Article
Where does Kafka fit in a reactive architecture?
Using Kafka for asynchonous messaging in a reactive systemArchive date: 2025-09-24
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.As laid out in our "Getting started with Reactive systems" article, the term reactive systems refers to systems that are flexible, loosely-coupled, scalable, and highly responsive. To achieve this state, applications must exhibit elasticity, resiliency, and responsiveness through a backbone of asynchronous, non-blocking communication. This asynchronous communication helps to establish a boundary between components that ensures loose coupling, isolation, and location transparency.
Non-blocking communication allows recipients to only consume resources while active, leading to less system overhead. Employing explicit message-passing enables load management, elasticity, and flow control by shaping and monitoring the message queues in the system and applying backpressure when necessary.
Apache Kafka is a great tool that is commonly used for this purpose: to enable the asynchronous messaging that makes up the backbone of a reactive system. If you're new to Kafka, check out our introduction to Kafka article. But where does Kafka fit in a reactive application architecture and what reactive characteristics does Kafka enable?
In this article, we'll take a look at the key underlying behaviors that enable the qualities of reactive applications and examine where Kafka fits in.
Asynchronous messaging backbone
Arguably the most important underlying behavior that enables the other qualities of reactive applications is having an asynchronous messaging backbone of communication. But what does this mean?
A message is usually defined as "An item of data sent to a specific location." So, in reactive systems, message-driven communication centers around messages being sent to relay data between the components of the application. Message-driven architectures enable a more asynchronous, stream-orientated approach, where data can be processed as it arrives.
Apache Kafka is a distributed streaming platform that can be used as this message-driven backbone of communication. Applications can send messages between its components in the form of records that can be produced to Kafka topics and consumed from Kafka topics.
Resiliency
Applications in reactive systems are expected to be able to gracefully handle potential failures in the system. This behavior is known as resiliency. This behavior enables applications to be able to recover from outages, enables decoupling between application components, and encourages the use of backpressure within reactive applications.
Message retention and data persistence
Kafka is different from message queuing systems in that it provides stream history. When a consumer reads a record from Kafka, the record is not removed from the topic and both that consumer and other consumers can re-consume the record at a later time. This stream history is useful for enabling consuming applications to recover from a failure.
The consumers store their location within the stream in Kafka in the form of offsets, and can resume consuming from where they left off if they go down.
The stream history within Kafka allows applications to use the in-built Kafka features to recover from failures that occur mid-processing, rather than requiring the application to use an additional persistence store to recover from failure.
Decoupling
Introducing decoupling between components of a system makes an application more resilient as it allows failures to be localized. If components in an application are closely coupled, an error in one component will affect the other components. When components are successfully decoupled, these cascading failures are prevented and the error is contained to the original component.
Achieving decoupling relies on the applications being written to handle unresponsive services and have sensible fallback behavior. This kind of behavior can often be handled by application libraries like MicroProfile or platforms like Istio.
Using Kafka as the communication mechanism between components is a good way to introduce further decoupling. If a producer goes down, the consumers can carry on consuming the existing records without encountering an error. Similarly, consumers can be added and removed from a topic without needing to change the producing application.
When writing a set of microservices that communicate using Kafka, you must consider the shape of the records being sent and received. If a producer changes the shape of records being produced, this change could break consumers and implies that there is still coupling. To remove this coupling, it is recommended to use schemas and a schema registry.
