Article
Attesting Istio workload identities with SPIFFE and SPIRE
Strengthen service identities with SPIREArchive date: 2024-02-13
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Enterprises that are considering moving their workloads to the cloud are often concerned that their data might end up in the hands of unauthorized parties. The research team at IBM is exploring various ways to minimize data leakage.
In this blog post, we demonstrate one aspect of our work related to stronger service identities where the aim is to restrict connectivity between pods by basing service identities on the running application code. We demonstrate our approach by using the Istio Service Mesh and by using SPIRE as the component that issues service identities to workloads. The code to reproduce our work is available in github.com/IBM/istio-spire.
What are Istio service identities?
When an application runs within a service mesh environment, each service is provided with an identity. This identity is used when connecting to other microservices running in the service mesh. Service identities enable mutual authentication of services to validate that a connection is allowed and to enforce authorization policies.
When Istio is run on top of Kubernetes, Istio provisions a service identity to each workload; this identity is based on the Kubernetes service account token of the workload.
Service identities in Istio conform to the SPIFFE standard and have the following format:
spiffe://<trust-domain>/ns/<namespace>/sa/<service-account>
Why the current Istio mechanism is not enough
Istio service identities are based on Kubernetes service accounts alone. In many cases, this works well: Your organization's administrators correctly set up namespaces, service accounts, and RBAC policies. Doing so restricts which users may deploy to which namespaces. The service teams deploy their services such that the right code gets deployed with the right service account to the correct clusters in the right geo-location and on the right hardware.
But what if something was misconfigured? Or what if someone has maliciously altered the deployment pipeline? Let's consider the following example to see some of the things that could go wrong with such a trust model.
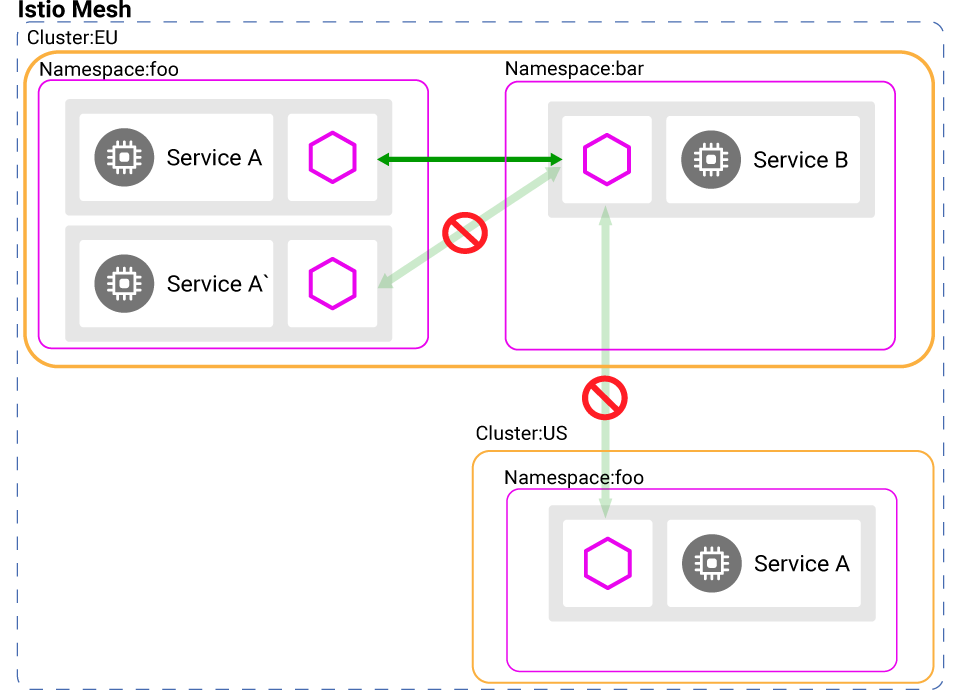
A service team develops a data service B that is connected to an enterprise's data. A fraud detection service A is a client of service B. Let's assume that we trust the setup of B and that of the authorization policies set to ensure that only pods with the identity of service A can connect to service B.
Policies such as General Data Protection Regulation (GDPR) may require that service B would only be used for fraud detection. At some point, a member of service team A is tasked with a completely separate effort to develop a marketing model. He decides that his model could benefit from some data that service B can provide. So, he runs an impersonated service A' (with different code) using the same service account as A, extracts some data and deletes his A' service instance. No harm done, right? Except that by now data that was forbidden from being used for marketing has been leaked. Similarly, an external attacker might alter the images of service A to perform malicious activity. To block such attacks, we require identities to be provided only after attestation of the code that is executed in the pod.
