Article
Transfer learning for deep learning
Repurpose models for new problems with less data for trainingIn the early days of AI, a common problem was the lack of general intelligence. Models could be built to do things like play checkers, but the knowledge encapsulated in that model was restricted to that domain. This problem is being explored today under the name transfer learning -- with the goal of building a model that can be applied to multiple related problem areas.
Transfer learning
Since the introduction of deep learning, there's been a renewed interest in neural networks for a range of applications. Deep learning has solved problems viewed as impossible not more than a decade ago. But deep learning neural networks require large clusters of compute servers, large amounts of training data, and a large amount of time to train the deep neural network.
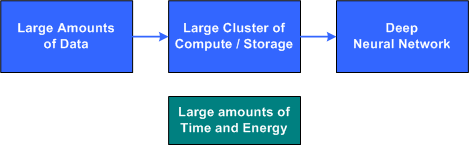
Figure 1. The problem with deep learning from scratch
The deep neural network is represented by tens of millions of weights that connect the many layers of neurons of the networks together. These weights (typically real values) are adjusted during the training process and applied to inputs (including inputs from intermediary layers) to feed forward to an output classification. The basic idea of transfer learning is then to start with a deep learning network that is pre-initialized from training of a similar problem. Using this network, a smaller duration of training is required for the new, but related, problem.
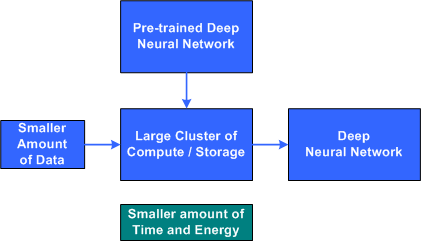
Figure 2. Transfer learning with a pre-trained network
Transfer learning is the method of starting with a pre-trained model and training it for a new -- related -- problem domain. The pre-trained network serves as transferred knowledge to be applied in another domain. But there are numerous options that can be used, including feature transfer and fine-tuning (which depend upon the similarity of the problems at hand), in addition to freezing certain layers of the network and retraining others.
Why is this so important?
Transfer learning is an important piece of many deep learning applications now and in the future. This is predominantly due to the scale of training production deep learning systems; they're huge and require significant resources.
A recent paper from the University of Amherst found that in a production deep learning application focused on natural language processing, there were more than 200 million weights required to be trained with the available training data. Training a network of this size with a network of graphical processing units (GPUs) emitted the same amount of CO2 as five average U.S. vehicles over their individual lifetimes.
The energy consumed in training the network also paralleled two roundtrip flights between New York and San Francisco (200 passengers each). You can read more in "Energy and Policy Considerations for Deep Learning in NLP."
Given this cost, it's important to use these resources in the most efficient way possible. Transfer learning is an opportunistic way of reducing machine learning model training to be a better steward of our resources.
Generality
The key to transfer learning is the generality of features within the learning model. The features exposed by the deep learning network feed the output layer for a classification. The ability to reuse these features means that the trained network can in some form be repurposed for a new problem.
Consider a network that is able to differentiate between ripe apples and rotten apples. Even though pears are different in shape, the features that identify rot within the fruit could be shared. These features could represent the texture of the fruit (smooth, wrinkles, or bumps), whether uniform color or with blotches or lines, etc. As illustrated by this example, the generality of the features would support the ability to reuse a network trained on one fruit for another.
Another important driver for transfer learning is around training data. Consider that for apples an organization can train a network to differentiate between fresh and rotten apples, but that same organization lacks sufficient data for pears. In this case, the deep learning model could be trained using the apples data set and then be updated using the smaller pear data set.
Methods for transfer learning
There are a number of methods for transfer learning, and in this section, we'll explore some of the most important.
Feature transfer
One of the most straightforward methods of transfer learning is called feature transfer. But before we dive into this method, let's look at how it's applied.
Recall that in deep learning, the network is made up of many layers. These layers are important because deep learning is a layered architecture that learns different features at different layers. Figure 3 illustrates a sample deep learning network made up of many layers, but three distinct categories of layers. In this application, the network accepts a 3-D image (width, height, and depth for the color). This constitutes the input layer, mapping the input to the subsequent layer. Next is the feature-extraction layer, which can have many internal layers consisting of convolutions (which map spatially located neurons from the prior layer through a set of weights to the output) and pooling (which reduce the spatial size of the outputs of the convolutions), in addition to other functions. The output of the feature extraction layer are "features" that can represent features from the image (such as a wheel) and can then be used hierarchically to translate to higher-level features. The final classification layer pulls together the features found within the feature-extraction layer and provides a classification. For example, does the input image represent a car or a motorcycle? Each are made up of differing features, which the classification layer translates into an output.