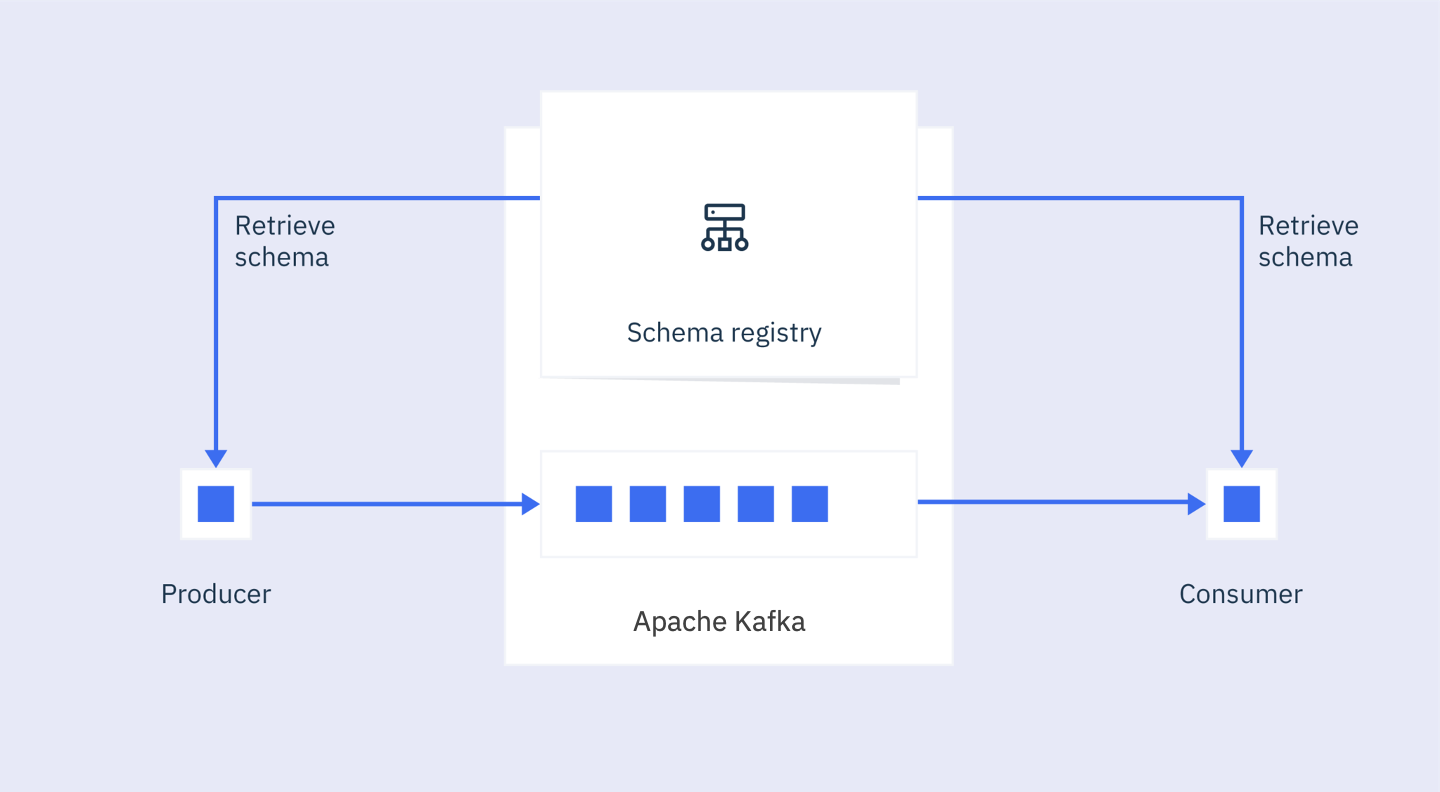
A schema defines the structure of the data in a record and a schema registry is used to store the schemas. There are various open-sourced and vendor-provided schema registries for Apache Kafka. Many schema registries also provide features like validation and compatibility verification to make sure producers and consumers can easily upgrade to new versions of a schema.
IBM's supported Apache Kafka offering, IBM Event Streams supports schemas and includes a schema registry for using and managing schemas. To learn more about what schemas and schema registries are, visit our documentation.
By using a messaging backbone like Kafka, components are decoupled. And, when combined with fault tolerant applications, Kafka enables the system to have greater resiliency.
Backpressure
Backpressure is a useful pattern when implementing reactive systems because it helps applications to gracefully handle potential bottlenecks, prevents resources from becoming overwhelmed and enables greater resiliency of a system under load. The backpressure pattern consists of a feedback mechanism that allows consumers to inform upstream components when they are ready to handle new messages, preventing them from becoming overwhelmed or stressed.
In TCP/IP, backpressure is normally achieved by having separate send and receive buffers and data only being sent between them when there is available space in the receive buffer. Rather than using a receive window and requesting data only when the downstream component has space, Kafka can be introduced as a sort of infinite buffer, since messages are persisted. In applications that only integrate with Kafka and have relatively simplistic processing within consuming applications, this almost infinite buffer-like behavior can remove the requirement for backpressure. However, this does not work for all use cases, and therefore some level of backpressure is often required in systems that use Kafka. In this section we'll explore the various backpressure strategies that can be implemented through the reactive Java Kafka clients. However, very few, if any, of these libraries provides full end-to-end backpressure that will trigger producers to stop sending records to Kafka. Although individuals within the community have experimented with such a mechanism, most use-cases can be fulfilled by simply using backpressure within the consumer.
