Blog post
Use open source Drain3 log-template mining project to monitor for network outages
Use log-template mining to monitor for network outagesLog-template mining is a method for extracting useful information from unstructured log files. This blog post explains how you can use log-template mining to monitor for network outages and introduces you to Drain3, an open source streaming log template miner.
Our main goal in this use case is the early identification of incidents in the networking infrastructure of data centers that are part of the IBM Cloud. The IBM Cloud is based on many data centers in different regions and continents. At each data center (DC), thousands of network devices produce a high volume of syslog events. Using that information to quickly identify and troubleshoot outages and performance issues in the networking infrastructure helps reduce downtime and improve customer satisfaction.
Logs usually exist as raw text files, although they can also be in other formats like csv, json, etc. A log contains a series of events that occurred in the system/component that wrote them. Each event usually carries a timestamp field and a free text field that describes the nature of the event (generated from a template written in a free language). Usually, each log event includes additional information, which might cover event severity level, thread ID, ID of the software component that wrote the event, host name, etc.
An example of a log event from a network device might be:
Aug 15 05:44:51 vpn01.dc01 pri=6 msg="User David.ohana@ibm.com logged out successfully, session duration = 6 hours, 40 seconds"
This log event contains the following information parts (headers): timestamp, hostname, priority, and message body.
Each data center contains devices covering many vendors, types and versions. And these devices output log messages in many formats. Our first step was to extract the headers specified above. This can be done deterministically with some regular-expression based rules.

