Blog post
GitOps: Best practices for the real world
What is GitOps and how can it help with day-to-day development and operations?There is a common misunderstanding about how GitOps should be applied in real-world environments. Developers equate Infrastructure as Code (IaC) with GitOps in concept or believe that GitOps can only work with container-based applications — which is not true. In this blog, you will learn what GitOps is and how to apply its principles to real-world development and operations.
What is GitOps?
GitOps is an operational model that evolves DevOps best practices (such as version control, collaboration, compliance, and CI/CD) and IaC to perform operations on infrastructure and modern cloud-native applications. It does this by putting descriptive code for cloud infrastructure or applications into Git repositories for processing and version control, and then applying those changes to infrastructure through automation.
The 4 basic principles of GitOps are:
- System definitions are described as code.
- The desired system state and configuration is defined and versioned in Git.
- Changes to the configuration can be automatically applied using pull requests.
- A controller ensures that no configuration drifts are present.
You can learn more about these principles in the Introduction to GitOps with OpenShift post on the Red Hat Hybrid Cloud blog.
The GitOps methodology has several advantages:
- Single source of truth. All code is on Git, so there is a single source of truth for the infrastructure or platform.
- Easy rollback and fast recovery. All changes to the infrastructure are version controlled and reviewed so they are easy to roll back if necessary.
- Enhanced security. All changes are pulled and applied by automation; this limits manual access to the infrastructure and thus improves security.
GitOps practices can be applied not only to classic infrastructure like VMs, but also to Kubernetes, network config, application definitions, or even resources that can be described by config files and applied to the environment through automation.
The GitOps way
Here's an overview of how GitOps works:
Declarative description. The declarative description of the infrastructure/application as the desired state in the target environment is fundamental to GitOps. It also calls everything as code, including infrastructure, network, and security. The declarative description code or configuration exists on a centralized Git repository as a single source of truth for the whole system.
Utilize the Git workflow as control. All operations are conducted by making changes to code or configuration files in Git, so any changes can be versioned, reviewed, or merged based on Git's version control system.
