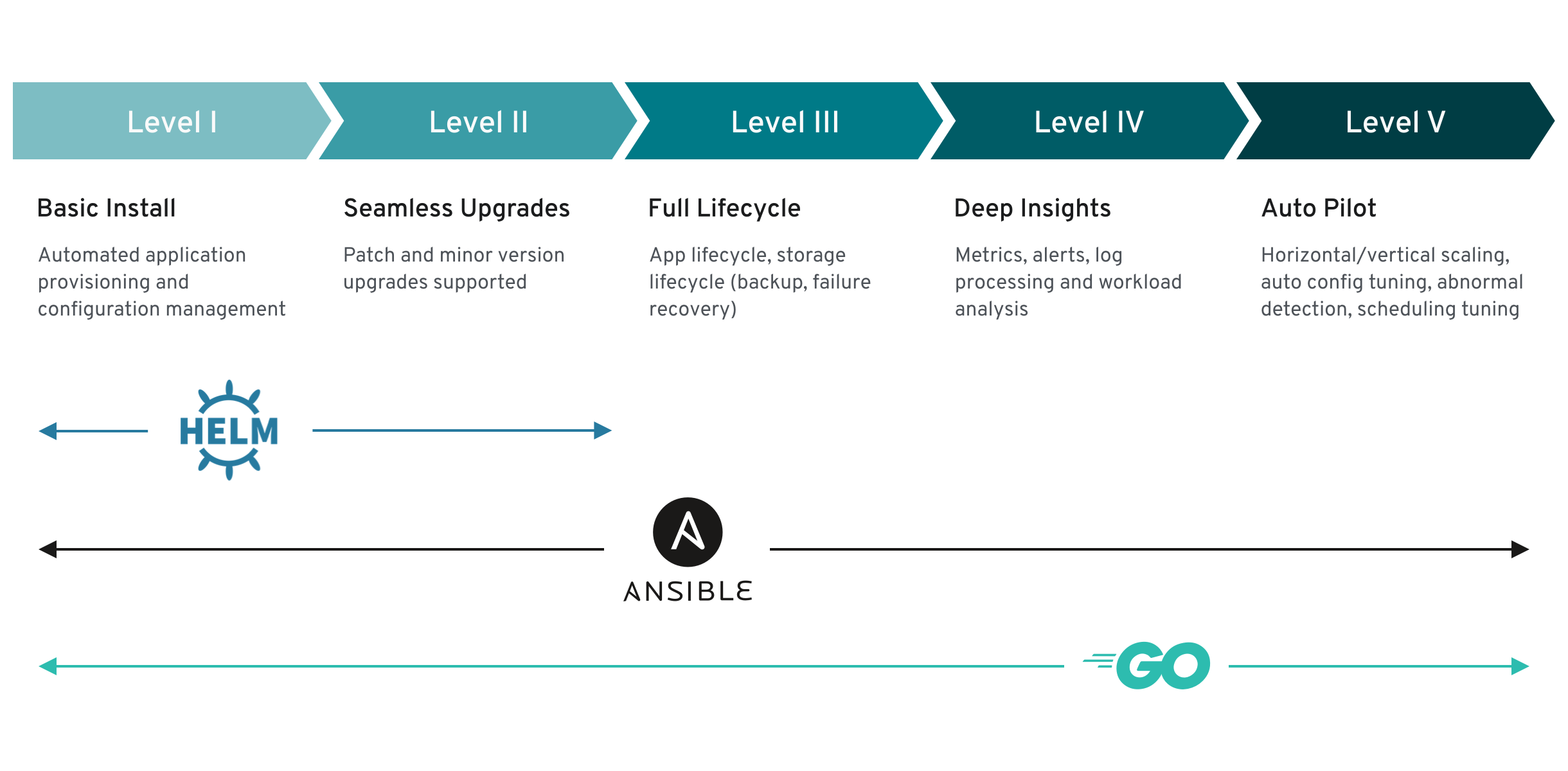
This model aims to provide guidance for the features that users can expect from a particular operator. As the picture shows, you can only use Ansible and Go to achieve all five capability levels. Helm can only be used to achieve the first two levels.
Note: Capability levels build on top of one another. That means if an operator has level 3 capabilities, then it should also have all of the capabilities required from levels 1 and 2.
Let's examine the capabilities of a level 1 operator in more detail.
Operator Capability Level 1: Basic install
In level 1, your operator can provision an application as described by a CR, which specifies all of the configuration details. Avoid making the user create and manage configuration files outside of Kubernetes -- that's what the CR is for.
Level 1 example: Install the operand
When a custom resource is created, that triggers the operator, which responds by creating and installing the operand. If the custom resource is deleted, then the operator removes the operand.
To install an operand, the controller creates the managed resources for that operand and installs them, which causes the cluster to install the operand. These managed resources are typical Kubernetes workload kinds such as a Deployment and a Service, as well as other kinds like a ConfigMap, a Secret, and a PersistentVolumeClaim.
You can specify the configuration of these managed resources in the custom resource's specification (that is, the spec section of its YAML); we cover this in greater detail in the next article.
A simple controller may simply copy values out of the CR's specification and into the appropriate fields of the managed resources, possibly transforming the values as needed. Once the cluster installs the operand, the controller gathers the status of those managed resources and updates the custom resource's status (that is, the status section of its YAML); we cover this in greater detail in our next article. Status is how the CR remembers the managed resources that were created for its operand.
Level 1 example: Manage the operand
Assuming you want to increase the capacity of the operand, how would you do this using an operator?
You can do this by updating the custom resource's specification -- perhaps it has a size setting and you increase it. When you update the custom resource's specification, you are specifying a different configuration for the operand. The controller notices the changes in the custom resource and responds by changing the configuration of the managed resources -- perhaps to increase the number of pods or to create new persistent volume claims.
Once the controller applies these changes to the managed resources, the cluster responds by applying them to the operand, thereby scaling the operand.
This article only covers the first of the capability levels, but you can read more about the other four Operator capability levels in the Operator SDK documentation.
Operator Hub
OperatorHub.io is a web-based application that enables you to find, install, and publish operators. It is a one-stop shop for Kubernetes operators, as shown below:
Check out How to contribute an Operator for details of how to package, test, preview, and submit your operator for addition to the Hub.
Summary
In this article, you learned how operators can extend the base Kubernetes functionality using custom controllers and custom resources. You also learned that the Operator SDK offers code scaffolding tools to enable you to write your operator more easily, and offers guidelines for the capability levels of an operator. Lastly, we introduced you to OperatorHub.io where you can browse existing operators and submit your own.
The next article, Use operators to extend Kubernetes' functionality, takes a closer look at the Kubernetes architecture that enables operators to work.
If you would rather go straight to developing an operator, check out the tutorial Develop and deploy a Memcached Operator.