Policies may also require that service B and all the services connected to it must run in the European Union (EU) region. They may also require that those services must use specific hardware, for example, hardware components that support full memory encryption. At some point, the service mesh operator decides to expand the mesh to more clusters and regions. He configures a basic cluster in the United States (US) to be part of the same service mesh trust domain. The service team of service A happily deploys to all clusters to improve the availability of their service. However, now service A breaks the regulation policies by processing data outside of the EU. To block such scenarios, we require identities to be provided only after attestation of the node that the pod executes in, including the geo-location of the node.
The need for stronger service identities is not limited to service meshes. In a previously published blog, the authors introduce a project that brings elements of Trusted Computing, such as hardware root-of-trust and attestation, into the world of service identities. The use case described there involves secrets management. Our aim was to investigate a similar approach but with a focus on support for service mesh identities (x509 certificates).
Enter SPIRE
SPIRE is an open-source implementation of the SPIFFE APIs (federation included). SPIRE performs node and workload attestation in order to securely issue identities to workloads.
SPIRE supplies a broad and extendable set of selectors. It provides both a set of built-in plugins and a mechanism to use external plugins. These allows administrators to configure SPIRE to issue identities based on a multitude of conditions. Workloads could be attested based, for instance, on a combination of Kubernetes properties and conditions based on metadata values from a public-cloud system.
We use SPIRE to issue the same SPIFFE identities that would have been issued by the Istio identity mechanism. However, these identities are now being issued only after an attestation process has taken place, ensuring that all required conditions match. When conditions are not met, identities are not issued. In a Kubernetes environment, this allows us to issue identities based on the container images. We imagine future extensions to SPIRE to support attesting geo location, hardware attributes, Integrity Measurement Architecture (IMA) measurements, etc.
Our journey connecting SPIRE to Istio
In Istio, the proxy sidecars receive their identities through a UNIX Domain Socket (UDS) that they share with an Istio agent running in the same container. When replacing the Istio identity-issuing mechanism with that of SPIRE, we first configured the sidecars to communicate with the UDS of the SPIRE node agent instead of the Istio agent UDS. We did this by changing the proxy configuration. Once we achieved that, all that was left was to make changes to the SPIRE code to support the proxy sidecar configuration which is automatically generated by Istio. These changes were approved and merged into the SPIRE repository.
As shown in the figure below, the result is an architecture similar to Istio citadel, used in previous Istio releases. But we now use SPIRE to perform node attestation and PID-based workload attestation. The Istio agent does not participate in identity provisioning.

Let's take a more detailed look at our work. The first step was to take the directory in which the SPIRE UDS resides and to mount it to each sidecar. We did that by making small changes to the mount options in the YAML files that are used to customize the Istio installation. A more challenging task was to change the Istio Envoy proxy configuration to point to the SPIRE UDS instead of the Istio UDS. This was done by making a minor change to the envoy_bootstrap_tmpl.json file in the Envoy proxy docker image. This JSON template file is used to generate the sidecar Envoy configuration. We did not need to change any of the envoy code.
So far, we mounted the SPIRE UDS and changed the Envoy configuration to point to it. But we were not quite finished.
Until recently, the Envoy configuration that was automatically generated by Istio was not SPIRE-friendly. SPIRE code did not support generic names for the validation context resources. For instance, suppose that the SpiffeID of your cluster is spiffe://cluster.local. SPIRE worked properly if the Envoy configuration named the validation context spiffe://cluster.local, but did not work at all if Envoy configuration named it ROOTCA (that was the case in the Envoy configuration which was automatically generated by Istio). We addressed this issue by making small changes to the SPIRE code, which were recently merged into the SPIRE repository.
Now that SPIRE can issue identities to workloads running in an Istio service mesh, let’s see what can be done with this capability.
We wanted to issue identities that are based on the set of container images running in the service, rather than solely on service accounts. In an Istio deployment, a typical Istio pod has two containers, one of which is an Envoy proxy. The Envoy proxy requests its identity, since Envoy is tasked with establishing mutual Transport Layer Security (mTLS) connections. If you configure SPIRE to issue identities based on the container image, SPIRE would give all workloads the same identity — the identity assigned to the Envoy container image. It would be more valuable to identify the workload as, for example, “Envoy running in a pod alongside the web-server container”. We have contributed code to the SPIRE project to do just that by adding additional selectors to the SPIRE Kubernetes workload attestor plugin.
What's next?
The use of SPIRE does come with a few caveats. SPIRE identities must be registered in the SPIRE server beforehand. A Kubernetes Workload Registrar is available, but it follows the Istio model of basing identities solely on service accounts. An additional caveat is that securing the SPIRE node agent UDS with pod security policies is needed (as was done in older Istio releases); however, this can probably be automated.
We demonstrated that SPIRE can be used as the identity and certificate manager in Istio. While our approach is ad-hoc, it shows that this is indeed possible. The code to reproduce the work described in this blog post is available in github.com/IBM/istio-spire.
We hope that this work will inspire a complete solution to install Istio with SPIRE. We welcome contributions and are working with the Istio and SPIRE communities to advance this effort.