Separation of configuration and deployment. Automated process are used to apply changes to the target environment; the best practice is to use a pull-based deployment where the agent/operator pulls and applies the changes.
The following diagram illustrates a typical high-level architecture for applying GitOps in a single environment:
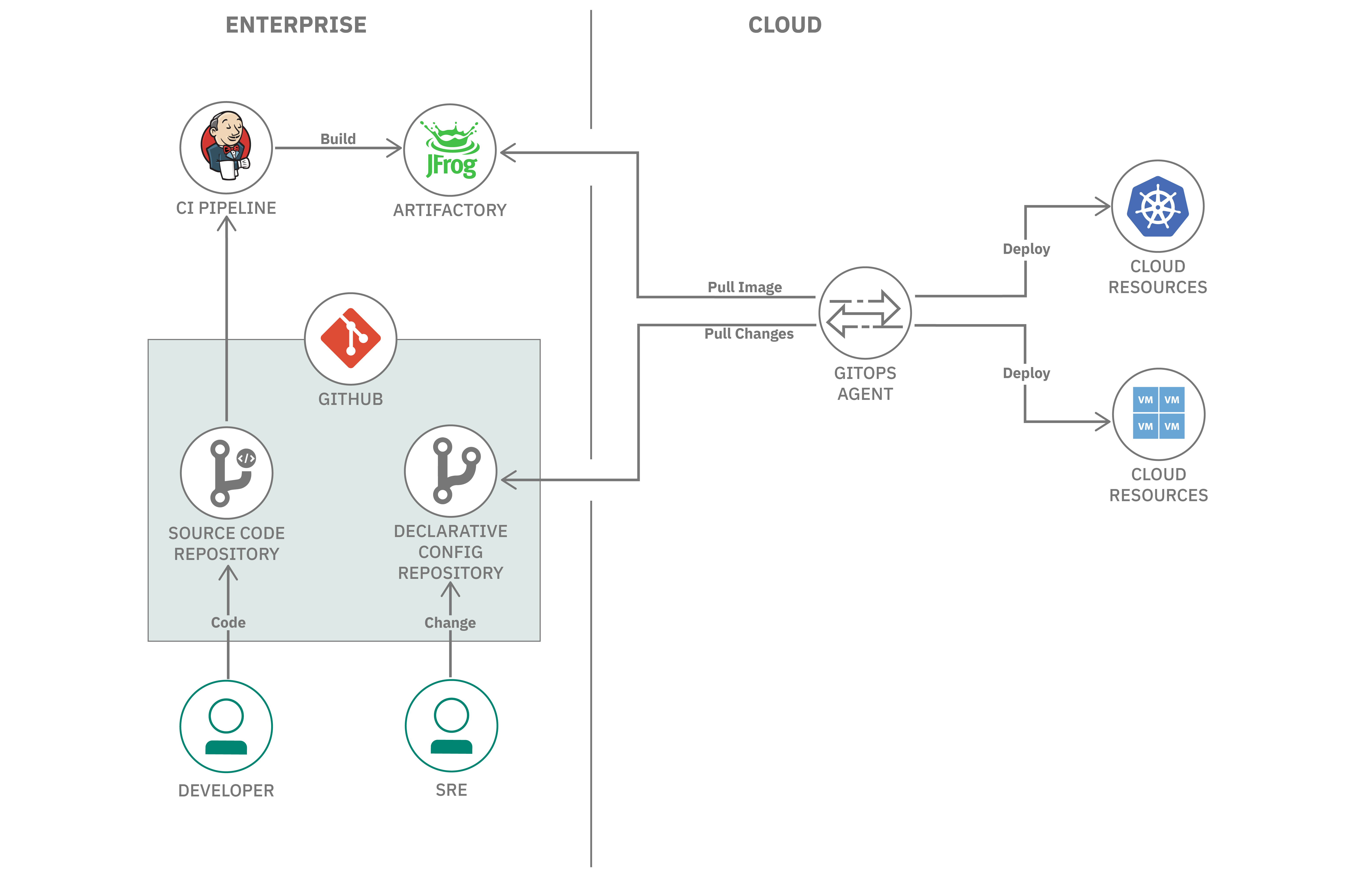
With GitOps, the application source code and declarative environment configuration are stored on Git with workflow support. On the development side, the developer changes the application source code and merges the changes after reviewing the pull request. The CI pipeline then detects the changes and triggers the build into an Artifacts repository. On the operations side, the SRE makes the changes to the environment configuration in the Declarative Config Repo and merges the changes after the review process. From an architecture perspective, a new GitOps Agent component is introduced in the target environment to detect the changes in the environment configuration repo, pull the latest configuration, and apply those changes to the environment. The changes are detected and pulled by the GitOps Agent, so there is no need for an operator to access the target environment and all credentials are kept within the environment.
GitOps in the real world
Day-to-day operations in the real world, however, can be complicated. For example, how do you handle destructive changes that are applied to an environment? An incorrect change can destroy a bare metal server, which can result in lost data and changes to the IP. How does GitOps work with different environments (such as development, staging, or production)? How do you promote changes to staging and production?
In this section, we address these questions and discuss how GitOps can be applied to real-world operations.
Cloud resource lifecycle
In many cases, GitOps works fine with Kubernetes clusters since it naturally supports declarative deployment and immutable infrastructure. However, real-world cloud infrastructures can be complicated and hybrid cloud can include many different resources, such as bare metal, classic VSI, network devices, cloud databases services, Kubernetes clusters, and containers.
Each type of resource has its own lifecycle. Imagine that you have a Kubernetes cluster built on top of several VSIs, and the cloud-native application that's deployed as containers has the shortest lifecycle. The cluster may have a longer lifecycle than a VSI since the worker node of a cluster is changeable over time. The bare metal server has the longest lifecycle of them all.