The screenshot above demonstrates univariate anomaly detection on a single log template from a single network device.
Logs vs metrics
When we want to troubleshoot or debug a complex software component, logs are usually among our best friends. Often we can also use metrics that cover periodic measurements of the system’s performance. These may include: CPU usage, memory usage, number of requests per second, etc. There are multiple mature and useful techniques and algorithms to analyze metrics, but significantly fewer to analyze logs. Therefore, we decided to build our own.
While metrics are easier to deal with because they represent a more structured type of information, they don’t always have the information we’re looking for. From a developer perspective, the effort required to add a new type of metric is greater than what is needed to add a new log event. Also, we usually want to keep the number of metrics we collect reasonably small to avoid bloating storage space and I/O.
We tend to add metric types post-mortem (after some kind of error occurred) in an effort to detect that same kind of error in the future. Software with a good set of metrics is usually mature and has been deployed in production for a long period. Logging, on the other hand, is easier to write and more expressive. This naturally results in log files containing more information that is useful for debugging than what is found in metric streams. This is especially true in less-mature systems. As a result, logs are better for troubleshooting errors and performance problems that were not anticipated when the software was written.
Dealing with the unstructured nature of logs
One major difference between a log file and a book, for example, is that a log is produced from a finite number of immutable print statements. The log template in each print statement never changes, and the only dynamic part is the template variables. For example, the following Python print statement would generate the free-text (message-body) portion of the log event in the example above:
print (f’User {user_name} logged out successfully, session duration = {hours} hours, {seconds} seconds’)
It’s generally not a simple task to identify the templates used in a log file because the source code or parts of it are not always available. If we had a unique identifier per event type included in each log message, that would help a lot, but that kind of information is rarely included.
Fortunately, the de-templating problem has received some research attention in recent years. The LogPAI project at the Chinese University of Hong Kong performed extensive benchmarking on the accuracy of 13 template miners. We evaluated the leading performers on that benchmark for our use case and settled on Drain as the best template-miner for our needs. Drain uses a simple approach for de-templating that is both accurate and fast.
Preparing Drain for production usage
Moving forward, our next step was to extend Drain for the production environment, giving birth to Drain3 (i.e., adjusted for Python 3). In our scenario, syslogs are collected from the IBM Cloud network devices and then streamed into an Apache Kafka topic. Although Drain was developed with a streaming use-case in mind, we had to solve some issues before we could use Drain in a production pipeline. We detail these issues below.
Refactoring - Drain was originally implemented in Python 2.7. We converted the code into a modern Python 3.6 codebase, while refactoring, improving the readability of the code, removing dependencies (e.g., pandas) and unused code, and fixing some bugs.
Streaming Support - Instead of using the original function that reads a static log file, we externalized the log-reading code, and added a feeding function add_log_message() to process the next log line and return the ID of the identified log cluster (template). The cluster ID format was changed from a hash code into a more human-readable sequential ID.
Resiliency - A production pipeline must be resilient. Drain is a stateful algorithm that maintains a parse tree that can change after each new log line begins being processed. To ensure resiliency, the template extractor must be able to restart using a saved state. In this way, after a failure, any knowledge already gathered will remain when the process recovers. Otherwise, we would have to stream all the logs from scratch to reach the same knowledge level. The state should be saved to a fault-tolerant, distributed medium and not a local file. A messaging system such as Apache Kafka is suitable for this, since it is distributed and persistent. Moreover, we were already using Kafka in our pipeline and did not want to add a dependency on another database/technology.
We had the Drain state serialized and published into a dedicated Kafka topic upon each change. Our assumption was that after an initial learning period, new or changed templates will occur rather infrequently, and that would not be a big performance hit. Another advantage of Kafka as a persistence medium is that, in addition to loading the latest state, we could also load prior versions, depending on the topic size, which is dependent on the topic retention policy we define.
We also made the persistence pluggable (i.e., injectable), so it would be easy to add additional persistence mediums or databases, and provide persistence to a local file for testing purposes.
Masking - We also improved the template mining accuracy by adding support for masking. Masking of a log message is the process of identifying constructs such as decimal numbers, hex numbers, IPs, email addresses, and so on, and replacing those with wildcards. In Drain3, masking is performed prior to processing of the log de-templating algorithm to help improve its accuracy. For example, the message ‘request 0xefef23 from 127.0.0.1 handled in 23ms‘ could be masked to ‘request
Packaging - The improved Drain3 code-base, including state persistence support and the enhancements, is available as an open source software under the MIT license in GitHub: https://github.com/logpai/Drain3. It is also consumable with pip as a PyPI package. Contributions are welcome.
Using log templates for analytics
Now that we could identify the template for each log message, how would we use that information to identify outages? Our model detects sudden changes in the frequencies of message types over time, and those may indicate networking issues. Take for example, a network device that normally outputs 10 log message of type L1 every 5 minutes. If that rate drops to 0, it might mean the device is down. Similarly, if the rate increased significantly, it may indicate another issue, e.g. a DDoS attack. Generally, rare types of messages, or message types we have never seen before, are also highly correlated with issues. This is keeping in mind that errors in a production data center are rare.
It is also possible to analyze the values of parameters in the log messages, just as we would for metrics. An anomaly in a parameter value could indicate of an issue. For example, we could look at a log message that prints the time it took to perform some operation:
fine tuning completed (took <NUM> ms)
Or a new categorical (string) parameter we never encountered before, e.g., a new task name that did not load:
Task Did Not Load: <*>
Let’s take the following synthetic log snippet and see how we turn it into a time series on which we can do anomaly detection:
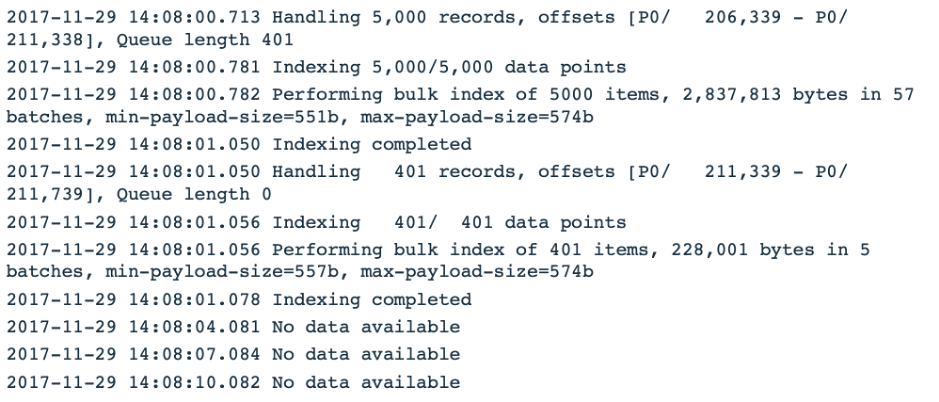
We cluster the messages using the color codes for message types, as follows:

We also extract numeric parameter values from each template type:

Now we count the occurrences of each message type in each time window, and also calculate an average value for each parameter:

The outcome is multiple time-series, which can be used for anomaly detection.
What’s next?
Of course, not every anomaly is an outage or an incident. In a big data center, it is almost guaranteed that you will get a few anomalies every hour. Weighting and correlating multiple anomalies is a must in order to estimate when an alert is justified.
We will discuss more details of our analytics pipeline, including the univariate and the multivariate analysis steps, in an upcoming blog post.