Backpressure in Kafka Consumers
The standard Java Kafka Consumer client can be used in an application to handle short, unexpected fluctuations in load without becoming overwhelmed. Kafka consumers are pull-based so they request new messages using a poll method. This pull-based mechanism of consuming allows the consumer to stop requesting new records when the application or downstream components are overwhelmed with load.
In the simplest use-case, backpressure is enabled by only polling for new records when all previous records have been processed:

- Synchronous call to poll, in while loop, blocks until records are received
- Then records are processed.
- Once all records have been processed, the code can then restart the loop to call poll again (consumer is ready to process some more)
This mechanism of consuming works well for simple use cases that can be modeled as a single loop, in a single thread, and where processing is fairly quick. However, it doesn't allow for the processing to be distributed (parallelized) across multiple threads to better use resources within the consumer application.
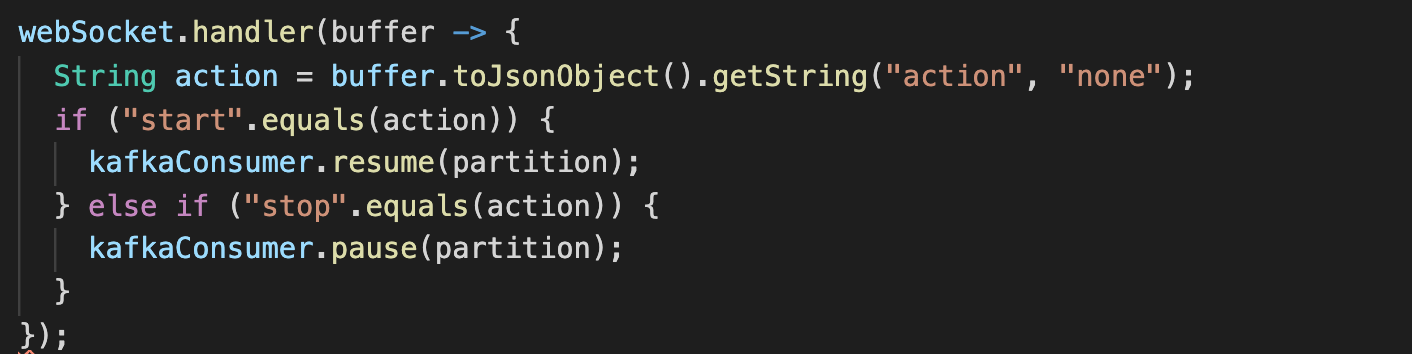
Most reactive Java Kafka clients provide a separation between polling and processing to enable better resource utilization. These clients do this by either stopping the poll loop or using a combination of the "pause" and "resume" functions provided by the standard Java Kafka client when backpressure is required.
The "pause/resume" functions allow a consumer to continue polling Kafka but without receiving new records. This is beneficial because Kafka has a configurable timeout for subsequent polls and exceeding this timeout will result in consumers being removed from the consumer group. Note this timeout is separate to the heartbeat timeout that is used to inform Kafka if a consumer application has crashed. This also allows the consumer to continue responding to consumer group rebalance events.
Backpressure in Alpakka Kafka Connector
The Alpakka Kafka connector is a reactive Kafka client that is built on top of Akka Streams. It handles all poll requests to Kafka, enabling the application code to request new records using the standard Akka Streams backpressure mechanism. This mechanism is implemented according to the Reactive Streams specification and works on the basis that an application is split into stages, where downstream stages advertise to their upstream stage when they are ready to receive more data.