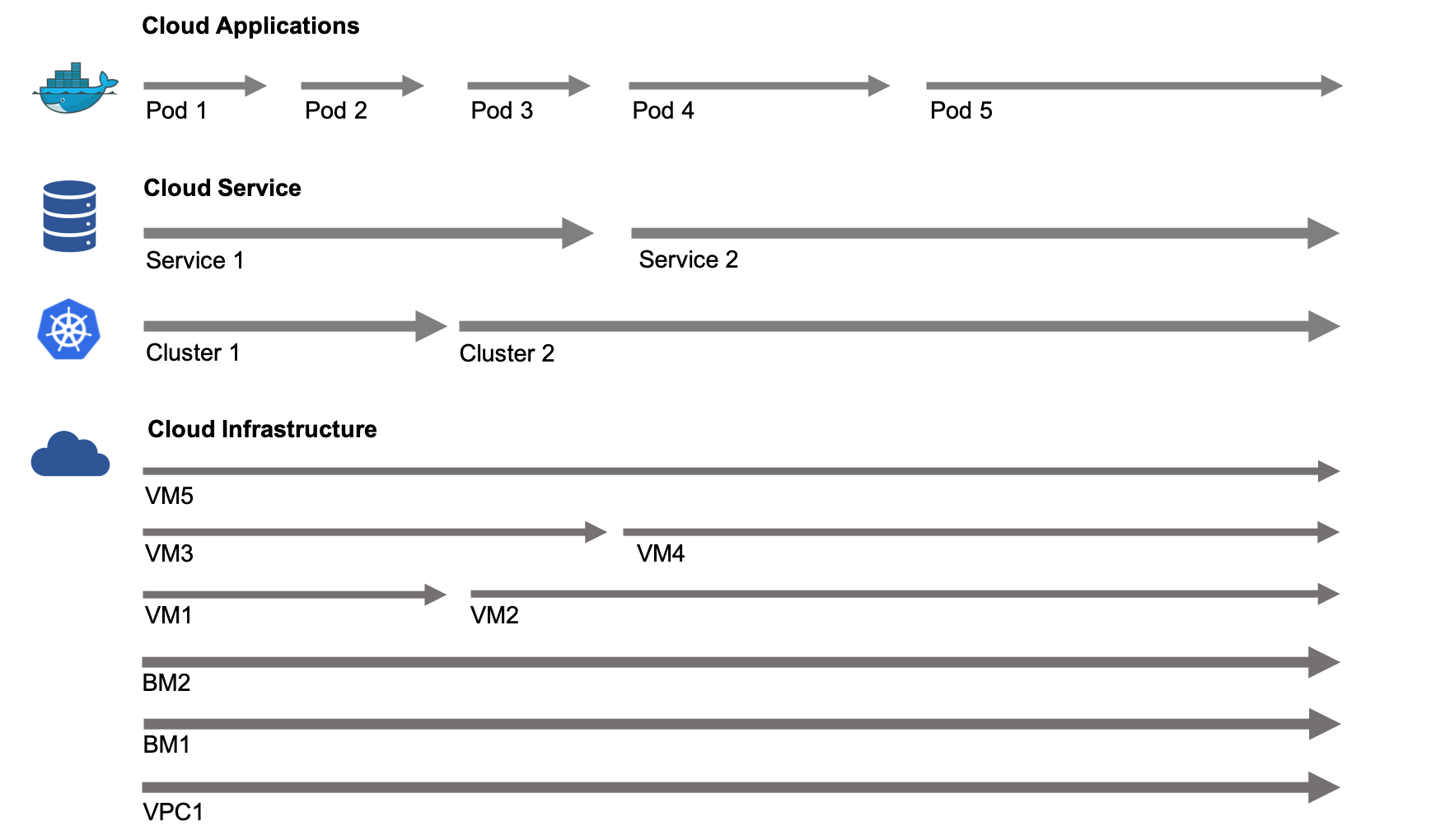
Because there are different resource lifecycles, you cannot process all the changes against the full stack through a single CI/CD pipeline or a single operation workflow. You need to use different strategies when applying GitOps practice to full-stack cloud resources.