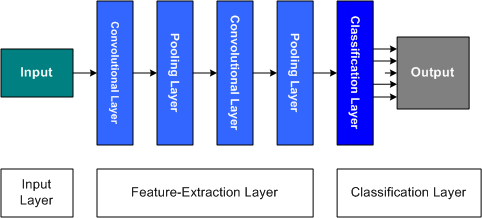
Figure 3. Simple deep learning network illustrating the basic layers
Note here that the classification layer is responsible for determining the object from the image as a function of the detected features. The idea behind feature transfer is then to use the input and feature-extraction layers that have been trained with a given data set (with their weights and structure frozen) and train a new classification layer for the related problem domain. In this way, a deep learning network used to detect cars in an image could be have a newly trained classification layer to detect bicycles. This method is ideal if the two problem domains are similar.
Fine-tuning
In the prior example of feature extraction, we introduced a new classification layer (along with training) and froze the prior layers of the deep learning network. A simple alternative is to introduce a new classification layer, but then fine-tune the prior layers through additional training using the new training data set.
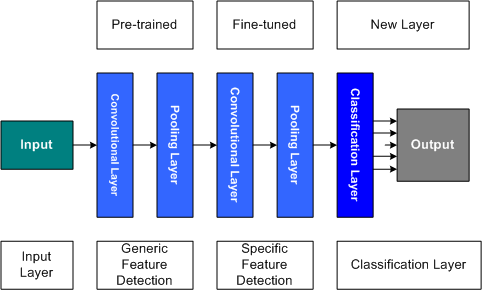
Figure 4. Fine-tuning the specific feature extraction layers
This fine-tuning could mean that we train the later layers of the deep learning network (meaning adjust the weights based upon the classification error) while leaving the earlier layers frozen. In this way, we fine-tune the layers that are more specific to features of the classification task (compared to earlier layers, which are more generic). This method is ideal when the problem domains have some distance, requiring new features to be classified.
Using a pre-trained model
With feature transfer, a model is trained for a problem and reused on a related problem. But another option is to reuse a model trained by a third party. There are many pre-trained models available for use over a variety of platforms and tasks, both common and specialized:
- MobileNet is model-trained on the ImageNet database (covering millions of images with 20,000 classifications) for the Keras neural networks API running on Android, iOS, and others. MobileNet can perform object detection, landmark recognition, and other computer vision tasks like detection of face attributes.
- Object Detection is a TensorFlow model capable of localizing and identifying multiple objects in a single image. This model was trained on a variety of image data sets, including the Open Images Data set V4. It is capable of running on TensorFlow and TensorFlow Lite (for Android platforms).
- Sentiment Discovery is a PyTorch-based sentiment discovery model. This NLP model can identify sentiment of natural language, but also indicate through a heat map the positive and negative elements of text.
- YOLO for TensorFlow++ is a real-time object detection model that is pre-trained to run in real time on mobile devices. It can detect people and other objects in its field of view.
- Lip Reading is a model that can correlate an audio track to a video to properly orient the audio to the video based upon lip reading. The model runs on TensorFlow and uses a coupled 3-D CNN for audio-visual matching.
Using a pre-trained model, the model can be refined through feature transfer (train the classification layer) or by freezing some of the early convolutional layers and retraining the later ones. Given that the early convolutional layers detect general features that can be independent of the problem, retraining (or fine-tuning) the later convolutional layers where features are more specific and dependent on the problem can be useful. This strategy is ideal if the problem domains are similar (with additional work in either feature transfer or in fine-tuning with additional training data).
Advantages of transfer learning
As illustrated in this article, there are a large number of advantages for using transfer learning beyond the potential savings of time and energy. One key advantage exists around the availability of a sufficient labeled training set for your problem domain. When insufficient training data exists, an existing model (from a related problem domain) can be used with additional training to support the new problem domain.
As discussed in feature transfer, a deep learning model implements feature extraction and classification with a smaller neural network topology. Depending upon the problem domain, the outputs (or classification) will commonly differ between two problems. For this reason, the classification layer is commonly replaced and reconstructed for the new problem domain. This requires significantly less resources to train and validate while exploiting the pre-trained feature extraction pipeline.
Challenges of transfer learning
The ideas behind transfer learning are not new, and it has the potential to decrease the work required to build complex deep learning neural networks. One of the earliest issues discovered in transfer learning is called negative transfer. Negative transfer refers to the reduction of accuracy of a deep learning model after retraining (biologically, this refers to interference of previous knowledge with new learning). This can be caused from too high a dissimilarity of the problem domains or the inability of the model to train for the new domain's data set (in addition to the new data set itself). This has led to methods to quantitatively identify similarity of problem domains to understand the potential for negative transfer (in addition to the viability transfer learning between domains).
Going further
As deep learning grows into new applications and into larger and more complex models, the problem of scaling becomes key. You can find transfer learning applied to many problem domains, including natural language processing, audio and video processing, image captioning models, etc. While not a panacea, transfer learning allows you to repurpose models for new problems with less data for training. If you're training a new model for a related problem domain, or you have a minimal amount of data for training, transfer learning is here to save you time and energy.