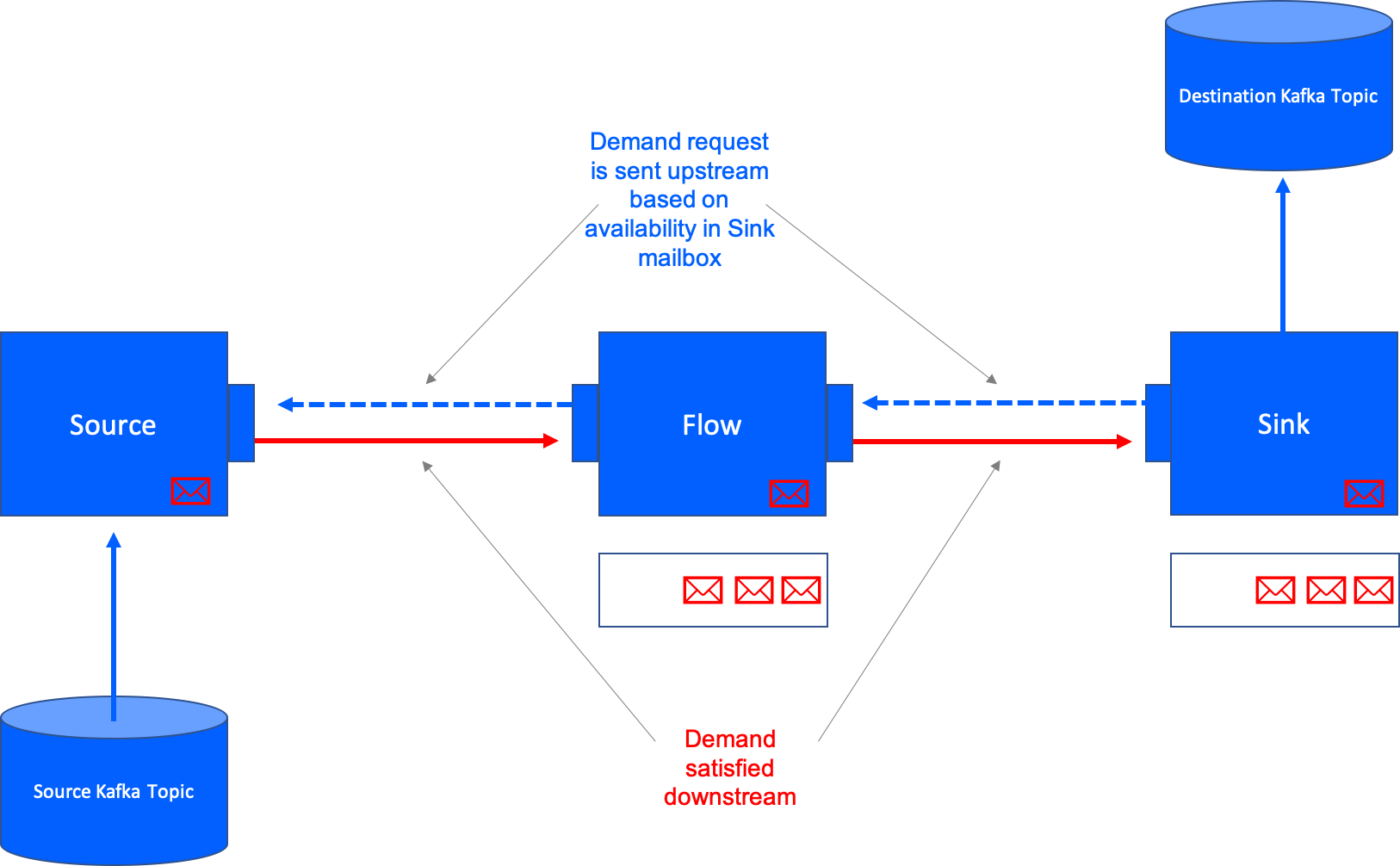
This approach to backpressure will be familiar to developers who have previously used Akka Streams within their applications. However, this does require a learning curve to understand the syntax and fully grasp the paradigm shift of adopting the actor model that is used within Akka.
Backpressure in MicroProfile Reactive Messaging
MicroProfile Reactive Messaging is another reactive library. It provides a specification for asynchronous communication based on the Reactive Streams specification and the MicroProfile Reactive Streams Operators specification. MicroProfile Reactive Messaging uses methods annotated with @Incoming or @Outgoing that are connected up through channels, either in the form of internal calls or external connectors to messaging systems (for example, a Kafka connector).