Mutable vs. immutable
GitOps encourages you to work with immutable infrastructures and declarative containers, which means that after the deployment no change can be made to the infrastructure or the cloud-native applications. Kubernetes takes immutable containers.
However, let's say you're deploying an application on top of a classic infrastructure with limited resources, and it still has a long lifecycle. In this case, the GitOps methodology can still be leveraged to manage the infrastructure to take the advantage of GitOps, such as versioned changes over time and improved security.
Push-based vs. pull-based deployments
Even though pull-based deployment is a GitOps best practice that can ensure better security, GitOps adopters are not required to use pull-based deployment. However, in some situations not everything can be described using declarative configuration and there is no option for using a push-based deployment — for example, to provision a cloud infrastructure using tools like Jenkins, Travis, or Ansible.
Support for multiple environments
The description above mainly describes how GitOps works with a single environment. However, in real-world cloud environments (as with DevOps), you usually have multiple environments to support development, testing, and production scenarios.
The following diagram is a reference model that illustrates how GitOps can work with development, staging, and production environments:
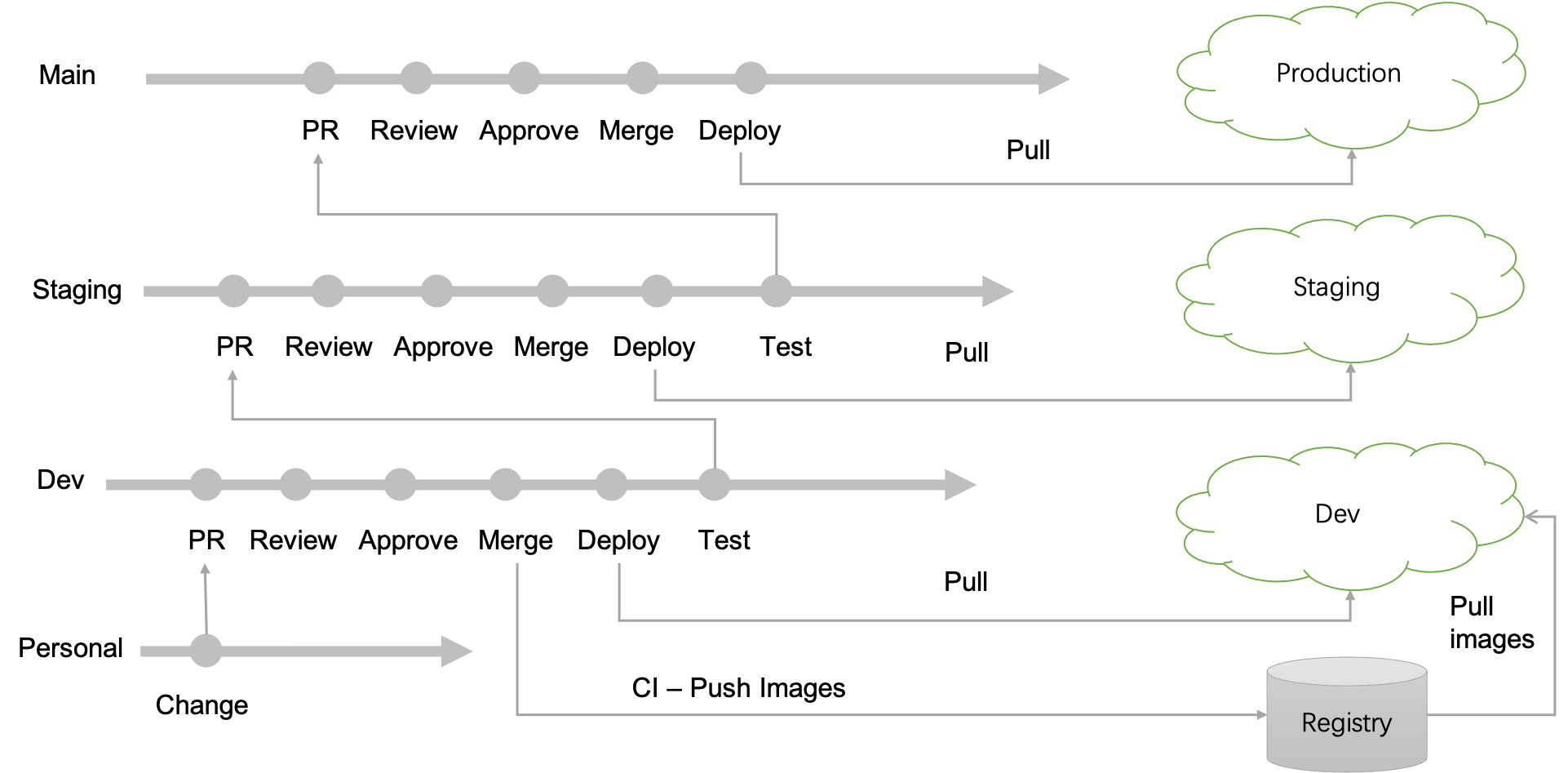
A typical strategy is to set up development, staging, and production environments for a system. With GitOps, you can set up corresponding branches in a Declarative Config Repository so that all three environments share the same configuration repository. For each environment, there is a GitOps Agent (one or more — see the Reference architecture section) that pulls changes from a staging branch. For example, the development environment monitors and pulls changes from the development branch and the staging environment pulls changes from the staging branch.
The Git workflow is set up to support code review, approval, merging, and testing. After the changes are pulled by the development environment and pass the integration tests, then the same changes can be promoted to the staging branch by creating a new pull request on staging. By doing a similar process, a change made by a developer or SRE can ultimately be pulled by the production environment.
Note that this process is just a reference model. In real-world situations, a project team could tailor this based on architecture decisions made for the actual situation.
Reference architecture
With what you have learned, you can also define a high-level reference architecture to apply GitOps practices to an IBM Cloud environment. This would look similar to the architecture shown in the GitOps overview, but the main differences here would be based on real-world situations. In the diagram below, we've mapped the components to a suggested software instance.
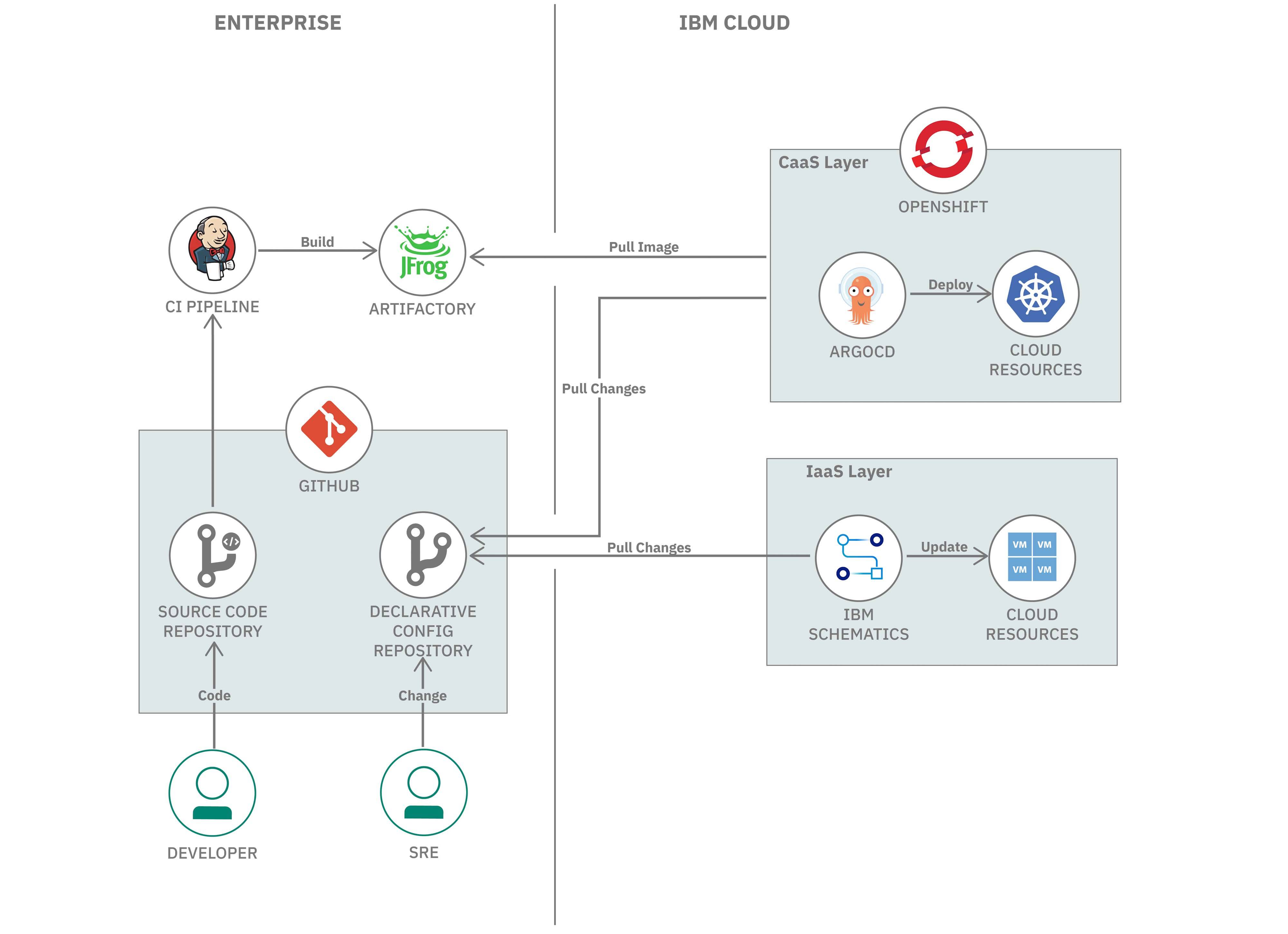
Most importantly, this architecture separates the CD processes for the CaaS and IaaS layers, since they can have very different resources and lifecycles. Based on the nature of the resources, different tools are used for different resources. More specifically, we recommend installing the GitOps plug-in on a Red Hat OpenShift instance. This ships an Argo CD instance out-of-the-box to play the GitOps Agent role to deploy the changes in the CaaS layer. On the IaaS layer, the IBM Cloud Schematics service implements GitOps practices by encapsulating the Terraform plug-in for IBM Cloud, which pulls the infrastructure changes and provisions/updates most of the IBM Cloud resources.
Summary
In this blog post, you learned about GitOps principles, the advantages provided by GitOps, and some best practices illustrated through real-world examples. GitOps can not only be applied to container-based apps, but also to a full stack of cloud resources. With well-designed automation processes, it can also support development and operations that promote changes in multiple environments.
GitOps is an improved approach for using DevOps on the cloud, but it cannot solve every challenge. That said, GitOps should be employed as a useful tool in your cloud DevOps toolbox.
Want to learn more about GitOps? Check out these resources:
- GitOps.tech website supported by INNOQ
- Guide to GitOps site supported by Weaveworks
- What is GitOps, how GitOps works, and why it's so useful video by TechWorld with Nana