Backpressure in MicroProfile Reactive Messaging works in a similar way to Akka, where the flow to downstream components is controlled based on those components making requests for data. The specification allows for the following example flow:
@Incomingannotation using a Kafka Connector@Outgoingannotation using a database Connector- The database Connector becomes unable to continue producing
- As a result, the Kafka Connector stops requesting new records
As MicroProfile simply defines a specification, there are multiple different available implementations, including OpenLiberty, Quarkus, and SmallRye Mutiny. The individual implementations of MicroProfile may interpret this backpressure request in different ways, for example, by using the resume and pause functions or by simply stopping the poll loop.
Backpressure in Vert.x Kafka Client
Vert.x is a reactive toolkit for applications running on the JVM. It also includes a Kafka client. This client gives the most flexibility regarding its approach to backpressure.
It provides tools for separating polling from processing and gives developers the choice to either let Vert.x handle the poll loop and use pause and resume functions or to handle the poll loop themselves.
For an example of using the pause and resume functions within a Vert.x application, see our sample application on GitHub or see our tutorial "Experiences writing a reactive Kafka application".
There are a few different reactive libraries that build on top of Vert.x, so if those libraries do not fulfill your requirements or you need more control over the backpressure behavior in your application, Vert.x might be the best option for you.
Backpressure in Kafka
Kafka can be used as a buffer to allow the processing speed of consumers to fluctuate without affecting the producers. If using Kafka as a buffer is not enough for your use-case there are various mechanisms you can use to add backpressure to your consumers. These range from using the provided Kafka Consumer client, all the way to libraries that integrate with wider reactive frameworks.
Elasticity
Reactive systems should be designed to be responsive under fluctuating load. This can be achieved by creating a system that is elastic. Elastic means that it can react to changes in the input rate by increasing or decreasing resources accordingly.
Elasticity allows applications to take advantage of the promises of cloud computing: allowing systems to be resource efficient, cost-efficient, environmentally-friendly, and pay-per-use.
When scaling applications that communicate using a message backbone, the producers and consumers can be scaled up and down to react to fluctuating load. However, particular care must be taken by the messaging system to make sure individual instances of a consumer receive unique messages.
Kafka uses partitions to allow load to be distributed across different brokers, making it easy to scale up and down the number of producers. When it comes to consuming, Kafka works differently to traditional message queuing systems. In traditional message queuing systems, adding a new consumer requires a new copy of the data to be created. In Kafka, records are persisted and consumers can read from anywhere in the stream.
Kafka uses a concept called consumer groups to allow a set of applications to spread the load of consuming between them without needing to create new copies of the data. The number of consumers in a group that can actively receive records from a topic is limited to the number of partitions in that topic. As adding new partitions does increase overhead when consumers join and leave, it is advisable to take care in defining the most appropriate number of partitions.
The fact that Kafka does not require topics to be duplicated when new consumers are added, combined with the consumer group mechanism, means that Kafka really is built to handle large numbers of consumers. This elasticity makes it a great choice for applications that are expecting to scale based on load.
Although Kafka is designed to deal with large workloads, you might find a need to increase the number of brokers in your cluster or partitions in your topics. Whether you are increasing these resources or not, you should pay attention to how load is distributed across your cluster. For example, make sure that leadership of partitions is spread out across brokers and consumers are spread across partitions. There are scripts that can be used to do this, and they are included in a download of Kafka (e.g. kafka-leader-election.sh and kafka-reassign-partitions.sh), however you can also use technologies like cruise control.
Summary and next steps
Using Kafka as part of your application does help to make the system more reactive. The stream history that Kafka provides, combined with the consumer group feature, enables applications that rely on Kafka for data to be more resilient and elastic. By using a publish-subscribe mechanism, Kafka also provides decoupling and can act as a buffer for reactive systems. However, like any other messaging system, the applications are still coupled by the shape of the messages they exchange and using Kafka as a buffer will not work for all use cases. Kafka is also very configurable, and because it is a distributed platform it needs to be managed and configured correctly.
Fortunately, the Kafka community is very active and so there are plenty of options when it comes to libraries and tools to fill these gaps and these options complement the reactive capabilities that Kafka provides. These tools include:
- Schema registries like Apicurio
- Libraries like MicroProfile Reactive Messaging
- Connectors like Alpakka Kafka connector
- Tools like cruise control.
Overall Kafka is a great asynchronous messaging tool for use in reactive systems, but it is only a small part of the bigger picture that you must consider when designing and building a reactive system.
Ready to get started? Try this two-part tutorial, "Reactive and event streaming app development with Apache Kafka and Java."